目錄
1. 概述
2. 聚合類型分類詳解
2.1?桶聚合(Bucket Aggregations)
2.1.1? 基礎桶聚合
2.1.2 特殊桶聚合
2.1.3?高級桶聚合
2.2?指標聚合(Metric Aggregations)
2.2.1 單值指標聚合(Single-value Metrics)
2.2.2 多值指標聚合(Multi-value Metrics)
2.3 管道聚合(Pipeline Aggregation)
2.3.1 數學計算類
2.3.2?桶操作類
2.3.3? 流程控制類
3.?聚合的作用范圍
4. 聚合排序
5. ES聚合分析不精準原因分析
6. Elasticsearch 聚合性能優化
1. 概述
Elasticsearch 的聚合(Aggregations)功能用于對數據進行統計、分析和分組,類似 SQL 中的?GROUP BY?與聚合函數(如?SUM、AVG)。其核心分為桶聚合、指標聚合和管道聚合三類
基本語法
- 查詢條件:指定需要聚合的文檔,可以使用標準的 Elasticsearch 查詢語法,如 term、match、range 等等。
- 聚合函數:指定要執行的聚合操作,如 sum、avg、min、max、terms、date_histogram 等等。每個聚合命令都會生成一個聚合結果。
- 聚合嵌套:聚合命令可以嵌套,以便更細粒度地分析數據。
GET <index_name>/_search
{"aggs": {"<aggs_name>": { // 聚合名稱需要自己定義"<agg_type>": {"field": "<field_name>"}}}
}- aggs_name:聚合函數的名稱
- agg_type:聚合種類,比如是桶聚合(terms)或者是指標聚合(avg、sum、min、max等)
- field_name:字段名稱或者叫域名。
聚合類型分類
Elasticsearch 聚合操作主要分為三大類:
| 聚合類型 | 核心功能 | 典型應用場景 |
|---|---|---|
| 桶聚合 | 將文檔分組到"桶"中 | 分組統計、分類分析 |
| 指標聚合 | 對桶內文檔進行數值計算 | 平均值、求和等數值計算 |
| 管道聚合 | 對其他聚合結果進行二次處理 | 復雜統計分析 |
示例數據準備
DELETE /employees
#創建索引庫
PUT /employees
{"mappings": {"properties": {"age":{"type": "integer"},"gender":{"type": "keyword"},"job":{"type" : "text","fields" : {"keyword" : {"type" : "keyword","ignore_above" : 50}}},"name":{"type": "keyword"},"salary":{"type": "integer"}}}
}PUT /employees/_bulk
{ "index" : { "_id" : "1" } }
{ "name" : "Emma","age":32,"job":"Product Manager","gender":"female","salary":35000 }
{ "index" : { "_id" : "2" } }
{ "name" : "Underwood","age":41,"job":"Dev Manager","gender":"male","salary": 50000}
{ "index" : { "_id" : "3" } }
{ "name" : "Tran","age":25,"job":"Web Designer","gender":"male","salary":18000 }
{ "index" : { "_id" : "4" } }
{ "name" : "Rivera","age":26,"job":"Web Designer","gender":"female","salary": 22000}
{ "index" : { "_id" : "5" } }
{ "name" : "Rose","age":25,"job":"QA","gender":"female","salary":18000 }
{ "index" : { "_id" : "6" } }
{ "name" : "Lucy","age":31,"job":"QA","gender":"female","salary": 25000}
{ "index" : { "_id" : "7" } }
{ "name" : "Byrd","age":27,"job":"QA","gender":"male","salary":20000 }
{ "index" : { "_id" : "8" } }
{ "name" : "Foster","age":27,"job":"Java Programmer","gender":"male","salary": 20000}
{ "index" : { "_id" : "9" } }
{ "name" : "Gregory","age":32,"job":"Java Programmer","gender":"male","salary":22000 }
{ "index" : { "_id" : "10" } }
{ "name" : "Bryant","age":20,"job":"Java Programmer","gender":"male","salary": 9000}
{ "index" : { "_id" : "11" } }
{ "name" : "Jenny","age":36,"job":"Java Programmer","gender":"female","salary":38000 }
{ "index" : { "_id" : "12" } }
{ "name" : "Mcdonald","age":31,"job":"Java Programmer","gender":"male","salary": 32000}
{ "index" : { "_id" : "13" } }
{ "name" : "Jonthna","age":30,"job":"Java Programmer","gender":"female","salary":30000 }
{ "index" : { "_id" : "14" } }
{ "name" : "Marshall","age":32,"job":"Javascript Programmer","gender":"male","salary": 25000}
{ "index" : { "_id" : "15" } }
{ "name" : "King","age":33,"job":"Java Programmer","gender":"male","salary":28000 }
{ "index" : { "_id" : "16" } }
{ "name" : "Mccarthy","age":21,"job":"Javascript Programmer","gender":"male","salary": 16000}
{ "index" : { "_id" : "17" } }
{ "name" : "Goodwin","age":25,"job":"Javascript Programmer","gender":"male","salary": 16000}
{ "index" : { "_id" : "18" } }
{ "name" : "Catherine","age":29,"job":"Javascript Programmer","gender":"female","salary": 20000}
{ "index" : { "_id" : "19" } }
{ "name" : "Boone","age":30,"job":"DBA","gender":"male","salary": 30000}
{ "index" : { "_id" : "20" } }
{ "name" : "Kathy","age":29,"job":"DBA","gender":"female","salary": 20000}2. 聚合類型分類詳解
2.1?桶聚合(Bucket Aggregations)
按照一定的規則,將文檔分配到不同的桶中,從而達到分類的目的。將文檔按規則分組到“桶”中,類似 SQL 的?GROUP BY。
桶聚合類型分類
2.1.1? 基礎桶聚合
| 聚合類型 | 功能描述 | 示例場景 |
|---|---|---|
| terms | 按字段值分組 | 按品牌統計商品數量 |
| range | 按數值范圍分組 | 按價格區間統計商品 |
| date_range | 按日期范圍分組 | 按時間段統計銷售額 |
| histogram | 按固定間隔分組 | 每100元價格段統計商品數 |
| date_histogram | 按時間間隔分組 | 每月/每周統計銷售額 |
| geo_distance | 按地理位置距離分組 | 按距離商圈范圍統計門店 |
注意:
- Terms,需要字段支持filedata
- keyword 默認支持fielddata
- text需要在Mapping 中開啟fielddata,會按照分詞后的結果進行分桶
2.1.2 特殊桶聚合
| 聚合類型 | 功能描述 | 示例場景 |
|---|---|---|
| filters | 使用自定義過濾器分組 | 同時統計多個過濾條件結果 |
| nested | 處理嵌套對象分組 | 統計訂單中的商品分類 |
| reverse_nested | 從嵌套對象返回父文檔分組 | 統計含特定商品的訂單 |
| children | 在父子文檔關系中進行分組 | 統計作者及其書籍 |
| composite | 多維度組合分組(替代多級terms) | 品牌+顏色組合統計 |
| sampler | 獲取代表性樣本分組 | 大數據集抽樣分析 |
2.1.3?高級桶聚合
| 聚合類型 | 功能描述 | 示例場景 |
|---|---|---|
| significant_terms | 識別統計顯著性高的詞項 | 發現異常關鍵詞 |
| geohash_grid | 按地理網格分組 | 區域熱力圖分析 |
| variable_width | 自動調整數值區間寬度分組 | 智能價格分段 |
| adjacency_matrix | 關系矩陣分組 | 用戶行為關聯分析 |
示例
獲取job的分類信息
# 對keword 進行聚合
GET /employees/_search
{"size": 0,"aggs": {"jobs": {"terms": {"field":"job.keyword"}}}
}- field:指定聚合字段
- size:指定聚合結果數量
- order:指定聚合結果排序方式
GET /employees/_search
{"size": 0,"aggs": {"jobs": {"terms": {"field":"job.keyword","size": 10,"order": {"_count": "desc" }}}}
}限定聚合范圍
#只對salary在10000元以上的文檔聚合
GET /employees/_search
{"query": {"range": {"salary": {"gte": 10000 }}}, "size": 0,"aggs": {"jobs": {"terms": {"field":"job.keyword","size": 10,"order": {"_count": "desc" }}}}
}注意:對 Text 字段進行 terms 聚合查詢,會失敗拋出異常
解決辦法:對 Text 字段打開 fielddata,支持terms aggregation
# 對 Text 字段進行 terms 聚合查詢,會失敗拋出異常
POST /employees/_search
{"size": 0,"aggs": {"jobs": {"terms": {"field":"job"}}}
}#對 Text 字段打開 fielddata,支持terms aggregation
PUT /employees/_mapping
{"properties" : {"job":{"type": "text","fielddata": true}}
}# 對 Text 字段進行分詞,分詞后的terms
POST /employees/_search
{"size": 0,"aggs": {"jobs": {"terms": {"field":"job"}}}
}Range & Histogram聚合
- 按照數字的范圍,進行分桶
- 在Range Aggregation中,可以自定義Key
Salary Range分桶,可以自己定義 key
POST employees/_search
{"size": 0,"aggs": {"salary_range": {"range": {"field":"salary","ranges":[{"to":10000},{"from":10000,"to":20000},{"key":">20000","from":20000}]}}}
}Histogram示例:按照工資的間隔分桶
#工資0到10萬,以 5000一個區間進行分桶
POST employees/_search
{"size": 0,"aggs": {"salary_histrogram": {"histogram": {"field":"salary","interval":5000,"extended_bounds":{"min":0,"max":100000}}}}
}top_hits應用場景: 當獲取分桶后,桶內最匹配的頂部文檔列表
# 指定size,不同工種中,年紀最大的3個員工的具體信息
POST /employees/_search
{"size": 0,"aggs": {"jobs": {"terms": {"field":"job.keyword"},"aggs":{"old_employee":{"top_hits":{"size":3,"sort":[{"age":{"order":"desc"}}]}}}}}
}嵌套聚合示例
# 嵌套聚合1,按照工作類型分桶,并統計工資信息
POST employees/_search
{"size": 0,"aggs": {"Job_salary_stats": {"terms": {"field": "job.keyword"},"aggs": {"salary": {"stats": {"field": "salary"}}}}}
}# 多次嵌套。根據工作類型分桶,然后按照性別分桶,計算工資的統計信息
POST employees/_search
{"size": 0,"aggs": {"Job_gender_stats": {"terms": {"field": "job.keyword"},"aggs": {"gender_stats": {"terms": {"field": "gender"},"aggs": {"salary_stats": {"stats": {"field": "salary"}}}}}}}
}2.2?指標聚合(Metric Aggregations)
指標聚合主要用于對文檔進行數值計算,分為兩大類:
2.2.1 單值指標聚合(Single-value Metrics)
| 聚合類型 | 功能描述 | 公式/說明 |
|---|---|---|
| avg | 計算平均值 |
|
| sum | 計算總和 |
|
| min | 獲取最小值 |
|
| max | 獲取最大值 |
|
| value_count | 統計非空值數量 |
|
| cardinality | 計算唯一值數量(去重計數) |
|
2.2.2 多值指標聚合(Multi-value Metrics)
| 聚合類型 | 功能描述 | 包含指標 |
|---|---|---|
| stats | 基礎統計匯總 | count, min, max, avg, sum |
| extended_stats | 擴展統計(含標準差/方差) | stats + std_deviation, variance |
| percentiles | 計算百分位值(如P95/P99) | [P50, P75, P90, P95] |
| percentile_ranks | 計算值的百分位排名 | 值X的百分位位置 |
| top_hits | 返回每個分組的最相關文檔 | 子聚合中的特殊類型 |
| geo_centroid | 計算地理坐標中心點 | lat/lon平均值 |
| median_absolute_deviation | 計算中位數絕對偏差 | 穩健統計離散度 |
示例
查詢員工的最低最高和平均工資
#多個 Metric 聚合,找到最低最高和平均工資
POST /employees/_search
{"size": 0, "aggs": {"max_salary": {"max": {"field": "salary"}},"min_salary": {"min": {"field": "salary"}},"avg_salary": {"avg": {"field": "salary"}}}
}2.3 管道聚合(Pipeline Aggregation)
對聚合分析的結果,再次進行聚合分析。
2.3.1 數學計算類
| 聚合類型 | 功能 | 公式示例 |
|---|---|---|
| cumulative_sum | 累積和 |
|
| derivative | 變化率 |
|
| moving_function | 移動計算 |
|
2.3.2?桶操作類
| 聚合類型 | 功能 | 類似SQL |
|---|---|---|
| max/min/avg/sum_bucket | 桶值極值/平均 |
|
| stats/extended_stats_bucket | 桶統計信息 |
|
| percentiles_bucket | 桶百分位值 |
|
2.3.3? 流程控制類
| 聚合類型 | 功能 | 類似編程概念 |
|---|---|---|
| bucket_selector | 桶過濾 |
|
| bucket_sort | 桶排序 | ORDER BY |
| bucket_script | 自定義腳本 | 函數計算 |
min_bucket示例
在員工數最多的工種里,找出平均工資最低的工種
# 平均工資最低的工種
POST employees/_search
{"size": 0,"aggs": {"jobs": {"terms": {"field": "job.keyword","size": 10},"aggs": {"avg_salary": {"avg": {"field": "salary"}}}},"min_salary_by_job":{ "min_bucket": { "buckets_path": "jobs>avg_salary" }}}
}- min_salary_by_job結果和jobs的聚合同級
- min_bucket求之前結果的最小值
- 通過bucket_path關鍵字指定路徑
Stats示例
# 平均工資的統計分析
POST employees/_search
{"size": 0,"aggs": {"jobs": {"terms": {"field": "job.keyword","size": 10},"aggs": {"avg_salary": {"avg": {"field": "salary"}}}},"stats_salary_by_job":{"stats_bucket": {"buckets_path": "jobs>avg_salary"}}}
}percentiles示例
# 平均工資的百分位數
POST employees/_search
{"size": 0,"aggs": {"jobs": {"terms": {"field": "job.keyword","size": 10},"aggs": {"avg_salary": {"avg": {"field": "salary"}}}},"percentiles_salary_by_job":{"percentiles_bucket": {"buckets_path": "jobs>avg_salary"}}}
}Cumulative_sum示例
#Cumulative_sum 累計求和
POST employees/_search
{"size": 0,"aggs": {"age": {"histogram": {"field": "age","min_doc_count": 0,"interval": 1},"aggs": {"avg_salary": {"avg": {"field": "salary"}},"cumulative_salary":{"cumulative_sum": {"buckets_path": "avg_salary"}}}}}
}3.?聚合的作用范圍
- Filter
- Post Filter
- Global
示例
#Query
POST employees/_search
{"size": 0,"query": {"range": {"age": {"gte": 20}}},"aggs": {"jobs": {"terms": {"field":"job.keyword"}}}
}#Filter
POST employees/_search
{"size": 0,"aggs": {"older_person": {"filter":{"range":{"age":{"from":35}}},"aggs":{"jobs":{"terms": {"field":"job.keyword"}}}},"all_jobs": {"terms": {"field":"job.keyword"}}}
}#Post field. 一條語句,找出所有的job類型。還能找到聚合后符合條件的結果
POST employees/_search
{"aggs": {"jobs": {"terms": {"field": "job.keyword"}}},"post_filter": {"match": {"job.keyword": "Dev Manager"}}
}#global
# 使用global聚合來計算所有匹配查詢的文檔(即所有年齡大于或等于40歲的員工)的平均薪資。
#global聚合的特點是它會考慮查詢范圍內的所有文檔,而不僅僅是某個特定分組或桶中的文檔。
POST employees/_search
{"size": 0,"query": {"range": {"age": {"gte": 40}}},"aggs": {"jobs": {"terms": {"field":"job.keyword" }},"all":{"global":{},"aggs":{"salary_avg":{"avg":{"field":"salary"}}}}}
}4. 聚合排序
- 默認情況,按照count降序排序
- 指定size,就能返回相應的桶
#排序 order
#count and key
POST employees/_search
{"size": 0,"query": {"range": {"age": {"gte": 20}}},"aggs": {"jobs": {"terms": {"field":"job.keyword","order":[{"_count":"asc"},{"_key":"desc"}]}}}
}#排序 order
#count and key
POST employees/_search
{"size": 0,"aggs": {"jobs": {"terms": {"field":"job.keyword","order":[ {"avg_salary":"desc"}]},"aggs": {"avg_salary": {"avg": {"field":"salary"}}}}}
}#排序 order
#count and key
POST employees/_search
{"size": 0,"aggs": {"jobs": {"terms": {"field":"job.keyword","order":[ {"stats_salary.min":"desc"}]},"aggs": {"stats_salary": {"stats": {"field":"salary"}}}}}
}5. ES聚合分析不精準原因分析
ElasticSearch在對海量數據進行聚合分析的時候會損失搜索的精準度來滿足實時性的需求。
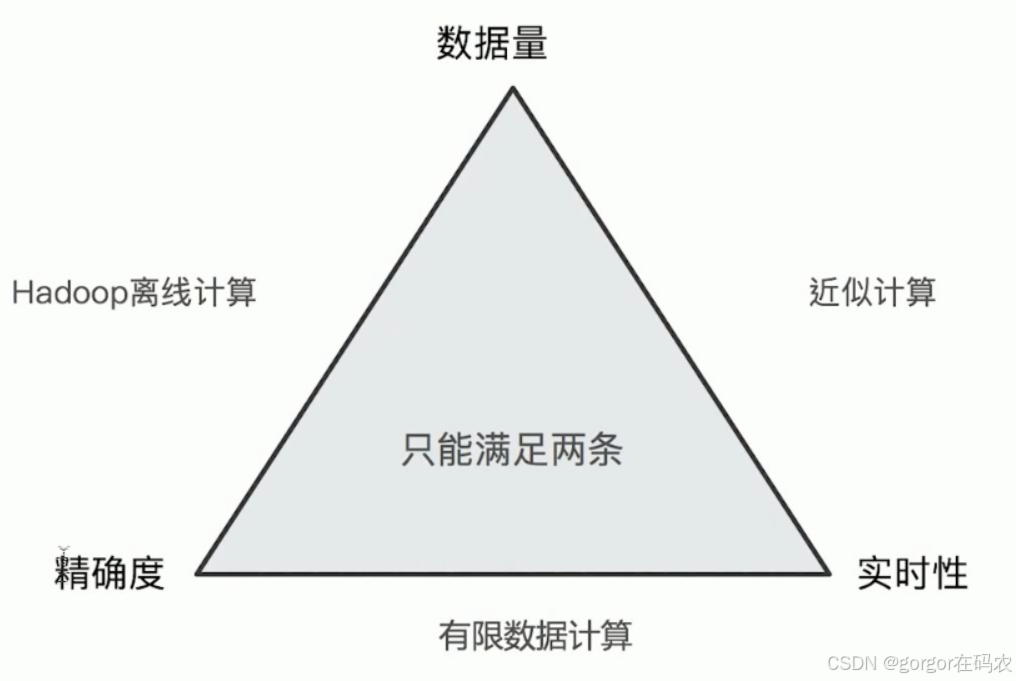
Terms聚合分析的執行流程:
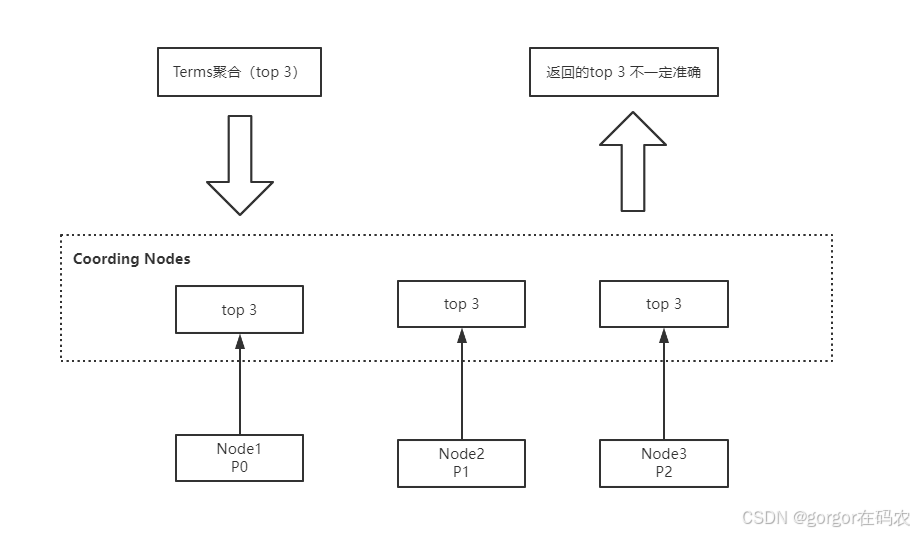
不精準的原因: 數據分散到多個分片,聚合是每個分片的取 Top X,導致結果不精準。ES 可以不每個分片Top X,而是全量聚合,但勢必這會有很大的性能問題。
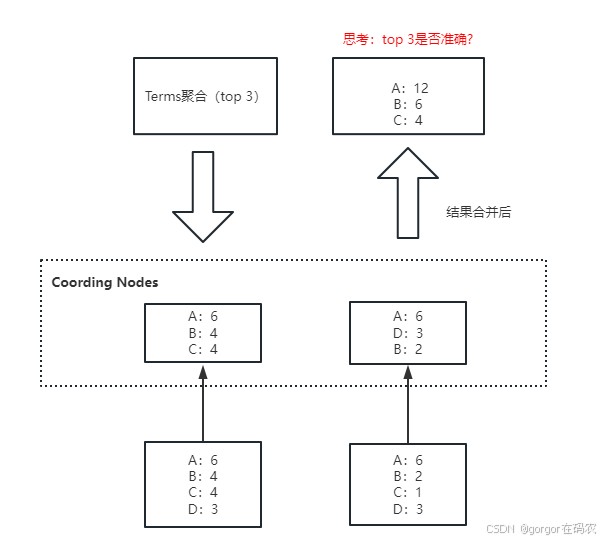
- size:是聚合結果的返回值,客戶期望返回聚合排名前三,size值就是 3。
- shard_size: 每個分片上聚合的數據條數。shard_size 原則上要大于等于 size
DELETE my_flights
PUT my_flights
{"settings": {"number_of_shards": 20},"mappings" : {"properties" : {"AvgTicketPrice" : {"type" : "float"},"Cancelled" : {"type" : "boolean"},"Carrier" : {"type" : "keyword"},"Dest" : {"type" : "keyword"},"DestAirportID" : {"type" : "keyword"},"DestCityName" : {"type" : "keyword"},"DestCountry" : {"type" : "keyword"},"DestLocation" : {"type" : "geo_point"},"DestRegion" : {"type" : "keyword"},"DestWeather" : {"type" : "keyword"},"DistanceKilometers" : {"type" : "float"},"DistanceMiles" : {"type" : "float"},"FlightDelay" : {"type" : "boolean"},"FlightDelayMin" : {"type" : "integer"},"FlightDelayType" : {"type" : "keyword"},"FlightNum" : {"type" : "keyword"},"FlightTimeHour" : {"type" : "keyword"},"FlightTimeMin" : {"type" : "float"},"Origin" : {"type" : "keyword"},"OriginAirportID" : {"type" : "keyword"},"OriginCityName" : {"type" : "keyword"},"OriginCountry" : {"type" : "keyword"},"OriginLocation" : {"type" : "geo_point"},"OriginRegion" : {"type" : "keyword"},"OriginWeather" : {"type" : "keyword"},"dayOfWeek" : {"type" : "integer"},"timestamp" : {"type" : "date"}}}
}POST _reindex
{"source": {"index": "kibana_sample_data_flights"},"dest": {"index": "my_flights"}
}GET my_flights/_count
GET kibana_sample_data_flights/_search
{"size": 0,"aggs": {"weather": {"terms": {"field":"OriginWeather","size":5,"show_term_doc_count_error":true}}}
}GET my_flights/_search
{"size": 0,"aggs": {"weather": {"terms": {"field":"OriginWeather","size":5,"shard_size":10,"show_term_doc_count_error":true}}}
}- doc_count_error_upper_bound : 被遺漏的term 分桶,包含的文檔,有可能的最大值
- sum_other_doc_count: 除了返回結果 bucket的terms以外,其他 terms 的文檔總數(總數-返回的總數
方案3:將size設置為全量值,來解決精度問題
將size設置為2的32次方減去1也就是分片支持的最大值,來解決精度問題。
原因:1.x版本,size等于 0 代表全部,高版本取消 0 值,所以設置了最大值(大于業務的全量值)。
全量帶來的弊端就是:如果分片數據量極大,這樣做會耗費巨大的CPU 資源來排序,而且可能會阻塞網絡。
適用場景:對聚合精準度要求極高的業務場景,由于性能問題,不推薦使用。
方案4:使用Clickhouse/ Spark 進行精準聚合
適用場景:數據量非常大、聚合精度要求高、響應速度快的業務場景。
6. Elasticsearch 聚合性能優化
插入數據時對索引進行預排序
- Index sorting (索引排序)可用于在插入時對索引進行預排序,而不是在查詢時再對索引進行排序,這將提高范圍查詢(range query)和排序操作的性能。
- 在 Elasticsearch 中創建新索引時,可以配置如何對每個分片內的段進行排序。
- 這是 Elasticsearch 6.X 之后版本才有的特性。
PUT /my_index
{"settings": {"index":{"sort.field": "create_time","sort.order": "desc"}},"mappings": {"properties": {"create_time":{"type": "date"}}}
}注意:預排序將增加 Elasticsearch 寫入的成本。在某些用戶特定場景下,開啟索引預排序會導致大約 40%-50% 的寫性能下降。也就是說,如果用戶場景更關注寫性能的業務,開啟索引預排序不是一個很好的選擇。
使用節點查詢緩存
節點查詢緩存(Node query cache)可用于有效緩存過濾器(filter)操作的結果。如果多次執行同一 filter 操作,這將很有效,但是即便更改過濾器中的某一個值,也將意味著需要計算新的過濾器結果。
你可以執行一個帶有過濾查詢的搜索請求,Elasticsearch將自動嘗試使用節點查詢緩存來優化性能。例如,如果你想緩存一個基于特定字段值的過濾查詢,你可以發送如下的HTTP請求:
GET /your_index/_search
{"query": {"bool": {"filter": {"term": {"your_field": "your_value"}}}}
}使用分片請求緩存
聚合語句中,設置:size:0,就會使用分片請求緩存緩存結果。size = 0 的含義是:只返回聚合結果,不返回查詢結果。
GET /es_db/_search
{"size": 0,"aggs": {"remark_agg": {"terms": {"field": "remark.keyword"}}}
}拆分聚合,使聚合并行化
Elasticsearch 查詢條件中同時有多個條件聚合,默認情況下聚合不是并行運行的。當為每個聚合提供自己的查詢并執行 msearch 時,性能會有顯著提升。因此,在 CPU 資源不是瓶頸的前提下,如果想縮短響應時間,可以將多個聚合拆分為多個查詢,借助:msearch 實現并行聚合。
#常規的多條件聚合實現
GET /employees/_search
{"size": 0,"aggs": {"job_agg": {"terms": {"field": "job.keyword"}},"max_salary":{"max": {"field": "salary"}}}
}
# msearch 拆分多個語句的聚合實現
GET _msearch
{"index":"employees"}
{"size":0,"aggs":{"job_agg":{"terms":{"field": "job.keyword"}}}}
{"index":"employees"}
{"size":0,"aggs":{"max_salary":{"max":{"field": "salary"}}}}





——文本分塊優化)
)









![[NLP]多電源域設計的仿真驗證方法](http://pic.xiahunao.cn/[NLP]多電源域設計的仿真驗證方法)
的執行方式)
如何使用全文索引?)