目錄
1、DSL 概述
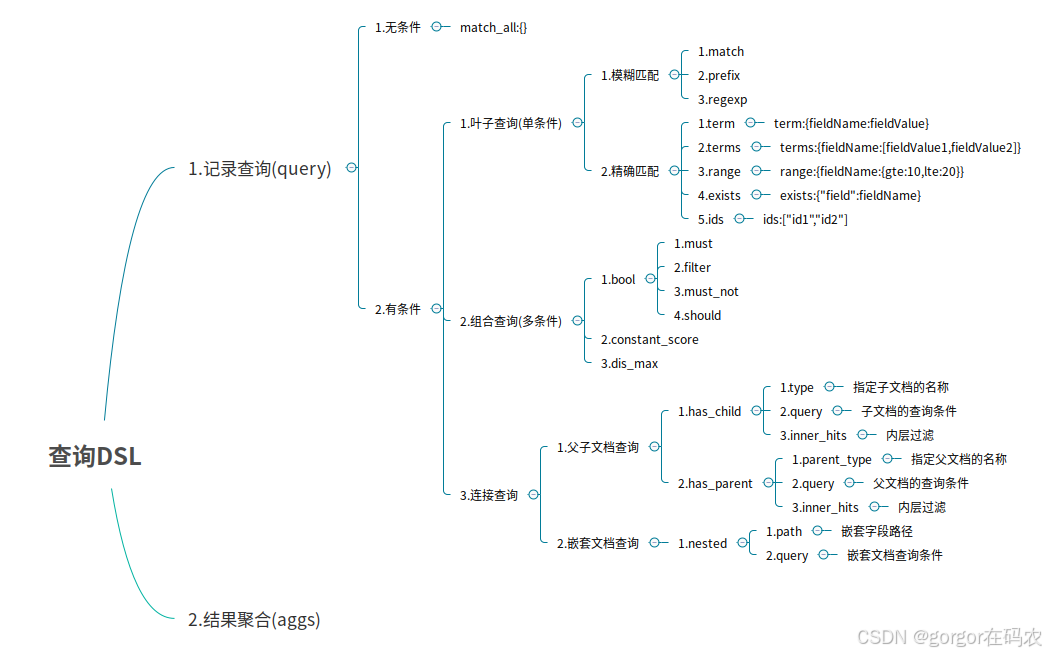
1.1 DSL按照查詢的結構層次劃分
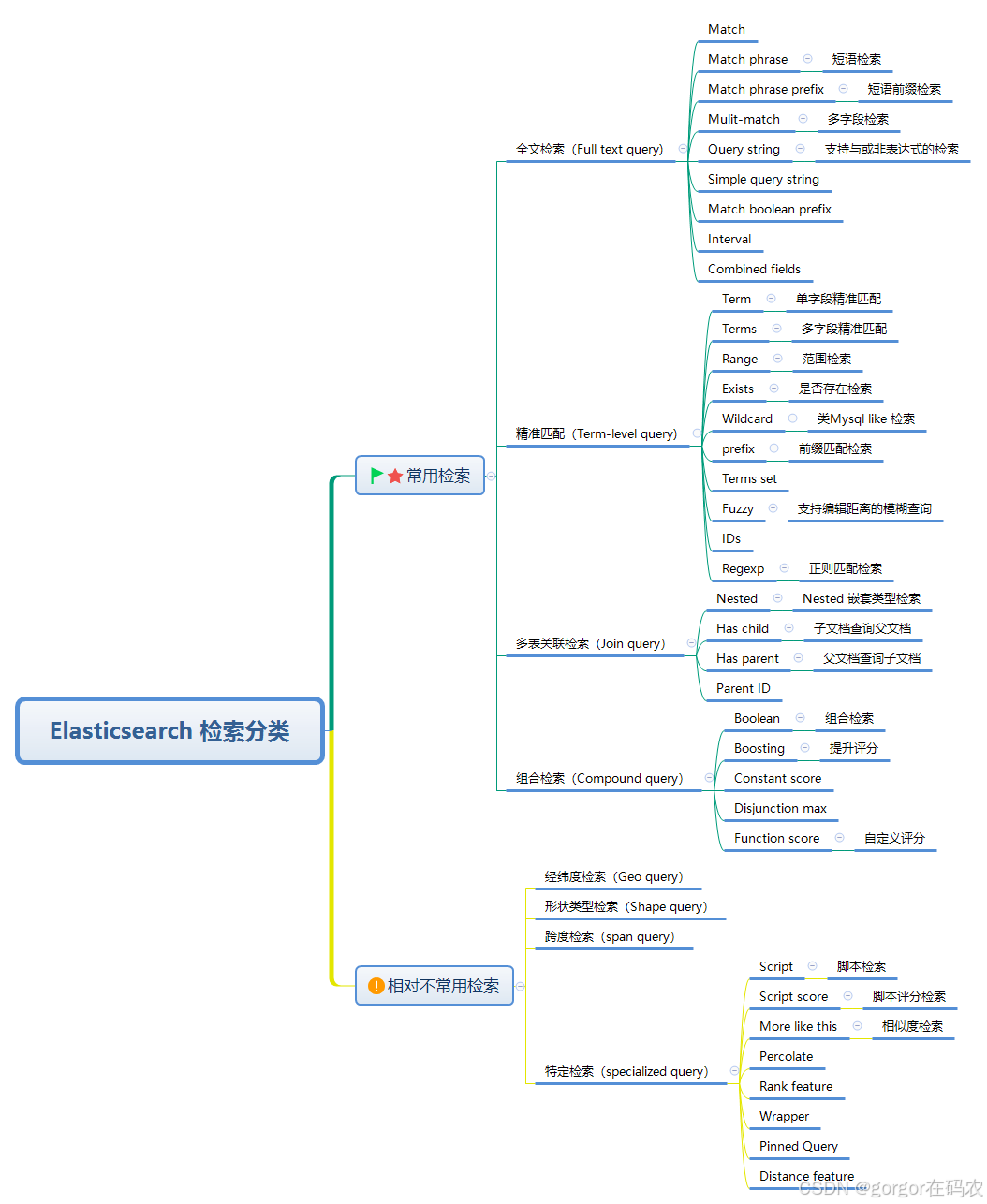
1.2 DSL按照檢索功能的用途和特性劃分
1.3 示例數據準備
2、match_all ——匹配所有文檔
3、精確匹配
3.1 term——單字段精確匹配查詢
3.2 terms——多值精確匹配
3.3 range——范圍查詢
3.4 exists——是否存在查詢
3.5 ids——根據一組id查詢
3.6 Prefix Query - 前綴匹配
3.7 wildcard——通配符匹配
3.8 regexp——正則匹配查詢
3.9 fuzzy——支持編輯距離的模糊查詢
3.10 term set——用于解決多值字段中的文檔匹配問題
4. 全文檢索
4.1 match——分詞查詢
4.2 multi_match——多字段查詢
4.3 match_phrase短語查詢
4.4 match_phrase_prefix——短語前綴匹配(嚴格順序)?
4.5?match_bool_prefix——短語前綴匹配(無順序)?
4.6?query_string——支持與或非表達式的查詢
4.7 simple_query_string——更安全的?query_string?替代品
4.8 interval——?高級文本匹配工具
5. bool query布爾查詢
6. highlight高亮
7. 地理空間位置查詢
8.?ElasticSearch8.x 向量檢索
1、DSL 概述
ES中提供了一種強大的檢索數據方式,這種檢索方式稱之為Query DSL(Domain Specified Language 領域專用語言) , Query DSL是利用Rest API傳遞JSON格式的請求體(RequestBody)數據與ES進行交互,這種方式的豐富查詢語法讓ES檢索變得更強大,更簡潔。
官方文檔: Query DSL | Elasticsearch Guide [8.14] | Elastic
1.1 DSL按照查詢的結構層次劃分
1.2 DSL按照檢索功能的用途和特性劃分
1.3 示例數據準備
DELETE /employee
PUT /employee
{"settings": {"number_of_shards": 1,"number_of_replicas": 1},"mappings": {"properties": {"name": {"type": "keyword"},"sex": {"type": "integer"},"age": {"type": "integer"},"address": {"type": "text","analyzer": "ik_max_word","fields": {"keyword": {"type": "keyword"}}},"remark": {"type": "text","analyzer": "ik_smart","fields": {"keyword": {"type": "keyword"}}}}}
}POST /employee/_bulk
{"index":{"_index":"employee","_id":"1"}}
{"name":"張三","sex":1,"age":25,"address":"廣州富星商業大廈","remark":"java developer"}
{"index":{"_index":"employee","_id":"2"}}
{"name":"李四","sex":1,"age":28,"address":"廣州塔","remark":"java assistant"}
{"index":{"_index":"employee","_id":"3"}}
{"name":"王五","sex":0,"age":26,"address":"番禺萬民城","remark":"php developer"}
{"index":{"_index":"employee","_id":"4"}}
{"name":"趙六","sex":0,"age":22,"address":"番禺南村萬博","remark":"python assistant"}
{"index":{"_index":"employee","_id":"5"}}
{"name":"拐腳七","sex":0,"age":19,"address":"江門萬達廣場","remark":"java architect assistant"}
{"index":{"_index":"employee","_id":"6"}}
{"name":"三八","sex":1,"age":32,"address":"臺山浪琴灣","remark":"java architect"}
{"index":{"_index":"employee","_id":"7"}}
{"name":"九天","sex":1,"age":35,"address":"廣州白云山","remark":"go architect"}
2、match_all ——匹配所有文檔
match_all查詢是一個特殊的查詢類型,它用于匹配索引中的所有文檔,而不考慮任何特定的查詢條件。
基本語法
GET /<your-index-name>/_search
{"query": {"match_all": {}}
}高級用法
例如,如果您想要返回索引中的前10個文檔,并且按照文檔的評分進行排序,您可以使用以下查詢:
GET /<your-index-name>/_search
{"query": {"match_all": {}},"size": 10,"sort": [{"_score": {"order": "desc"}}]
}- size 返回指定條數
_source的用法
#不查看源數據,僅查看元字段GET /<your-index-name>/_search
{"query": {"match_all": {}},"_source": false
}# 返回指定字段
GET /<your-index-name>/_search
{"query": {"match_all": {}},"_source": ["field1","field2"]
}#只看以obj.開頭的字段
GET /<your-index-name>/_search
{"query": {"match_all": {}},"_source": "obj.*"
}
from&size分頁查詢
GET /employee/_search
{"query": {"match_all": {}},"from": 0,"size": 5
}
sort 指定字段排序
# 根據age排序
GET /employee/_search
{"query": {"match_all": {}},"sort": [{"age": "desc"}]
}# 排序的同時進行分頁
GET /employee/_search
{"query": {"match_all": {}},"sort": [{"age": "desc"}],"from": 2,"size": 5
}
3、精確匹配
精確匹配是指的是搜索內容不經過文本分析直接用于文本匹配,這個過程類似于數據庫的SQL查詢,搜索的對象大多是索引的非text類型字段。此類檢索主要應用于結構化數據,如ID、狀態和標簽等。
3.1 term——單字段精確匹配查詢
term檢索主要應用于單字段精準匹配的場景。在實戰過程中,需要避免將term檢索應用于text類型的檢索。進一步說,term檢索針對的是非text類型,用于text類型時并不會報錯,但檢索結果一般會達不到預期。
基本語法
在Elasticsearch 8.x中,term查詢用于執行精確匹配查詢,它適用于未經過分詞處理的keyword字段類型。term查詢的基本語法如下:
GET /{index_name}/_search
{"query": {"term": {"{field.keyword}": {"value": "your_exact_value"}}}
}
這里的{index_name}是你要查詢的索引名稱,{field.keyword}是你要匹配的字段名稱,.keyword后綴表示該字段是一個keyword類型,用于存儲精確匹配的數據。"value"是你要精確匹配的值。
示例
對bool,日期,數字,結構化的文本可以利用term做精確匹配
# 查詢姓名為張三的員工信息GET /employee/_search
{"query":{"term": {"address": {"value": "番禺"}}}
}# 采用term精確查詢, 查詢字段映射類型為keyword
GET /employee/_search
{"query":{"term": {"address.keyword": {"value": "番禺萬民城"}}}
}
注意:最好不要在term查詢的字段中使用text字段,因為text字段會被分詞,這樣做既沒有意義,還很有可能什么也查不到。
term處理多值字段(數組)時,term查詢是包含,不是等于。
POST /people/_bulk
{"index":{"_id":1}}
{"name":"小明","interest":["跑步","籃球"]}
{"index":{"_id":2}}
{"name":"小紅","interest":["跳舞","畫畫"]}
{"index":{"_id":3}}
{"name":"小麗","interest":["跳舞","唱歌","跑步"]}POST /people/_search
{"query": {"term": {"interest.keyword": {"value": "跑步"}}}
}3.2 terms——多值精確匹配
terms檢索主要應用于多值精準匹配場景,它允許用戶在單個查詢中指定多個詞條來進行精確匹配。這種查詢方式適合從文檔中查找包含多個特定值的字段,例如篩選出具有多個特定標簽或狀態的項目。而terms檢索是針對未分析的字段進行精確匹配的,因此它在處理關鍵詞、數字、日期等結構化數據時表現良好。
基本語法
在Elasticsearch 8.x中,進行多字段精確匹配時,可以使用terms查詢。terms查詢允許你指定一個字段,并匹配該字段中的多個精確值。
基本語法如下:
GET /<index_name>/_search
{"query": {"terms": {"<field_name>": ["value1","value2","value3",...]}}
}
- <index_name>?是你想要查詢的索引名稱。
-
<field_name>?是你想要對其執行terms查詢的字段名。
-
方括號內的值列表是你希望在查詢中匹配的字段值。
示例
POST /employee/_search
{"query": {"terms": {"remark.keyword": ["java assistant", "java architect"]}}
}
3.3 range——范圍查詢
range檢索是Elasticsearch中一種針對指定字段值在給定范圍內的文檔的檢索類型。這種查詢適合對數字、日期或其他可排序數據類型的字段進行范圍篩選。range檢索支持多種比較操作符,如大于(gt)、大于等于(gte)、小于(lt)和小于等于(lte)等,可以實現靈活的區間查詢。
基本語法
在Elasticsearch 8.x版本中,range查詢的基本語法如下:
GET /<index_name>/_search
{"query": {"range": {"<field_name>": {"gte": <lower_bound>,"lte": <upper_bound>,"gt": <greater_than_bound>,"lt": <less_than_bound>}}}
}
- <index_name>?是你想要查詢的索引名稱。
- <field_name>?是你想要對其執行range查詢的字段名。
- gte 表示大于或等于(Greater Than or Equal)。
- lte 表示小于或等于(Less Than or Equal)。
- gt 表示嚴格大于(Greater Than)。
- lt 表示嚴格小于(Less Than)。
- <lower_bound>, <upper_bound>, <greater_than_bound>,<less_than_bound> 是指定的數值邊界。
- 查詢年齡在25到28的員工
POST /employee/_search
{"query": {"range": {"age": {"gte": 25,"lte": 28}}}
}3.4 exists——是否存在查詢
exists檢索在Elasticsearch中用于篩選具有特定字段值的文檔。這種查詢類型適用于檢查文檔中是否存在某個字段,或者該字段是否包含非空值。通過使用exists檢索,你可以有效地過濾掉缺少關鍵信息的文檔,從而專注于包含所需數據的結果。應用場景包括但不限于數據完整性檢查、查詢特定屬性的文檔以及對可選字段進行篩選等。
基本語法
GET /<index_name>/_search
{"query": {"exists": {"field": "missing_field"}}
}
示例
查詢索引庫中存在remark字段的文檔
GET /employee/_search
{"query": {"exists": {"field": "remark"}}
}3.5 ids——根據一組id查詢
IDs檢索也是一種常用的Elasticsearch查詢方法,它允許我們基于給定的ID組快速召回相關數據,從而實現高效的文檔檢索。
基本語法
在Elasticsearch 8.x中,ids查詢用于返回具有指定ID列表的文檔。這個查詢是檢索特定文檔的有效方式,特別是當你已經知道具體的文檔ID時。
基本語法如下:
GET /<index_name>/_search
{"query": {"ids": {"values": ["id1", "id2", "id3", ...]}}
}
示例
GET /employee/_search
{"query": {"ids": {"values": [1,2]}}
}3.6 Prefix Query - 前綴匹配
這種查詢不會對搜索字符串進行分詞處理,用戶輸入的前綴將直接作為匹配條件。
默認情況下,前綴查詢不會計算相關性分數,而是返回所有匹配的文檔,并將它們的分數統一設為1。
實現原理
通過遍歷所有倒排索引,檢查每個詞項是否以指定前綴開頭來實現匹配。
基本用法
在Elasticsearch 8.x中,prefix查詢用于查找指定字段中以特定前綴開頭的文檔,常用于自動補全或搜索場景,特別是當用戶輸入的內容可能是更長文本的起始部分時。基礎語法如下:
GET /<index_name>/_search
{"query": {"prefix": {"your_field_name": {"value": "your_prefix_string"}}}
}3.7 wildcard——通配符匹配
Elasticsearch的wildcard檢索是一種支持通配符匹配的查詢方式,允許使用通配符表達式來匹配文檔字段值。主要支持兩種通配符:
- 星號(*):匹配零個或多個任意字符
- 問號(?):匹配單個任意字符
這種檢索方式特別適合對部分已知內容的文本字段進行模糊匹配,比如文件名、產品編號等具有特定格式的字段。使用時需注意:通配符查詢可能帶來較大計算開銷,在數據量大的場景中應謹慎使用。
基本語法如下:
GET /<index_name>/_search
{"query": {"wildcard": {"your_field_name": {"value": "your_search_pattern"}}}
}示例:
GET /employee/_search
{"query": {"wildcard": {"address.keyword": {"value": "*萬*廣場"}}}
}
3.8 regexp——正則匹配查詢
regexp檢索是一種基于正則表達式的檢索方法。雖然該檢索方式的功能強大,但建議在非必要情況下避免使用,以保持查詢性能的高效和穩定。
基本語法
在Elasticsearch 8.x中,regexp 查詢用于在字段中執行正則表達式匹配。這個查詢可以用來搜索滿足特定模式的文本,并且比 wildcard 查詢更加靈活和強大。
基本語法如下:
GET /<index_name>/_search
{"query": {"regexp": {"your_field_name": {"value": "your_search_pattern"}}}
}示例
GET /employee/_search
{"query": {"regexp": {"remark": {"value": "java.*"}}}
}
3.9 fuzzy——支持編輯距離的模糊查詢
fuzzy檢索是一種強大的搜索功能,它能夠在用戶輸入內容存在拼寫錯誤或上下文不一致時,仍然返回與搜索詞相似的文檔。通過使用編輯距離算法來度量輸入詞與文檔中詞條的相似程度,模糊查詢在保證搜索結果相關性的同時,有效地提高了搜索容錯能力。
編輯距離是指從一個單詞轉換到另一個單詞需要編輯單字符的次數。如中文集團到中威集團編輯距離就是1,只需要修改一個字符;如果fuzziness值在這里設置成2,會把編輯距離為2的東東集團也查出來。
基本語法
基本語法如下:
-
GET /<index_name>/_search {"query": {"fuzzy": {"your_field": {"value": "search_term","fuzziness": "AUTO","prefix_length": 1}}} } - fuzziness參數用于編輯距離的設置,其默認值為AUTO,支持的數值為[0,1,2]。如果值設置越界會報錯。
- prefix_length: 搜索詞的前綴長度,在此長度內不會應用模糊匹配。默認是0,即整個詞都會被模糊匹配。
示例
GET /employee/_search
{"query": {"fuzzy": {"address": {"value": "大樓","fuzziness": 1 }}}
}
3.10 term set——用于解決多值字段中的文檔匹配問題
terms_set 查詢是 Elasticsearch 針對多值字段(通常為 keyword 類型)設計的一種特殊查詢,專門用于處理基于特定術語集合的匹配計數需求。它有效解決了傳統查詢在多值場景下難以處理的復雜匹配問題。
傳統查詢存在以下局限性:
-
terms查詢:執行邏輯 OR 運算。例如{"terms": {"tags": ["search", "database"]}}會匹配包含 "search" 或 "database" 中任意一個術語的文檔。 -
bool + must(AND) 查詢:執行邏輯 AND 運算。例如{"bool": {"must": [{"term": {"tags": "search"}}, {"term": {"tags": "database"}}]}}會匹配同時包含 "search" 和 "database" 的文檔。
但當需要實現更靈活的匹配條件時,傳統查詢就顯得力不從心,例如:
- 匹配包含 ['elasticsearch', 'search', 'database', 'nosql'] 中至少 2 個術語的文檔
- 查找擁有 ['read', 'write', 'delete'] 全部權限的用戶(即 K=集合大小)
- 篩選出具有 ['red', 'blue', 'green'] 中恰好 1 個顏色屬性的商品
使用純 bool 查詢實現"至少 K 個"的匹配條件會導致查詢變得極其復雜且低效(需要組合所有可能的 C(n,k) 情況)。terms_set 查詢正是為優雅解決這類問題而設計的解決方案。
基本語法
terms_set可以檢索至少匹配一定數量給定詞項的文檔,其中匹配的數量可以是固定值,也可以是基于另一個字段的動態值
基本語法如下
GET /<index_name>/_search
{"query": {"terms_set": {"<field_name>": {"terms": ["<term1>", "<term2>", ...],"minimum_should_match_field": "<minimum_should_match_field_name>" or"minimum_should_match_script": {"source": "<script>"}}}}
}
- <index_name>: 指定要查詢的字段名,這個字段通常是一個多值字段。
- terms: 提供一組詞項,用于在指定字段中進行匹配。
- minimum_should_match_field: 指定一個包含匹配數量的字段名,其值應用作要匹配的最少術語數,以便返回文檔。
- minimum_should_match_script: 提供一個自定義腳本,用于動態計算匹配數量。如果需要動態設置匹配所需的術語數,這個參數將非常有用。
示例
假設我們有一個電影數據庫,其中每部電影都有多個標簽。現在,我們希望找到同時具有一定數量的給定標簽的電影。
測試數據
PUT /movies
{"mappings": {"properties": {"title": {"type": "text"},"tags": {"type": "keyword"},"tags_count": {"type": "integer"}}}
}POST /movies/_bulk
{"index":{"_id":1}}
{"title":"電影1", "tags":["喜劇","動作","科幻"], "tags_count":3}
{"index":{"_id":2}}
{"title":"電影2", "tags":["喜劇","愛情","家庭"], "tags_count":3}
{"index":{"_id":3}}
{"title":"電影3", "tags":["動作","科幻","家庭"], "tags_count":3}- 使用固定數量的term進行匹配
GET /movies/_search
{"query": {"terms_set": {"tags": {"terms": ["喜劇","動作","科幻"],"minimum_should_match": 2}}}
}GET /movies/_search
{"query": {"terms_set": {"tags": {"terms": ["喜劇","動作","科幻"],"minimum_should_match_script": {"source": "2"}}}}
}- 使用動態計算的term數量進行匹配
GET /movies/_search
{"query": {"terms_set": {"tags": {"terms": ["喜劇","動作","科幻"],"minimum_should_match_field": "tags_count"}}}
}GET /movies/_search
{"query": {"terms_set": {"tags": {"terms": ["喜劇","動作","科幻"],"minimum_should_match_script": {"source": "doc['tags_count'].value*0.7"}}}}
}4. 全文檢索
全文檢索查詢旨在基于相關性搜索和匹配文本數據。這些查詢會對輸入的文本進行分析,將其拆分為詞項(單個單詞),并執行諸如分詞、詞干處理和標準化等操作。此類檢索主要應用于非結構化文本數據,如文章和評論等。
4.1 match——分詞查詢
match查詢是一種全文搜索查詢,它使用分析器將查詢字符串分解成單獨的詞條,并在倒排索引中搜索這些詞條。match查詢適用于文本字段,并且可以通過多種參數來調整搜索行為。
對于match查詢,其底層邏輯的概述:
1.分詞:首先,輸入的查詢文本會被分詞器進行分詞。分詞器會將文本拆分成一個個詞項(terms),如單詞、短語或特定字符。分詞器通常根據特定的語言規則和配置進行操作。
2.匹配計算:一旦查詢被分詞,ES將根據查詢的類型和參數計算文檔與查詢的匹配度。對于match查詢,ES將比較查詢的詞項與倒排索引中的詞項,并計算文檔的相關性得分。相關性得分衡量了文檔與查詢的匹配程度。
3.結果返回:根據相關性得分,ES將返回最匹配的文檔作為搜索結果。搜索結果通常按照相關性得分進行排序,以便最相關的文檔排在前面。
基本語法
一個基本的match查詢的結構如下:
GET /<index_name>/_search
{"query": {"match": {"<field_name>": "<query_string>"}}
}- <index_name>?是你要搜索的索引名稱。
- <field_name>?是你要在其中搜索的字段名稱。
- <query_string>?是你要搜索的文本字符串。
示例
#分詞后or的效果
GET /employee/_search
{"query": {"match": {"address": "番禺萬民城"}}
}# 分詞后 and的效果
GET /employee/_search
{"query": {"match": {"address": {"query": "番禺萬民城","operator": "and"}}}
}
在match中的應用: 當operator參數設置為or時,minnum_should_match參數用來控制匹配的分詞的最少數量。
# 最少匹配廣州,塔兩個詞
GET /employee/_search
{"query": {"match": {"address": {"query": "廣州塔","minimum_should_match": 2}}}
}4.2 multi_match——多字段查詢
multi_match查詢在Elasticsearch中用于在多個字段上執行相同的搜索操作。它可以接受一個查詢字符串,并在指定的字段集合中搜索這個字符串。multi_match查詢提供了靈活的匹配類型和操作符選項,以便根據不同的搜索需求調整搜索行為。
基本語法
一個基本的multi_match查詢的結構如下:
GET /<index_name>/_search
{"query": {"multi_match": {"query": "<query_string>","fields": ["<field1>", "<field2>", ...]}}
}- <index_name>?是你要搜索的索引名稱。
- <query_string>?是你要在多個字段中搜索的字符串。
- <field1>?,<field2> , ... 是你要搜索的字段列表。
示例
GET /employee/_search
{"query": {"multi_match": {"query": "江門java","fields": ["address","remark"]}}
}4.3 match_phrase短語查詢
match_phrase查詢在Elasticsearch中用于執行短語搜索,它不僅匹配整個短語,而且還考慮了短語中各個詞的順序和位置。這種查詢類型對于搜索精確短語非常有用,尤其是在用戶輸入的查詢與文檔中的文本表達方式需要嚴格匹配時。
基本語法
一個基本的match_phrase查詢的結構如下:
GET /<index_name>/_search
{"query": {"match_phrase": {"<field_name>": {"query": "<phrase>"}}}
}- <index name>是你要搜索的索引名稱。
- <field name>是你要在其中搜索短語的字段名稱。
- <phrase>是你要搜索的短語。
match_phrase查詢還支持一個可選的slop參數,用于指定短語中詞之間可以出現的最大位移數量。默認值為0,意味著短語中的詞必須嚴格按照順序出現。如果設置了非零的slop值,則允許短語中的某些詞在一定范圍內錯位。
GET /employee/_search
{"query": {"match_phrase": {"address": "廣州白云"}}
}GET /employee/_search
{"query": {"match_phrase": {"address": "廣州白云山"}}
}示例
GET /employee/_search
{"query": {"match_phrase": {"address": "廣州白云山"}}
}GET /employee/_search
{"query": {"match_phrase": {"address": "廣州白云"}}
}
思考:為什么查詢廣州白云山有數據,廣州白云沒有數據?
分析原因:
先查看廣州白云山公園分詞結果,可以知道廣州和白云不是相鄰的詞條,中間會隔一個白云山,而match_phrase匹配的是相鄰的詞條,所以查詢廣州白云山有結果,但查詢廣州白云沒有結果。
POST _analyze
{"analyzer":"ik_max_word","text":"廣州白云山"
}
#結果
{"tokens" : [{"token" : "廣州","start_offset" : 0,"end_offset" : 2,"type" : "CN_WORD","position" : 0},{"token" : "白云山","start_offset" : 2,"end_offset" : 5,"type" : "CN_WORD","position" : 1},{"token" : "白云","start_offset" : 2,"end_offset" : 4,"type" : "CN_WORD","position" : 2},{"token" : "云山","start_offset" : 3,"end_offset" : 5,"type" : "CN_WORD","position" : 3}]
}如何解決詞條間隔的問題?可以借助slop參數,slop參數告訴match_phrase查詢詞條能夠相隔多遠時仍然將文檔視為匹配。
#廣州云山分詞后相隔為2,可以匹配到結果
GET /employee/_search
{"query": {"match_phrase": {"address": {"query": "廣州云山","slop": 2} }}
}
4.4 match_phrase_prefix——短語前綴匹配(嚴格順序)?
場景:自動補全、搜索框實時提示
特點:
-
最后一個詞做前綴匹配
-
需控制?
max_expansions?防性能問題
基本語法
GET /<index name>/_search
{"query": {"match_phrase_prefix": {"<field name>": {"query": "<phrase>", // 必需參數"max_expansions": 50, // 可選參數"slop": 2, // 可選參數"analyzer": "<your_analyzer>" // 可選參數}}}
}- <index name>是你要搜索的索引名稱。
- <field name>是你要在其中搜索短語的字段名稱。
- <phrase>是你要搜索的短語。
- <your_analyzer>?指定分詞器處理查詢文本
-
max_expansions?限制最后一個詞的前綴擴展數量-
示例:
"max_expansions": 10
搜索 "elast" 時,最多考慮 10 個以 "elast" 開頭的詞(如 elastic, elasticity, elastomer...)
-
slop?允許詞項之間的間隔距離
示例
GET /employee/_search
{"query": {"match_phrase_prefix": {"address": {"query": "廣", // 匹配 "廣" 等"max_expansions": 2 // 限制擴展詞數量}}}
}4.5?match_bool_prefix——短語前綴匹配(無順序)?
match_bool_prefix查詢的工作原理如下:
首先通過分詞器將輸入文本拆分為多個詞項(tokens),然后對除最后一個詞項外的所有詞項執行精確匹配(term查詢),僅對最后一個詞項進行前綴匹配(prefix查詢)。
該查詢本質上構建了一個布爾查詢結構,其中前面的詞項都以must條件進行精確匹配,而最后一個詞項則采用前綴匹配方式。
基本語法
GET /<index name>/_search
{"query": {"match_bool_prefix": {"<field name>": {"query": "<phrase>", // 必需參數"analyzer": "<your_analyzer>", // 可選"minimum_should_match": 2, // 可選"fuzziness": "AUTO", // 可選(僅對最后詞項生效)"boost": 2.0 // 可選}}}
}
- <index name>是你要搜索的索引名稱。
- <field name>是你要在其中搜索短語的字段名稱。
- <phrase>是你要搜索的短語。
- <your_analyzer>?指定分詞器處理查詢文本
minimum_should_match?必須匹配的最少詞項數?-
配置值類型
類型 示例 說明 整數 2必須匹配至少2個詞項 百分比 75%匹配 ≥ 總詞項數×75% 的詞項 組合 3<90%詞項≤3時全匹配,>3時匹配90% 動態 2<-1總詞項數-1(至少匹配N-1個)
-
- fuzziness?對最后一個詞項啟用模糊匹配(前面詞項仍精確匹配)
-
配置值類型
值 說明 0關閉模糊匹配(默認) 1允許1個字符的編輯距離 2允許2個字符的編輯距離 AUTO基于詞長自動選擇:
- 1-2字符:0
- 3-5字符:1
>5字符:2
-
- boost?查詢權重
示例
# 匹配要求:
#必須滿足以下任一組合:
#1. "廣州" + "天河*"(完整匹配)
#2. 僅當詞項>2時允許75%匹配
GET /employee/_search
{"query": {"match_bool_prefix": {"address": {"query": "廣州 天河", "minimum_should_match": "2<75%", // 動態匹配閾值(核心參數)"fuzziness": 1, // 最后詞項模糊匹配"boost": 1.5 // 適度權重提升}}}
}匹配結果示例
| 文檔地址 | 匹配詞項 | 是否匹配 | 原因 |
|---|---|---|---|
| "廣州天河區體育西路" | 廣州 + 天河*(天河區) | ? | 滿足2個詞項 |
| "廣州市天河軟件園" | 廣州 + 天河*(天河) | ? | 滿足2個詞項 |
| "廣州番禺區" | 廣州(缺少天河*) | ? | 只匹配1個詞項 <2 |
| "北京天河科技大廈" | 天河*(但缺少廣州) | ? | 只匹配1個詞項 <2 |
| "廣州白云機場T3航站樓" | 廣州(缺少天河*) | ? | 只匹配1個詞項 <2 |
4.6?query_string——支持與或非表達式的查詢
query_string查詢是一種靈活的查詢類型,它允許使用Lucene查詢語法來構建復雜的搜索查詢。這種查詢類型支持多種邏輯運算符,包括與(AND)、或(OR)和非(NOT),以及通配符、模糊搜索和正則表達式等功能。query_string查詢可以在單個或多個字段上進行搜索,并且可以處理復雜的查詢邏輯。
應用場景包括高級搜索、數據分析和報表等,適合處理需滿足特定需求、要求支持與或非表達式的復雜查詢任務,通常用于專業領域或需要高級查詢功能的應用中。
基本語法
query_string查詢的基本語法結構如下:
GET /<index_name>/_search
{"query": {"query_string": {"query": "<your_query_string>","default_field": "<field_name>"}}
}- <your_query_string>是查詢邏輯,可以包含上述提到的邏輯運算符和通配符等
- <field name>是默認搜索字段,如果省略則會搜索所有可索引字段.
- 未指定字段查詢
# AND 要求大寫
GET /employee/_search
{"query": {"query_string": {"query": "趙六 AND 南村萬博"}}
}- 指定單個字段查詢
GET /employee/_search
{"query": {"query_string": {"default_field": "address","query": "白云山 OR 南村"}}
}注意: 查詢字段分詞就將查詢條件分詞查詢,查詢字段不分詞將查詢條件不分詞查詢
- 指定多個字段查詢
GET /employee/_search
{"query": {"query_string": {"fields": ["name","address"],"query": "張三 OR (番禺 AND 王五)"}}
}4.7 simple_query_string——更安全的?query_string?替代品
與Query String類似,但具有更強的容錯性:
- 自動忽略語法錯誤
- 僅支持部分查詢語法
- 不支持完整的
AND/OR/NOT邏輯(這些關鍵詞會被視為普通字符串)
支持簡化的邏輯運算符:
+代替AND|代替OR-代替NOT
生產環境建議:
優先使用simple_query_string而非query_string,因其:
- 語法更寬松
- 可容忍輸入錯誤
- 避免因語法問題導致查詢失敗
基礎語法結構示例:
GET /<index_name>/_search
{"query": {"simple_query_string": {"query": "<query_string>","fields": ["<field1>", "<field2>", ...],"default_operator": "OR" // 或 "AND"}}
}- ?<query_string>是要搜索的査詢表達式。
- <field1>,<field2>,.. 是搜索可以在其中進行的字段列表
- default operator 定義了查詢字符串中未指定操作符時的默認邏輯運算符,可以是"OR"或"AND"。
示例
#simple_query_string 默認的operator是OR
GET /employee/_search
{"query": {"simple_query_string": {"fields": ["name","address"],"query": "廣州白云","default_operator": "AND"}}
}GET /employee/_search
{"query": {"simple_query_string": {"fields": ["name","address"],"query": "廣州 + 白云"}}
}- 精確不對待檢索文本進行分詞處理,而是將整個文本視為一個完整的詞條進行匹配。
- 全文檢索則需要對文本進行分詞處理。在分詞后,每個詞條將單獨進行檢索,并通過布爾邏輯(如與、或、非等)進行組合檢索,以找到最相關的結果。
4.8 interval——?高級文本匹配工具
interval?查詢是 Elasticsearch 提供的一種高級文本匹配工具,它允許您通過定義精確的規則來控制查詢詞項在文檔中的出現順序、間隔和關系。這種查詢特別適用于需要精細控制匹配模式的場景,如法律文本、專利搜索、歌詞匹配等。
基本語法結構
GET /your_index/_search
{"query": {"intervals": {"<FIELD_NAME>": {"<RULE_TYPE>": {// 規則特定參數"intervals": [ // 子規則數組{ ... },{ ... }],// 通用參數"ordered": true|false,"max_gaps": 整數,"filter": { ... }}}}}
}核心概念解釋
1. 規則類型 (Rule Types)
| 規則類型 | 描述 | 使用場景 |
|---|---|---|
|
| 必須匹配所有子規則 | 嚴格的多條件匹配 |
|
| 匹配任意子規則 | 同義詞或可選條件 |
|
| 匹配單個詞項/短語 | 基礎詞項匹配 |
|
| 匹配前綴 | 自動補全場景 |
|
| 通配符匹配 | 模糊匹配 |
|
| 模糊匹配 | 容錯拼寫錯誤 |
2. 通用參數
| 參數 | 類型 | 默認值 | 描述 |
|---|---|---|---|
|
| boolean | false | 是否要求子規則按順序匹配 |
|
| integer | -1 (無限制) | 允許的最大間隔詞數 |
|
| object | - | 對匹配結果應用額外過濾 |
詳細語法解釋
基礎匹配規則 (match)
{"match": {"query": "搜索詞","analyzer": "分詞器","use_field": "字段名"}
}組合規則 (all_of/any_of)
{"all_of": {"ordered": true,"max_gaps": 2,"intervals": [{ "match": { "query": "詞1" } },{ "match": { "query": "詞2" } }]}
}實用示例解析
示例 1:精確法律條款匹配
匹配"版權"后跟"侵權"或"違反",最后是"處罰",最多允許5個詞間隔
GET /legal_docs/_search
{"query": {"intervals": {"content": {"all_of": {"ordered": true,"max_gaps": 5,"intervals": [{ "match": { "query": "版權" } },{ "any_of": {"intervals": [{ "match": { "query": "侵權" } },{ "match": { "query": "違反" } }]}},{ "match": { "query": "處罰" } }]}}}}
}示例 2:歌詞匹配(允許詞序變化)
匹配"月亮"和"代表",順序不限,中間最多3個詞
GET /song_lyrics/_search
{"query": {"intervals": {"lyrics": {"all_of": {"ordered": false, // 不要求順序"max_gaps": 3,"intervals": [{ "match": { "query": "月亮" } },{ "match": { "query": "代表" } }]}}}}
}示例 3:專利搜索(帶同義詞和模糊匹配)
匹配"人工智能"后跟"醫療"或"健康",然后是"診斷"的模糊匹配
GET /patents/_search
{"query": {"intervals": {"abstract": {"all_of": {"ordered": true,"intervals": [{ "match": { "query": "人工智能" } },{ "any_of": {"intervals": [{ "match": { "query": "醫療" } },{ "match": { "query": "健康" } }]}},{ "fuzzy": {"term": "診斷","fuzziness": 1, // 允許1個字符差異"prefix_length": 1 // 要求首字符相同}}]}}}}
}示例 4:排除特定內容的匹配
匹配"云服務"后跟"安全",但不包含"漏洞"的內容
GET /tech_articles/_search
{"query": {"intervals": {"content": {"all_of": {"ordered": true,"intervals": [{ "match": { "query": "云服務" } },{ "match": { "query": "安全" } }],"filter": {"not_containing": {"match": {"query": "漏洞"}}}}}}}
}5. bool query布爾查詢
布爾查詢允許通過布爾邏輯條件組合多個查詢語句,僅返回符合整體條件的文檔。布爾條件可包含兩種不同上下文:
-
搜索上下文(query context)
在此上下文中,Elasticsearch會計算文檔與查詢條件的相關度得分。該計算涉及復雜公式,會產生一定性能開銷。適合需要文本分析的全文檢索查詢。 -
過濾上下文(filter context)
在此上下文中,Elasticsearch僅判斷文檔是否匹配查詢條件(如Term query驗證值是否一致,Range query檢查數值區間等)。過濾查詢無需計算相關度得分,且可利用緩存提升查詢速度,適合大多數術語級查詢。
布爾查詢支持四種組合類型:
| 類型 | 說明 |
| must | 可包含多個查詢條件,每個條件均滿足的文檔才能被搜索到,每次查詢需要計算相關度得分,屬于搜索上下文? |
| should | 可包含多個查詢條件,不存在must和fiter條件時,至少要滿足多個查詢條件中的一個,文檔才能被搜索到,否則需滿足的條件數量不受限制,匹配到的查詢越多相關度越高,也屬于搜索上下文? |
| filter | 可包含多個過濾條件,每個條件均滿足的文檔才能被搜索到,每個過濾條件不計算相關度得分,結果在一定條件下會被緩存, 屬于過濾上下文? |
| must_not | 可包含多個過濾條件,每個條件均不滿足的文檔才能被搜索到,每個過濾條件不計算相關度得分,結果在一定條件下會被緩存, 屬于過濾上下文? |
示例
PUT /books
{"settings": {"number_of_replicas": 1,"number_of_shards": 1},"mappings": {"properties": {"id": {"type": "long"},"title": {"type": "text","analyzer": "ik_max_word"},"language": {"type": "keyword"},"author": {"type": "keyword"},"price": {"type": "double"},"publish_time": {"type": "date","format": "yyyy-MM-dd"},"description": {"type": "text","analyzer": "ik_max_word"}}}
}POST /_bulk
{"index":{"_index":"books","_id":"1"}}
{"id":"1", "title":"Java編程思想", "language":"java", "author":"Bruce Eckel", "price":70.20, "publish_time":"2007-10-01", "description":"Java學習必讀經典,殿堂級著作!贏得了全球程序員的廣泛贊譽。"}
{"index":{"_index":"books","_id":"2"}}
{"id":"2","title":"Java程序性能優化","language":"java","author":"葛一鳴","price":46.5,"publish_time":"2012-08-01","description":"讓你的Java程序更快、更穩定。深入剖析軟件設計層面、代碼層面、JVM虛擬機層面的優化方法"}
{"index":{"_index":"books","_id":"3"}}
{"id":"3","title":"Python科學計算","language":"python","author":"張若愚","price":81.4,"publish_time":"2016-05-01","description":"零基礎學python,光盤中作者獨家整合開發winPython運行環境,涵蓋了Python各個擴展庫"}
{"index":{"_index":"books","_id":"4"}}
{"id":"4", "title":"Python基礎教程", "language":"python", "author":"Helant", "price":54.50, "publish_time":"2014-03-01", "description":"經典的Python入門教程,層次鮮明,結構嚴謹,內容翔實"}
{"index":{"_index":"books","_id":"5"}}
{"id":"5","title":"JavaScript高級程序設計","language":"javascript","author":"Nicholas C. Zakas","price":66.4,"publish_time":"2012-10-01","description":"JavaScript技術經典名著"}GET /books/_search
{"query": {"bool": {"must": [{"match": {"title": "java編程"}},{"match": {"description": "性能優化"}}]}}
}GET /books/_search
{"query": {"bool": {"should": [{"match": {"title": "java編程"}},{"match": {"description": "性能優化"}}],"minimum_should_match": 1}}
}
GET /books/_search
{"query": {"bool": {"filter": [{"term": {"language": "java"}},{"range": {"publish_time": {"gte": "2010-08-01"}}}]}}
}6. highlight高亮
- pre_tags 前綴標簽
- post_tags 后綴標簽
- tags_schema 設置為styled可以使用內置高亮樣式
- require_field_match 多字段高亮需要設置為false
示例
#指定ik分詞器
PUT /products
{"settings" : {"index" : {"analysis.analyzer.default.type": "ik_max_word"}}
}PUT /products/_doc/1
{"proId" : "2","name" : "牛仔男外套","desc" : "牛仔外套男裝春季衣服男春裝夾克修身休閑男生潮牌工裝潮流頭號青年春秋棒球服男 7705淺藍常規 XL","timestamp" : 1576313264451,"createTime" : "2019-12-13 12:56:56"
}PUT /products/_doc/2
{"proId" : "6","name" : "HLA海瀾之家牛仔褲男","desc" : "HLA海瀾之家牛仔褲男2019時尚有型舒適HKNAD3E109A 牛仔藍(A9)175/82A(32)","timestamp" : 1576314265571,"createTime" : "2019-12-18 15:56:56"
}GET /products/_search
{"query": {"term": {"name": {"value": "牛仔"}}},"highlight": {"fields": {"*":{}}}
}自定義高亮html標簽
可以在highlight中使用pre_tags和post_tags
GET /products/_search
{"query": {"multi_match": {"fields": ["name","desc"],"query": "牛仔"}},"highlight": {"post_tags": ["</span>"], "pre_tags": ["<span style='color:red'>"],"fields": {"*":{}}}
}多字段高亮
GET /products/_search
{"query": {"term": {"name": {"value": "牛仔"}}},"highlight": {"pre_tags": ["<font color='red'>"],"post_tags": ["<font/>"],"require_field_match": "false","fields": {"name": {},"desc": {}}}
}- require_field_match: 該設置控制是否需要所有指定的高亮字段都匹配搜索查詢,才能應用高亮。當設置為false時,只要任意一個字段匹配,該文檔的匹配部分就會被高亮。如果設置為true,則所有指定的字段都必須匹配查詢條件。
7. 地理空間位置查詢
地理空間位置查詢是數據庫和搜索系統中的一個重要特性,特別是在地理信息系統(GIS)和位置服務中。它允許用戶基于地理位置信息來搜索和過濾數據。在Elasticsearch這樣的全文搜索引擎中,地理空間位置查詢被廣泛應用,例如在旅行、房地產、物流和零售等行業,用于提供基于位置的搜索功能。
在Elasticsearch中,地理空間數據通常存儲在geo_point字段類型中。這種字段類型可以存儲緯度和經度坐標,用于表示地球上的一個點。
以下是一個使用geo_distance查詢的例子,它會找到距離特定點一定距離內的所有文檔。
1)確保索引中有一個geo_point字段,例如location。
PUT /my_index
{"mappings": {"properties": {"location": {"type": "geo_point"}}}
}2)使用以下查詢來找到距離給定坐標點(例如lat和lon)小于或等于10公里的所有文檔:
GET /my_index/_search
{"query": {"bool": {"must": {"match_all": {}},"filter": {"geo_distance": {"distance": "10km","distance_type": "arc","location": {"lat": 39.9,"lon": 116.4}}}}}
}- "bool"?是一個邏輯查詢容器,用于組合多個查詢子句。
- "match_all"?是一個匹配所有文檔的查詢子句。
- "geo_distance"?是一個地理距離查詢,它允許您指定一個距離和一個點的坐標。
- "distance"?是查詢的最大距離,單位可以是米(m)、公里(km)等。
- "distance_type"?可以是?arc(以地球表面的弧長為單位)或?plane(以直線距離為單位)。通常對于地球上的距離查詢,建議使用?arc。
- "location"?是查詢的參考點,包含緯度和經度坐標。
假設我們正在管理一個記錄中國各地著名景點的索引,每個景點都帶有地理坐標。以下是一些示例數據:
# 創建索引
PUT /tourist_spots
{"mappings": {"properties": {"name": {"type": "text","analyzer": "ik_max_word","search_analyzer": "ik_max_word"},"location": {"type": "geo_point"}}}
}# 插入文檔
POST /tourist_spots/_doc
{"name": "故宮博物院","location": {"lat": 39.9159,"lon": 116.3945},"city": "北京"
}POST /tourist_spots/_doc
{"name": "西湖","location": {"lat": 30.2614,"lon": 120.1479},"city": "杭州"
}POST /tourist_spots/_doc
{"name": "雷峰塔","location": {"lat": 30.2511,"lon": 120.1347},"city": "杭州"
}POST /tourist_spots/_doc
{"name": "蘇堤春曉","location": {"lat": 30.2584,"lon": 120.1383},"city": "杭州"
}# 搜索包含故宮或博物院的景點:
GET /tourist_spots/_search
{"query": {"match": {"name": "故宮 博物院"}}
}
# 查詢北京附近的景點
GET /tourist_spots/_search
{"query": {"bool": {"must": {"match_all": {}},"filter": {"geo_distance": {"distance": "10km","distance_type": "arc","location": {"lat": 39.9159,"lon": 116.3945}}}}}
}
# 查詢杭州西湖5km附近的景點
#雷峰塔 - 位于西湖附近,距離約2.8公里。
#蘇堤春曉 - 位于西湖邊,距離西湖中心約1公里。
GET /tourist_spots/_search
{"query": {"bool": {"must": {"match_all": {}},"filter": {"geo_distance": {"distance": "5km","distance_type": "arc","location": {"lat": 30.2614,"lon": 120.1479}}}}}
}
8.?ElasticSearch8.x 向量檢索
Elasticsearch 8.x 引入了一個重要的新特性:向量檢索(Vector Search),特別是通過KNN(K-Nearest Neighbors)算法支持向量近鄰檢索。這一特性使得Elasticsearch在機器學習、數據分析和推薦系統等領域的應用變得更加廣泛和強大。
向量檢索的基本思路是,將文檔(或數據項)表示為高維向量,并使用這些向量來執行相似性搜索。在Elasticsearch中,這些向量被存儲在dense_vector類型的字段中,然后使用KNN算法來找到與給定向量最相似的其他向量。
PUT image-index
{"mappings": {"properties": {"image-vector": {"type": "dense_vector","dims": 3},"title": {"type": "text"},"file-type": {"type": "keyword"},"my_label": {"type": "text"}}}
}POST image-index/_bulk
{ "index": {} }
{ "image-vector": [-5, 9, -12], "title": "Image A", "file-type": "jpeg", "my_label": "red" }
{ "index": {} }
{ "image-vector": [10, -2, 3], "title": "Image B", "file-type": "png", "my_label": "blue" }
{ "index": {} }
{ "image-vector": [4, 0, -1], "title": "Image C", "file-type": "gif", "my_label": "red" }POST image-index/_search
{"knn": {"field": "image-vector","query_vector": [-5, 10, -12],"k": 10,"num_candidates": 100},"fields": [ "title", "file-type" ]
}












如何分析和優化存儲過程?)
)


是什么)

