書接上文(使用Apriori進行關聯分析(一)),介紹如何挖掘關聯規則。
發現關聯規則
我們的目標是通過頻繁項集挖掘到隱藏的關聯規則。
所謂關聯規則,指通過某個元素集推導出另一個元素集。比如有一個頻繁項集{底板,膠皮,膠水},那么一個可能的關聯規則是{底板,膠皮}→{膠水},即如果客戶購買了底板和膠皮,則該客戶有較大概率購買膠水。這個頻繁項集可以推導出6個關聯規則:
{底板,膠水}→{膠皮},
{底板,膠皮}→{膠水},
{膠皮,膠水}→{底板},
{底板}→{膠水, 膠皮},
{膠水}→{底板, 膠皮},
{膠皮}→{底板, 膠水}
箭頭左邊的集合稱為“前件”,右邊集合稱為“后件”,根據前件會有較大概率推導出后件,這個概率就是之前提到的置信度。需要注意的是,如果A→B成立,B→A不一定成立。
一個具有N個元素的頻繁項集,共有M個可能的關聯規則:
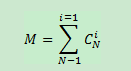
下圖是一個頻繁4項集的所有關聯規則網格示意圖,?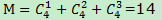
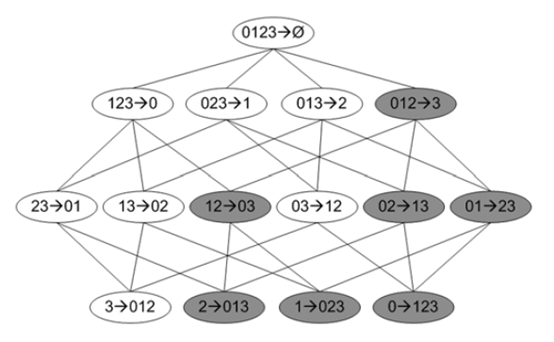
上圖中深色區域表示低可信度規則,如果012→3是一條低可信度規則,則所有其它3為后件的規則都是低可信度。這需要從可信度的概念去理解,Confidence(012→3) = P(3|0,1,2),Confidence(01→23)=P(2,3|0,1),P(3|0,1,2) >= P(2,3|0,1)。由此可以對關聯規則做剪枝處理。
還是以上篇的超市交易數據為例,我們發現了如下的頻繁項集:

對于尋找關聯規則來說,頻繁1項集L1沒有用處,因為L1中的每個集合僅有一個數據項,至少有兩個數據項才能生成A→B這樣的關聯規則。
當最小置信度取0.5時,L2最終能夠挖掘出9條關聯規則:

從頻繁3項集開始,挖掘的過程就較為復雜。

假設有一個頻繁4項集(這是杜撰的,文中的數據不能生成L4),其挖掘過程如下:

因為書中的代碼假設購買商品是有順序的,所以在生成3后件時,{P2,P4}和{P3,P4}并不能生成{P2,P23,P4},如果想去掉假設,需要使用上篇中改進后的代碼。
發掘關聯規則的代碼如下:

1 #生成關聯規則 2 #L: 頻繁項集列表 3 #supportData: 包含頻繁項集支持數據的字典 4 #minConf 最小置信度 5 def generateRules(L, supportData, minConf=0.7): 6 #包含置信度的規則列表 7 bigRuleList = [] 8 #從頻繁二項集開始遍歷 9 for i in range(1, len(L)): 10 for freqSet in L[i]: 11 H1 = [frozenset([item]) for item in freqSet] 12 if (i > 1): 13 rulesFromConseq(freqSet, H1, supportData, bigRuleList, minConf) 14 else: 15 calcConf(freqSet, H1, supportData, bigRuleList, minConf) 16 return bigRuleList 17 18 19 # 計算是否滿足最小可信度 20 def calcConf(freqSet, H, supportData, brl, minConf=0.7): 21 prunedH = [] 22 #用每個conseq作為后件 23 for conseq in H: 24 # 計算置信度 25 conf = supportData[freqSet] / supportData[freqSet - conseq] 26 if conf >= minConf: 27 print(freqSet - conseq, '-->', conseq, 'conf:', conf) 28 # 元組中的三個元素:前件、后件、置信度 29 brl.append((freqSet - conseq, conseq, conf)) 30 prunedH.append(conseq) 31 32 #返回后件列表 33 return prunedH 34 35 36 # 對規則進行評估 37 def rulesFromConseq(freqSet, H, supportData, brl, minConf=0.7): 38 m = len(H[0]) 39 if (len(freqSet) > (m + 1)): 40 Hmp1 = aprioriGen(H, m + 1) 41 # print(1,H, Hmp1) 42 Hmp1 = calcConf(freqSet, Hmp1, supportData, brl, minConf) 43 if (len(Hmp1) > 0): 44 rulesFromConseq(freqSet, Hmp1, supportData, brl, minConf)
?
由此可以看到,apriori算法需要經常掃描全表,效率并不算高。

)










)






