首先要做什么?
一個垃圾郵件分類器算法為例:
為了解決這樣一個問題,首先要做的決定是如何選擇并表達特征向量 x。
可以選擇一個由 100 個最常出現在垃圾郵件中的詞所構成的列表,根據這些詞是否有在郵件中
出現,來獲得我們的特征向量(出現為 1,不出現為 0),尺寸為 100×1。?
為了構建這個分類器算法,我們可以做很多事,例如:?
1.?收集更多的數據,讓我們有更多的垃圾郵件和非垃圾郵件的樣本;’?
2.?基于郵件的路由信息開發一系列復雜的特征;
3.?基于郵件的正文信息開發一系列復雜的特征,包括考慮截詞的處理;?
4.?為探測刻意的拼寫錯誤(把 watch 寫成 w4tch)開發復雜的算法。??
在上面這些選項中,非常難決定應該在哪一項上花費時間和精力,作出明智的選擇,比隨著感覺走要更好。
當我們使用機器學習時,總是可以“頭腦風暴”一下,想出一堆方法來試試。實際上,當你需要通過頭腦風暴來想出不同方法來嘗試去提高精度的時候,你可能已經超越了很多人了。
我們將在隨后的課程中講誤差分析, 我會告訴你怎樣用一個更加系統性的方法。從一堆不同的方法中,選取合適的那一個。
因此,你更有可能選擇一個真正的好方法,能讓你花上幾天幾周,甚至是幾個月去進行深入的研究。?
—————————————————————————————————————————————————————————
誤差分析(Error Analysis?)
如果你準備研究機器學習的東西,或者構造機器學習應用程序,最好的實踐方法不是建立一個非常復雜的系統,擁有多么復雜的變量;而是構建一個簡單的算法,這樣你可以很快地實現它。?
每當我研究機器學習的問題時, 我最多只會花一天的時間, 就是字面意義上的 24 小時,來試圖很快的把結果搞出來,即便效果不好。坦白的說,就是根本沒有用復雜的系統,但是只是很快的得到的結果。即便運行得不完美,但是也把它運行一遍,最后通過交叉驗證來檢驗數據。
一旦做完,你可以畫出學習曲線,通過畫出學習曲線,以及檢驗誤差,來找出你的算法是否有高偏差和高方差的問題,或者別的問題。在這樣分析之后,再來決定用更多的數據訓練,或者加入更多的特征變量是否有用。
這么做的原因是:這在你剛接觸機器學習問題時是一個很好的方法, 你并不能提前知道你是否需要復雜的特征變量, 或者你是否需要更多的數據,還是別的什么。提前知道你應該做什么,是非常難的,因為你缺少證據,缺少學習曲線。因此,你很難知道你應該把時間花在什么地方來提高算法的表現。
但是當你實踐一個非常簡單即便不完美的方法時,你可以通過畫出學習曲線來做出進一步的選擇。 你可以用這種方式來避免一種電腦編程里的過早優化問題。
?這種理念是: 我們必須用證據來領導我們的決策,怎樣分配自己的時間來優化算法,而不是僅僅憑直覺,憑直覺得出的東西一般總是錯誤的。
除了畫出學習曲線之外,一件非常有用的事是誤差分析,我的意思是說:當我們在構造垃圾郵件分類器時,我會看一看我的交叉驗證數據集, 然后親自看一看哪些郵件被算法錯誤地分類。
因此,通過這些被算法錯誤分類的垃圾郵件與非垃圾郵件,你可以發現某些系統性的規律:什么類型的郵件總是被錯誤分類。經常地這樣做之后,這個過程能啟發你構造新的特征變量,或者告訴你:現在這個系統的短處,然后啟發你如何去提高它。
構建一個學習算法的推薦方法為:?
1.?從一個簡單的能快速實現的算法開始,實現該算法并用交叉驗證集數據測試這個算法;;
2.?繪制學習曲線,決定是增加更多數據,或者添加更多特征,還是其他選擇 ;
3.?進行誤差分析: 人工檢查交叉驗證集中我們算法中產生預測誤差的實例, 看看這些實例是否有某種系統化的趨勢 。
當你在構造學習算法的時候,你總是會去嘗試很多新的想法,實現出很多版本的學習算法,如果每一次你實踐新想法的時候,你都要手動地檢測這些例子,去看看是表現差還是表現好,那么這很難讓你做出決定。到底是否使用詞干提取,是否區分大小寫。
但是通過一個量化的數值評估,你可以看看這個數字,誤差是變大還是變小了。你可以通過它更快地實踐你的新想法,它基本上非常直觀地告訴你:你的想法是提高了算法表現,還是讓它變得更壞, 這會大大提高你實踐算法時的速度。?
所以我強烈推薦在交叉驗證集上來實施誤差分析,而不是在測試集上。但是,還是有一些人會在測試集上來做誤差分析。即使這從數學上講是不合適的。所以我還是推薦你在交叉驗證向量上來做誤差分析。?
總結一下, 當你在研究一個新的機器學習問題時, 我總是推薦你實現一個較為簡單快速、即便不是那么完美的算法。我幾乎從未見過人們這樣做。大家經常干的事情是:花費大量的時間在構造算法上,構造他們以為的簡單的方法。
因此,不要擔心你的算法太簡單,或者太不完美,而是盡可能快地實現你的算法。當你有了初始的實現之后,它會變成一個非常有力的工具, 來幫助你決定下一步的做法。因為我們可以先看看算法造成的錯誤, 通過誤差分析,來看看他犯了什么錯,然后來決定優化的方式。
另一件事是:假設你有了一個快速而不完美的算法實現,又有一個數值的評估數據,這會幫助你嘗試新的想法,快速地發現你嘗試的這些想法是否能夠提高算法的表現,從而你會更快地做出決定,在算法中放棄什么,吸收什么。誤差分析可以幫助我們系統化地選擇該做什么。?
—————————————————————————————————————————————————————————
類偏斜的誤差度量(Error Metrics for Skewed Classes)
有一件重要的事情要注意, 就是使用一個合適的誤差度量值, 這有時會對于你的學習算法造成非常微妙的影響,這件重要的事情就是偏斜類(skewed classes)的問題。
類偏斜情況表現為訓練集中有非常多的同一種類的實例,只有很少其他類的實例。
例如預測癌癥是否惡性,在訓練集中,只有 0.5%的實例是惡性腫瘤。
假設編寫一個非學習而來的算法,在所有情況下都預測腫瘤是良性的,那么誤差只有 0.5%。
然而通過訓練而得到的神經網絡算法卻有 1%的誤差。
這時,誤差的大小是不能視為評判算法效果的依據的。
?
將算法預測的結果分成四種情況:?
1.?正確肯定(True Positive,TP):預測為真,實際為真?
2.?正確否定(True Negative,TN):預測為假,實際為假?
3.?錯誤肯定(False Positive,FP):預測為真,實際為假?
4.?錯誤否定(False Negative,FN):預測為假,實際為真
查準率(Precision)和查全率(Recall)
查準率=TP/(TP+FP)例, 在所有我們預測有惡性腫瘤的病人中,實際上有惡性腫瘤的病人的百分比,越高越好。?
查全率=TP/(TP+FN)例,在所有實際上有惡性腫瘤的病人中,成功預測有惡性腫瘤的病人的百分比,越高越好。?

—————————————————————————————————————————————————————————————————————————————
查全率和查準率之間的權衡(Trading Off Precision and Recall)
作為偏斜類問題的評估度量值,在很多應用中,我們希望能夠保證查準率和召回率的相對平衡。?
假使,算法輸出的結果在 0-1 之間,使用閥值 0.5 來預測真和假。
?
查準率(Precision)=TP/(TP+FP) 例:在所有預測為惡性腫瘤的病人中,實際上有惡性腫瘤的病人的百分比,越高越好。?
查全率(Recall)=TP/(TP+FN)例,在所有實際上有惡性腫瘤的病人中,成功預測有惡性腫瘤的病人的百分比,越高越好。?
如果我們希望只在非常確信的情況下預測為真(腫瘤為惡性),即我們希望更高的查準率,我們可以使用比 0.5 更大的閥值,如 0.7,0.9。這樣做我們會減少錯誤預測病人為惡性腫瘤的情況,同時卻會增加未能成功預測腫瘤為惡性的情況。?
如果我們希望提高查全率,盡可能地讓所有有可能是惡性腫瘤的病人都得到進一步地檢查、診斷,我們可以使用比 0.5 更小的閥值,如 0.3。?
我們可以將不同閥值情況下, 查全率與查準率的關系繪制成圖表, 曲線的形狀根據數據的不同而不同:?
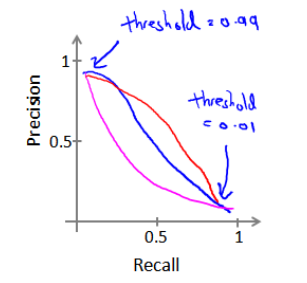
我們希望有一個幫助我們選擇這個閥值的方法。
一種方法是計算 F1 值(F1 Score),其計算公式為:
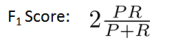
我們選擇使得 F1值最高的閥值。?
—————————————————————————————————————————————————————————
機器學習的數據(Data For Machine Learning)
討論一下機器學習系統設計中另一個重要的方面:用來訓練的數據有多少。
?得到大量的數據并在某種類型的學習算法中進行訓練, 可以是一種有效的方法來獲得一個具有良好性能的學習算法。
而這種情況往往出現在這些條件對于你的問題都成立,并且你能夠得到大量數據的情況下。
這可以是一個很好的方式來獲得非常高性能的學習算法。
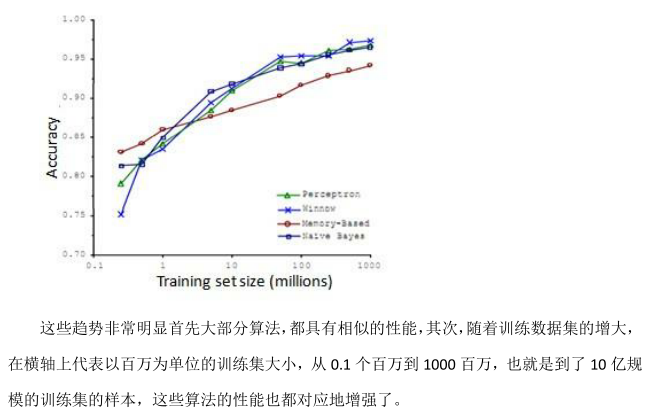
事實上,如果你選擇任意一個算法,可能是選擇了一個"劣等的"算法,如果你給這個劣等算法更多的數據,那么從這些例子中看起來的話,它看上去很有可能會其他算法更好,甚至會比"優等算法"更好。由于這項原始的研究非常具有影響力,因此已經有一系列許多不同的研究顯示了類似的結果。這些結果表明,許多不同的學習算法有時傾向于非常相似的表現,這還取決于一些細節,但是真正能提高性能的,是你能夠給一個算法大量的訓練數據。
像這樣的結果,引起了一種在機器學習中的普遍共識:"取得成功的人不是擁有最好算法的人,而是擁有最多數據的人"。
那么這種說法在什么時候是真, 什么時候是假呢?因為如果我們有一個學習算法,并且如果這種說法是真的,那么得到大量的數據通常是保證我們具有一個高性能算法的最佳方式, 而不是去爭辯應該用什么樣的算法。
那么讓我們來看一看, 大量的數據是有幫助的情況。
假設特征值有足夠的信息來預測 y?值,假設我們使用一種需要大量參數的學習算法,比如有很多特征的邏輯回歸或線性回歸,或者用帶有許多隱藏單元的神經網絡。 這些都是非常強大的學習算法,它們有很多參數,這些參數可以擬合非常復雜的函數。因此我要調用這些,我將把這些算法想象成低偏差算法,因為我們能夠擬合非常復雜的函數,而且因為我們有非常強大的學習算法,這些學習算法能夠擬合非常復雜的函數。很有可能,如果我們用這些數據運行這些算法,這種算法能很好地擬合訓練集,因此,訓練誤差就會很低了。?現在假設我們使用了非常非常大的訓練集,在這種情況下,盡管我們希望有很多參數,但是如果訓練集比參數的數量還大,甚至是更多,那么這些算法就不太可能會過度擬合。也就是說訓練誤差有希望接近測試誤差。?
另一種考慮這個問題的角度是為了有一個高性能的學習算法, 我們希望它不要有高的偏差和方差。?
因此偏差問題, 我么將通過確保有一個具有很多參數的學習算法來解決, 以便我們能夠得到一個較低偏差的算法;并且通過用非常大的訓練集來保證,?我們在此沒有方差問題,我們的算法將沒有方差。通過這兩個方面,我們最終可以得到一個低誤差和低方差的學習算法。 這使得我們能夠很好地測試測試數據集。?
從根本上來說,這是一個關鍵的假設:特征值有足夠的信息量,且我們有一類很好的函數,這是為什么能保證低誤差的關鍵所在。它有大量的訓練數據集,這能保證得到更多的方差值,因此這給我們提出了一些可能的條件,如果你有大量的數據,而且你訓練了一種帶有很多參數的學習算法,那么這將會是一個很好的方式,來提供一個高性能的學習算法。?
我覺得關鍵的測試: 首先, 一個人類專家看到了特征值 x, 能很有信心的預測出 y 值嗎??因為這可以證明 y 可以根據特征值 x 被準確地預測出來。
其次,我們實際上能得到一組龐大的訓練集, 并且在這個訓練集中訓練一個有很多參數的學習算法嗎?
如果你能做到這兩者,那么更多時候,你會得到一個性能很好的學習算法。?
)
--接口測試工具介紹(詳解))




)

)
 用于數據可視化實驗 -- Matlab版)


)

)




