

?博客主頁: https://blog.csdn.net/m0_63815035?type=blog
💗《博客內容》:.NET、Java.測試開發、Python、Android、Go、Node、Android前端小程序等相關領域知識
📢博客專欄: https://blog.csdn.net/m0_63815035/category_11954877.html
📢歡迎點贊 👍 收藏 ?留言 📝
📢本文為學習筆記資料,如有侵權,請聯系我刪除,疏漏之處還請指正🙉
📢大廈之成,非一木之材也;大海之闊,非一流之歸也?


目錄
- 前言
- 設計思想
- 1. MapReduce的基本概念
- 2. MapReduce的核心組件
- 3. MapReduce的工作流程
- 4. MapReduce的數據處理模型
- 5. Shuffle機制詳解
- 6. MapReduce的優化策略
- 7. MapReduce的應用場景
- 8. MapReduce與YARN的關系
前言
Hadoop是一個開源的分布式計算框架,主要用于處理和存儲大規模數據集。它的設計初衷是解決海量數據的存儲和計算問題,具有高容錯性、高擴展性和低成本等特點。下面詳細講解Hadoop的核心知識點:
設計思想

1. MapReduce的基本概念
- 定義:一種分布式計算模型,用于處理海量數據的并行計算
- 核心思想:將復雜的計算任務分解為Map(映射)和Reduce(歸約)兩個階段
- 優勢:
- 自動實現并行處理
- 提供容錯機制
- 處理PB級別的海量數據
- 適用于各種分布式計算場景
2. MapReduce的核心組件
- JobTracker:負責整個作業的調度和監控(Hadoop 1.x中,Hadoop 2.x中被YARN的ResourceManager替代)
- TaskTracker:運行在每個節點上,負責執行具體任務(Hadoop 1.x中,Hadoop 2.x中被YARN的NodeManager替代)
- Map Task:執行Map階段的任務
- Reduce Task:執行Reduce階段的任務
- InputSplit:輸入數據的邏輯分片,每個分片由一個Map Task處理
- Combiner:可選的本地Reduce操作,用于減少Map輸出的數據量
- Partitioner:決定Map輸出的鍵值對分配到哪個Reduce Task
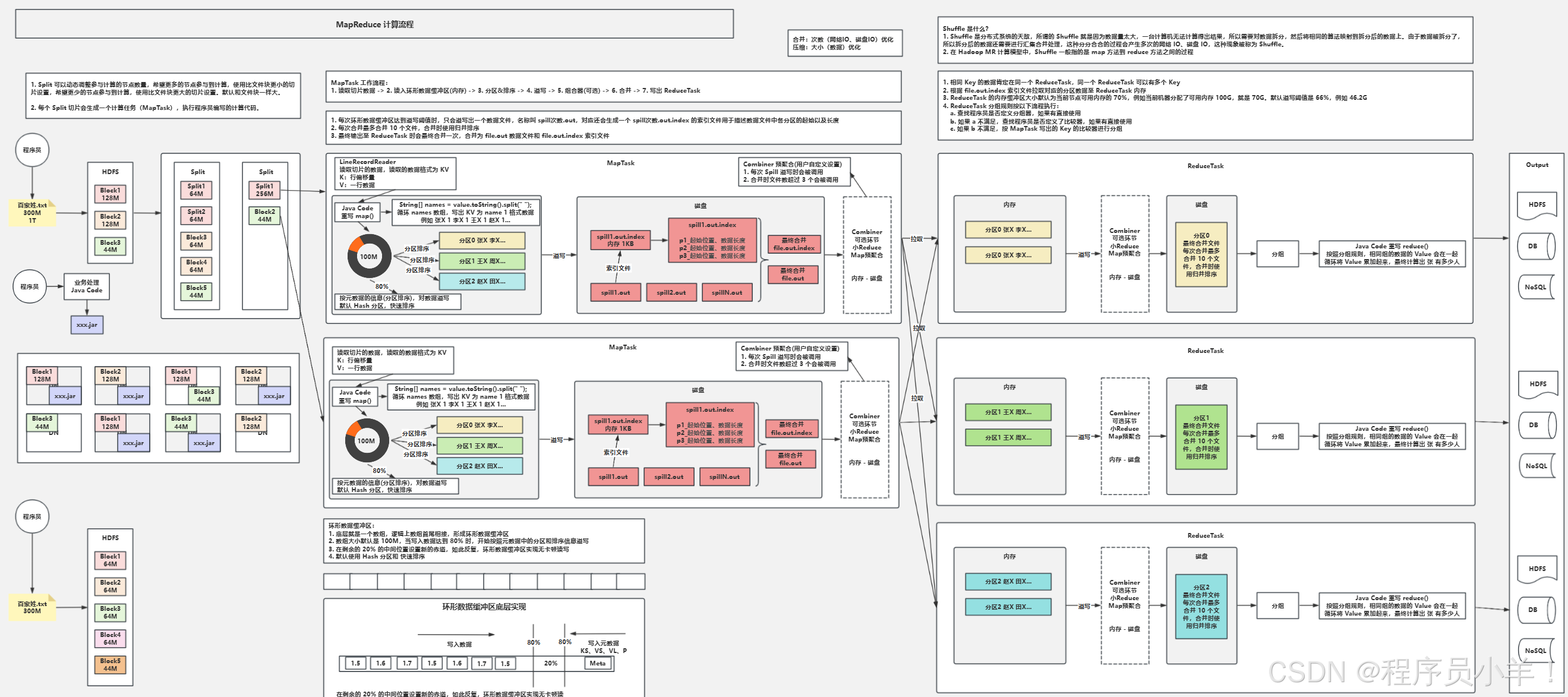
3. MapReduce的工作流程
-
輸入分片(InputSplit)
- 將輸入數據分割成多個InputSplit(通常與HDFS塊大小一致)
- 每個InputSplit由一個Map Task處理
-
Map階段
- 讀取InputSplit中的數據,解析成鍵值對(K1, V1)
- 對每個鍵值對執行map函數,生成中間鍵值對(K2, V2)
- 示例:計算單詞頻率時,將(“文檔1”, “hello world”)轉換為(“hello”, 1)、(“world”, 1)
-
Shuffle階段(核心)
- 分區(Partitioning):根據Partitioner將Map輸出分到不同的分區
- 排序(Sorting):對每個分區內的鍵值對按鍵排序
- 合并(Combining):可選操作,對排序后的結果進行本地合并,減少數據傳輸
- 歸并(Merging):將多個Map Task的輸出合并成一個有序的數據集
-
Reduce階段
- 讀取Shuffle后的有序數據
- 對相同鍵的value集合執行reduce函數,生成最終鍵值對(K3, V3)
- 示例:將多個(“hello”, 1)合并為(“hello”, 5)
-
輸出(Output)
- 將Reduce的輸出寫入到指定的存儲系統(通常是HDFS)
4. MapReduce的數據處理模型
-
鍵值對:MapReduce的所有數據處理都基于鍵值對(Key-Value Pair)
-
數據類型:所有的Key和Value都必須實現Writable接口,常用類型包括:
- Text:用于字符串
- IntWritable:用于整數
- LongWritable:用于長整數
- DoubleWritable:用于浮點數
-
函數定義:
- Map函數:map(K1, V1) → list(K2, V2)
- Reduce函數:reduce(K2, list(V2)) → list(K3, V3)
5. Shuffle機制詳解
Shuffle是MapReduce的核心,連接Map和Reduce階段,負責數據的傳輸和處理:
-
Map端的Shuffle
- 環形緩沖區:Map輸出先寫入內存緩沖區(默認100MB)
- 溢出寫(Spill):當緩沖區達到閾值(默認80%),將數據寫入磁盤
- 合并溢出文件:將多個溢出文件合并成一個有序文件
-
Reduce端的Shuffle
- 拉取數據(Fetch):Reduce Task從各個Map Task拉取屬于自己的分區數據
- 合并數據(Merge):將拉取的多個數據片段合并成一個大的有序數據集
- 分組(Grouping):將相同Key的Value合并成一個列表
6. MapReduce的優化策略
- 數據本地化:盡量將計算任務分配到數據所在的節點,減少網絡傳輸
- Combiner使用:在Map端進行本地聚合,減少Shuffle階段的數據量
- 合理設置Map和Reduce數量:根據數據大小和集群規模調整
- 壓縮:對Map輸出和中間數據進行壓縮,減少IO操作
- JVM重用:在TaskTracker上重用JVM,減少啟動開銷
- 調整緩沖區大小:根據內存情況調整Map階段的緩沖區大小
7. MapReduce的應用場景
- 日志分析:統計訪問量、用戶行為分析等
- 數據挖掘:關聯規則挖掘、聚類分析等
- 機器學習:訓練大規模數據集的模型
- 搜索引擎:網頁排序、關鍵詞統計等
- 數據轉換:數據格式轉換、數據清洗等
8. MapReduce與YARN的關系
在Hadoop 2.x中,MapReduce運行在YARN框架上:
- ResourceManager負責集群資源管理
- ApplicationMaster負責MapReduce作業的生命周期管理
- NodeManager負責單個節點的資源管理和任務執行
- Container為Map和Reduce任務提供計算資源
今天這篇文章就到這里了,大廈之成,非一木之材也;大海之闊,非一流之歸也。感謝大家觀看本文








—Dubbo Provider處理服務調用請求源碼)

![6-Django項目實戰-[dtoken]-用戶登錄模塊](http://pic.xiahunao.cn/6-Django項目實戰-[dtoken]-用戶登錄模塊)




![視覺圖像處理中級篇 [2]—— 外觀檢查 / 傷痕模式的原理與優化設置方法](http://pic.xiahunao.cn/視覺圖像處理中級篇 [2]—— 外觀檢查 / 傷痕模式的原理與優化設置方法)

戰士:序)


