一句話總結——“所有架構都為了解決上一代模型的致命缺陷而生:CNN 解決參數爆炸,ResNet 解決梯度消失,Transformer 解決 RNN 無法并行,而 Mamba 則試圖一次解決 Transformer 的 O(N2) 與 RNN 的記憶瓶頸。”
1 每種架構的存在理由
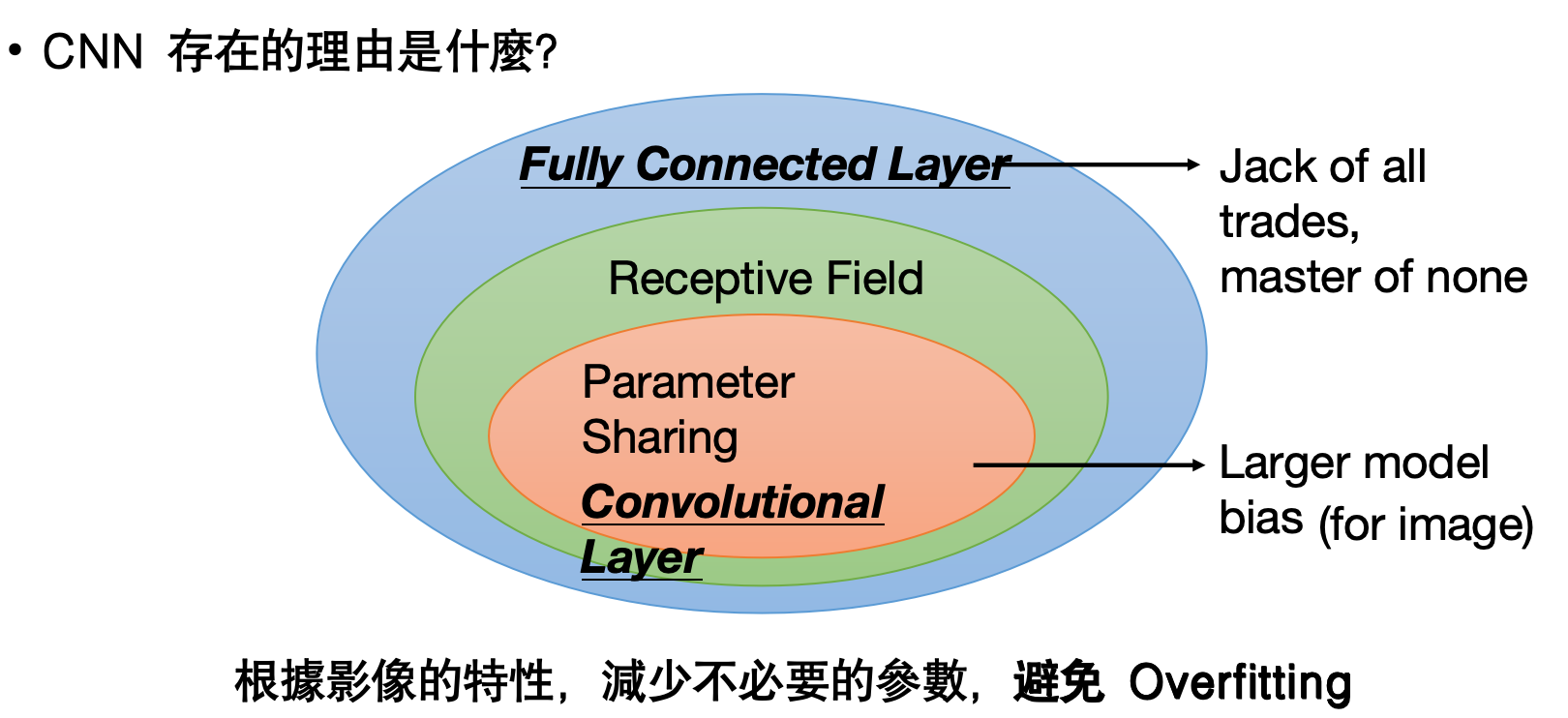
? CNN:局部感受野+參數共享→圖像任務參數量驟降,避免過擬合。
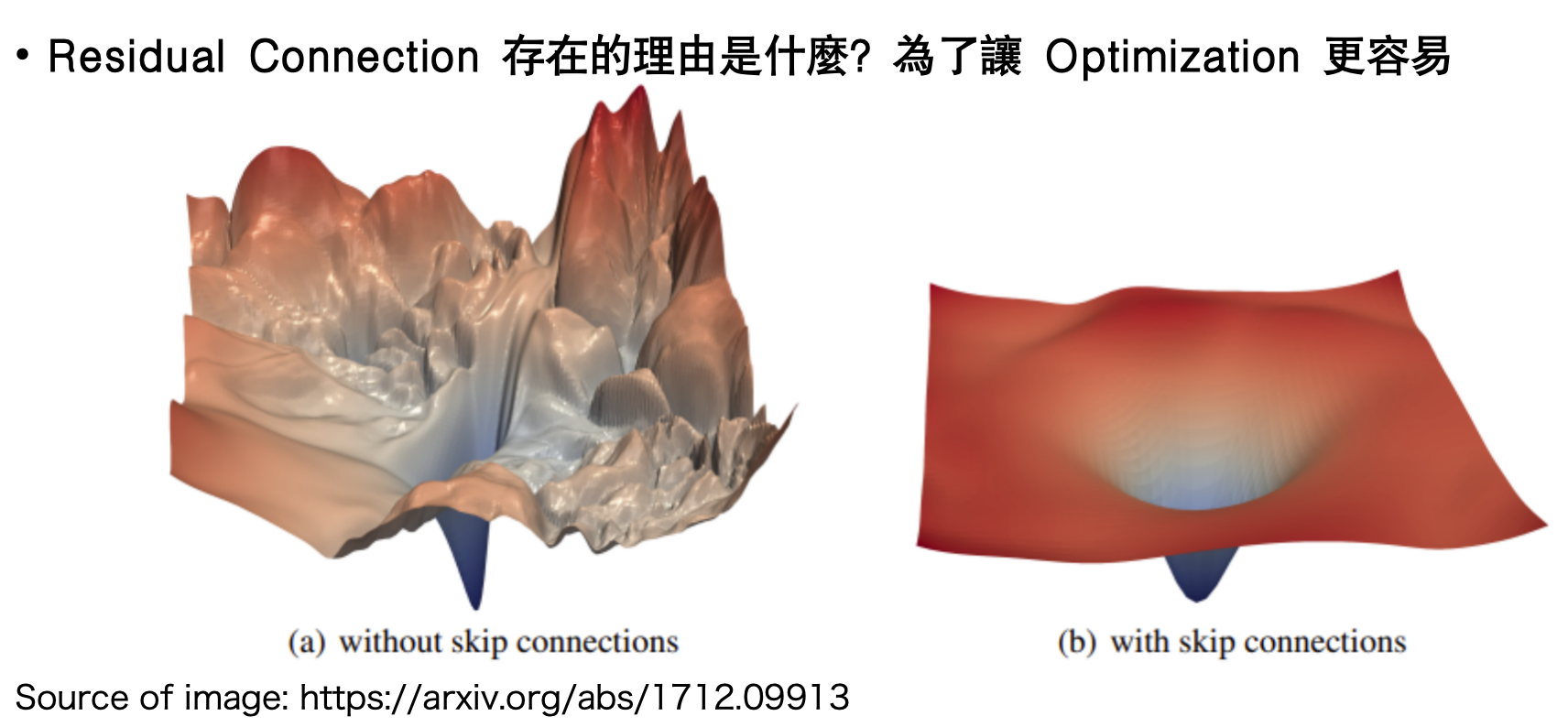
? Residual:跳躍連接→平滑損失曲面,讓深層網絡可訓練。
? Transformer:用 Self-Attention 替代 RNN,實現訓練期并行化。
2 從 RNN 到 Transformer:為什么改朝換代
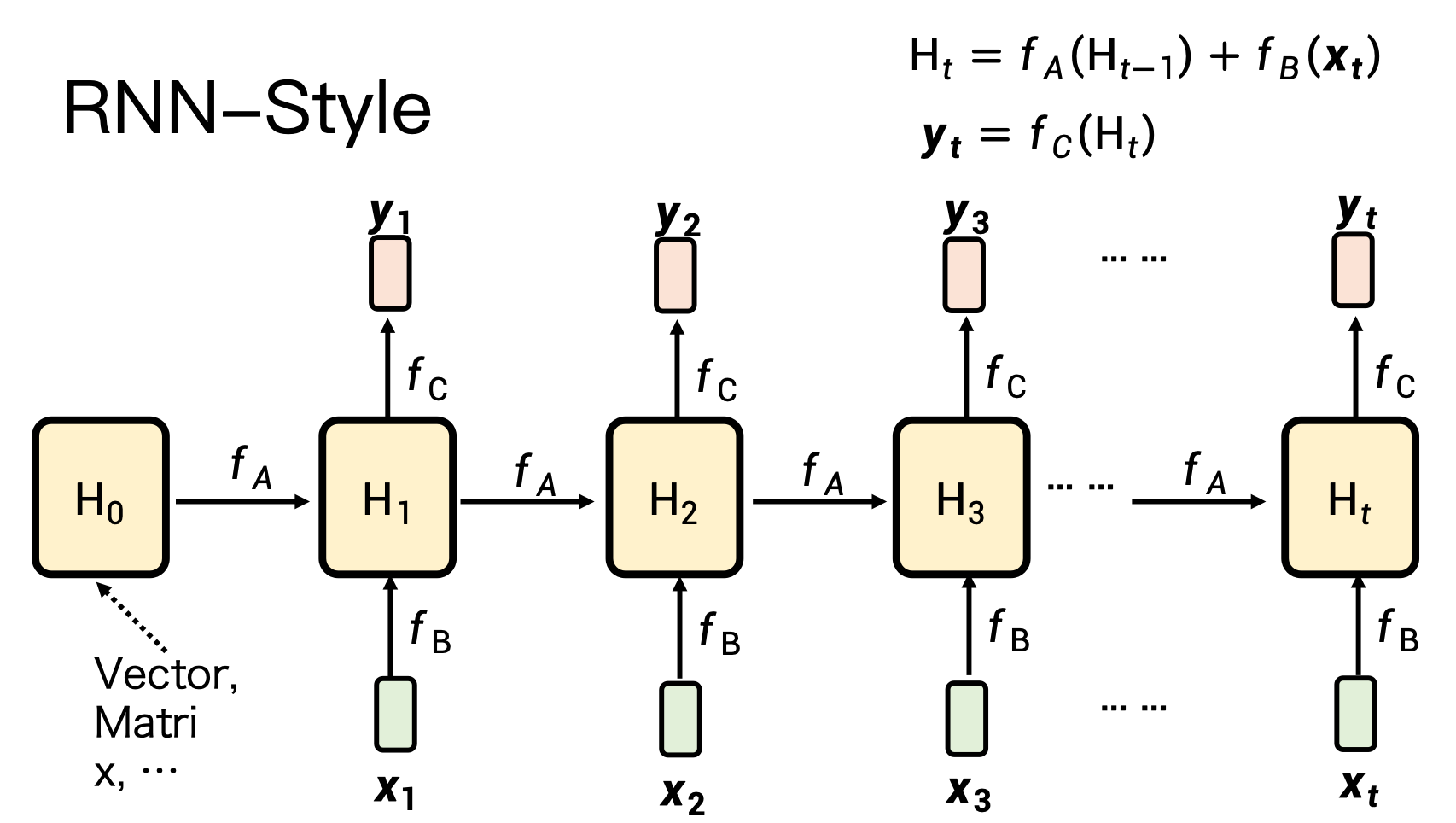
1)RNN 的痛點
– 順序計算:時間步 t 必須等 t-1,訓練無法并行。
– 記憶有限:隱狀態維度固定,長序列信息丟失。
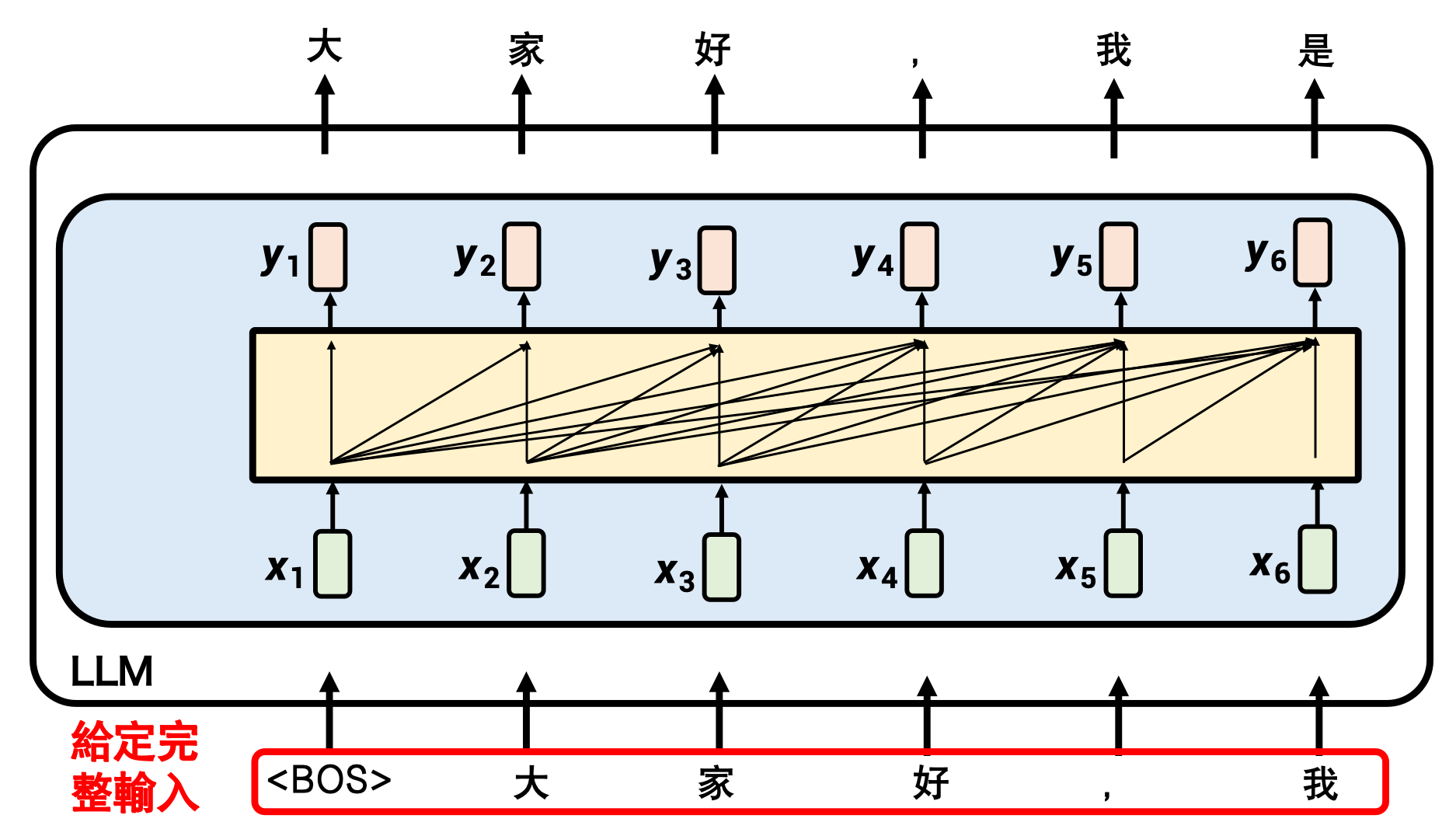
2)Self-Attention 的賣點
– 并行:所有位置一次性計算,GPU 友好。
– 長程依賴:任意兩位置直接相連,信息無損。
代價:推理時 O(N2) 計算/顯存隨長度爆炸。

self-attention: 并行,一次性給出輸出
3 繞不過去的 O(N2):Linear Attention
Linear Attention就是沒有softmax的Self-attention
把 softmax(QK^T)V 拆成 (Q(K^T V)),復雜度降到 O(N)。
訓練并行,推理像 RNN:一路累加 KV 狀態即可。
問題:無 softmax 的“歸一化”→記憶權重永不更新,長序列“記憶錯亂”。
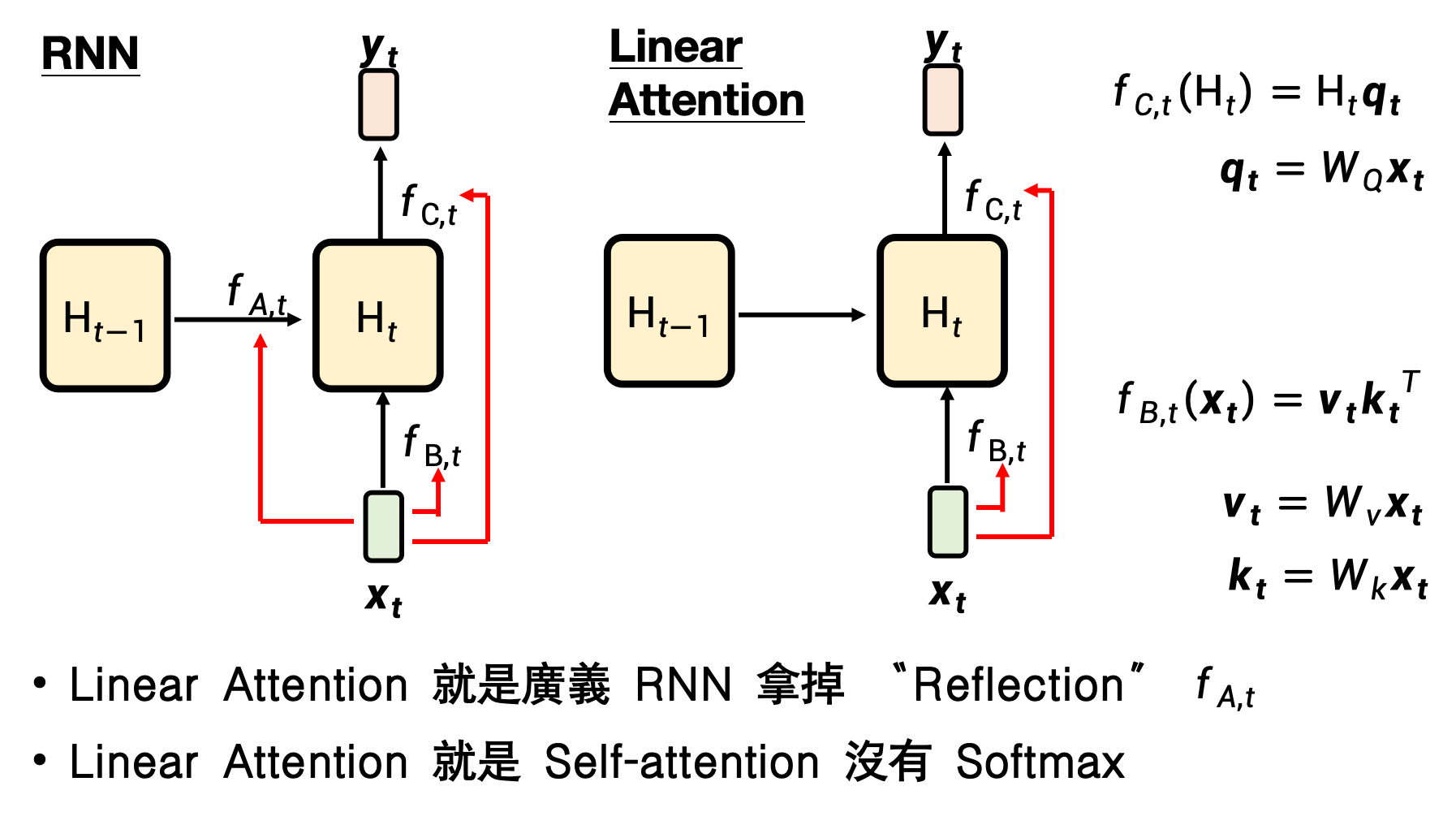
4 “可遺忘”的線性注意力 → RetNet / Gated Retention / DeltaNet
在線性注意力外再加“遺忘門”或“衰減因子”,讓舊記憶逐漸淡出;效果逼近 Transformer,推理仍是 RNN 形式。
5 新架構候選:Mamba(及其朋友)
核心創新
選擇性狀態空間模型(Selective SSM):讓 B,C,Δ 隨輸入動態變化,實現“內容感知”的讀寫與遺忘。
硬件感知并行算法:掃描(Scan)+ Kernel Fusion,在 GPU 上實現訓練期并行、推理期恒定顯存。
結果:
– 訓練并行度 ≈ Transformer
– 推理 O(N) 計算 + O(1) 顯存
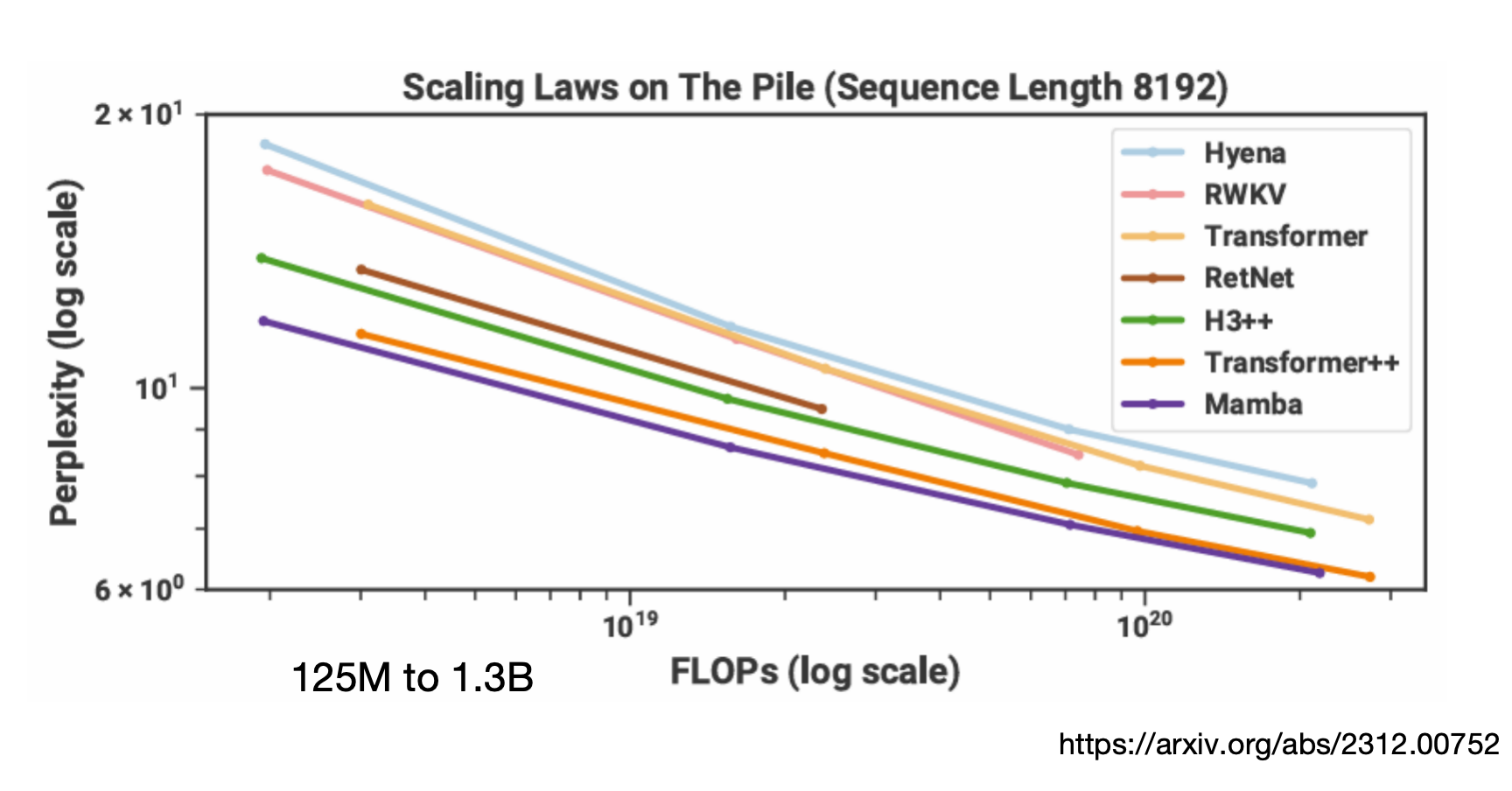
– 在 1B-7B 規模已追平或超越同尺寸 Transformer(如下圖)

6 課程彩蛋 & 延伸
? “MambaOut:視覺任務真需要 Mamba 嗎?”——論文結論:不一定。
? “Do not train from scratch”——把現成 Llama 權重蒸餾進 Mamba,節省算力。
? 最新競技場:Minimax-01、Titans 等繼續探索“測試時記憶”與混合架構。
??一個賭局:到2027年1月,transformer的架構還會是最佳模型的架構嗎?

給工程師的 3 句 memo
Transformer 仍是通用王者,但長序列場景(語音、視頻、RAG)先看 Mamba 類模型。
訓練期并行 + 推理期 O(1) 顯存是終極賣點,適合邊緣部署。
暫時不要從零訓 Mamba;先用 LoLCATs、Linger 等蒸餾方案“白嫖”現成權重。
--------疊甲--------
本篇課程博主也聽得一知半解,如有記得不對的地方歡迎指正




集成開發環境簡介)
![[論文閱讀] 軟件工程 | 告別“線程安全玄學”:基于JMM的Java類靜態分析,CodeQL3分鐘掃遍GitHub千倉錯誤](http://pic.xiahunao.cn/[論文閱讀] 軟件工程 | 告別“線程安全玄學”:基于JMM的Java類靜態分析,CodeQL3分鐘掃遍GitHub千倉錯誤)
 方法核心參數詳解)








)



