在原生 Postgres 實現中,全文搜索由B 樹或GIN(廣義倒排索引)結構支持。這些索引針對相對快速的查找進行了優化,但受限于 B 樹的寫入吞吐量。
當我們構建pg_searchPostgres 搜索和分析擴展時,我們的優先級有所不同。為了成為 Elasticsearch 的有效替代方案,我們需要支持高效的實時掃描。我們選擇了一種更適合密集發布列表位圖和高數據采集工作負載的數據結構:日志結構化合并 ( LSM ) 樹。
然而,當我們在物理復制(允許 Postgres 將數據從主節點復制到一個或多個只讀副本的兩種機制之一)下測試 LSM 樹時,我們遇到了一些波折。最令人驚訝的是,我們發現 Postgres 基于預寫日志 (WAL) 傳輸機制構建的開箱即用的物理復制支持不足以讓LSM 樹這樣的高級數據結構實現復制安全。在本文中,我們將深入探討:
- LSM 樹的復制安全意味著什么
- Postgres 的 WAL 傳輸如何保證物理一致性
- 為什么原子日志對于邏輯一致性是必要的
- 我們如何利用鮮為人知但功能強大的 Postgres 設置hot_standby_feedback
什么是 LSM 樹?
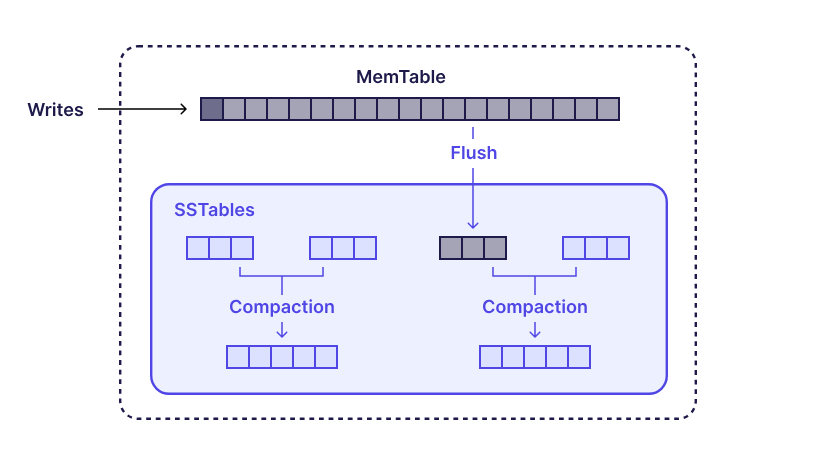
日志結構合并樹 (LSM 樹) 是一種寫優化數據結構,常用于 RocksDB 和 Cassandra 等系統。
LSM 樹的核心思想是將隨機寫入轉換為順序寫入。傳入的寫入首先存儲在內存緩沖區(稱為 memtable)中,該緩沖區更新速度很快。一旦 memtable 寫滿,它將被刷新到磁盤,形成一個已排序的、不可變的段文件(通常稱為 SSTable)。
這些段文件按大小組織成層或級別。較新的數據寫入最頂層。隨著時間的推移,數據通過稱為“壓縮”的過程逐漸下推到較低的級別。在此過程中,較小段中的數據會被合并、去重,然后重寫到較大的段中。
復制安全是什么意思?
可靠的分布式數據存儲(保證“復制安全”)必須證明跨數據庫副本的物理和邏輯一致性。
- 物理一致性意味著副本包含結構有效的數據——磁盤上的每個頁面或塊都是格式良好的,并且對應于主節點上某個時刻存在的狀態。
- 邏輯一致性確保副本上的數據反映數據庫的一致且穩定的視圖,這是主數據庫上的事務可以看到的。
物理一致的狀態并不總是邏輯一致的狀態。具體來說,如果在復制正在進行的事務時拍攝物理一致的副本的快照,則它可能在邏輯上不一致。一個很好的比喻是想象復制一本書。物理一致性就像精確地復制每一頁,即使正在復制某一章的中間部分——保證有真實的頁面,但最終可能會缺少半句話或腳注。邏輯一致性就像等到章節完成后再復制,確保結果對讀者有意義。
WAL 傳輸:Postgres 如何保證物理一致性
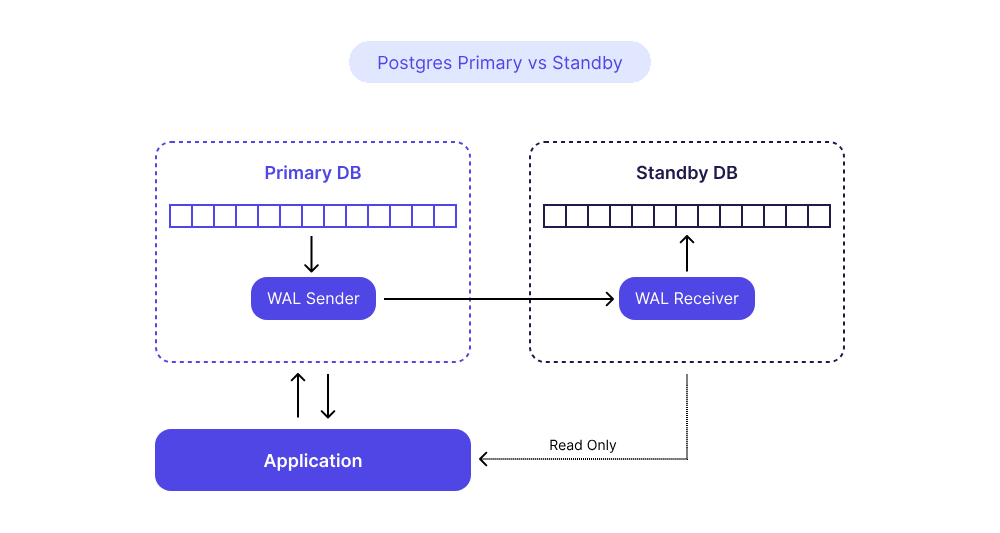
在主備物理復制設置中,主服務器與備用服務器配對,備用服務器充當其主服務器的只讀副本。服務器通過使用預寫日志 (WAL) 來保持同步,在發生任何二進制更改之前,這些更改都會記錄在主服務器上的存儲塊上。然后,對此僅追加的 WAL 文件的更改將流式傳輸到備用服務器(此過程稱為“日志傳送”),并按接收的順序應用。此過程使兩臺服務器之間能夠實現近乎實時的數據同步,因此有“熱備”的說法。
為什么原子性是物理一致性的必要條件
原子性是物理一致性的必要條件,因為 Postgres 的鎖不會在副本服務器上重放。這是因為重放主服務器上獲取的每個鎖需要嚴格的時間同步,這會嚴重影響性能,并妨礙備用服務器提供讀取服務的能力。相反,WAL 使用每個緩沖區的鎖來按特定順序增量重放編輯:它獲取緩沖區(塊在內存中的表示形式)的獨占鎖,進行更改,然后釋放它。
當修改跨越多個 Postgres 緩沖區的數據結構時,就會出現問題。由于無法保證操作在整個結構上是原子的,這些修改可能會導致結構損壞。
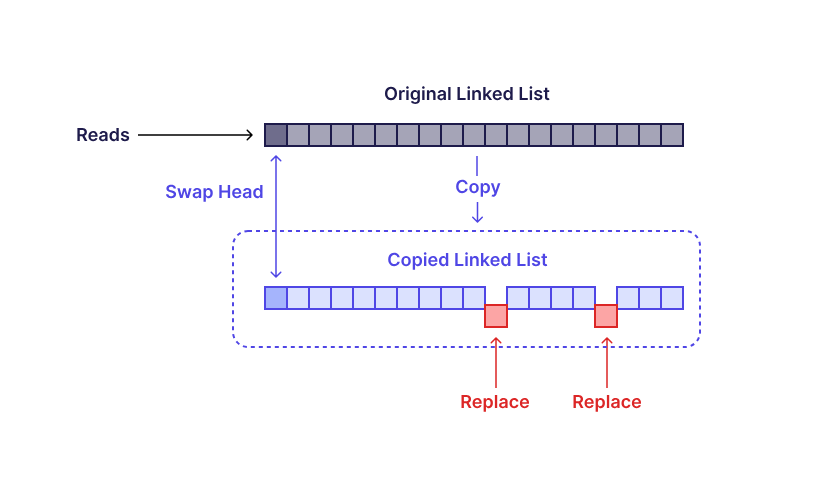
例如:pg_search使用Postgres 緩沖區的展開鏈表,其中每個節點保存 LSM 樹中一批段的讀取有效性。為了確保主服務器永遠不會發現損壞的鏈表,我們使用了手動鎖定(也稱為鎖耦合)來保證該列表在主服務器上保持物理一致性。列表中的每個緩沖區被修改后,其 WAL 條目將在副本上以原子方式可見。
但是,當我們想要“一次性”(原子地)編輯列表中的多個條目時,例如當一個新壓縮的段替換多個舊段時,會發生什么情況?如果只有主服務器重要,那么我們可以通過在列表本身上應用全局鎖來保護多個列表節點的邏輯完整性,確保列表內容僅在有效狀態下可見。但是副本服務器無法訪問全局鎖,因此無法同時協調跨多個節點(和多個緩沖區)的編輯。
相反,對于多節點操作,pg_search使用列表的寫時復制 (CoW) 克隆,并在頭部進行原子交換。更一般地說,原子操作通過消除對粗粒度鎖的依賴,使免受危險。
問題:真空破壞邏輯一致性
調整算法以在塊級別原子地工作是物理復制的賭注:如果不這樣做,您的數據結構就會被破壞,并且您將無法一致地使用它們。
但即使單個 WAL 操作和數據結構在原子上兼容,VACUUM也會干擾跨多個 WAL 條目的并發事務的執行,并損害邏輯一致性。
為了說明這個問題,假設主數據庫有一個包含一定數量行的表。為了確保并發寫入操作能夠安全地進行,而不會相互阻塞,Postgres 使用了一種稱為多版本并發控制 ( MVCC ) 的機制,該機制會為修改后的行(或元組)創建多個版本,而不是就地更新元組。當更新或刪除一行時,先前的元組不會被立即刪除,而是被標記為“已死”。
這些“死”的元組會一直保留在磁盤上,直到運行名為 VACUUM 的定期維護操作。與其他操作一樣,VACUUM 操作會記錄在 WAL 中,然后發送到備用數據庫,并在那里重放。
由于元組的“失效”發生在服務器本地,而 VACUUM 操作則會在全局范圍內重放,因此如果過早地從備庫中對某個元組執行 VACUUM 操作,則可能會出現錯誤。備庫可能正在讀取某個元組,并對其進行迭代(遍歷多個 WAL 條目),而主庫可能并發地決定執行 VACUUM 操作,將該元組從數據庫中移除。由于備庫缺乏任何鎖協調或對并發操作的感知,會在前一個事務仍在進行時重放 VACUUM 操作。如果一個長時間運行的查詢嘗試訪問已執行 VACUUM 操作的元組,則可能導致查詢失敗。
為什么 LSM 樹特別容易受到這個問題的影響
如果您的 Postgres 配置了只讀副本,并且寫入量很大,那么即使使用 B 樹索引,您可能也已經遇到過這個問題。如果在查詢命中只讀副本的同時,主服務器上正在運行 VACUUM,Postgres 可能會中止讀取操作。但是,在典型的 Postgres 設置中,這些錯誤可能很少發生,并且可以容忍,因為 VACUUM 每隔幾個小時運行一次。
但 LSM 樹的情況則不同,因為壓縮是系統的核心,并且是持續執行的部分。在高寫入吞吐量的系統中,壓縮每分鐘甚至每秒都可能發生多次。這增加了發生沖突的可能性。
與 VACUUM 類似,壓縮會重寫主服務器上的數據,并且需要知道正在進行的查詢何時不再需要該數據,以便能夠安全地刪除舊段。
合理的解決方案:熱備反饋
此時,Postgres 中一個可選的設置hot_standby_feedback就派上用場了。啟用后,hot_standby_feedback備用服務器可以告知主服務器從副本服務器的角度來看哪些數據是可以安全清理的。此信息顯著降低了元組被過早 VACUUM 的可能性,并允許pg_search確定何時可以安全刪除段。
要理解實際傳遞的信息hot_standby_feedback,我們必須首先了解 Postgres 中元組版本控制的工作原理。Postgres 中的每個元組都有兩個關鍵的元數據屬性: xmin 和 xmax。存儲創建 或 插入 該特定元組版本的xmin事務的事務 ID (XID) ,而 存儲更新 或 刪除該元組版本的事務的 XID ,從而有效地將其標記為已過時。當元組被刪除時,其 值將使用刪除事務的 XID 進行更新。由于 XID 是按順序分配的,因此后續事務的 XID 會被分配更大的編號,因此另一種思考方式是將其作為元組的“創建時間”和“上次更新或刪除時間”的代理。
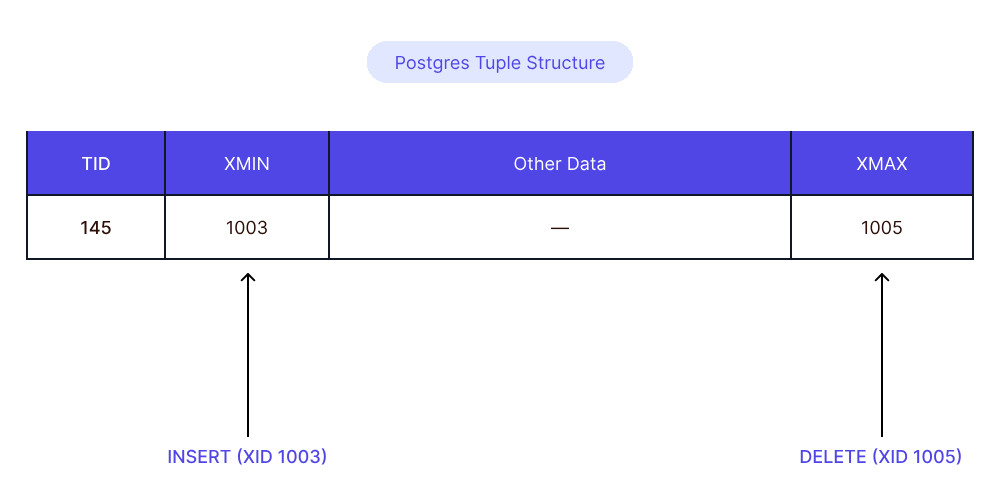
啟用后hot_standby_feedback,副本將定期傳達xmin其任何活動查詢當前固定的最小(最早的“創建時間”),這xmin標識了備用服務器上仍在使用的最舊元組。
有了這些信息,主服務器就可以更明智地決定何時允許執行清理操作(例如 VACUUM)。如果它發現備用查詢仍在對原本會被視為“死亡”的元組進行操作,則可以將清理操作推遲到該查詢完成。
最后的想法
即使借助hot_standby_feedback,備用服務器也基本上要依賴 WAL 來提供按接收順序和時間安全執行的指令。本地激勵與全局需求之間的矛盾,只是在分布式 Postgres 系統中實現完全復制安全性的挑戰性維度之一。
為了實現物理和邏輯一致性,pg_search我們實現了原子記錄的 LSM 樹,而為了實現邏輯一致性,我們依賴于hot_standby_feedback。
這項挑戰值得挑戰,因為它能夠在不犧牲一致性的情況下實現最快的搜索性能。要查看實際效果。

是什么)









)







