關注gongzhonghao【CVPR頂會精選】
眾所周知,機器人因復雜環境適應性差、硬件部署成本高,對高效泛化一直需求迫切。再加上多傳感器協同難題、真實場景數據獲取不易,當下對遷移學習 + 機器人智能融合的研究也就更熱烈了。不過顯然,這方向的創新也基本圍繞以上問題展開,比如環境魯棒遷移、軟硬協同優化、跨場景知識適配、人機交互動態適配等等。如果想發論文,建議先從這些切入點著手。
今天小圖給大家精選3篇CVPR有機器人方向的論文,請注意查收!
論文一:Hierarchical Diffusion Policy?for Kinematics-Aware Multi-Task Robotic Manipulation
方法:
文章首先將操作策略分解為分層結構,包括用于預測下一個最佳末端執行器姿態的高層任務規劃代理和用于生成最優運動軌跡的低層目標條件擴散策略。接著,通過可微運動學將準確但缺乏運動學感知的末端執行器姿態軌跡提煉為運動學感知的關節位置軌跡,避免了逆運動學求解器常見的問題。最后,在多個挑戰性的操作任務中進行了實驗驗證,證明了所提方法在模擬和現實世界中的優越性能。
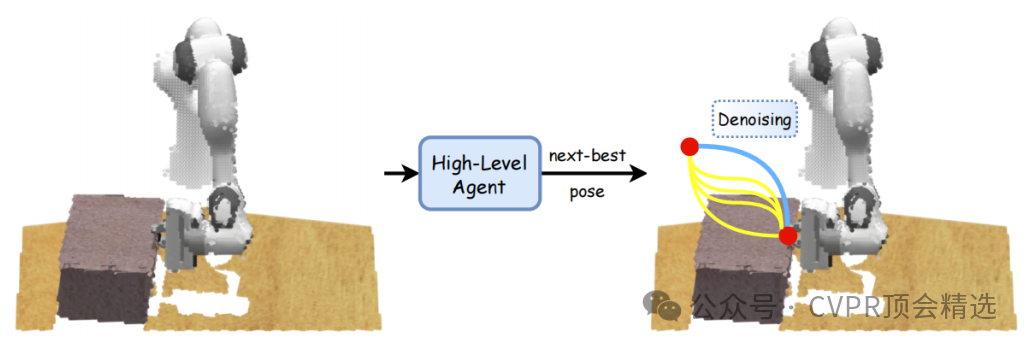
創新點:
提出了分層策略,使機器人能夠同時處理長時域任務規劃和精細的低層次動作。
引入了機器人運動學擴散器,通過可微運動學將末端執行器姿態軌跡轉換為關節位置軌跡,確保運動學約束。
在廣泛的模擬和現實世界任務中展示了顯著高于現有方法的成功率,證明了其在復雜操作任務中的有效性和泛化能力。

論文鏈接:
https://arxiv.org/abs/2403.03890
圖靈學術論文輔導
論文二:ManipLLM: Embodied Multimodal Large Language Model for Object-Centric Robotic Manipulation
方法:
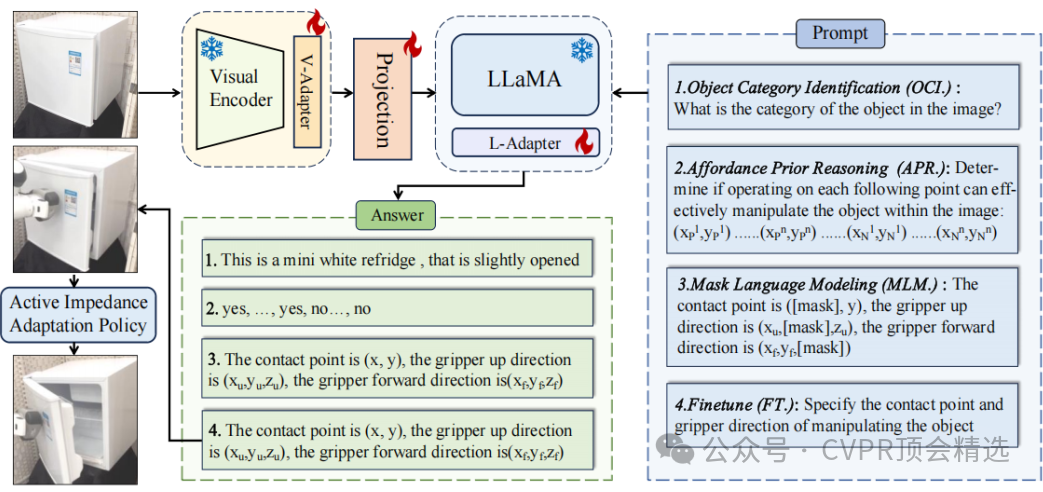
文章首先采用注入適配器的方式對MLLM進行微調,通過設計包括物體類別識別、操作先驗推理和操作感知姿態預測等任務,逐步引導模型學習物體的操作知識。在推理階段,利用鏈式思考策略,使模型按照訓練時的邏輯逐步生成末端執行器的初始姿態,并通過深度信息將其投影到三維空間。此外,為了適應現實世界的復雜情況,還設計了主動阻抗適應策略,通過力反饋調整運動方向,確保操作的平滑性和適應性。
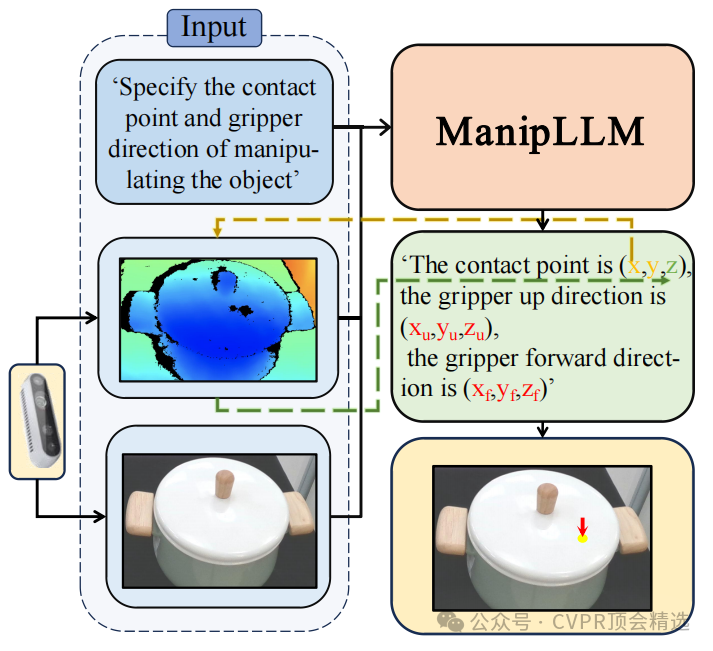
創新點:
提出了一種新穎的訓練范式,保留了MLLM的常識和推理能力,同時賦予其操作能力。
設計了鏈式思考推理策略,增強了模型的泛化能力和穩定性。
引入了主動阻抗適應策略,確保操作的平滑性和適應性,進一步提升了模型在復雜環境中的表現。
論文鏈接:
https://arxiv.org/abs/2312.16217
圖靈學術論文輔導
論文三:JRDB-PanoTrack: An Open-world Panoptic Segmentation and Tracking?Robotic Dataset in Crowded Human Environments
方法:
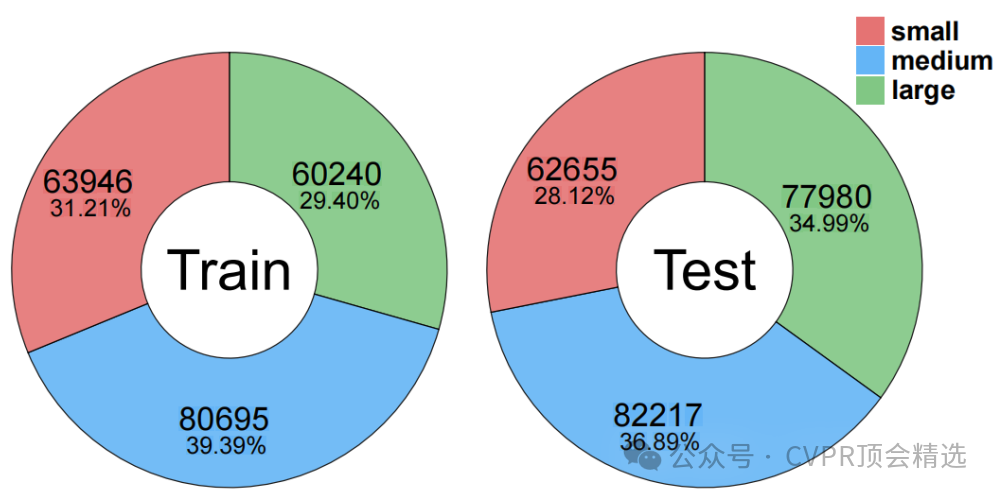
文章首先構建了一個包含20,000張圖像的數據集,這些圖像從54個視頻中以1Hz的頻率采樣,并提供了428K全景分割和27K跟蹤注釋。其次,引入了OSPA評估指標,用于更準確地評估多標簽場景下的分割和跟蹤性能。最后,基于該數據集,提出了閉世界和開放世界的全景分割與跟蹤基準測試,并對現有的先進方法進行了廣泛的評估,結果表明該數據集具有獨特的挑戰性,強調了開發更魯棒方法的必要性。

創新點:
提供了涵蓋室內外擁擠場景的多樣化數據,包括2D和3D同步數據模態,支持視覺和機器人應用。
提出了基于最優子模式匹配的評估指標,解決了現有評估方法的局限性。
設計了閉世界和開放世界的基準測試,包含多類別注釋和OSPA基礎評估指標,以促進泛化能力的研究。
論文鏈接:
https://arxiv.org/abs/2404.0168
本文選自gongzhonghao【CVPR頂會精選】

)









—Dubbo Provider處理服務調用請求源碼)

![6-Django項目實戰-[dtoken]-用戶登錄模塊](http://pic.xiahunao.cn/6-Django項目實戰-[dtoken]-用戶登錄模塊)




![視覺圖像處理中級篇 [2]—— 外觀檢查 / 傷痕模式的原理與優化設置方法](http://pic.xiahunao.cn/視覺圖像處理中級篇 [2]—— 外觀檢查 / 傷痕模式的原理與優化設置方法)
