- 🌈所屬專欄:【機械學習】
- ?作者主頁:??Mr.Zwq
- ??個人簡介:一個正在努力學技術的Python領域創作者,擅長爬蟲,逆向,全棧方向,專注基礎和實戰分享,歡迎咨詢!
您的點贊、關注、收藏、評論,是對我最大的激勵和支持!!!🤩🥰😍
目錄
安裝
數據
缺失值處理
數據標準化
對文本數據進行數字編碼
總結
安裝
pip install scikit-learn數據
X,y即為所需要進行回歸處理的數據。
操作:拆分為訓練集和測試集
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X,y,test_size=0.3, random_state=12)缺失值處理
# 缺失值處理
from sklearn.impute import SimpleImputer# 創建SimpleImputer對象,使用均值填充缺失值
imputer = SimpleImputer(strategy='mean')# 對數據集進行擬合和轉換
X_train = imputer.fit_transform(X_train)
X_test = imputer.transform(X_test)數據標準化
# 數據標準化
#fit(), 用來求得訓練集X的均值,方差,最大值,最小值,這些訓練集x固有的屬性。
#transform(),在fit的基礎上,進行標準化,降維,歸一化等操作。
#fit_transform(),包含上述兩個功能。from sklearn.preprocessing import StandardScalerscaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)對文本數據進行數字編碼
# 對某列進行編碼
from sklearn.preprocessing import LabelEncoder# 創建LabelEncoder對象
encoder = LabelEncoder()# data數據自行提供
data['朝向編碼'] = encoder.fit_transform(data['朝向'])處理后效果如下:
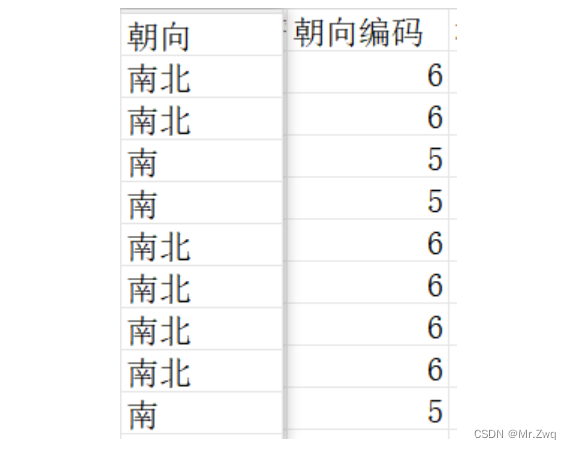
總結
感謝觀看,原創不易,如果覺得有幫助,請給文章點個贊吧,讓更多的人看到。🌹🌹🌹
 ?
?
👍🏻也歡迎你,關注我。👍🏻
如有疑問,可在評論區留言哦~
)













)




