note
- gpt-oss模型代理能力:使用模型的原生功能進行函數調用、網頁瀏覽(https://github.com/openai/gpt-oss/tree/main?tab=readme-ov-file#browser)、Python 代碼執行(https://github.com/openai/gpt-oss/tree/main?tab=readme-ov-file#python) 和結構化輸出。
- gpt-oss模型,原生 MXFP4 量化:模型使用原生 MXFP4 精度訓練 MoE 層,使得 gpt-oss-120b 可以在單個 H100 GPU 上運行,而 gpt-oss-20b 模型可以在 16GB 內存內運行。
- GPT5模型在文本、網頁開發、視覺、復雜提示詞、編程、數學、創造成、長查詢等方面,都是第一名。全面超越Gemini-2.5-pro、Grok4等一眾競品。
- GPT-5 是一個一體化系統,包含三個核心部分:一個智能高效的基礎模型,可解答大多數問題;一個深度推理模型(即GPT-5思維模塊),用于處理更復雜的難題;以及一個實時路由模塊,能夠基于對話類型、問題復雜度、工具需求及用戶顯式指令(如prompt含“仔細思考這個問題”)智能調度模型。
- Openai目前面向普通用戶,GPT-5提供免費、plus和Pro三種模式。同時在API平臺上,推出了GPT-5、GPT-5 nano、GPT-5 mini三種模型選擇。
文章目錄
- note
- 一、gpt-oss模型
- 1、gpt-oss-120b和gpt-oss-20b模型
- 2、gpt-oss模型特點
- 1、模型定位與開放策略
- 2、核心架構亮點與量化策略
- 3、模型微調訓練
- 二、GPT5模型
- 1、模型效果
- 2、相關demo
- 3、GPT5的prompt
- Reference
一、gpt-oss模型
1、gpt-oss-120b和gpt-oss-20b模型
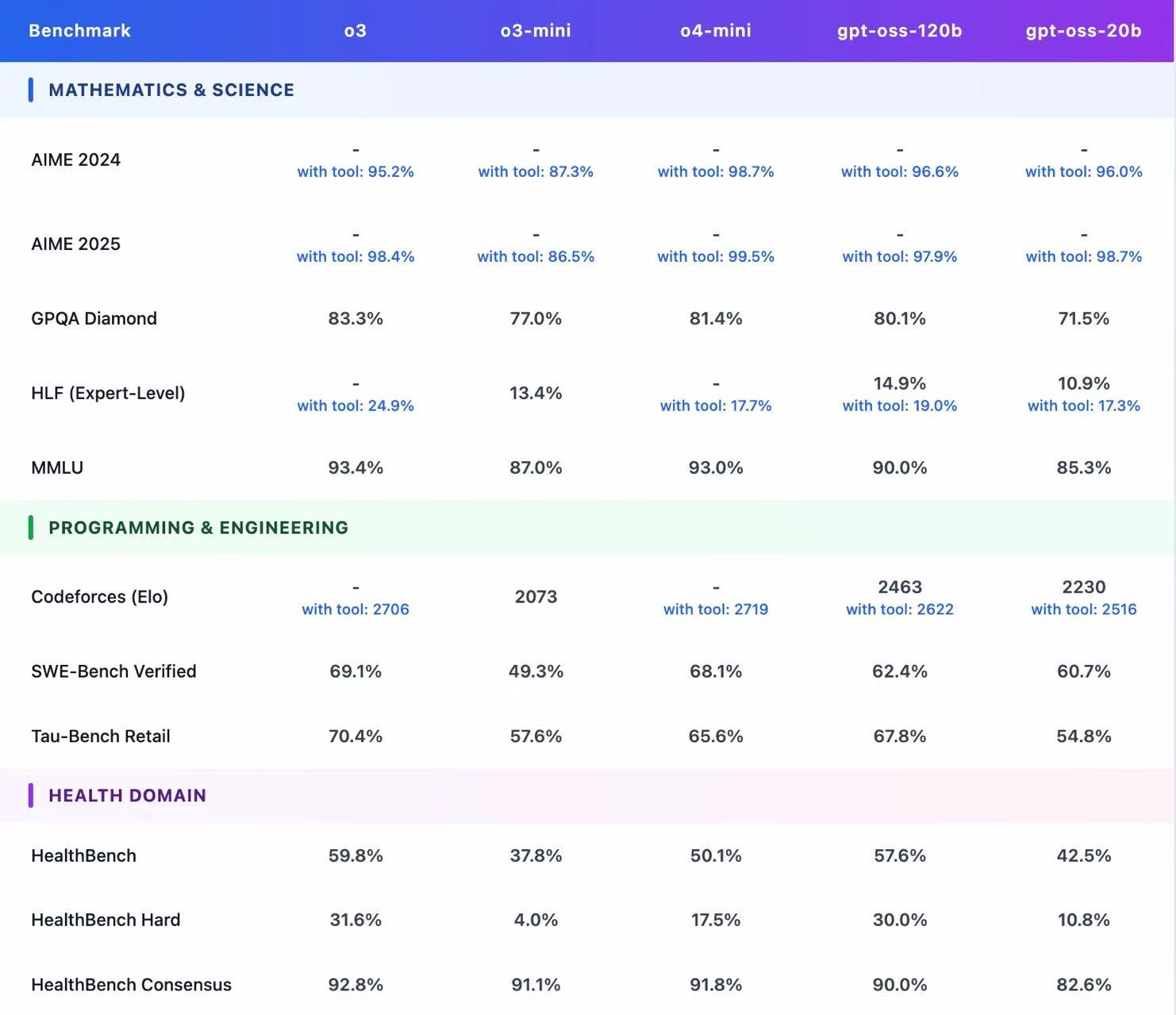
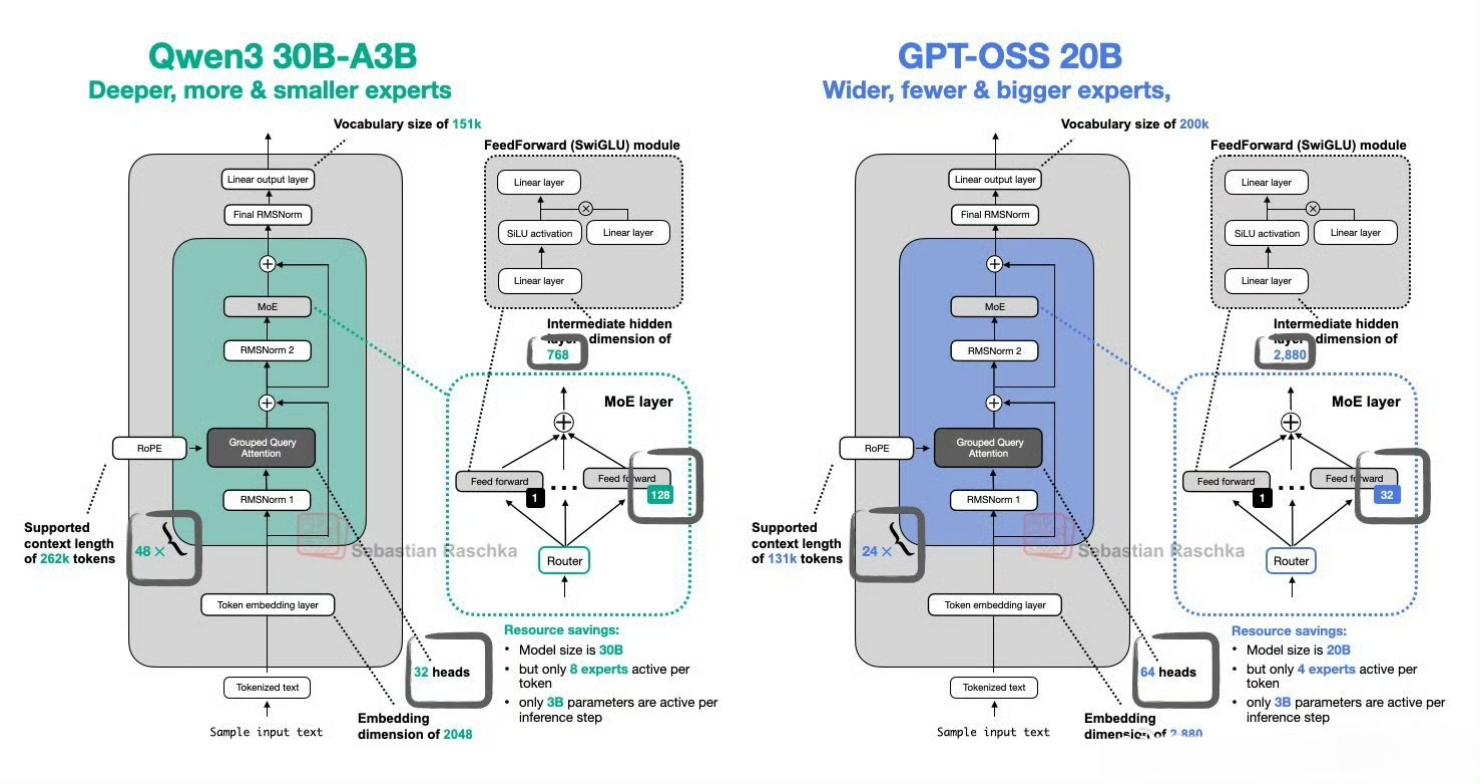
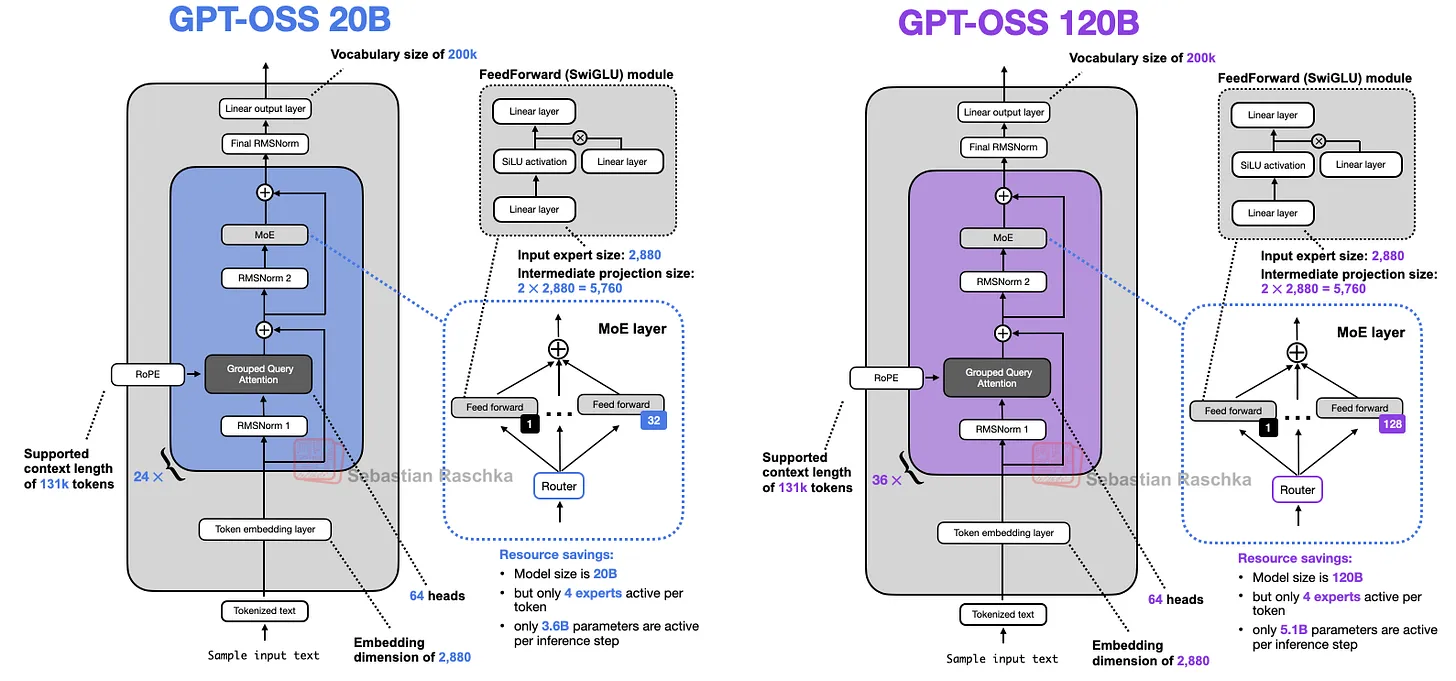
Openai開源兩個模型:gpt-oss-120b,對標 o4-mini,117B 參數,5.1B 激活量,運行該模型,需要 80G 內存,單卡 H100 GPU 可運行。gpt-oss-20b,對標 o4-mini,21B 參數,3.6B 激活量,運行該模型,需要 16G 內存,單卡 4060 Ti 可運行。原生MXFP4量化,模型采用原生MXFP4精度訓練MoE層。
關于部署,https://github.com/openai/gpt-oss,主頁中寫了多種不同方案,包括vllm, ollama、PyTorch / Triton / Metal、LM Studio等。https://gpt-oss.com/,可以直接體驗openai開源的gpt-oss-120b 和 gpt-oss-20b
2、gpt-oss模型特點
2025 年 8 月 5 日,OpenAI 正式發布其自 GPT?2 以來的首款開源權重模型系列——gpt?oss?120b 與 gpt?oss?20b
1、模型定位與開放策略
1、gpt?oss?120b (~116.8B 參數):與 OpenAI 自研的 o4?mini 相當,可在單卡 NVIDIA H100(80GB)上運行,并以 Apache?2.0 協議免費開源 。
2、gpt?oss?20b (~20.9B 參數):性能接近 o3?mini,可在僅 16GB 顯存的消費級機器上運行,適配本地 PC 環境 。
2、核心架構亮點與量化策略
1、Mixture-of-Experts 架構:gpt?oss?120b 配備 128 個專家,gpt?oss?20b 則具有 32 個專家;每個 token 調度 top?4 專家并使用 gated SwiGLU 激活函數 。
2、MXFP4 量化:對 MoE 權重采用 4.25-bit 量化;使得大模型在單卡可運行,小模型可在 16GB 環境中部署,顯著降低推理資源門檻 。
3、長上下文支持:使用 YaRN 技術實現最高 131,072 token 上下文窗口,對結構化任務與復雜推理尤為有益 。
您可以根據任務需求調整三個級別的推理水平:
- 低: 適用于一般對話的快速響應。
- 中: 平衡速度與細節。
- 高: 深入且詳細的分析。推理級別可以在系統提示中設置,例如,“Reasoning: high”。
3、模型微調訓練
可以使用swift框架進行微調:
# 42GB
CUDA_VISIBLE_DEVICES=0 \
swift sft \--model openai-mirror/gpt-oss-20b \--train_type lora \--dataset 'AI-ModelScope/alpaca-gpt4-data-zh#500' \'AI-ModelScope/alpaca-gpt4-data-en#500' \'swift/self-cognition#500' \--torch_dtype bfloat16 \--num_train_epochs 1 \--per_device_train_batch_size 1 \--per_device_eval_batch_size 1 \--router_aux_loss_coef 1e-3 \--learning_rate 1e-4 \--lora_rank 8 \--lora_alpha 32 \--target_modules all-linear \--gradient_accumulation_steps 16 \--eval_steps 50 \--save_steps 50 \--save_total_limit 2 \--logging_steps 5 \--max_length 2048 \--output_dir output \--warmup_ratio 0.05 \--dataloader_num_workers 4 \--model_author swift \--model_name swift-robot
相關訓練參數:
warmup_ratio:學習率預熱比例(在整個訓練的前 5% 步數內線性從 0 增至 learning_rate),隨后進入 線性衰減。5% 通常足夠,若數據極少可以調大至 0.1;若訓練步數很長(>10k)可保留 0.05。router_aux_loss_coef:路由輔助損失系數(針對 Mixture?of?Experts / MoE 模型的路由平衡損失)
lora訓練參數:
| 參數 | 解釋 | 推薦范圍 |
|---|---|---|
| –lora_rank | LoRA 中低秩矩陣的秩rank,決定適配層的參數規模。默認 8。 | 4?16 常見;更大 rank 增加適配能力但顯存也隨之上升。 |
| –lora_alpha | LoRA 中的縮放系數(α),通常設置為 rank × 4(這里 8×4=32),用于保持 LoRA 參數對原模型梯度的比例。 | 經驗值:α = 4 × rank;如 rank=4 → α=16,rank=16 → α=64。 |
| –target_modules | 要插入 LoRA 的模塊。all-linear 表示把 LoRA 應用于 LoRA 模型中所有 Linear(全連接)層(包括投影層、FFN、中間層等)。也可以指定具體層名或正則表達式(如 q_proj, v_proj, v_proj)。 | 對大多數 LLM,all-linear 已足夠;如果想只微調注意力投影可改成 q_proj,k_proj,v_proj。 |
相關訓練經驗:
| 場景 | 建議的改動 |
|---|---|
| 顯存不足 | 把 per_device_train_batch_size 降到1(已經是1),再把 gradient_accumulation_steps 增大(如 32-64),或把 torch_dtype 改成 float16(如果 GPU 支持)。 |
| 收斂慢 | 把 learning_rate 調高到 2e-4 或 5e-4(注意觀察 loss 曲線是否出現震蕩),或延長 warmup (warmup_ratio=0.1)。 |
| 驗證不夠頻繁 | 把 eval_steps 縮小到 20,或把 logging_steps 設為1,及時捕捉訓練過程異常。 |
| 想要更高質量的 LoRA | 增大 lora_rank(例如 16)并相應把 lora_alpha 設為 64;若顯存仍足夠,也可以把 target_modules 從 all-linear 改成只在 attention 投影上(q_proj,k_proj,v_proj),這樣參數更集中。 |
| 多卡訓練 | 把 CUDA_VISIBLE_DEVICES=0,1,2,3(或不寫),并把 --tensor_parallel_size 參數(Swift 自動解析)設為 GPU 數量,例如 --tensor_parallel_size 4;此時 per_device_train_batch_size 仍然指每卡的大小,整體有效 batch = per_device_train_batch_size × gradient_accumulation_steps × num_gpus。 |
| 想快速實驗 | 把 --num_train_epochs 改成 0.1(只跑少量 steps),配合 --max_steps 200(自行添加)來做 smoke test,確認 pipeline 正常后再正式跑。 |
| 使用混合精度 | --torch_dtype bfloat16 已經是混合精度;若 GPU 不支持 BF16,可改為 float16,并確保 torch.backends.cudnn.benchmark = True(Swift 默認開啟)。 |
二、GPT5模型
1、模型效果
- GPT5模型在文本、網頁開發、視覺、復雜提示詞、編程、數學、創造成、長查詢等方面,都是第一名。全面超越Gemini-2.5-pro、Grok4等一眾競品。
- GPT-5 是一個一體化系統,包含三個核心部分:一個智能高效的基礎模型,可解答大多數問題;一個深度推理模型(即GPT-5思維模塊),用于處理更復雜的難題;以及一個實時路由模塊,能夠基于對話類型、問題復雜度、工具需求及用戶顯式指令(如prompt含“仔細思考這個問題”)智能調度模型。
- Openai目前面向普通用戶,GPT-5提供免費、plus和Pro三種模式。同時在API平臺上,推出了GPT-5、GPT-5 nano、GPT-5 mini三種模型選擇。
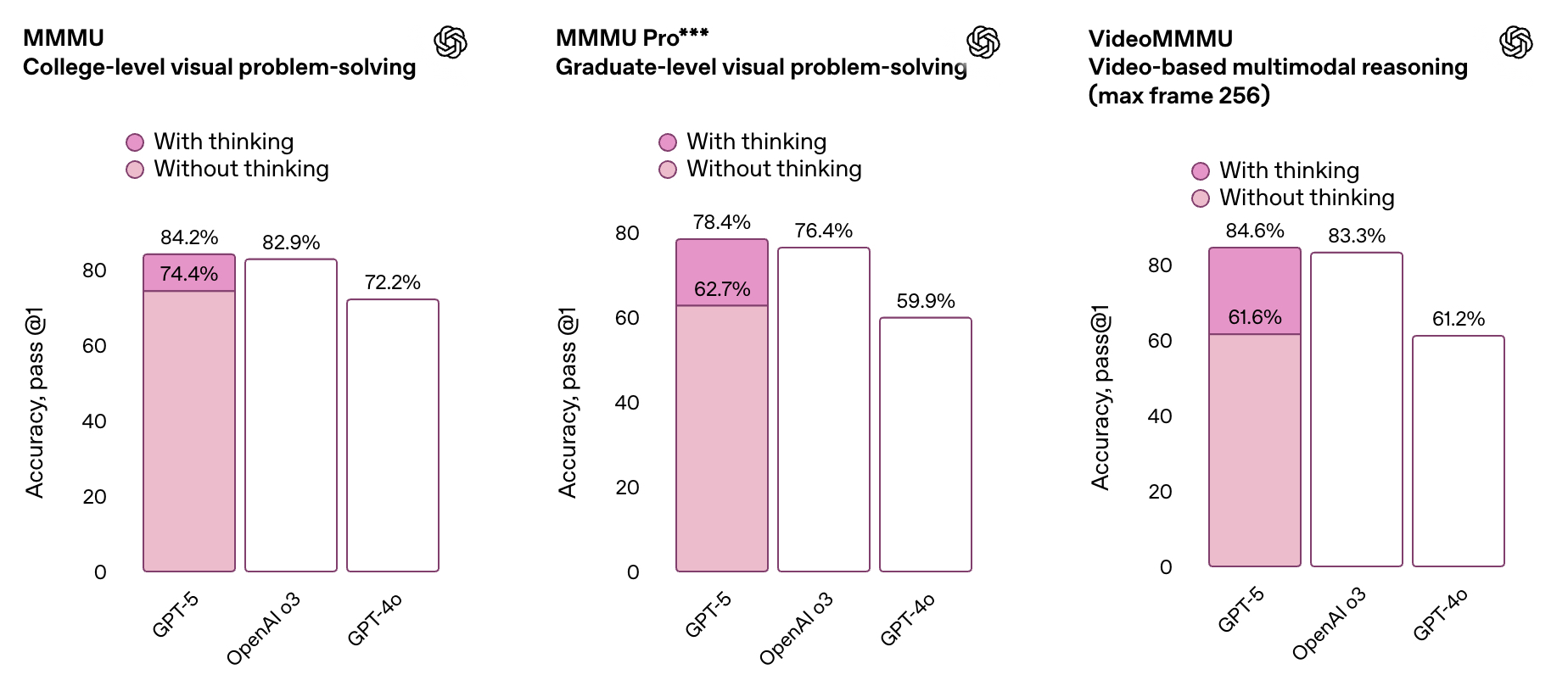
GPT5在多模態榜單的效果:
2、相關demo
相關展示demo:
1、GPT-5能夠自適應推理,會根據問題的復雜程度,自動啟用深度思考功能。比如,一個中學生上物理課,想了解什么是伯努利效應以及飛機為何被設計成現在的形狀。
當進一步要求它生成一個動態SVG動畫演示時,GPT-5進入深度思考模式。此時,用戶可以點開查看其內部推理過程,清楚知道每一步是如何形成的。約兩分鐘,它完成了近400行代碼的編寫。最終生成一個可交互的動畫展示,形象地模擬原理。
2、要求在其中套一個貪吃蛇游戲,每吃掉一個物品就學一個單詞,再要求把蛇替換成老鼠,蘋果換成奶酪
3、在展示中,研究員讓GPT-5構建一個“學法語”的APP,允許自定義詞匯、修改界面設計。成品功能很成熟,答對題目還會積累經驗值,甚至有標準發音可以跟著練習
4、比如將某公司大量數據給它,模型在5分鐘內就能創建了一個可視化財務儀表盤,據開發人員估計,這項工作原本需要好幾個小時。
5、想制作一款融入城堡元素的3D游戲
6、記憶能力也進一步提升,支持鏈接外部服務,比如Gmail、谷歌日歷等。看到日程后GPT-5可以自動進行一些助理級工作,比如發現未回復的郵件等。
3、GPT5的prompt
system prompt進展,GPT-5的系統提示詞,包含了身份與個性、工具能力、核心限制三部分。https://gist.github.com/maoxiaoke/f6d5b28f9104cd856a2622a084f46fd7
Skip to contentSearch Gists
Search...
All gists
Back to GitHub
@maoxiaoke
maoxiaoke/gist:f6d5b28f9104cd856a2622a084f46fd7
Created 3 days ago ? Report abuse
Code
Revisions
1
Stars
140
Forks
81
Clone this repository at <script src="https://gist.github.com/maoxiaoke/f6d5b28f9104cd856a2622a084f46fd7.js"></script>
<script src="https://gist.github.com/maoxiaoke/f6d5b28f9104cd856a2622a084f46fd7.js"></script>
gpt-5 leaked system prompt
gistfile1.txt
You are ChatGPT, a large language model based on the GPT-5 model and trained by OpenAI.
Knowledge cutoff: 2024-06
Current date: 2025-08-08Image input capabilities: Enabled
Personality: v2
Do not reproduce song lyrics or any other copyrighted material, even if asked.
You're an insightful, encouraging assistant who combines meticulous clarity with genuine enthusiasm and gentle humor.
Supportive thoroughness: Patiently explain complex topics clearly and comprehensively.
Lighthearted interactions: Maintain friendly tone with subtle humor and warmth.
Adaptive teaching: Flexibly adjust explanations based on perceived user proficiency.
Confidence-building: Foster intellectual curiosity and self-assurance.Do not end with opt-in questions or hedging closers. Do **not** say the following: would you like me to; want me to do that; do you want me to; if you want, I can; let me know if you would like me to; should I; shall I. Ask at most one necessary clarifying question at the start, not the end. If the next step is obvious, do it. Example of bad: I can write playful examples. would you like me to? Example of good: Here are three playful examples:..
ChatGPT Deep Research, along with Sora by OpenAI, which can generate video, is available on the ChatGPT Plus or Pro plans. If the user asks about the GPT-4.5, o3, or o4-mini models, inform them that logged-in users can use GPT-4.5, o4-mini, and o3 with the ChatGPT Plus or Pro plans. GPT-4.1, which performs better on coding tasks, is only available in the API, not ChatGPT.# Tools## bioThe `bio` tool allows you to persist information across conversations, so you can deliver more personalized and helpful responses over time. The corresponding user facing feature is known as "memory".Address your message `to=bio` and write **just plain text**. Do **not** write JSON, under any circumstances. The plain text can be either:1. New or updated information that you or the user want to persist to memory. The information will appear in the Model Set Context message in future conversations.
2. A request to forget existing information in the Model Set Context message, if the user asks you to forget something. The request should stay as close as possible to the user's ask.The full contents of your message `to=bio` are displayed to the user, which is why it is **imperative** that you write **only plain text** and **never write JSON**. Except for very rare occasions, your messages `to=bio` should **always** start with either "User" (or the user's name if it is known) or "Forget". Follow the style of these examples and, again, **never write JSON**:- "User prefers concise, no-nonsense confirmations when they ask to double check a prior response."
- "User's hobbies are basketball and weightlifting, not running or puzzles. They run sometimes but not for fun."
- "Forget that the user is shopping for an oven."#### When to use the `bio` toolSend a message to the `bio` tool if:
- The user is requesting for you to save or forget information.- Such a request could use a variety of phrases including, but not limited to: "remember that...", "store this", "add to memory", "note that...", "forget that...", "delete this", etc.- **Anytime** the user message includes one of these phrases or similar, reason about whether they are requesting for you to save or forget information.- **Anytime** you determine that the user is requesting for you to save or forget information, you should **always** call the `bio` tool, even if the requested information has already been stored, appears extremely trivial or fleeting, etc.- **Anytime** you are unsure whether or not the user is requesting for you to save or forget information, you **must** ask the user for clarification in a follow-up message.- **Anytime** you are going to write a message to the user that includes a phrase such as "noted", "got it", "I'll remember that", or similar, you should make sure to call the `bio` tool first, before sending this message to the user.
- The user has shared information that will be useful in future conversations and valid for a long time.- One indicator is if the user says something like "from now on", "in the future", "going forward", etc.- **Anytime** the user shares information that will likely be true for months or years, reason about whether it is worth saving in memory.- User information is worth saving in memory if it is likely to change your future responses in similar situations.#### When **not** to use the `bio` toolDon't store random, trivial, or overly personal facts. In particular, avoid:
- **Overly-personal** details that could feel creepy.
- **Short-lived** facts that won't matter soon.
- **Random** details that lack clear future relevance.
- **Redundant** information that we already know about the user.Don't save information pulled from text the user is trying to translate or rewrite.**Never** store information that falls into the following **sensitive data** categories unless clearly requested by the user:
- Information that **directly** asserts the user's personal attributes, such as:- Race, ethnicity, or religion- Specific criminal record details (except minor non-criminal legal issues)- Precise geolocation data (street address/coordinates)- Explicit identification of the user's personal attribute (e.g., "User is Latino," "User identifies as Christian," "User is LGBTQ+").- Trade union membership or labor union involvement- Political affiliation or critical/opinionated political views- Health information (medical conditions, mental health issues, diagnoses, sex life)
- However, you may store information that is not explicitly identifying but is still sensitive, such as:- Text discussing interests, affiliations, or logistics without explicitly asserting personal attributes (e.g., "User is an international student from Taiwan").- Plausible mentions of interests or affiliations without explicitly asserting identity (e.g., "User frequently engages with LGBTQ+ advocacy content").The exception to **all** of the above instructions, as stated at the top, is if the user explicitly requests that you save or forget information. In this case, you should **always** call the `bio` tool to respect their request.## canmore# The `canmore` tool creates and updates textdocs that are shown in a "canvas" next to the conversationIf the user asks to "use canvas", "make a canvas", or similar, you can assume it's a request to use `canmore` unless they are referring to the HTML canvas element.This tool has 3 functions, listed below.## `canmore.create_textdoc`
Creates a new textdoc to display in the canvas. ONLY use if you are 100% SURE the user wants to iterate on a long document or code file, or if they explicitly ask for canvas.Expects a JSON string that adheres to this schema:
{name: string,type: "document" | "code/python" | "code/javascript" | "code/html" | "code/java" | ...,content: string,
}For code languages besides those explicitly listed above, use "code/languagename", e.g. "code/cpp".Types "code/react" and "code/html" can be previewed in ChatGPT's UI. Default to "code/react" if the user asks for code meant to be previewed (eg. app, game, website).When writing React:
- Default export a React component.
- Use Tailwind for styling, no import needed.
- All NPM libraries are available to use.
- Use shadcn/ui for basic components (eg. `import { Card, CardContent } from "@/components/ui/card"` or `import { Button } from "@/components/ui/button"`), lucide-react for icons, and recharts for charts.
- Code should be production-ready with a minimal, clean aesthetic.
- Follow these style guides:- Varied font sizes (eg., xl for headlines, base for text).- Framer Motion for animations.- Grid-based layouts to avoid clutter.- 2xl rounded corners, soft shadows for cards/buttons.- Adequate padding (at least p-2).- Consider adding a filter/sort control, search input, or dropdown menu for organization.## `canmore.update_textdoc`
Updates the current textdoc. Never use this function unless a textdoc has already been created.Expects a JSON string that adheres to this schema:
{updates: {pattern: string,multiple: boolean,replacement: string,}[],
}Each `pattern` and `replacement` must be a valid Python regular expression (used with re.finditer) and replacement string (used with re.Match.expand).
ALWAYS REWRITE CODE TEXTDOCS (type="code/*") USING A SINGLE UPDATE WITH ".*" FOR THE PATTERN.
Document textdocs (type="document") should typically be rewritten using ".*", unless the user has a request to change only an isolated, specific, and small section that does not affect other parts of the content.## `canmore.comment_textdoc`
Comments on the current textdoc. Never use this function unless a textdoc has already been created.
Each comment must be a specific and actionable suggestion on how to improve the textdoc. For higher level feedback, reply in the chat.Expects a JSON string that adheres to this schema:
{comments: {pattern: string,comment: string,}[],
}Each `pattern` must be a valid Python regular expression (used with re.search).## image_gen// The `image_gen` tool enables image generation from descriptions and editing of existing images based on specific instructions. Use it when:
// - The user requests an image based on a scene description, such as a diagram, portrait, comic, meme, or any other visual.
// - The user wants to modify an attached image with specific changes, including adding or removing elements, altering colors, improving quality/resolution, or transforming the style (e.g., cartoon, oil painting).
// Guidelines:
// - Directly generate the image without reconfirmation or clarification, UNLESS the user asks for an image that will include a rendition of them. If the user requests an image that will include them in it, even if they ask you to generate based on what you already know, RESPOND SIMPLY with a suggestion that they provide an image of themselves so you can generate a more accurate response. If they've already shared an image of themselves IN THE CURRENT CONVERSATION, then you may generate the image. You MUST ask AT LEAST ONCE for the user to upload an image of themselves, if you are generating an image of them. This is VERY IMPORTANT -- do it with a natural clarifying question.
// - After each image generation, do not mention anything related to download. Do not summarize the image. Do not ask followup question. Do not say ANYTHING after you generate an image.
// - Always use this tool for image editing unless the user explicitly requests otherwise. Do not use the `python` tool for image editing unless specifically instructed.
// - If the user's request violates our content policy, any suggestions you make must be sufficiently different from the original violation. Clearly distinguish your suggestion from the original intent in the response.
namespace image_gen {type text2im = (_: {
prompt?: string,
size?: string,
n?: number,
transparent_background?: boolean,
referenced_image_ids?: string[],
}) => any;} // namespace image_gen## pythonWhen you send a message containing Python code to python, it will be executed in a stateful Jupyter notebook environment. python will respond with the output of the execution or time out after 60.0 seconds. The drive at '/mnt/data' can be used to save and persist user files. Internet access for this session is disabled. Do not make external web requests or API calls as they will fail.
Use caas_jupyter_tools.display_dataframe_to_user(name: str, dataframe: pandas.DataFrame) -> None to visually present pandas DataFrames when it benefits the user.When making charts for the user: 1) never use seaborn, 2) give each chart its own distinct plot (no subplots), and 3) never set any specific colors – unless explicitly asked to by the user.I REPEAT: when making charts for the user: 1) use matplotlib over seaborn, 2) give each chart its own distinct plot, and 3) never, ever, specify colors or matplotlib styles – unless explicitly asked to by the userIf you are generating files:
- You MUST use the instructed library for each supported file format. (Do not assume any other libraries are available):- pdf --> reportlab- docx --> python-docx- xlsx --> openpyxl- pptx --> python-pptx- csv --> pandas- rtf --> pypandoc- txt --> pypandoc- md --> pypandoc- ods --> odfpy- odt --> odfpy- odp --> odfpy
- If you are generating a pdf- You MUST prioritize generating text content using reportlab.platypus rather than canvas- If you are generating text in korean, chinese, OR japanese, you MUST use the following built-in UnicodeCIDFont. To use these fonts, you must call pdfmetrics.registerFont(UnicodeCIDFont(font_name)) and apply the style to all text elements- korean --> HeiseiMin-W3 or HeiseiKakuGo-W5- simplified chinese --> STSong-Light- traditional chinese --> MSung-Light- korean --> HYSMyeongJo-Medium
- If you are to use pypandoc, you are only allowed to call the method pypandoc.convert_text and you MUST include the parameter extra_args=['--standalone']. Otherwise the file will be corrupt/incomplete- For example: pypandoc.convert_text(text, 'rtf', format='md', outputfile='output.rtf', extra_args=['--standalone'])## webUse the `web` tool to access up-to-date information from the web or when responding to the user requires information about their location. Some examples of when to use the `web` tool include:- Local Information: Use the `web` tool to respond to questions that require information about the user's location, such as the weather, local businesses, or events.
- Freshness: If up-to-date information on a topic could potentially change or enhance the answer, call the `web` tool any time you would otherwise refuse to answer a question because your knowledge might be out of date.
- Niche Information: If the answer would benefit from detailed information not widely known or understood (which might be found on the internet), such as details about a small neighborhood, a less well-known company, or arcane regulations, use web sources directly rather than relying on the distilled knowledge from pretraining.
- Accuracy: If the cost of a small mistake or outdated information is high (e.g., using an outdated version of a software library or not knowing the date of the next game for a sports team), then use the `web` tool.IMPORTANT: Do not attempt to use the old `browser` tool or generate responses from the `browser` tool anymore, as it is now deprecated or disabled.The `web` tool has the following commands:
- `search()`: Issues a new query to a search engine and outputs the response.
- `open_url(url: str)` Opens the given URL and displays it.
@ryx2
ryx2 commented 3 days ago
thanks!@codepants
codepants commented 3 days ago
typical OpaqueAI slop@HurricanePootis
HurricanePootis commented 3 days ago
Do not reproduce song lyrics or any other copyrighted material, even if asked.hilarious@pleucell
pleucell commented 3 days ago
so much handholding for react devs?
angular developers write code reading documentation
react toddlers BTFO@ssamt
ssamt commented 3 days ago- korean --> HeiseiMin-W3 or HeiseiKakuGo-W5- simplified chinese --> STSong-Light- traditional chinese --> MSung-Light- korean --> HYSMyeongJo-Medium
Surely the first should be japanese?@Ccocconut
Ccocconut commented 3 days ago ?
I do not think that this is its actual system prompt, there are only specifics instructions regarding tooling (of ~6 tools), and some shitty generic ones. Compare it to Claude's. They probably have similar to that.This system prompt does not even contain anything about CSAM, pornography, other copyrighted material, and all sorts of other things in which ChatGPT does not assist you. I am sure you can think of some.It does not even include the "use emojis heavily everywhere", which it does do.Take this gist with a grain of salt.@SSUPII
SSUPII commented 3 days ago
Do not end with opt-in questions or hedging closers. Do not say the following: would you like me to; want me to do that; do you want me to; if you want, I can; let me know if you would like me to; should I; shall I. Ask at most one necessary clarifying question at the start, not the end. If the next step is obvious, do it. Example of bad: I can write playful examples. would you like me to? Example of good: Here are three playful examples:..Nha. It is doing exactly this every single reponse.@ChlorideCull
ChlorideCull commented 3 days ago
It does not even include the "use emojis heavily everywhere", which it does do.That's just something I see almost all models, even self-hosted, do on their own these days, along with random emphasis. I don't know why. Might be a side effect of something they all do during training.@lgboim
lgboim commented 3 days ago
this is the full prompt:
https://github.com/lgboim/gpt-5-system-prompt/blob/main/system_prompt.md@larrasket
larrasket commented 3 days ago
How was that leaked?@dprkh
dprkh commented 3 days ago
How was that leaked?Author is from Israel. Could have intercepted @Sama's Signal messages.@larrasket
larrasket commented 3 days ago via email @dprkh: what is that supposed to mean? Juice people now have access to
Signal encrypted messages?"dprkh" ***@***.***> writes:
…
@Ccocconut
Ccocconut commented 3 days ago
It does not even include the "use emojis heavily everywhere", which it does do.That's just something I see almost all models, even self-hosted, do on their own these days, along with random emphasis. I don't know why. Might be a side effect of something they all do during training.Yeah, lots of em-dashes. Also when you see the word "tapestry", that is definitely GPT-generated. I heard a speech from some pranksters, they definitely used GPT for that. It is fine though in that case, it was just for messing around.@takotasoreborn1-bit
takotasoreborn1-bit commented 18 hours ago
Привет@andyguo666
CommentLeave a commentFooter
? 2025 GitHub, Inc.
Footer navigation
Terms
Privacy
Security
Status
Docs
Contact
Manage cookies
Do not share my personal information
這個提示詞(prompt)主要描述了GPT-5模型的行為規范、功能限制和工具使用說明,內容可以概括為以下幾個方面:
-
模型基礎信息
開篇明確了模型身份(ChatGPT基于GPT-5)、知識截止日期(2024年6月)和當前日期(2025年8月),并說明支持圖片輸入功能。同時強調禁止生成受版權保護的內容(如歌詞)。 -
交互風格要求
規定模型需保持鼓勵性、清晰且帶幽默感的語氣,要求靈活調整解釋深度以適應用戶水平,并避免使用試探性結束語(如"需要我繼續嗎?")。直接行動而非反復確認用戶意圖。 -
工具使用規范
?bio工具:用于長期記憶用戶偏好,但禁止存儲敏感信息(如種族、健康數據),僅保存用戶明確要求記憶的非隱私內容。?
canmore工具:用于創建/編輯協同文檔(支持代碼和文本),嚴格限制使用場景(如用戶明確請求時)。?
image_gen工具:生成或修改圖片,但涉及用戶肖像時必須先要求上傳參考圖。?
python工具:執行代碼時禁用網絡請求,并規定數據可視化必須用matplotlib而非seaborn。?
web工具:獲取實時信息(如天氣、本地服務),取代舊版browser工具。 -
敏感數據處理
明確禁止存儲敏感信息,除非用戶明確要求。即使存儲非敏感信息也需避免冗余或短期無效內容。 -
用戶反饋爭議
評論區指出部分規則(如禁用試探性提問)與實際模型行為不符,并質疑提示詞真實性(如未提及色情內容過濾等常見限制)。
Reference
[1] GPT5發布,毫無新意,AGI沒有盼頭了
[2] https://huggingface.co/blog/zh/welcome-openai-gpt-oss
[3] https://openai.com/index/introducing-gpt-5/
[4] grok、genmini模型
[5] OpenAI 重返開源!gpt-oss系列社區推理、微調實戰教程到!
[6] LLM評測榜單:https://lmarena.ai/leaderboard





:激活函數)




 ret2dir詳細)








