推薦系統(Recommender Systems)?
推薦系統根據瀏覽用戶過去買過什么書,或過去評價過什么電影來判斷并推薦新產品給用戶。
這些系統會為像亞馬遜和網飛這樣的公司帶來很大一部分收入。
因此,對推薦系統性能的改善,將對這些企業的有實質性和直接的影響。
對機器學習來說,特征是很重要的,你所選擇的特征,將對你學習算法的性能有很大的影響。因此,在機器學習中有一種大思想,它針對一些問題,可能并不是所有的問題,而是一些問題,有算法可以為你自動學習一套好的特征。推薦系統就是一個例子。
例子:?我們有 5 部電影和 4 個用戶, 我們要求用戶為電影打分。 ?

基于內容的推薦系統(Content Based Recommendations)
在一個基于內容的推薦系統算法中,假設對于希望推薦的東西有一些數據,這些數據是有關這些東西的特征。
在例子中,假設每部電影都有兩個特征,如 x1代表浪漫程度,x2?代表動作程度。
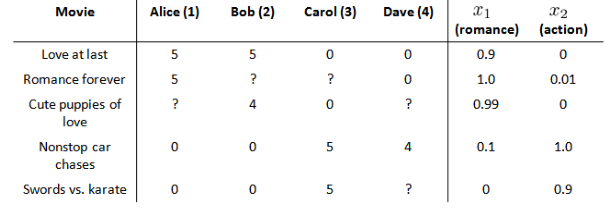
下面我們要基于這些特征來構建一個推薦系統算法。?
假設我們采用線性回歸模型,可以針對每一個用戶都訓練一個線性回歸模型。

代價函數:

上面的代價函數只是針對一個用戶的, 為了學習所有用戶, 我們將所有用戶的代價函數求和:
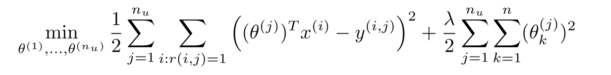
如果要用梯度下降法來求解最優解,我們計算代價函數的偏導數后得到梯度下降的更新公式為:
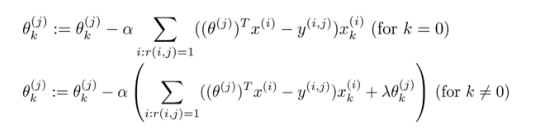
在之前的基于內容的推薦系統中,對于每一部電影,我們都掌握了可用的特征,使用這些特征訓練出了每一個用戶的參數。
相反地,如果我們擁有用戶的參數,我們可以學習得出電影的特征。
首先,用戶要對擁有特征的電影進行評分,此時就可以學習出用戶的偏好參數。
之后,上線新電影時,用戶對其觀看并打分,此時針對這個新電影,就可以根據用戶的偏好參數來自動學習出電影的特征。
—————————————————————————————————————————————————————————
協同過濾(Collaborative Filtering)
但是如果我們既沒有用戶的參數,也沒有電影的特征,這兩種方法都不可行了。
協同過濾算法可以同時學習這兩者。
優化目標改為同時針對 x 和 θ 進行:
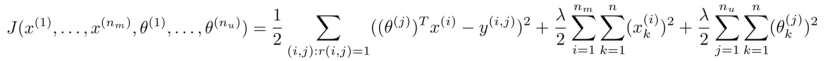
對代價函數求偏導數的結果如下:
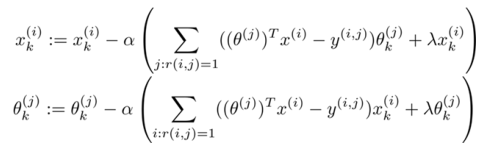
注:在協同過濾從算法中,我們通常不使用bias項,如果需要的話,算法會自動學得。 ?
協同過濾算法使用步驟如下:

對于電影 x(i)和另一電影 x(j),依據兩部電影特征向量之間的距離 ||x(i)-x(j)|| 的大小,可以判斷它們是否為同一類電影。
小結:
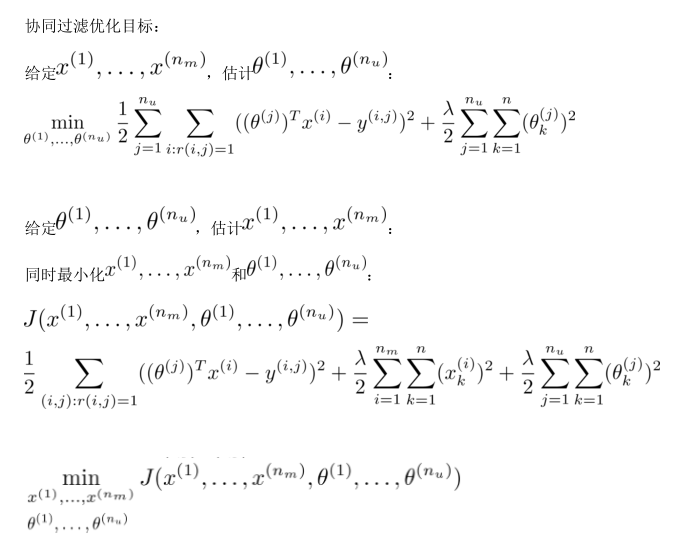
—————————————————————————————————————————————————————————
舉例子: ?
1.當給出一件產品時,你能否找到與之相關的其它產品。?
2.一位用戶最近看上一件產品,有沒有其它相關的產品,你可以推薦給他。?
我將要做的是:實現一種選擇的方法,寫出協同過濾算法的預測情況。?
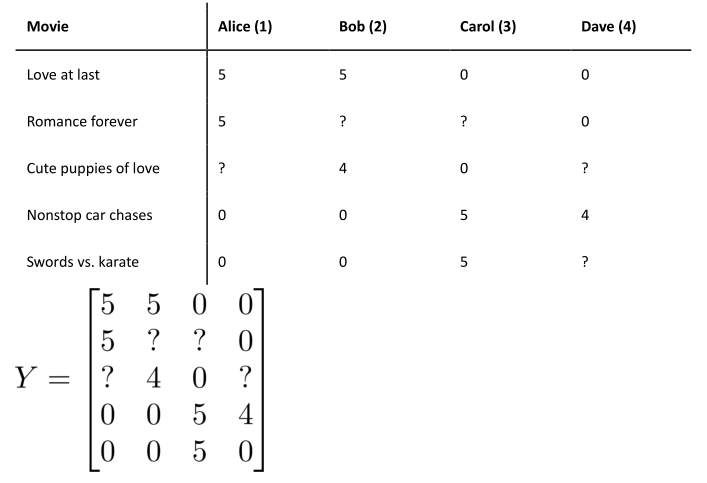
我們有關于五部電影的數據集,我將要做的是,將這些用戶的電影評分,進行分組并存到一個矩陣中。?
我們有五部電影,以及四位用戶,那么這個矩陣 Y 就是一個 5 行 4 列的矩陣,它將這些電影的用戶評分數據都存在矩陣里:
推出評分:

找到相關影片:

現在既然你已經對特征參數向量進行了學習,那么我們就會有一個很方便的方法來度量兩部電影之間的相似性。
例如說:電影 i 有一個特征向量 x(i),你是否能找到一部不同的電影?j,保證兩部電影的特征向量之間的距離 x(i)和 x(j)很小,那就能很有力地表明電影 i 和電影 j?在某種程度上有相似,至少在某種意義上,某些人喜歡電影 i,或許更有可能也對電影 j 感興趣。?
總結一下, 當用戶在看某部電影 i 的時候,如果你想找 5 部與電影非常相似的電影,為了能給用戶推薦 5 部新電影,你需要做的是找出電影 j,在這些不同的電影中與我們要找的電影 i 的距離最小,這樣你就能給你的用戶推薦幾部不同的電影了。?
通過這個方法, 希望你能知道, 如何進行一個向量化的計算來對所有的用戶和所有的電影進行評分計算。 同時希望你也能掌握, 通過學習特征參數, 來找到相關電影和產品的方法。
實現細節:均值歸一(Implementational Detail_ Mean Normalization)
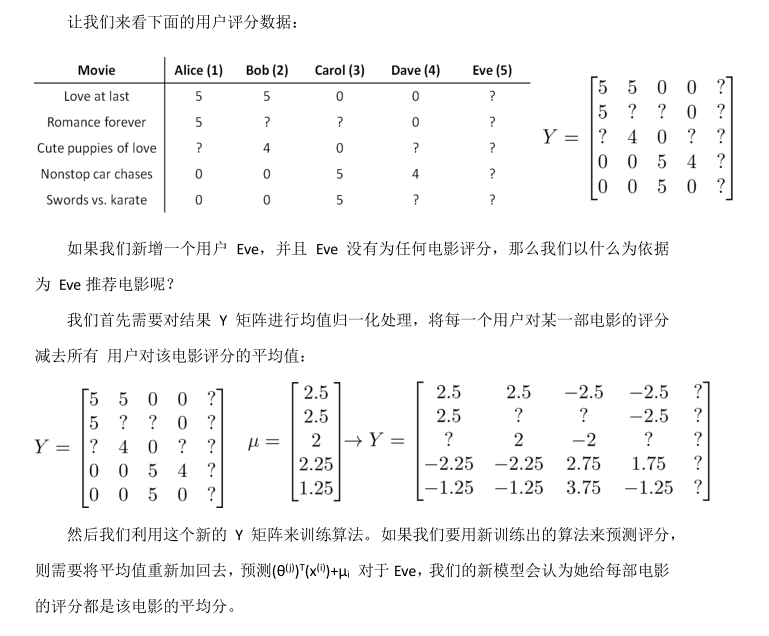
)

)










)





