假如你正在設計和開發一個分布式服務系統,系統中存在一批能夠獨立運行的服務,而在部署上也采用了集群模式以防止出現單點故障。所謂集群,就是指將多個服務實例集中在一起,對外提供同一業務功能,也就是任意請求都可以由集群中的某一個服務實例進行響應。如下圖所示:

那么問題就來了,就像上圖中所展示的,你的一次請求到底應該是由哪個服務實例來響應最為合適呢?這就是今天我們要討論的話題。這個話題看上去很簡單,實際上卻有點復雜,涉及到服務請求的路由機制。在分布式系統中,負載均衡(Load Balance)是最常見的一種路由機制,接下來我們就來展開一下。
所謂負載均衡,簡單講就是將請求分攤到多個操作單元上進行執行。負載均衡建立在現有網絡結構之上,它提供了一種廉價、有效、透明的方法擴展服務器的帶寬、增加吞吐量、加強網絡數據處理能力,以及提高網絡的靈活性。下圖展示了負載均衡的基本結構,可以看到來自客戶端的請求通過中間的負載均衡器將被分發到各個服務實例,根據分發策略的不同將產生不同的分發結果。
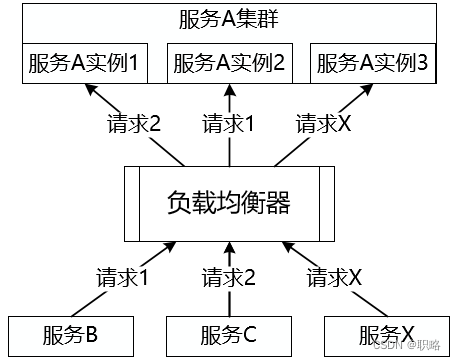
針對上圖,我們先來考慮一個基礎性的問題,即負載均衡器想要實現請求分發的前提是什么?顯然,負載均衡器需要掌握當前各個服務實例的運行時狀態,也就是說需要持有當前的服務實例列表信息,如下所示:

接下來我們來詳細討論具體的分發策略。首當其沖我們要明確的是一個問題是:請求是由誰來分發?針對這點就可以分成兩大類負載均衡器,即服務器端負載均衡和客戶端負載均衡,它們的核心區別就是服務實例地址列表所存放的位置。
我們先來看服務器端負載均衡,它的結構如下圖所示:

顯然,在這種負載均衡架構下,在客戶端與服務實例之間存在一個獨立的負載均衡服務器,然后這臺負載均衡服務器負責將接收到的各個請求轉發到運行中的某個服務實例上。提供服務器端負載均衡的工具有很多,例如常見的Apache、Nginx、HAProxy等都實現了基于HTTP協議或TCP協議的負載均衡模塊。
基于服務器端的負載均衡機制實現比較簡單,只需要在客戶端與各個服務實例之間架設集中式的負載均衡器即可。負載均衡器與各個服務實例之間需要實現服務診斷以及狀態監控,通過動態獲取各個服務實例的運行時信息來決定負載均衡的目標服務。如果負載均衡器檢測到某個服務實例已經不可用時就會自動移除該服務實例,正如上圖中所示的“服務A實例2”那樣。
通過上述分析,可以看到負載均衡器運行在一臺獨立的服務器上并充當代理(Proxy)的作用。所有的請求都需要通過負載均衡器的轉發才能實現服務調用,這可能會是一個問題,因為當服務請求量越來越大時,負載均衡器將會成為系統的瓶頸。同時,一旦負載均衡器自身發生失敗,整個服務的調用過程都將發生失敗。因此,分布式架構中,為了避免集中式負載均衡所帶來的這種問題,客戶端負載均衡同樣也是一種常用的方式。
客戶端本身同樣可以實現負載均衡。所謂客戶端負載均衡,簡單的說就是在客戶端程序內部保存著各個服務實例信息,然后自己設定一個調度算法,在向服務器發起請求的時候,先執行調度算法計算出目標服務實例的地址。客戶端負載均衡的表現形式如下圖所示:

客戶端負載均衡應用廣泛,例如目前主流的微服務架構實現框架Spring?Cloud、Dubbo等都內置了完整的客戶端負載均衡模塊。而像老牌的分布式緩存Memcache同樣也是這一負載均衡策略的典型應用。
相比較而言,客戶端負載均衡機制的主要優勢就是不會出現集中式負載均衡所產生的瓶頸問題,因為每個客戶端都有自己的負載均衡器,單個負載均衡器的失效也不會造成嚴重的后果。另一方面,由于所有的服務實例運行時信息都需要在多個負載均衡器之間進行傳遞,會在一定程度上加重網絡流量負載。
通過前面內容的介紹,我們已經明確了“請求由誰來分發?”這個核心問題,同時也引出了一個新的概念,即用于執行負載均衡的調度算法,這就是我們要討論的第二個問題,即“請求分發到哪去?”。
無論是使用服務器端負載均衡還是客戶端負載均衡,運行時的分發策略決定了負載均衡的效果。分發策略在軟件負載均衡中的實現形式為一組調度算法,通常稱為負載均衡算法。負載均衡算法可以分成兩大類,即靜態負載均衡算法和動態負載均衡算法,它們之間的區別在于是否依賴于當前服務的運行時狀態,這些狀態信息通常包括服務過去一段時間的平均調用時延和所承接的連接數等。
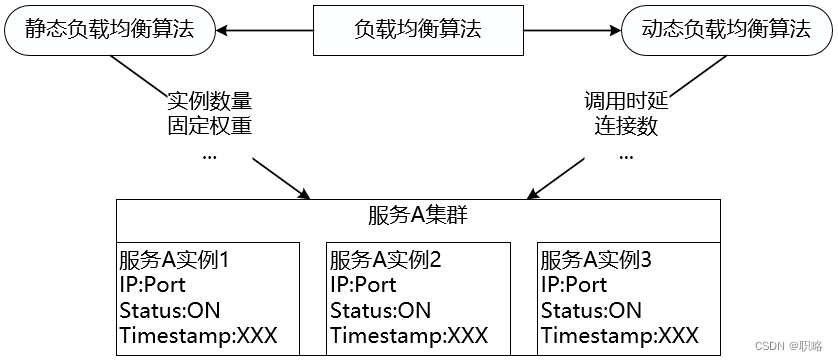
我們先來看靜態負載均衡算法,這類算法中具有代表性的是各種隨機(Random)和輪詢(Round Robin)算法。
所謂隨機算法,顧名思義,就是在集群中采用隨機算法進行負載均衡,其特點是負載均衡的結果相對比較平均。隨機算法實現也比較簡單,使用JDK自帶的Random工具類就可以用來指定服務實例的地址。例如,下圖中來自客戶端的9個請求分別被分發到了3個服務實例,分發的策略是隨機選擇一個服務實例,而不是一個固定的規則:

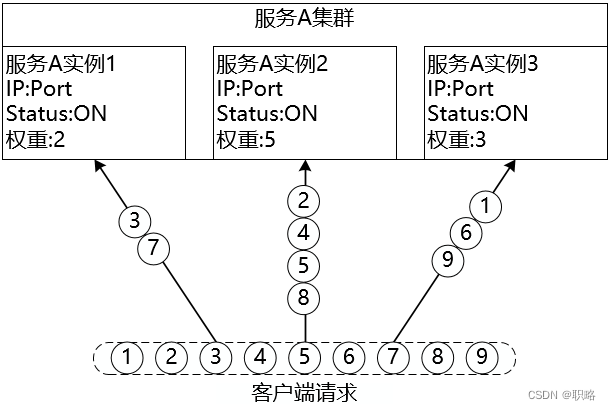
隨機算法的一種改進是加權隨機(Weight Random)算法,在集群中可能存在部分性能較優的服務器,為了使這些服務器響應更多請求,就可以通過加權隨機算法提升這些服務器的權重,例如下圖中實例2的權重設置的最大,所以對應的處理的請求數可能也就最多:
講完隨機算法,我們來看輪詢算法。輪循算法的一般實現流程為順序循環遍歷服務實例列表,到達上限之后重新歸零,繼續順序循環直到指定某一個服務實例。例如,在下圖中第一個請求被分發到實例1,第二個請求被分發到實例2,第三個請求被分發到實例3,然后第四個請求再次被分發到了實例1,以此類推。當然,輪詢的時候也可以為每個實例添加權重構成加權輪詢算法。

事實上,所有涉及到權重的靜態算法都可以轉變為動態算法,因為權重可以在運行過程中動態更新。例如動態輪詢算法中權重值會基于對各個服務器的持續監控并不斷更新。另外,基于服務器的實時性能分配請求是常見的動態策略。典型的動態算法包括最少連接數算法、服務調用時延算法等。
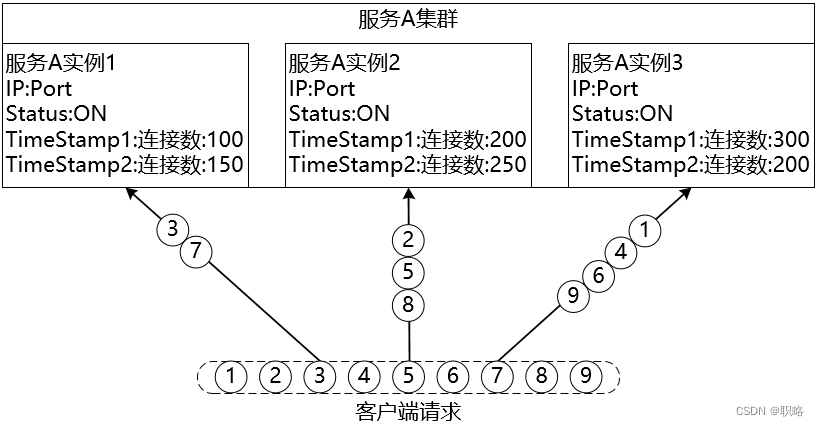
最少連接數(Least Connection)算法對傳入的請求根據每臺服務器當前所打開的連接數來分配,連接數最少的服務實例會優先響應請求。當執行分發策略時,會根據在某一個特定的時間點下服務實例的最新連接數來判斷是否執行客戶端請求。而在下一個時間點時,服務實例的連接數一般都會發生相應的變化,對應的請求處理也會做相應的調整,如下圖所示:
與最少連接數類似,服務調用時延(Service Invoke Delay)算法的判斷依據是服務實例的調用時延,根據服務調用和平均時延的差值動態調整權重。如下所示:

在現實中,有時候我們也會使用源地址哈希(Source IP Hash)算法,該算法實現請求IP粘滯(Sticky)連接,盡可能讓客戶端總是向同一服務實例發起調用服務。顯然,這是一種有狀態機制,我們也可以把它歸為動態負載均衡算法,效果如下:

我們也可以進一步來梳理一下主流微服務框架中所采用的負載均衡算法。在Spring Cloud中所實現的核心負載均衡算法包括隨機、輪詢、加權響應時間、并發量最小優先等,而Dubbo中則提供了隨機、輪詢、最少活躍調用數和一致性哈希等算法。可以看到,這兩個框架中都實現了我們介紹的一些主流算法,但也根據框架自身的特點提供了一些比較有特色的策略。當然,這兩個框架也都提供了開發入口供開發人員實現自定義的負載均衡算法。
最后,我們通過如下所示的一張思維導圖來總結今天的內容:












)







