? ? ? ? ?
づ?ど
?🎉?歡迎點贊支持🎉

個人主頁:勵志不掉頭發的內向程序員;
專欄主頁:python學習專欄;
文章目錄
前言
一、文件是什么
二、文件路徑
三、文件操作
(1)打開文件
(2)關閉文件
(3)寫文件
(4)讀文件
四、上下文管理器
總結
前言
本章節我們就來了解了解我們計算機是如何保存我們的數據的,為什么我們的程序運行完數據就沒了,但是我們的計算機卻能在不斷的關機重啟中還能保存我們的數據,我們一起來看看吧。

一、文件是什么
變量是把數據保存到內存中,如果程序重啟/主機重啟,內存中的數據就會丟失。
要想能讓數據被持久化存儲,就可以把數據存儲到硬盤中,也就是在文件中保存。
在 Windows "此電腦中",看到的內容都是文件。
通過文件的后綴名,可以看到文件的類型,常見的文件類型如下:
- 電影文件(mp4)
- 歌曲文件(mp3)
- 圖片文件(jpg)
- 文本文件(tet)
- 表格文件(xlsx)
雖然它們里面保存的內容都不一樣,但是它們有一個共同點,就是它們的數據都是保存在硬盤上的。
在此電腦中,我們C盤、D盤等,里面的內容都是硬盤上的內容,也都是文件。文件夾也叫目錄,也是一種特殊的文件,叫目錄文件。
但即使都是文件,在文件里面存儲的內容和格式差異還是非常大的,還比較復雜。我們文章中重點學習的是文本文件。
二、文件路徑
一個機器上,會存在很多文件,為了讓這些文件更方便的被組織,往往會使用很多的 "文件夾"(也叫目錄)來整理文件。實際一個文件往往是放在一系列的目錄結構之中的。
為了方便確定一個文件所在位置,使用文件路徑來進行描述。
例如在這里打開一個 WPS 軟件。

它頭頂就是它的文件路徑。
![]()
在 D 盤中有個 WPS 目錄,WPS 目錄中有個 wps2024 目錄, wps2024目錄中有個 WPS Office 目錄.....。最后就可以看到這里有很多的文件。我們 WPS 相關的很多文件,就是包含在上述文件路徑之中。
所以我們為了表示 WPS.exe 這個文件位置,我們就可以通過路徑的方式來表示。
我們點一下頭頂的文件路徑。

我們可以按照 D:\WPS\wps2024\WPS Office\12.1.0.21915\office6\ + 文件名 找到這里面的任意一個文件。我們把這一串字符串稱之為文件的路徑。當然,知道了文件路徑,也就可以進一步的知道這個文件里都有啥了,就可以使用這個文件了。
文件路徑也可以視為是文件在硬盤上的身份標識,每個文件對應的路徑都是唯一的。
我們目錄名之間,使用 \ 來分割。但是使用 / 其實也行。在代碼中表示一個文件路徑,用 / 更多。因為使用 \ 不太方便,\ 在字符串中有特殊的含義,表示 "轉義字符"。\\ 在字符中才表示 字符 \。
三、文件操作
要使用文件,主要是通過文件來保存數據,并且在后續把保存的數據讀取出來。
但是要想讀寫文件,需要先 "打開文件",讀寫完畢之后還要 "關閉文件"。
(1)打開文件
使用內置函數 open 打開一個文件。
我們的系統是不會區分大小寫的。open 的第一個參數就是你要打開的文件路徑,我在這里的 D 盤的 Python 環境中新創建了一個 test.txt 文件,這里就打開這個文件,文件路徑就是:
D:/Python環境/test.txt
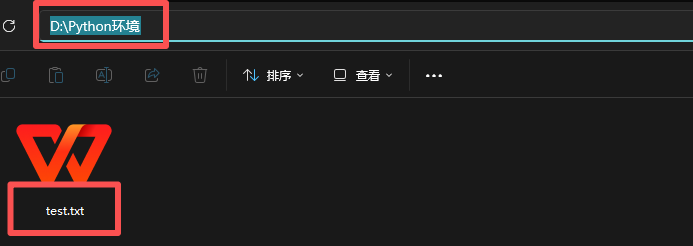
當然有的人的后面的文件類型是默認隱藏的,想要打開可以在查看中打開。
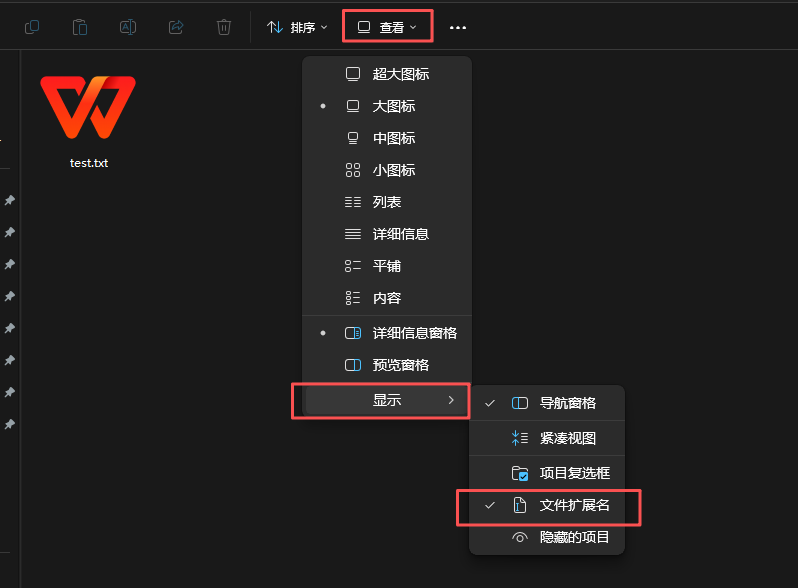
這樣就可以看到了。
我們第二個參數也是一個字符串。它的作用是決定了文件的打開方式。
- r 表示 read,按照讀的方式打開,只能讀,不能修改。
- w 表示 write,按照寫的方式打開,只能寫,不能讀。
- a 表示 append,也是寫的方式打開,但是是把內容寫到原有文件末尾。
# 使用 open 打開一個文件
f = open('d:/Python環境/test.txt', 'r')
print(f)
print(type(f))如果打開文件成功,返回一個文件對象,后續的讀寫文件操作都是圍繞這個文件對象展開。f 此處相當于 file 縮寫,意思是這是一個文件對象。

文件中涉及到了一些信息,文件路徑,打開方式以及編碼方式。而文件類型名字是 Python 內部給起的名字,我們沒必要糾結。
當然,如果路徑指定的文件不存在或者其他事情導致打開文件夾失敗,就會拋出異常。
# 使用 open 打開一個文件
f = open('d:/Python環境/test1.txt', 'r')
此時我們沒有文件 test1.txt,文件會打開失敗。

我們運行時就會拋出異常,錯誤信息就是文件沒找到。
open 的返回值是一個文件對象,我們文件內容是在硬盤上的,而此處的文件對象,則是內存上的一個變量。后續讀寫文件操作,都是拿著這個文件對象來進行操作的。此處的文件對象就像一個 "遙控器",我們借助這個遙控器間接訪問硬盤。
計算機中也把這樣遠程操控的 "遙控器" 稱為 "句柄"。
(2)關閉文件
使用 close 方法關閉已經打開的文件。
f.close()使用完畢的文件要記得及時關閉。打開文件其實就是在申請一定的系統資源,不使用文件的時候,資源就應該及時釋放。否則就可能造成文件資源泄露,進一步導致其他部分的代碼無法順利打開文件了。
正是因為一個系統的資源是有限的,因此一個程序能打開的文件個數是有上限的。
# 打開文件個數的上限
flist = []
count = 0
while True:f = open('d:/Python環境/test.txt', 'r')flist.append(f)count += 1print(f'打開文件的個數: {count}')
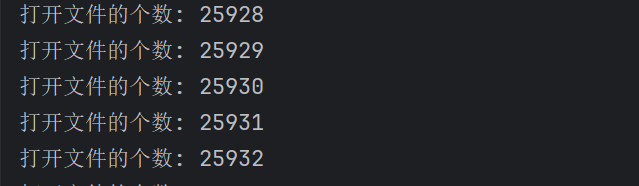
我們來運行一下上面的程序,這個程序就是一直循環打開我們的文件。每打開一個文件我們的count 計數器就會 +1。我們來看看一共可以打開多少文件。
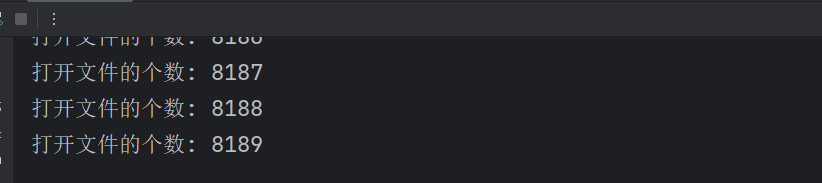
雖然這里顯示我們最多打開的文件數量是 8189,但是你不能說最多能打開 8189 個文件。因為在系統中,是可以通過一些設置項來配置能打開文件的最大數目的。但是無論配置多少都不是無窮無盡的,所以我們一定要記得關閉文件。"有借有還,再借不難"。
當然我們如果仔細觀察就會發現,我們這里打開文件的最大個數如果 +3 就是 2 的 13 次方,其實我們計算機中的很多數據都是按照 2 的多少次方這樣來表示的,所以在程序猿眼中,1000 不是一個很整齊的數字,1024(2 的 10 次方)才是一個比較整齊的數字。
也就是說其實計算機默認打開了 3 個文件,它們分別是:
1、標準輸入? ? ? ? 對應鍵盤
2、標準輸出? ? ? ? 對應顯示器
3、標準錯誤? ? ? ? 對應顯示器
我們的 print 就是通過標準輸出來讀取數據,而 input 就是通過我們標準輸入來讀取數據。
文件資源泄露,其實是一個挺重要的問題,因為它不會第一時間暴露出來,而是在角落里,冷不丁的偷襲一下。
我們 Python 中有一個重要的機制就是垃圾回收機制(GC),它會默認把我們不使用的變量進行釋放。
count = 0
while True:f = open('d:/Python環境/test.txt', 'r')count += 1print(f'打開文件的個數: {count}')由于我們打開的文件沒有使用,所以 Python 認為是垃圾而自動回收了。所以這里就可以一直打開文件。
但是我們也不能完全依賴 Python 的回收機制,因為這個釋放不一定及時,它還得判斷是否是垃圾。
(3)寫文件
文件打開之后,就可以寫文件了。
- 寫文件,要使用寫的方式打開,open 第二個參數設為 'w'
- 使用 write 方法寫入文件
# 使用 open 打開一個文件
f = open('d:/Python環境/test.txt', 'w')
f.write('hello')f.close()
我們運行程序可以發現我們的控制臺沒有任何的輸出。

此時我們打開我們的文件看看。

我們的文件中就有了我們打印的內容。
f = open('d:/Python環境/test.txt', 'r')
f.write('hello')f.close()我們如果使用 r 方式打開后去寫文件就會出現問題。

錯誤信息為不支持此操作。
當然,我們寫方式有兩種,一種是直接寫方式打開,另外一種是追加寫方式打開。它們之間有所不同。
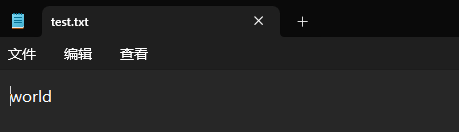
我們往剛才的文件中接著寫一些內容看看,我們已經往文件中寫了一個 "hello" 了,我們繼續寫一個 "world" 看看。
f = open('d:/Python環境/test.txt', 'w')
f.write('world')f.close()我們的 hello 沒了。
我們這次打印一個空字符串看看。
f.write('')
我們文件啥也沒了。
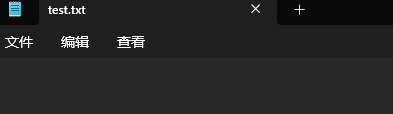
所以如果直接寫方式打開的文件,系統會把文件原本的內容清空。
如果想要關注我們的舊的數據,我們就得使用 a 的方式打開文件,這種方式不會清空,寫的內容會追加在原有內容末尾。
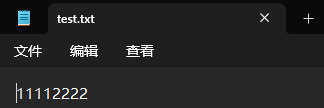
f = open('d:/Python環境/test.txt', 'a')
f.write('1111')f.close()此時我們文件就會寫入 '1111'。

此時我們再寫入 '2222'。
f.write('2222')我們原有的數據沒有清空,而是在后面繼續寫入我們想要的內容了。
如果想要換行,我們只需要輸入換行符即可,換行符是一種轉義字符,它的寫法是 \n。
f.write('\n2222')
如果文件對象已經關閉,那么意味著系統中和該文件相關的內存資源已經釋放了,強行去寫就會出異常。
f = open('d:/Python環境/test.txt', 'w')
f.close()f.write('3333')
(4)讀文件
- 讀文件內容需要使用 'r' 的方式打開文件。
- 使用 read 方法完成讀操作,參數表示 "讀取幾個字符"
先準備一個文件,文件內容如下。
床前明月光
疑是地上霜
舉頭望明月
低頭思故鄉
我們針對這一首詩來進行讀文件操作。
# 使用 read 讀取文件內容,指定讀取幾個字符
f = open('d:/Python環境/test.txt', 'r')
result = f.read(2)
print(result)
f.close()我們這樣去嘗試讀取文件中前兩個字符,運行時卻報錯了。
![]()
這是關于一個字符編碼的問題,在我們的代碼中,我們要嘗試讀取一個中文。中文和英文類似,在計算機中都是使用 "數字" 來表示字符的,但是具體時那個數字對應哪個漢字,在計算機中有多個版本,現在最主流的版本有兩個,一個是 GBK,另一個是 UTF8。我們在實際開發時就需要保證,文件內容的編碼方式和代碼中操作文件的編碼方式匹配。
所以我們得先確認一下我們文件的編碼格式。
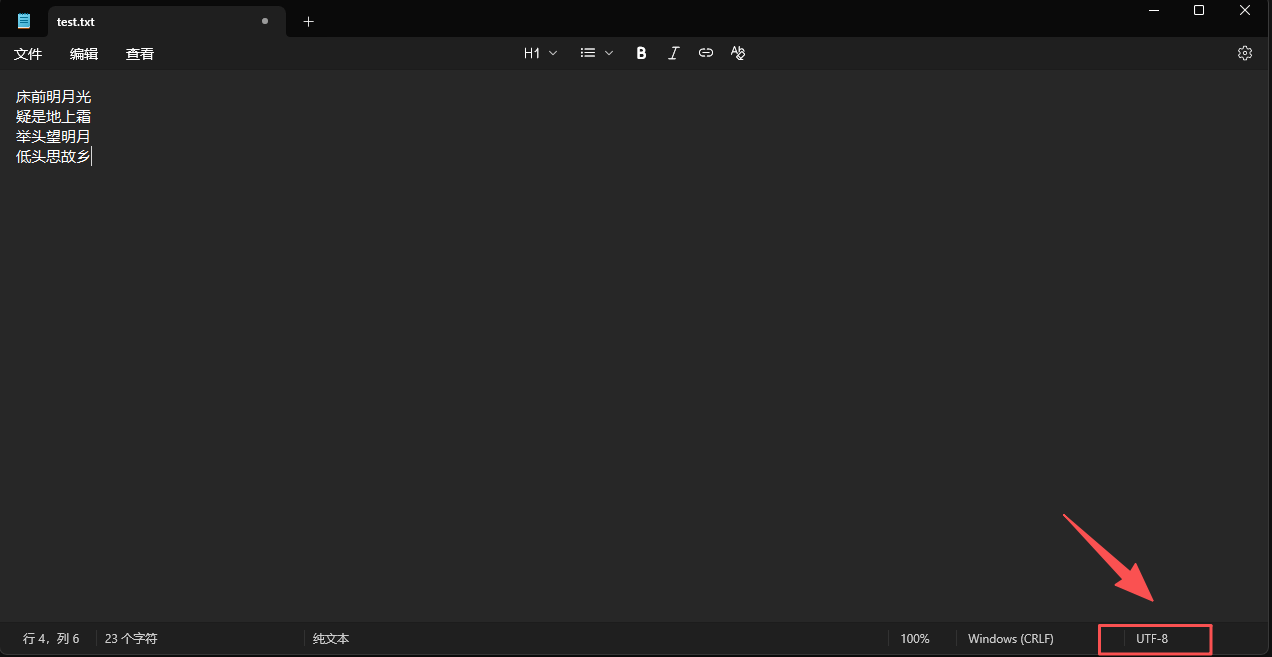
所以我們可以看到我們的格式是 UTF8,所以我們得讓我們代碼中按照 UTF8 來解析,但是代碼中默認是GBK,所以就會報錯。當然,相比于 GBK,UTF8 是使用的更廣泛的編碼方式。
我們在 open 后面再加一個 encoding = 'utf8' 即可。
# 使用 read 讀取文件內容,指定讀取幾個字符
f = open('d:/Python環境/test.txt', 'r', encoding = 'utf8')
result = f.read(2)
print(result)
f.close()我們前面兩個是位置參數,而 encoding 是關鍵字參數,這里就能夠看到我們位置參數和關鍵字參數是可以混著用的。
![]()
如果文件是多行文本,可以使用 for 循環一次讀取一行。
f = open('d:/Python環境/test.txt', 'r', encoding = 'utf8')
for line in f:print(f'line = {line}')
f.close()此處的 line 是我們創建的一個局部變量,它表示我們文件中每一行的內容,第一次循環就對應第一行,第二次循環就對應第二行以此類推,直到讀完循環就結束了。

但是我們發現打印的時候行與行之間帶了一個空行。之所以多了一個空行是因為本來讀到的文件內容的末尾就帶有換行符(\n)。此處使用 print 打印又會自動加一個換行符(\n)。
我們可以給 print 再多設定一個參數,修改 print 自動換行的行為。
f = open('d:/Python環境/test.txt', 'r', encoding = 'utf8')
for line in f:print(f'line = {line}', end = '')
f.close()此時我們 end 參數就表示我們每打印一次就要在末尾加一個什么,默認是換行符(\n)。

我們還可以使用 readlines 方法直接把整個文件所有內容都讀出來,按照行組織到一個列表里。
f = open('d:/Python環境/test.txt', 'r', encoding = 'utf8')
lines = f.readlines()
print(lines)
f.close()![]()
四、上下文管理器
我們寫代碼時,還是很容易忘記我們的文件的,所以為了確保我們的關閉可以及時有效的進行,Python 就引入了上下文管理器來幫助我們解決容易忘記關閉的問題。
有的時候我們很難避免不會忘記關閉文件。
def func():f = open('d:/Python環境/test.txt', 'r', encoding='utf8')# 中間代碼中如果有條件判斷,函數返回,拋出異常等if cond:# 進行條件處理return# 另外一些代碼f.close()此時我們就有可能造成內存泄漏。
此時我們使用上下文管理器就能解決這個問題
def func():with open('d:/Python環境/test.txt', 'r', encoding = 'utf8') as f:# 進行文件處理的邏輯if cond1:returnif cond2:return我們通過 as 賦值,此處的 f 仍然是 open 的返回值,但是已經被 with 監控起來了。此時我們不管有多少個 return 都沒有關系了,因為只要我們結束了下面的 with 的代碼塊,我們 with 就會自動調用 close 去釋放資源。
這樣就可以避免資源的泄露。
總結
以上便是我們文件的基本操作,通過本章學習,我們就可以明白我們計算機的內存和外存該如何交互,以及我們在使用一些數據時計算機是怎么保存我們的數據的,大家下去可以在 Python 庫中學習更多的內容,當然基礎也得好好吸收。
?
🎇堅持到這里已經很厲害啦,辛苦啦🎇
? ? ? ? ?
づ?ど


:開運算和閉運算)
)




 vp補題)











