一、KVM 虛擬機環境
GPU:4張英偉達A6000(48G)
內存:128G
海光Cpu:128核
大模型:DeepSeek-R1-Distill-Qwen-32B
推理框架Vllm:0.10.1
二、四個性能指標介紹
2.1、TTFT:Time to First token
首次生成token時間(ms),TTFT 越短,用戶體驗越好,TTFT 受 prompt 長度影響很大,如果輸入的prompt越長,TTFT就越長。
2.2、TPOT:Time per output token
除首token之后,每個 token 的平均生成時間(ms),TPOT 反映模型的解碼速度,受 GPU 性能、KV Cache、batch size 影響。
2.3、ITL:Inter-Token Latency
兩個連續 token 之間的實際時間間隔(ms),如果 ITL 波動大,說明生成不平穩。
2.4、E2EL:End-to-End Latency
從首token到最后token完成的全部時間(ms)
E2EL=TTFT + TPOT × 輸出長度
2.5舉個例子
假設你問模型:“請寫一篇 1000 字的作文。”
TTFT:800ms(你等了 0.8 秒看到第一個字)
TPOT:60ms(每個字平均 60 毫秒)
ITL:[58, 62, 59, 70, 57, ...](有時快,有時慢)
E2EL:800 + 60 × 999 ≈ 60.74 秒
→ 你等了 1 分鐘才看到完整答案。
2.6、優化目標
想優化 | 關注指標 | 方法 |
讓模型“更快響應” | TTFT | 減少 prompt 長度、啟用 chunked prefill、優化 KV Cache |
讓回答“說得更流暢” | TPOT | 升級 GPU、使用 vLLM、減少 batch size |
讓生成“更穩定” | ?ITL | 避免資源爭搶、使用 PagedAttention |
讓整體“更快完成” | ?E2EL | 降低 TTFT 和 TPOT,或減少輸出長度 |
三、測試過程
3.1、啟動命令
vllm serve "/mnt/data/models/DeepSeek-R1-Distill-Qwen-32B" \--host "127.0.0.1" \--port 9400 \--gpu-memory-utilization 0.7 \--served-model-name "qwen32b" \--tensor-parallel-size 4 \--chat-template "/mnt/data/models/qwen32_nonthinking.jinja" \--chat-template-content-format "string" \--enable-chunked-prefill \--max-model-len 65536?\--max-num-seqs 32 \--max-num-batched-tokens 131072?\--block-size 32 \--disable-log-requests3.1.1、如何設置max-model-len?
max-model-len最大可以設置為131072(對應config.json的max_position_embeddings)。
哪max-model-len到底設置多大合適呢?
場景 | 推薦?max-model-len |
普通對話、摘要 | 32768 |
長文檔處理 | 65536 |
超長上下文(如整本書) | 131072 |
我的應用牽涉長文檔處理,所以我采用65536。
3.1.2、如何設置max-num-batched-tokens?
max-num-batched-tokens 占用顯存,利用下面的公式來計算max-num-batched-tokens設置多大合適?
KV Cache Size (bytes)=2×num_layers×num_kv_heads×head_dim×dtype_size*max-num-batched-tokens
=2*64*8*128*2*131072
=32 GB
大概每張GPU有8G顯存用戶kv緩存。
剩余:48*0.7-16-8=9.6G(用于其他,如調度開銷)
參數 | 含義 | 范圍 |
--max-model-len | 單個請求的最大 token 數(prompt + 生成) | 單 sequence |
--max-num-batched-tokens | 所有并發請求的 token 總數上限(用于批處理調度) | 整個 batch |
3.2、測試命令(sharegpt )
vllm bench serve \--backend vllm \--base_url http://127.0.0.1:9400 \--model qwen32b \--tokenizer /mnt/data/models/DeepSeek-R1-Distill-Qwen-32B \--endpoint-type openai-chat \--endpoint /v1/chat/completions \--dataset-name sharegpt \--dataset-path /mnt/data/tools/vllm/ShareGPT_V3_unfiltered_cleaned_split.json \--sharegpt-output-len 1024 \--percentile-metrics ttft,tpot,itl,e2el \--metric-percentiles 95,99 \--num-prompts 16 \--request-rate 8我的應用要求輸出token都比較大,所以我設置成1024。
注:sharegpt-output-len不要設置2048及以上,否則報
Token indices sequence length is longer than the specified maximum sequence length for this model (29557 > 16384). Running this sequence through the model will result in indexing errors
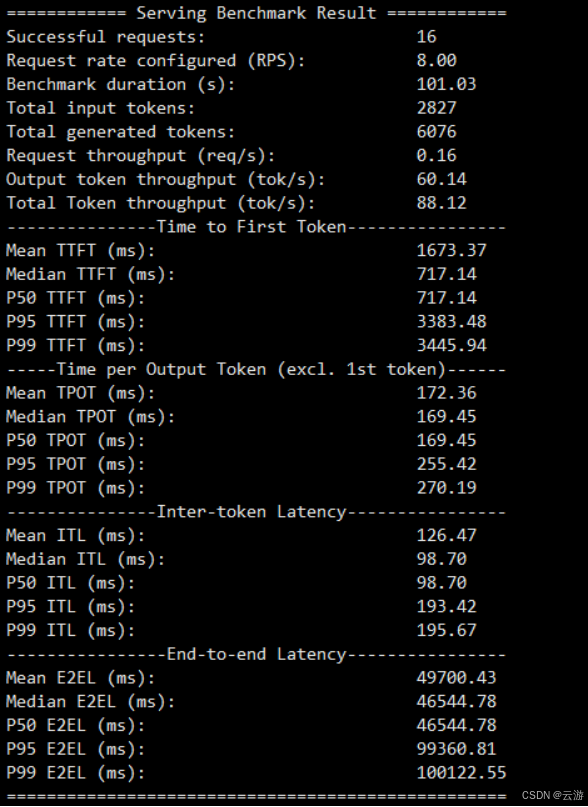
3.2、測試結果



集成開發環境簡介)
![[論文閱讀] 軟件工程 | 告別“線程安全玄學”:基于JMM的Java類靜態分析,CodeQL3分鐘掃遍GitHub千倉錯誤](http://pic.xiahunao.cn/[論文閱讀] 軟件工程 | 告別“線程安全玄學”:基于JMM的Java類靜態分析,CodeQL3分鐘掃遍GitHub千倉錯誤)
 方法核心參數詳解)








)




