大型數據集的學習(Learning With Large Datasets)
如果我們有一個低方差的模型, 增加數據集的規模可以幫助你獲得更好的結果。?
我們應該怎樣應對一個有 100 萬條記錄的訓練集??
以線性回歸模型為例,每一次梯度下降迭代,我們都需要計算訓練集的誤差的平方和,如果我們的學習算法需要有 20 次迭代,這便已經是非常大的計算代價。?
首先應該做的事是去檢查一個這么大規模的訓練集是否真的必要,也許我們只用 1000?個訓練集也能獲得較好的效果,我們可以繪制學習曲線來幫助判斷。
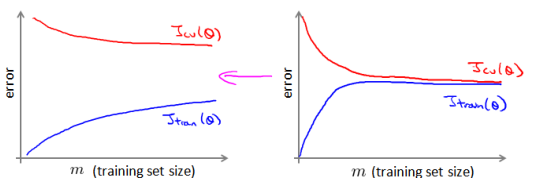
—————————————————————————————————————————————————————————
隨機梯度下降法(Stochastic Gradient Descent)
如果我們一定需要一個大規模的訓練集, 我們可以嘗試使用隨機梯度下降法來代替批量梯度下降法。
在隨機梯度下降法中,我們定義代價函數為一個單一訓練實例的代價:
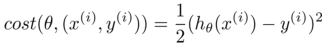
隨機梯度下降算法為:
首先:對訓練集隨機“洗牌”;
然后:
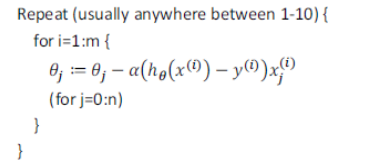
隨機梯度下降算法在每一次計算之后便更新參數 θ, 而不需要首先將所有的訓練集求和。
在梯度下降算法還沒有完成一次迭代時, 隨機梯度下降算法便已經走出了很遠。?
但是這樣的算法存在的問題是,不是每一步都是朝著”正確”的方向邁出的。
因此算法雖然會逐漸走向全局最小值的位置,但是可能無法站到那個最小值的那一點,而是在最小值點附近徘徊。
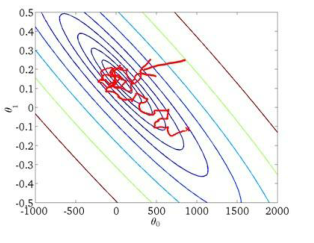
—————————————————————————————————————————————————————————
小批量梯度下降(Mini-Batch Gradient Descent)
小批量梯度下降算法是介于批量梯度下降算法和隨機梯度下降算法之間的算法, 每計算常數 b 次訓練實例,便更新一次參數 θ。
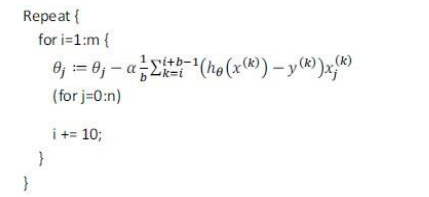
通常我們會令 b 在 2-100 之間。這樣做的好處在于,我們可以用向量化的方式來循環?b 個訓練實例,如果我們用的線性代數函數庫比較好,能夠支持平行處理,那么算法的總體表現將不受影響(與隨機梯度下降相同)。
—————————————————————————————————————————————————————————
在線學習(Online Learning)
一種新的大規模的機器學習機制,叫做在線學習機制。
今天,許多大型網站使用不同版本的在線學習機制算法,從大批的涌入又離開網站的用戶身上進行學習。
特別要提及的是, 如果你有一個由連續的用戶流引發的連續的數據流,進入你的網站,你能做的是使用一個在線學習機制,從數據流中學習用戶的偏好,然后使用這些信息來優化一些關于網站的決策。
在線學習算法指的是對數據流而非離線的靜態數據集的學習。
許多在線網站都有持續不斷的用戶流,對于每一個用戶,網站希望能在不將數據存儲到數據庫中便順利地進行算法學習。?
在線學習的算法與隨機梯度下降算法有些類似, 我們對單一的實例進行學習, 而非對一個提前定義的訓練集進行循環。

一旦對一個數據的學習完成了,我們便可以丟棄該數據,不需要再存儲它了。
這種方式的好處在于,我們的算法可以很好的適應用戶的傾向性,算法可以針對用戶的當前行為不斷地更新模型以適應該用戶。
這些問題中的任何一個都可以被歸類到標準的,擁有一個固定的樣本集的機器學習問題中。
或許,你可以運行一個你自己的網站,嘗試運行幾天,然后保存一個數據集,一個固定的數據集,然后對其運行一個學習算法。
但是這些是實際的問題,即大公司會獲取如此多的數據,真的沒有必要來保存一個固定的數據集, 取而代之的是你可以使用一個在線學習算法來連續的學習,從這些用戶不斷產生的數據中來學習。 這就是在線學習機制。
然后就像我們所看到的,我們所使用的這個算法與隨機梯度下降算法非常類似,唯一的區別的是,我們不會使用一個固定的數據集,我們會做的是獲取一個用戶樣本,從那個樣本中學習, 然后丟棄那個樣本并繼續下去, 而且如果你對某一種應用有一個連續的數據流,這樣的算法可能會非常值得考慮。
當然,在線學習的一個優點就是,如果你有一個變化的用戶群,又或者你在嘗試預測的事情,在緩慢變化,就像你的用戶的品味在緩慢變化,這個在線學習算法,可以慢慢地調試你所學習到的假設,將其調節更新到最新的用戶行為。
————————————————————————————————————————————————————————
Map Reduce and Data Parallelism
Map Reduce and Data Parallelism對于大規模機器學習問題而言是非常重要的概念。
之前提到, 如果我們用批量梯度下降算法來求解大規模數據集的最優解,我們需要對整個訓練集進行循環,計算偏導數和代價,再求和,計算代價非常大。如果我們能夠將我們的數據集分配給不多臺計算機,讓每一臺計算機處理數據集的一個子集,然后我們將計所的結果匯總在求和。這樣的方法叫做MapReduce。
具體而言,如果任何學習算法能夠表達為,對訓練集的函數的求和,那么便能將這個任務分配給多臺計算機(或者同一臺計算機的不同 CPU 核心),以達到加速處理的目的。
?
例如, 我們有 400 個訓練實例, 我們可以將批量梯度下降的求和任務分配給 4 臺計算機進行處理:

很多高級的線性代數函數庫已經能夠利用多核 CPU 的多個核心來并行地處理矩陣運算,這也是算法的向量化實現如此重要的緣故(比調用循環快)。









)









