本文來自作者 莫爾索 的 企業級 AI 應用開發與最佳實踐指南, 歡迎閱讀原文。
大家好,我之前出版的《LangChain 編程:從入門到實踐》一書獲得了良好的市場反響和讀者認可。近期推出了第二版,我對內容進行了大幅更新:近 60% 的文字內容和全部代碼示例均已重寫。本次修訂的目標,是讓本書不再僅聚焦 LangChain 框架本身,而是從 LangChain 全家桶中各類工具的設計理念出發,深入探討企業級 AI 應用的構建方法與當前 AI 工程化的最佳實踐。
LangChain 不止是一個框架
日常交流下來,發現很多人對 LangChain 的印象還停留在一個「功能臃腫、過度抽象」的 AI 應用開發框架,這是一種常見的誤解。事實上,自 0.3 版本起,LangChain 框架本身已經變得更加輕量和高效。更重要的是,LangChain 不只是一個開發框架,它代表了一整套完整的 AI 應用開發解決方案,涵蓋了從原型設計、Beta 測試到生產部署的全流程,已被 Replit、Lovable 等知名 AI 產品所采用。
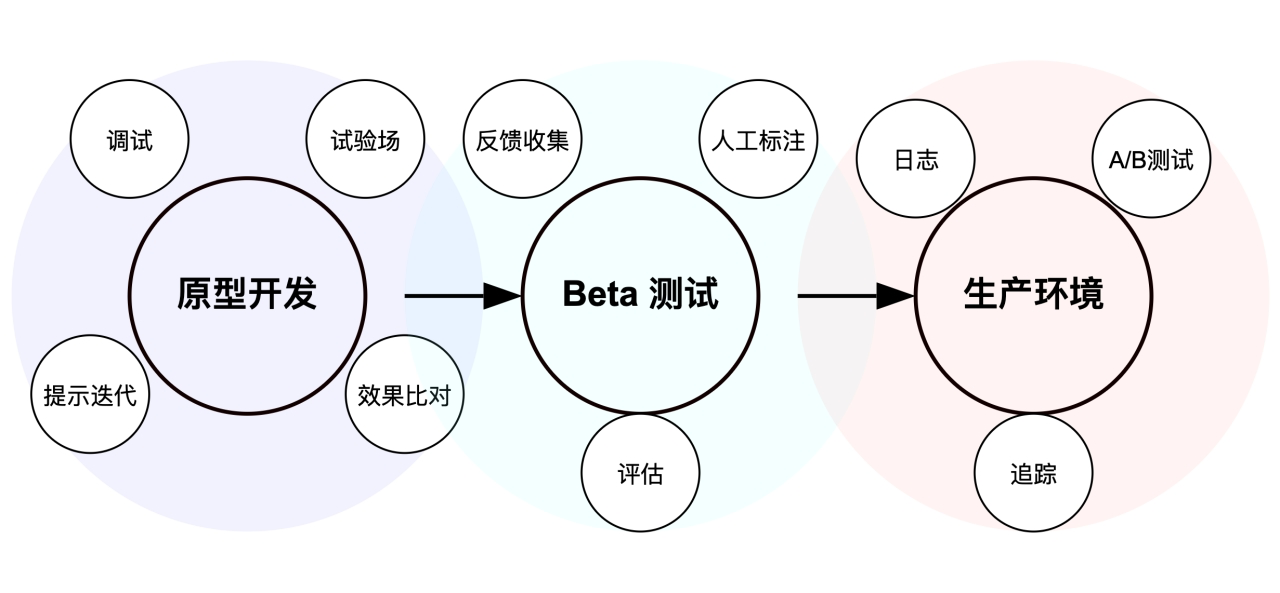
LangChain 生態系統包含七個關鍵工具,能夠高效支持 AI 應用的構建。無論是基于規則的工作流(使用 LangChain)、具備復雜狀態管理的 Agentic 工作流(結合 LangChain 與 LangGraph),還是完全自主的 Agent 模式(使用 LangGraph),都能找到相應的工具支持:
- 使用 LangChain CLI 創建標準化項目結構:
pip install langchain-cli - 利用 LangChain 核心框架快速進行原型開發:
pip install langchain - 通過 LangServe 快速啟動應用 API 服務:
pip install "langserve[all]" - 使用 LangSmith 實現 AI 應用的可觀測性、評估與生產監控:
pip install langsmith - 通過 LangGraph 實現復雜智能體工作流的編排:
pip install langgraph - 使用 LangGraph Studio 進行智能體工作流的可視化設計
- 利用 LangGraph Platform 實現智能體工作流的生產部署
LangChain 早期版本通過“鏈”的概念,將 AI 應用中的基礎模型、提示模板、外部數據和 API 工具等組件模塊化串聯,提供了高度靈活的設計能力。這種架構激發了開發者社區的廣泛集成,使 LangChain 成為功能全面、生態豐富的 AI 開發“瑞士軍刀”。隨著 Agentic 工作流的興起,LangChain 團隊推出了 LangGraph,采用更靈活的狀態圖模型,以應對包含循環、條件判斷和狀態控制等復雜邏輯的智能體任務。
使用 LangChain 構建企業級 AI 應用
LangChain 通過其兩大開源框架 —— LangChain 和 LangGraph,以及兩款商業化工具 —— LangSmith 和 LangGraph Platform,支持企業級 AI 應用的構建。其中,商業化工具已被用于多家知名 AI 產品的生產環境托管,而開源框架則廣泛受到大型企業的采納。以下是一些典型的企業級 AI 應用案例。

字節打造通用 Agent
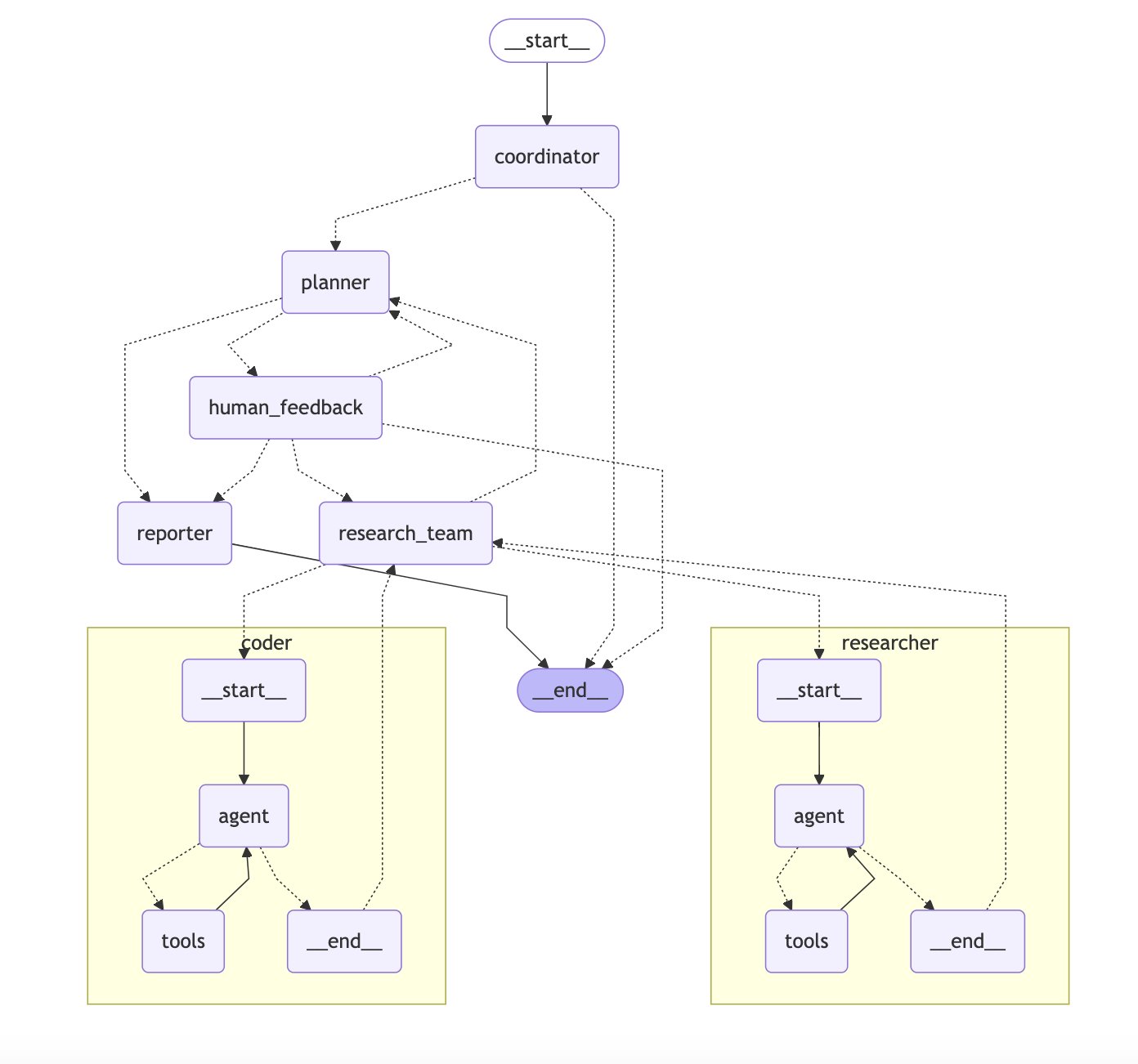
字節跳動開源的 DeerFlow 是一個成熟的通用 Agent 類工具,在 GitHub 上已獲得 15,700 顆 Star。其項目依賴通過 pyproject.toml 配置,核心基于 LangChain 與 LangGraph 構建。
dependencies = ["httpx>=0.28.1","langchain-community>=0.3.19","langchain-experimental>=0.3.4","langchain-openai>=0.3.8","langgraph>=0.3.5","readabilipy>=0.3.0",..."langchain-mcp-adapters>=0.0.9","langchain-deepseek>=0.1.3",
]
下面是 DeerFlow 架構圖,使用 LangGraph 自帶的工具可以直接導出(print(graph.get_graph().draw_mermaid()))。
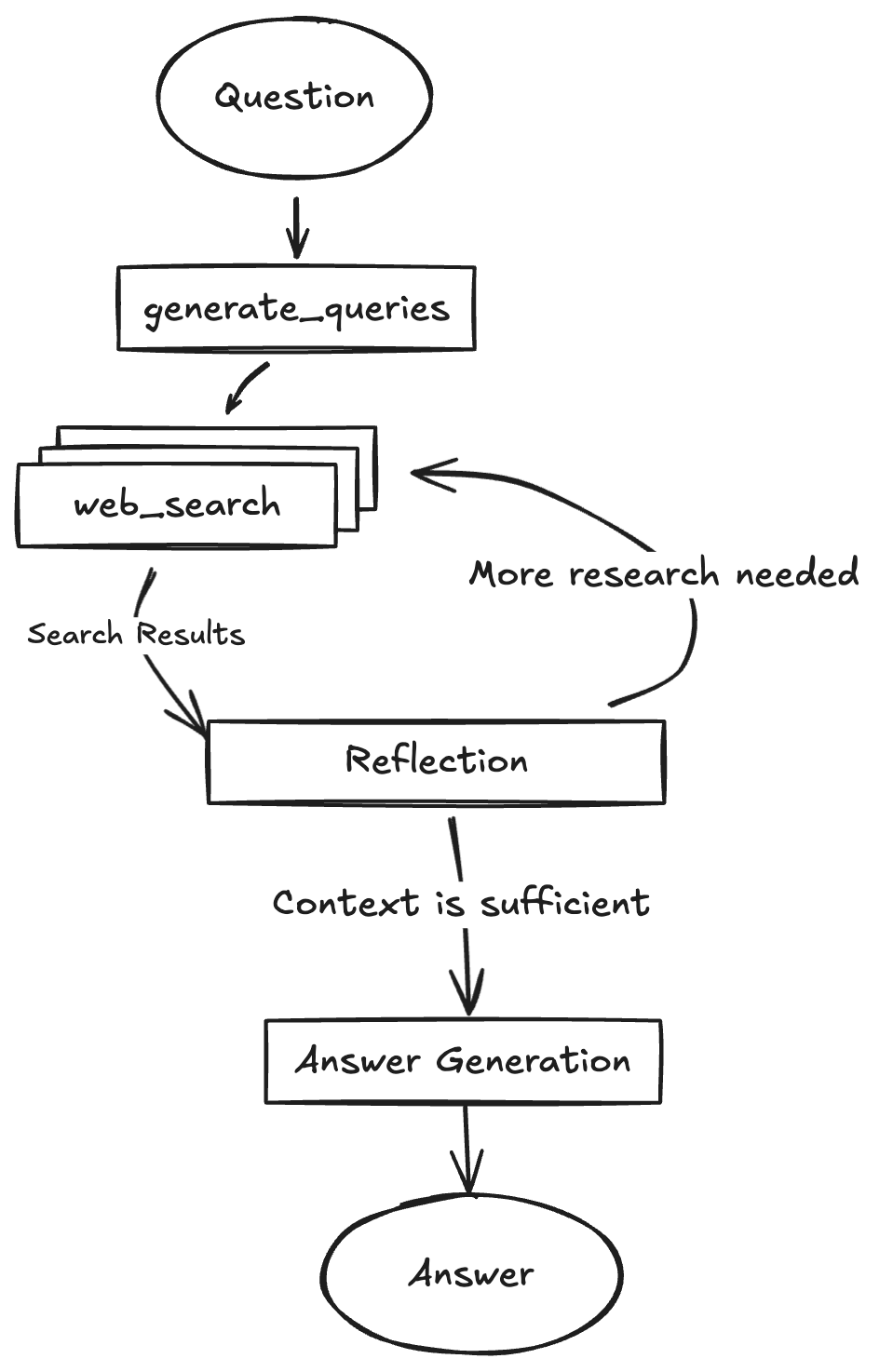
谷歌實現 Deep Reasearch
谷歌開源的 gemini-fullstack-langgraph-quickstart 項目在 GitHub 上獲得 15,900 顆 Star🌟,展示了如何構建一個高度完善的深度研究(Deep Research)類產品,核心基于 LangGraph 。
阿里云百煉 AI 應用觀測
以下是阿里云大模型服務平臺“百煉”的應用觀測功能截圖。
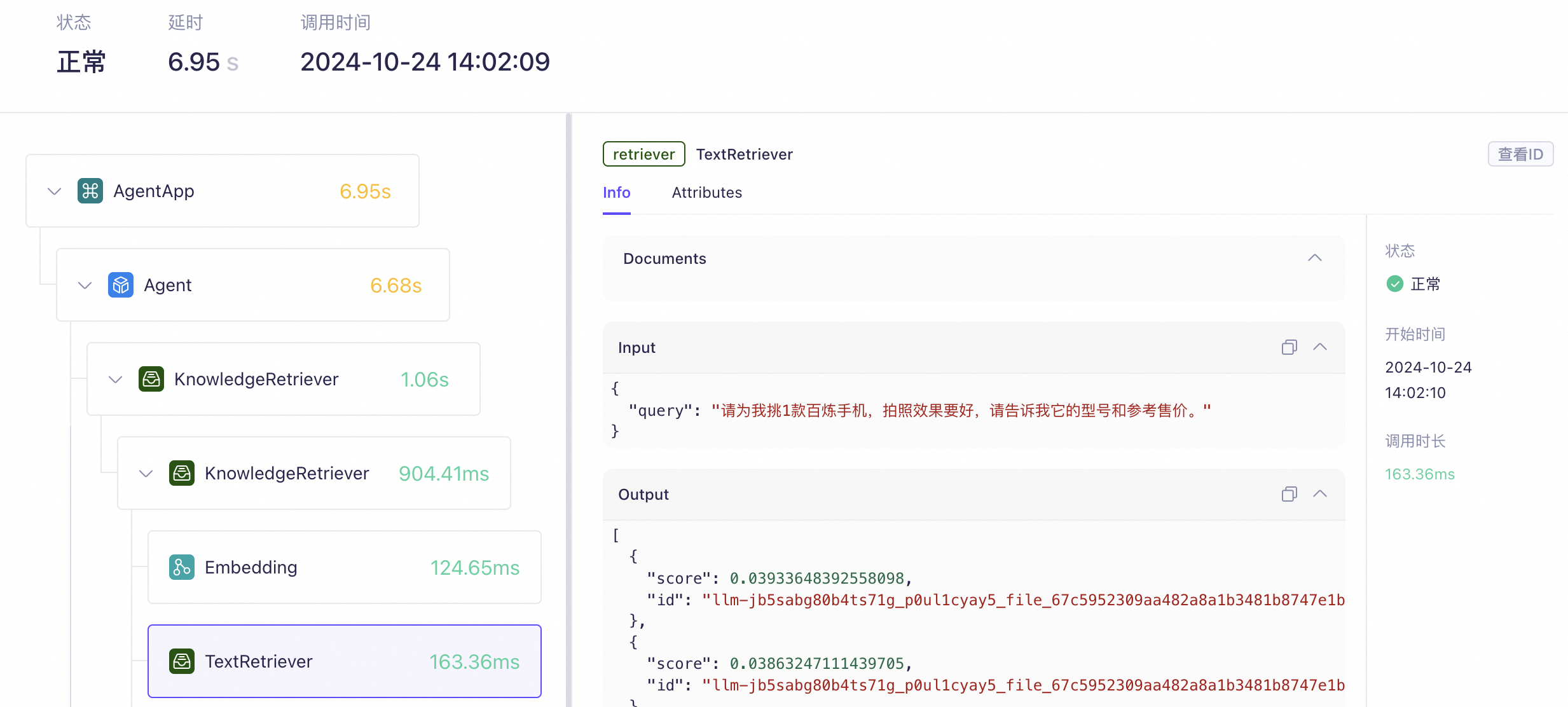
對比來看,LangSmith 提供了指標(metric)、追蹤(trace)和日志(log)等核心能力,百煉的應用觀測功能正是對標 LangSmith 的設計,旨在支持生產環境中 AI 應用的全面監控與分析。
扣子羅盤的觀測功能
最近,AI 領域值得關注的一個事件是,在 C 端用戶中廣受好評的扣子平臺宣布開源。其中,廣受好評的 Coze Loop(扣子羅盤)的觀測機制,借鑒了 LangChain 的設計理念。根據官方文檔 的說明,「扣子羅盤基于 LangChain 的 callback 機制,提供一鍵集成能力,可自動完成 Trace 數據的上報」。以下示例展示了如何在 LangChain 的 LCEL 模式中無縫集成扣子羅盤的 Trace 功能,從而實現對 AI 模型調用過程的監控與分析。
import osimport cozeloop
from langchain_core.runnables import RunnableConfig
from langchain_openai import ChatOpenAI
from langchain_core.output_parsers import StrOutputParserfrom cozeloop.integration.langchain.trace_callback import LoopTracerdef do_lcel_demo():# 配置CozeLoop環境變量os.environ['COZELOOP_API_TOKEN'] = '{your_token}'os.environ['COZELOOP_WORKSPACE_ID'] = '{your_workspace_id}'# 創建cozeloop clientclient = cozeloop.new_client()# 注冊callbacktrace_callback_handler = LoopTracer.get_callback_handler(client)llm_model = ChatOpenAI()lcel_sequence = llm_model | StrOutputParser()output = lcel_sequence.invoke(input='用你所學的技巧,幫我生成幾個有意思的問題',config=RunnableConfig(callbacks=[trace_callback_handler]))print(output)# 程序退出前,需要調用Close方法,否則可能造成trace數據上報丟失。Close后無法再執行任何操作。client.close()if __name__ == "__main__":do_lcel_demo()
類似的案例還有很多,這里不再一一列舉。關于如何開發可觀測性插件與企業自有 IT 系統集成的實現方法,我已在第一版中進行了詳細介紹,第二版會從設計角度進行更詳細的論述。

LangChian 為什么值得學習
需要再次強調,本書第二版的關注點不局限于 LangChain 框架本身,而是能夠從 LangChain 全家桶中的各類工具設計思想出發,探討企業級 AI 應用的構建過程以及 AI 工程化的最新最佳實踐。盡管市面上存在眾多可替代的框架、工具和產品,LangChain 的優勢在于能夠提供 Agent 應用從設計、開發、評估、部署到監控的完整實踐路徑。通過這一路徑,讀者可以先動手實踐,再結合自身的積累與判斷力,去評估甚至設計更優秀的框架。在此基礎上,讀者將能更清晰地辨別其他框架在設計上的優劣,深入理解其組件背后的設計原則,最終成長為合格的 Agent 應用開發者或 Agent 平臺架構師。
領先的 Agent 架構設計
Claude Code 最新推出的 Subagents(子智能體) 功能,是指預配置的 AI 角色,專為執行特定任務而設計,具備獨立的上下文窗口和定制的系統提示,有助于提高任務處理效率。從設計角度來看,Subagents 與 LangGraph 中的 Subgraphs(子圖) 相似:子圖本質上是嵌套在另一個圖中的圖,作為其中的一個節點使用。
該功能適用于以下場景:
- 構建多智能體系統:適用于在復雜系統中引入多個獨立的任務處理單元。
- 代碼復用:當多個流程圖中需要重復使用一組具有共同狀態的節點時,可將這些節點封裝為子圖,并在多個父圖中調用。
- 團隊協作:在不同團隊需獨立開發流程圖的不同部分時,可將每個部分定義為一個子圖。只要保持子圖接口(即輸入和輸出格式)一致,父圖即可在不了解其實現細節的前提下進行構建。
在多個子智能體之間如何實現平滑協作?LangGraph 提供了一種稱為 交接(Handoff) 的機制。其核心思想是:當某個智能體無法獨立完成任務時,可將對話流轉交給更合適的智能體,而用戶無需重復描述問題。這一概念也體現在 OpenAI Agents SDK 的設計中。
此外,在涉及人機協作(Human-in-the-loop)的場景中,如何在適當時機通知人工介入,以及智能體如何從故障中恢復等問題,LangGraph 也提供了相應的機制設計。
Agent 應用的構建過程應保持透明
HumanLayer 創始人 Dex Horthy 借鑒了「12-Factor App」的理念,提出了「12-Factor Agents」原則(相關視頻)。其核心思想是:將 Agent 視為軟件,將 LLM(大語言模型)視為可調用的純函數,開發者應掌控整個流程。LLM 的作用是生成結構化的 JSON 輸出,由確定性代碼解析并執行,而不是隱藏在抽象的“工具調用”背后。Agent 的核心控制邏輯,包括循環與分支判斷,應由開發者編寫代碼實現;LLM 僅負責決定“下一步該做什么”。流程的執行、中斷與重試等操作,均由開發者編寫的邏輯控制。
LangChain 可能從其早期框架設計中吸取了“過度抽象、封裝過重”的教訓。其后續推出的 LangGraph,成為目前開源 Agent 框架中控制最靈活、自由度最高的一個。我在這篇文章中曾深度分析過包括 OpenAI 的 Agents SDK、Google 的 ADK、Crew AI、Agno 和 AutoGen 等主流框架的設計思路。使用 LangGraph 構建 Agent 時,開發者可以完全掌控流程的執行、中斷與重試。
此外,LangGraph 支持顯式且統一地管理 Agent 的運行狀態與業務狀態(如對話歷史),并將這些狀態存儲在數據庫中。通過簡單的 API,即可實現 Agent 的啟動、暫停與恢復,非常適合處理長周期任務。
第二版主要更新內容
在介紹完 LangChain 生態之后,我們來看看本書第二版的變化。本書的標題《LangChain 編程:從入門到實踐》在第二版中更具現實意義。如果說第一版中的“從入門到實踐”是指“有一個想法,然后用 AI 實現并上線一個演示版本”,那么第二版的“實踐”則意味著“從一個想法出發,構建出一個可支持百萬用戶訪問的工具,并能持續收集反饋、進行測試與迭代的高效 AI 智能體應用”。那么,第二版具體有哪些更新呢?
- 移除已廢棄的 Chain 編程接口內容:由于 Chain 接口已被官方棄用,本書第二版不再介紹 LangChain 早期版本中提到的“六大模塊/組件”相關內容,這些內容已過時。
- 移除舊版記憶組件示例:如
ConversationBufferMemory、ConversationStringBufferMemory等舊式記憶組件已被淘汰,相關內容已刪除。記憶功能現在統一通過 LangGraph 中自定義的 Memory 模塊進行管理。 - 新增對 LangGraph 的詳細講解:本書第二版新增了對 LangGraph 這一 Agent 編排框架的詳細介紹,以及與其他主流 Agent 框架的對比分析。
- 全面遷移至 Pydantic 2:所有代碼示例均已更新至 Pydantic 2 標準,并兼容
langchain_core的最新版本。 - 所有案例重構為 LangChain 新模塊結構:隨著 langchain 主包的拆分,本書代碼已根據新的模塊結構進行重構,包括:
- langchain-core:包含核心抽象(如聊天模型)、可運行性與可觀測性工具;
- langchain:通用邏輯實現,適用于多種接口實現的通用代碼(如
create_tool_calling_agent); - langchain-community:由社區維護的第三方集成;
- langchain-[partner]:針對特定熱門集成(如
langchain-openai、langchain-anthropic)的官方支持包,通常具備更高的穩定性與維護優先級。
- 支持 LangChain 0.3 版本:全書代碼示例和講解均基于 LangChain 最新 0.3 穩定版本。
- 替換為國產模型支持:書中所有案例使用的模型已從 OpenAI 的 GPT 系列更換為國內主流模型,包括通義千問的文本嵌入模型、DeepSeek-V3 和 DeepSeek-R1。
- 新版更多內容介紹請參考圖靈編輯部專題文章:《LangChain 學習必備,從入門到實踐的全新版指南!》






:激活函數)




 ret2dir詳細)







