python生日悖論分析
If you have a group of people in a room, how many do you need to for it to be more likely than not, that two or more will have the same birthday?
如果您在一個房間里有一群人,那么您需要多少個才能使兩個或兩個以上的人有相同的生日?
Theoretically, the chances of two people having the same birthday are 1 in 365 (not accounting for leap years and the uneven distribution of birthdays across the year), and so odds are you’ll only meet a handful of people in your life who enjoy the same birthday as you. This leads many people to intuitively guess around 180.
從理論上講,兩個人擁有相同生日的機會是365分之一(不考慮leap年和全年中生日分布不均),因此,您人生中只會遇到少數幾個喜歡和你一樣的生日 這導致許多人憑直覺猜測大約180。
The correct answer is just 23.
正確的答案只有23。
That means in each of your classes at school, amongst the fellow commuters on the bus to work and amongst the players on a soccer field, there are more than likely at least two people with the same birthday.
這意味著在您學校的每個班級中,上班的通勤同胞和足球場上的球員中,至少有兩個人的生日相同。
Humans have a notoriously poor intuition when it comes to probability. The multi-billion dollar gambling industry is proof of this.
當涉及到概率時,人類的直覺非常差。 數十億美元的賭博業就是證明。
The source of confusion within the Birthday Paradox is that the probability grows relative to the number of possible pairings of people, not just the group’s size. The number of pairings grows with respect to the square of the number of participants, such that a group of 23 people contains 253 (23 x 22 / 2) unique pairs of people.
生日悖論之內的困惑根源在于,這種可能性相對于可能的配對人數而增加,而不僅僅是小組的人數。 配對的數量相對于參與者數量的平方而增加,因此,一個23人的組包含253(23 x 22/2)個獨特的人對。
In each of these pairings, there is a 364/365 chance of having different birthdays, but this needs to happen for every pair for there to be no matching birthdays across the entire group. Therefore the probability of two people having the same birthday in a group of 23 is:
在每個配對中,都有364/365個不同生日的機會,但是每對配對都需要這樣做,因為整個組中沒有匹配的生日。 因此,在23人一組中,兩個人有相同生日的概率為:
1 — (364/365)^253 = 50.05%If we plot the probability vs different group sizes, we see how the probability grows as the group size increases.
如果我們繪制概率與不同組大小的關系圖,我們將看到概率隨著組大小的增加而增加。
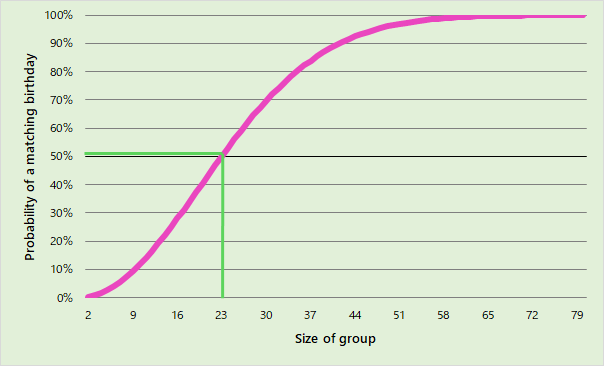
The line crosses 50% just before a group size of 23. Our previous guess of 180 has a probability so close to 100%, it’s not worth showing. In fact, the chance of choosing a group of 180 people at random, and having none of them share the same birthday, is roughly 6x10^-20 — 100 times less likely than two people picking the same grain of sand out of all the sand on Earth!
這條線在小組人數23之前越過了50%。我們先前的180猜測很可能接近100%,因此不值得顯示。 實際上,隨機選擇一組180個人并且沒有一個人共享同一生日的機會大約是6x10 ^ -20-比兩個人從所有沙子中挑選相同顆粒的可能性低100倍在地球上!
不太可能的巧合 (Less likely coincidences)
We can generalise the Birthday Paradox to look at other phenomena with a similar structure.
我們可以概括生日悖論,以研究具有相似結構的其他現象。
The probability of two people having the same PIN on their bank card is 1 in 10,000, or 0.01%. It would only take a group of 119 people however, to have odds in favour of two people having the same PIN.
兩個人的銀行卡上具有相同PIN的概率為10,000分之一,即0.01%。 但是,只需要一組119人,就能使兩個人擁有相同的PIN。
Of course, these numbers assume a randomly sampled, uniform distribution of birthdays and PINs. In reality, birthdays peak at certain times of year and people are more likely to pick certain numbers than others for their PIN. But the lack of a uniform distribution in fact reduces the size of group that you need.
當然,這些數字假設生日和PIN是隨機抽樣的均勻分布。 實際上, 生日會在一年中的某些時候達到頂峰 ,因此人們選擇PIN的可能性比其他人高。 但是實際上缺乏統一的分布會減小所需組的大小。
If we decrease the probability of a coincidence occurring, the size of group required to get an even chance of a collision obviously increases. However, it increases much more slowly than inverse of the probability.
如果我們降低發生重合的可能性,則獲得均勻碰撞機會所需的組的大小會明顯增加。 但是,它的增長比概率倒數慢得多。
For example, with a probability of 1 in 10,000, the minimum group size is 119. For a coincidence 10x less likely, the minimum group is 373, or only 3.15 times bigger. Therefore, even for incredibly tiny probabilities, the group size doesn’t grow particularly large. For odds of one in a million, the group required is only 1178.
例如,概率為10,000分之一,最小組大小為119。如果巧合的可能性小10倍,則最小組為373,或僅大3.15倍。 因此,即使對于極小的概率,組的大小也不會特別大。 對于百萬分之一的賠率,所需的小組僅為1178。
宇宙垃圾 (Space junk)

This has implications in the area of satellite collisions and space junk. The odds of two particular orbiting objects colliding with each other over the course of a year are almost infinitesimally small. However, given that there are around 5,500 satellites and approximately 900,000 objects of greater than 1 cm in size whizzing above our heads, collisions occur more regularly than you might expect.
這在衛星碰撞和太空垃圾領域具有影響。 在一年的過程中,兩個特定的軌道物體相互碰撞的幾率幾乎是無限小。 但是,考慮到大約有5500顆衛星和大約900,000個大小超過1厘米的物體在我們頭頂上方呼嘯而過,因此發生碰撞的次數比您預期的要多。
Various governments are able to track the larger pieces of space junk. This allows avoidance manoeuvres to take place to shift active satellites and the space station out of harm’s way. But with around 20,000 close approaches per week and growing, this could become an increasingly difficult and costly procedure.
各國政府能夠追蹤更大的太空垃圾。 這樣可以進行回避演習,以使活動中的衛星和空間站擺脫傷害。 但是,隨著每周大約20,000種接近方法不斷發展,這可能會變得越來越困難且成本更高。
In 2009, two satellites — an 16 year old defunct Russian military satellite and a still active Iridium communications satellite — collided, at a relative velocity of almost 12 km /s. Both satellites shattered into clouds of debris fragments, with over 1,000 pieces larger than a grapefruit in size.
2009年,兩顆衛星以近12 km / s的相對速度相撞,這是一顆16歲的已經失效的俄羅斯軍事衛星和一顆仍在活動的銥通信衛星。 兩顆衛星都破碎成碎片碎片云,其大小比葡萄柚大1,000顆。
More space junk means a higher chance of collisions occurring. And each collision increases the number of pieces of space junk. This positive feedback loop, if it exceeds the rate at which objects fall into the atmosphere and burn up, could lead to something called the Kessler Syndrome. This is a chain reaction in which collisions become increasingly common, spraying out more and more debris, until placing a satellite in low earth orbit becomes too dangerous to be feasible.
更多的太空垃圾意味著發生碰撞的機會更高。 每次碰撞都會增加太空垃圾的數量。 這種正反饋回路如果超過物體掉入大氣并燃燒的速率,則可能導致凱斯勒綜合癥。 這是一個連鎖React,其中碰撞變得越來越普遍,噴出越來越多的碎片,直到將衛星置于低地球軌道變得太危險以致于無法實現。
DNA證據 (DNA evidence)
Over the past forty years, DNA evidence has revolutionised the field of forensic investigation. As we go about our daily business, we leave behind us a trail of genetic material, mostly via skin cells and hair. Governments compile huge databases of DNA “profiles”, recording a series of uncorrelated genetic markers.
在過去的四十年中,DNA證據徹底革新了法醫調查領域。 在進行日常業務時,我們會留下大量遺傳物質,主要是通過皮膚細胞和頭發。 各國政府匯編了龐大的DNA“特征”數據庫,記錄了一系列不相關的遺傳標記。
For some systems, the probability of two people matching on all recorded genetic markers is estimated at one in one trillion (excluding identical twins). Given this number is over 100x the number of people on the planet, if a person’s DNA is found at the scene, you can be pretty sure they were there, right?
對于某些系統,兩個人在所有記錄的遺傳標記上匹配的概率估計為萬億分之一(不包括同卵雙胞胎)。 鑒于這個數字是地球上人數的100倍以上,如果在現場發現一個人的DNA,您就可以確定他們在那里。
Well, not necessarily. Following on from the previous examples, a tiny probability can inflate into something tangible when you have a large enough group of people.
好吧,不一定。 在前面的示例之后,當您有足夠多的人時,很小的概率就會膨脹為有形的東西。
In a country the size of the US (328 million people), a match rate of one in a trillion converts to a 1 in 3,000 chance of you having a genetic profile ‘twin’, somewhere out there. In 2019, there were 16k murders in the US. This means there are likely around 5 murders per year, for which the perpetrator’s DNA matches perfectly with that of another American (again, excluding identical twins). Even with the incredibly low probabilities involved, the power of the Birthday Paradox means that you shouldn’t convict based on DNA evidence alone, and other circumstantial evidence needs to be taken into consideration as well.
在美國這個龐大的國家(3.28億人口)中,萬億分之一的匹配率可以使您在某處具有“雙胞胎”遺傳特征的概率為3,000的三分之一。 2019年,美國發生了1.6萬起謀殺案。 這意味著每年可能有大約5起謀殺案,兇手的DNA與另一名美國人的DNA完全匹配(同樣,不包括同卵雙胞胎)。 即使涉及到的概率極低,“生日悖論”的力量也意味著您不應該僅憑DNA證據就定罪,還需要考慮其他間接證據。
It’s worth considering also, that DNA profiling systems have improved greatly in the last thirty years. Earlier in the application of the technology, probabilities of 1 in a billion were often quoted. This would have given around 5,000 murders with a DNA ambiguity.
同樣值得考慮的是,在過去的30年中,DNA分析系統已經有了很大的進步。 在該技術的早期應用中,經常引用十億分之一的概率。 這樣一來,大約有5,000起謀殺案帶有DNA歧義。
生日襲擊 (Birthday Attack)

The Birthday Paradox can be leveraged in a cryptographic attack on digital signatures. Digital signatures rely on something called a hash function f(x), which transforms a message or document into a very large number (hash value). This number is then combined with the signer’s secret key to create a signature. Someone reading the document could then “de-crypt” the signature using the signer’s public key, and this would prove that the signer had digitally signed the document.
可以將生日悖論用于對數字簽名的加密攻擊。 數字簽名依賴某種稱為哈希函數 f(x)的函數 ,該函數將消息或文檔轉換為非常大的數字(哈希值) 。 然后將此數字與簽名者的秘密密鑰結合在一起以創建簽名。 然后,閱讀文檔的人可以使用簽名者的公鑰“解密”簽名,這將證明簽名者已經對文??檔進行了數字簽名。
These signatures can be used to verify the authenticity of a document. By reading this article on Medium.com, you’re using a digital signature right now, via the HTTPS protocol. The security relies on the difficulty of finding another document with the same hash value as the signed original.
這些簽名可用于驗證文檔的真實性。 通過在Medium.com上閱讀本文,您現在正在通過HTTPS協議使用數字簽名。 安全性依賴于查找具有與簽名原始文檔相同的哈希值的另一個文檔的難度。
However, the Birthday Paradox lets us potentially abuse this system by attacking this hash function.
但是,生日悖論使我們有可能通過攻擊此哈希函數來濫用此系統。
Let’s say Bob is an authority that digitally signs contracts. We want to trick Bob into signing a fraudulent contract, without knowing, so that we can later suggest that he approved it. What we need to find are two contracts, one legitimate and one fraudulent, which produce the same hash value when passed through f(x).
假設鮑勃是通過數字方式簽署合同的機構。 我們想欺騙鮑勃在不知情的情況下簽署欺詐性合同,以便我們以后可以建議他批準該合同。 我們需要找到兩個合同,一個合法合同,一個欺詐合同,當通過f(x)傳遞時會產生相同的哈希值。
For each contract, we can identify many ways of subtly changing it, without altering its meaning. For example, you could add differing amounts of white-space at the end of each line, slightly alter the pixels in a logo, or make small changes to the formatting. In combination this gives us millions of technically different but semantically identical documents, which in Bob’s eyes would all get the stamp of approval. It also gives us millions of variations on the fraudulent document. If we find a pair of documents, one legitimate, one fraudulent, that produce the same hash, then we can pass the legitimate one to Bob for signing, and then use that signature to “prove” the authenticity of the fraudulent contract.
對于每個合同,我們可以找到許多在不改變其含義的情況下對其進行細微更改的方法。 例如,您可以在每行的末尾添加不同數量的空格,略微更改徽標中的像素,或對格式進行小的更改。 結合起來,我們得到了數以百萬計的技術上不同但語義相同的文檔,在Bob看來,這些文檔都將獲得認可。 它還為我們提供了數以百萬計的欺詐性文件變體。 如果我們找到一對產生相同散列的合法的,一個欺詐的文件,那么我們可以將合法的文件傳遞給Bob進行簽名,然后使用該簽名來“證明”欺詐性合同的真實性。
Thanks to the Birthday Paradox, the likelihood of at least one hash value collision between one of the legitimate and one of the fraudulent documents is much higher than might be expected, given the huge range of the hash function. In fact, the number of documents you need to produce is around the square root of the number of possible outputs of the hash function. This is improved by the fact that no hash function is perfectly uniformly distributed, which has led to many popular hashing algorithms becoming insecure.
多虧了生日悖論,鑒于散列函數的范圍很廣,合法文檔之一與欺詐文檔之一之間至少發生一次哈希值沖突的可能性比預期的要高得多。 實際上,您需要生成的文檔數量大約是散列函數可能輸出的數量的平方根。 沒有散??列函數可以完美地均勻分布這一事實得到了改善,這導致許多流行的散列算法變得不安全 。
翻譯自: https://towardsdatascience.com/the-birthday-paradox-ec71357d45f3
python生日悖論分析
本文來自互聯網用戶投稿,該文觀點僅代表作者本人,不代表本站立場。本站僅提供信息存儲空間服務,不擁有所有權,不承擔相關法律責任。 如若轉載,請注明出處:http://www.pswp.cn/news/389325.shtml 繁體地址,請注明出處:http://hk.pswp.cn/news/389325.shtml 英文地址,請注明出處:http://en.pswp.cn/news/389325.shtml
如若內容造成侵權/違法違規/事實不符,請聯系多彩編程網進行投訴反饋email:809451989@qq.com,一經查實,立即刪除!相關文章

統計0-n數字中出現k的次數

房價預測 search Search 中對數據預處理的學習

3.6.1.非阻塞IO

Symbol MC1000 掃描 沖突問題 把下面文件做成scanwedge.reg的注冊表文件,放在Application重起

rstudio 管道符號_R中的管道指南

蒙特卡洛模擬預測股票_使用蒙特卡洛模擬來預測極端天氣事件

iOS之UITraitCollection

直方圖繪制與直方圖均衡化實現

eclipse警告與報錯的修復

時間序列因果關系_分析具有因果關系的時間序列干預:貨幣波動

微生物 研究_微生物監測如何工作,為何如此重要

Linux shell 腳本SDK 打包實踐, 收集assets和apk, 上傳FTP

opencv:卷積涉及的基礎概念,Sobel邊緣檢測代碼實現及卷積填充模式

怎么查這個文件在linux下的哪個目錄

無法從套接字中獲取更多數據_數據科學中應引起更多關注的一個組成部分

web數據交互_通過體育運動使用定制的交互式Web應用程序數據科學探索任何數據...

C# .net 對圖片操作

數據類型之Integer與int
思想及實現)
PCA(主成分分析)思想及實現
