決定下一步做什么(Deciding What to Try Next)
確保在設計機器學習系統時,能夠選擇一條最合適、最正確的道路。
具體來講,將重點關注的問題是:假如你在開發一個機器學習系統,或者想試著改進一個機器學習系統的性能。
你應如何決定接下來應該選擇哪條道路?
1.?獲得更多的訓練實例——通常有效,但代價較大,下面的方法也可能有效,可
考慮先采用下面的幾種方法。?
2.?嘗試減少特征的數量?
3.?嘗試獲得更多的特征?
4.?嘗試增加多項式特征?
5.?嘗試減少歸一化程度 λ?
6.?嘗試增加歸一化程度 λ ?
不應該隨機選擇上面的某種方法來改進算法
而是運用一些機器學習診斷法來幫助我們知道上面哪些方法對算法是有效的。?
——————————————————————————————————————
評估學習器性能:
將數據分成訓練集和測試集, 通常70%作為訓練集, 30%作為測試集。

—————————————————————————————————————————————————————————
模型選擇和交叉驗證集(Model Selection and Train_Validation_Test Sets)

使用交叉驗證集來幫助選擇模型。?
即:使用 60%作為訓練集, 20%作為交叉驗證集,20%作為測試集 。
模型選擇的方法為:?
1.?使用訓練集訓練出 10 個模型?
2.?用 10 個模型分別對交叉驗證集計算得出交叉驗證誤差(代價函數的值)?
3.?選取代價函數值最小的模型?
4.?用步驟 3 中選出的模型對測試集計算得出泛化誤差(代價函數的值)——僅是為了得出泛化誤差,此步對模型選擇無用。

—————————————————————————————————————————————————————————
偏差/方差診斷(?Diagnosing Bias vs. Variance)
偏差大,欠擬合;
方差大,過擬合。
是一個很有效的指示器,指引可以改進算法的方法和途徑。
?
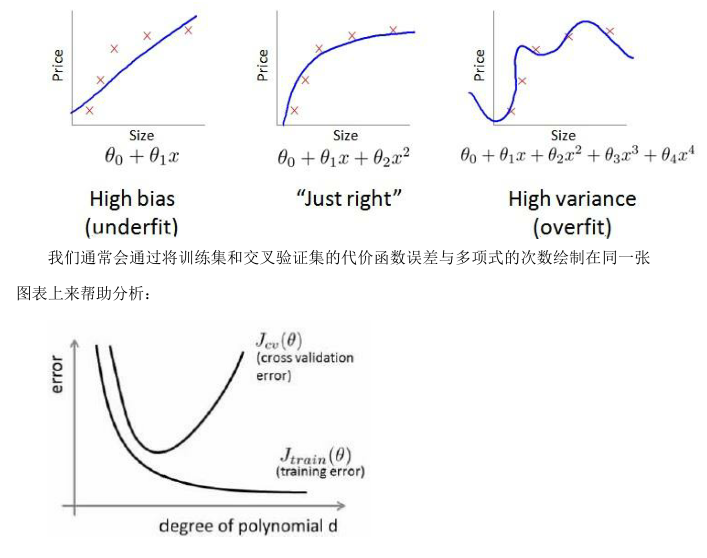
結論:
交叉驗證集誤差和訓練集誤差近似時:偏差/欠擬合 ;
交叉驗證集誤差遠大于訓練集誤差時:方差/過擬合。
—————————————————————————————————————————————————————————
正則化和偏差/方差(Regularization and Bias_Variance)
在訓練模型的過程中, 一般會使用一些正則化方法來防止過擬合。
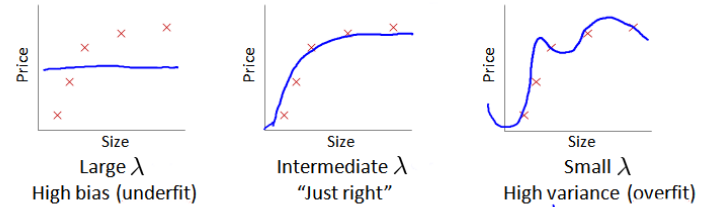
選擇一系列的想要測試的 λ 值,通常是 0-10 之間的呈現 2 倍關系的值。
(如:0,0.01,0.02,0.04,0.08,0.15,0.32,0.64,1.28,2.56,5.12,10 共 12 個)。?
我們同樣把數據分為訓練集、交叉驗證集和測試集。
選擇 λ 的方法為:?
1.?使用訓練集訓練出 12 個不同程度歸一化的模型;?
2.?用12個?模型分別對交叉驗證集計算的出交叉驗證誤差;?
3.?選擇得出交叉驗證誤差最小的模型;?
4.?運用步驟 3 中選出模型對測試集計算得出泛化誤差。——僅是為了得出泛化誤差,此步對模型選擇無用。
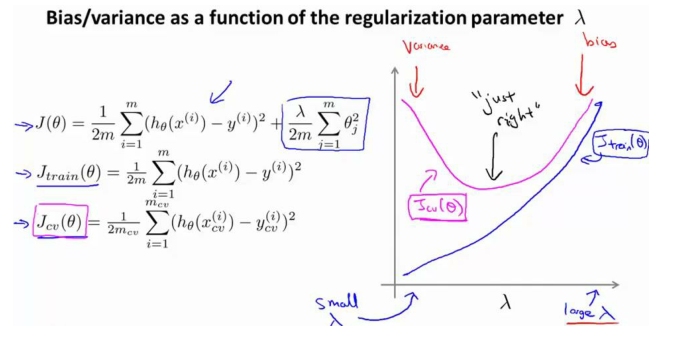
結論:
當 λ 較小時,訓練誤差較小(過擬合)而交叉驗證誤差較大 ;
隨著 λ 的增加,訓練誤差不斷增加(欠擬合),而交叉驗證誤差則是先減小后增加 。
—————————————————————————————————————————————————————————
學習曲線(Learning Curves)
經常使用學習曲線來判斷某一個學習算法是否處于偏差、方差問題。
學習曲線是學習算法的一個很好的合理檢驗(sanity check)。
學習曲線是將訓練集誤差和交叉驗證集誤差作為訓練集實例數量(m)的函數繪制的圖表。
?即,如果我們有 100 行數據,我們從 1 行數據開始,逐漸學習更多行的數據。
思想:
當訓練較少數據時, 訓練的模型將能夠非常完美地適應較少的訓練數據, 但是訓練出來的模型卻不能很好地適應交叉驗證集數據或測試集數據。
如何利用學習曲線識別高偏差/欠擬合?
作為例子,試用一條直線來適應下面的數據,可以看出,無論訓練集有多么大誤差都不會有太大改觀:
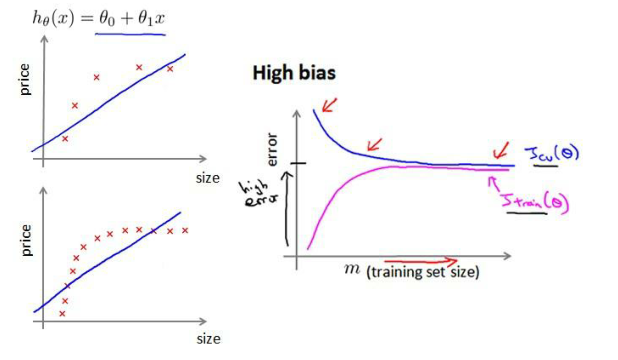
如何利用學習曲線識別高方差/過擬合?
?假設我們使用一個非常高次的多項式模型,并且正則化非常小.
可以看出,當交叉驗證集誤差遠大于訓練集誤差時,往訓練集增加更多數據可以提高模型的效果。?
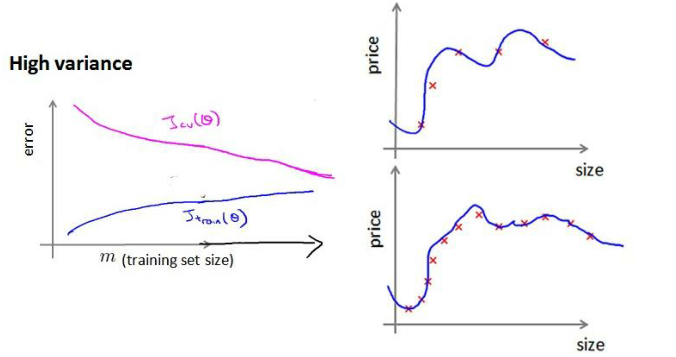
小結:
在高偏差/欠擬合的情況下,增加數據到訓練集不一定能有幫助;
在高方差/過擬合的情況下,增加更多數據到訓練集可能可以提高算法效果。?
—————————————————————————————————————————————————————————
決定下一步做什么(Deciding What to Do Next)
六種可選方案:?
1.?獲得更多的訓練實例——解決高方差?
2.?嘗試減少特征的數量——解決高方差?
3.?嘗試獲得更多的特征——解決高偏差?
4.?嘗試增加多項式特征——解決高偏差?
5.?嘗試減少正則化程度 λ——解決高偏差?
6.?嘗試增加正則化程度 λ——解決高方差?
神經網絡的方差和偏差:
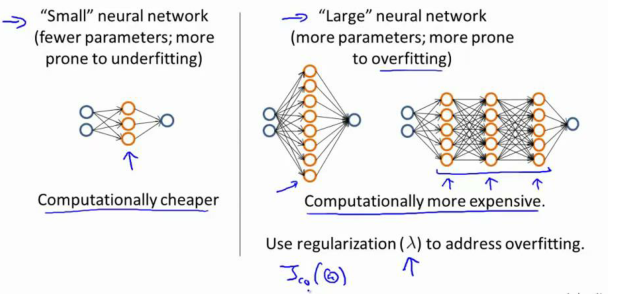
使用較小的神經網絡,類似于參數較少的情況,容易導致高偏差和欠擬合,但計算代價較小;
使用較大的神經網絡,類似于參數較多的情況,容易導致高方差和過擬合,雖然計算代價比較大,但是可以通過正則化手段來調整而更加適應數據。?
通常選擇較大的神經網絡并采用正則化處理會比采用較小的神經網絡效果要好。?
對于神經網絡中的隱藏層的層數的選擇,通常從一層開始逐漸增加層數。
為了更好地作選擇,可以把數據分為訓練集、交叉驗證集和測試集,針對不同隱藏層層數的神經網絡訓練神經網絡, 然后選擇交叉驗證集代價最小的神經網絡。
?



)
--接口測試工具介紹(詳解))




)

)
 用于數據可視化實驗 -- Matlab版)


)

)

