知識點回顧:
彩色和灰度圖片測試和訓練的規范寫法:封裝在函數中
展平操作:除第一個維度batchsize外全部展平
dropout操作:訓練階段隨機丟棄神經元,測試階段eval模式關閉dropout
作業:仔細學習下測試和訓練代碼的邏輯,這是基礎,這個代碼框架后續會一直沿用,后續的重點慢慢就是轉向模型定義階段了。
昨天我們介紹了圖像數據的格式以及模型定義的過程,發現和之前結構化數據的略有不同,主要差異體現在2處
-
模型定義的時候需要展平圖像
-
由于數據過大,需要將數據集進行分批次處理,這往往涉及到了dataset和dataloader來規范代碼的組織
現在我們把注意力放在訓練和測試代碼的規范寫法上
單通道圖片的規范寫法
# 先繼續之前的代碼
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader , Dataset # DataLoader 是 PyTorch 中用于加載數據的工具
from torchvision import datasets, transforms # torchvision 是一個用于計算機視覺的庫,datasets 和 transforms 是其中的模塊
import matplotlib.pyplot as plt
import warnings
# 忽略警告信息
warnings.filterwarnings("ignore")
# 設置隨機種子,確保結果可復現
torch.manual_seed(42)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"使用設備: {device}")
# 1. 數據預處理
transform = transforms.Compose([transforms.ToTensor(), # 轉換為張量并歸一化到[0,1]transforms.Normalize((0.1307,), (0.3081,)) # MNIST數據集的均值和標準差
])# 2. 加載MNIST數據集
train_dataset = datasets.MNIST(root='./data',train=True,download=True,transform=transform
)test_dataset = datasets.MNIST(root='./data',train=False,transform=transform
)# 3. 創建數據加載器
batch_size = 64 # 每批處理64個樣本
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)# 4. 定義模型、損失函數和優化器
class MLP(nn.Module):def __init__(self):super(MLP, self).__init__()self.flatten = nn.Flatten() # 將28x28的圖像展平為784維向量self.layer1 = nn.Linear(784, 128) # 第一層:784個輸入,128個神經元self.relu = nn.ReLU() # 激活函數self.layer2 = nn.Linear(128, 10) # 第二層:128個輸入,10個輸出(對應10個數字類別)def forward(self, x):x = self.flatten(x) # 展平圖像x = self.layer1(x) # 第一層線性變換x = self.relu(x) # 應用ReLU激活函數x = self.layer2(x) # 第二層線性變換,輸出logitsreturn x# 初始化模型
model = MLP()
model = model.to(device) # 將模型移至GPU(如果可用)# from torchsummary import summary # 導入torchsummary庫
# print("\n模型結構信息:")
# summary(model, input_size=(1, 28, 28)) # 輸入尺寸為MNIST圖像尺寸criterion = nn.CrossEntropyLoss() # 交叉熵損失函數,適用于多分類問題
optimizer = optim.Adam(model.parameters(), lr=0.001) # Adam優化器
# 5. 訓練模型(記錄每個 iteration 的損失)
def train(model, train_loader, test_loader, criterion, optimizer, device, epochs):model.train() # 設置為訓練模式# 新增:記錄每個 iteration 的損失all_iter_losses = [] # 存儲所有 batch 的損失iter_indices = [] # 存儲 iteration 序號(從1開始)for epoch in range(epochs):running_loss = 0.0correct = 0total = 0for batch_idx, (data, target) in enumerate(train_loader):# enumerate() 是 Python 內置函數,用于遍歷可迭代對象(如列表、元組)并同時獲取索引和值。# batch_idx:當前批次的索引(從 0 開始)# (data, target):當前批次的樣本數據和對應的標簽,是一個元組,這是因為dataloader內置的getitem方法返回的是一個元組,包含數據和標簽。# 只需要記住這種固定寫法即可data, target = data.to(device), target.to(device) # 移至GPU(如果可用)optimizer.zero_grad() # 梯度清零output = model(data) # 前向傳播loss = criterion(output, target) # 計算損失loss.backward() # 反向傳播optimizer.step() # 更新參數# 記錄當前 iteration 的損失(注意:這里直接使用單 batch 損失,而非累加平均)iter_loss = loss.item()all_iter_losses.append(iter_loss)iter_indices.append(epoch * len(train_loader) + batch_idx + 1) # iteration 序號從1開始# 統計準確率和損失running_loss += loss.item() #將loss轉化為標量值并且累加到running_loss中,計算總損失_, predicted = output.max(1) # output:是模型的輸出(logits),形狀為 [batch_size, 10](MNIST 有 10 個類別)# 獲取預測結果,max(1) 返回每行(即每個樣本)的最大值和對應的索引,這里我們只需要索引total += target.size(0) # target.size(0) 返回當前批次的樣本數量,即 batch_size,累加所有批次的樣本數,最終等于訓練集的總樣本數correct += predicted.eq(target).sum().item() # 返回一個布爾張量,表示預測是否正確,sum() 計算正確預測的數量,item() 將結果轉換為 Python 數字# 每100個批次打印一次訓練信息(可選:同時打印單 batch 損失)if (batch_idx + 1) % 100 == 0:print(f'Epoch: {epoch+1}/{epochs} | Batch: {batch_idx+1}/{len(train_loader)} 'f'| 單Batch損失: {iter_loss:.4f} | 累計平均損失: {running_loss/(batch_idx+1):.4f}')# 測試、打印 epoch 結果epoch_train_loss = running_loss / len(train_loader)epoch_train_acc = 100. * correct / totalepoch_test_loss, epoch_test_acc = test(model, test_loader, criterion, device)print(f'Epoch {epoch+1}/{epochs} 完成 | 訓練準確率: {epoch_train_acc:.2f}% | 測試準確率: {epoch_test_acc:.2f}%')# 繪制所有 iteration 的損失曲線plot_iter_losses(all_iter_losses, iter_indices)# 保留原 epoch 級曲線(可選)# plot_metrics(train_losses, test_losses, train_accuracies, test_accuracies, epochs)return epoch_test_acc # 返回最終測試準確率
之前我們用mlp訓練鳶尾花數據集的時候并沒有用函數的形式來封裝訓練和測試過程,這樣寫會讓代碼更加具有邏輯-----隔離參數和內容。
-
后續直接修改參數就行,不需要去找到對應操作的代碼
-
方便復用,未來有多模型對比時,就可以復用這個函數
這里我們先不寫早停策略,因為規范的早停策略需要用到驗證集,一般還需要劃分測試集
- 劃分數據集:訓練集(用于訓練)、驗證集(用于早停和調參)、測試集(用于最終報告性能)。
- 在訓練過程中,使用驗證集觸發早停。
- 訓練結束后,僅用測試集運行一次測試函數,得到最終準確率。
測試函數和繪圖函數均被封裝在了train函數中,但是test和繪圖函數在定義train函數之后,這是因為在 Python 中,函數定義的順序不影響調用,只要在調用前已經完成定義即可。
# 6. 測試模型(不變)
def test(model, test_loader, criterion, device):model.eval() # 設置為評估模式test_loss = 0correct = 0total = 0with torch.no_grad(): # 不計算梯度,節省內存和計算資源for data, target in test_loader:data, target = data.to(device), target.to(device)output = model(data)test_loss += criterion(output, target).item()_, predicted = output.max(1)total += target.size(0)correct += predicted.eq(target).sum().item()avg_loss = test_loss / len(test_loader)accuracy = 100. * correct / totalreturn avg_loss, accuracy # 返回損失和準確率
如果打印每一個batchsize的損失和準確率,會看的更加清晰,更加直觀
# 7. 繪制每個 iteration 的損失曲線
def plot_iter_losses(losses, indices):plt.figure(figsize=(10, 4))plt.plot(indices, losses, 'b-', alpha=0.7, label='Iteration Loss')plt.xlabel('Iteration(Batch序號)')plt.ylabel('損失值')plt.title('每個 Iteration 的訓練損失')plt.legend()plt.grid(True)plt.tight_layout()plt.show()
# 8. 執行訓練和測試(設置 epochs=2 驗證效果)
epochs = 2
print("開始訓練模型...")
final_accuracy = train(model, train_loader, test_loader, criterion, optimizer, device, epochs)
print(f"訓練完成!最終測試準確率: {final_accuracy:.2f}%")
開始訓練模型...
Epoch: 1/2 | Batch: 100/938 | 單Batch損失: 0.3583 | 累計平均損失: 0.6321
Epoch: 1/2 | Batch: 200/938 | 單Batch損失: 0.2035 | 累計平均損失: 0.4776
Epoch: 1/2 | Batch: 300/938 | 單Batch損失: 0.3044 | 累計平均損失: 0.4053
Epoch: 1/2 | Batch: 400/938 | 單Batch損失: 0.1427 | 累計平均損失: 0.3669
Epoch: 1/2 | Batch: 500/938 | 單Batch損失: 0.1742 | 累計平均損失: 0.3321
Epoch: 1/2 | Batch: 600/938 | 單Batch損失: 0.3089 | 累計平均損失: 0.3104
Epoch: 1/2 | Batch: 700/938 | 單Batch損失: 0.0455 | 累計平均損失: 0.2921
Epoch: 1/2 | Batch: 800/938 | 單Batch損失: 0.1018 | 累計平均損失: 0.2762
Epoch: 1/2 | Batch: 900/938 | 單Batch損失: 0.2935 | 累計平均損失: 0.2628
Epoch 1/2 完成 | 訓練準確率: 92.42% | 測試準確率: 95.84%
Epoch: 2/2 | Batch: 100/938 | 單Batch損失: 0.1767 | 累計平均損失: 0.1356
Epoch: 2/2 | Batch: 200/938 | 單Batch損失: 0.1742 | 累計平均損失: 0.1289
Epoch: 2/2 | Batch: 300/938 | 單Batch損失: 0.1273 | 累計平均損失: 0.1282
Epoch: 2/2 | Batch: 400/938 | 單Batch損失: 0.2078 | 累計平均損失: 0.1234
Epoch: 2/2 | Batch: 500/938 | 單Batch損失: 0.0236 | 累計平均損失: 0.1209
Epoch: 2/2 | Batch: 600/938 | 單Batch損失: 0.0573 | 累計平均損失: 0.1193
Epoch: 2/2 | Batch: 700/938 | 單Batch損失: 0.0990 | 累計平均損失: 0.1170
Epoch: 2/2 | Batch: 800/938 | 單Batch損失: 0.1580 | 累計平均損失: 0.1152
Epoch: 2/2 | Batch: 900/938 | 單Batch損失: 0.0749 | 累計平均損失: 0.1139
Epoch 2/2 完成 | 訓練準確率: 96.63% | 測試準確率: 96.93%
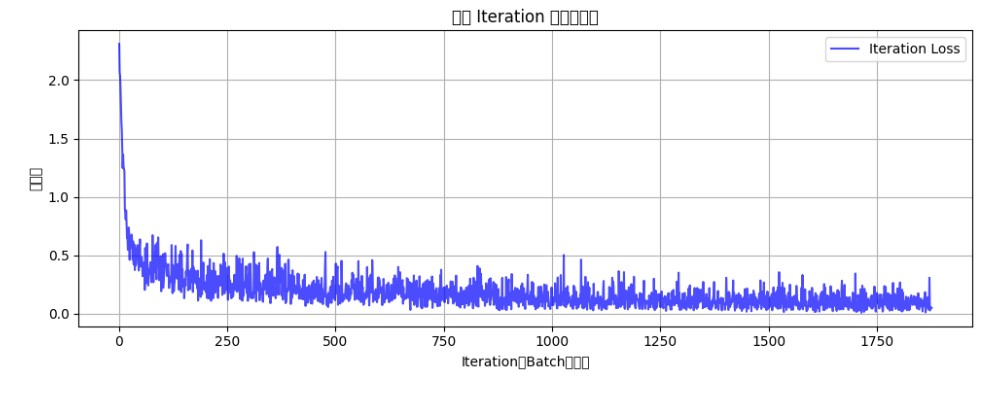
在PyTorch中處理張量(Tensor)時,以下是關于展平(Flatten)、維度調整(如view/reshape)等操作的關鍵點,這些操作通常不會影響第一個維度(即批量維度batch_size):
圖像任務中的張量形狀
輸入張量的形狀通常為:
(batch_size, channels, height, width)
例如:(batch_size, 3, 28, 28)
其中,batch_size 代表一次輸入的樣本數量。
NLP任務中的張量形狀
輸入張量的形狀可能為:
(batch_size, sequence_length)
此時,batch_size 同樣是第一個維度。
- Flatten操作
功能:將張量展平為一維數組,但保留批量維度。
示例:
輸入形狀:(batch_size, 3, 28, 28)(圖像數據)
Flatten后形狀:(batch_size, 3×28×28) = (batch_size, 2352)
說明:第一個維度batch_size不變,后面的所有維度被展平為一個維度。
- view/reshape操作
功能:調整張量維度,但必須顯式保留或指定批量維度。
示例:
輸入形狀:(batch_size, 3, 28, 28)
調整為:(batch_size, -1)
結果:展平為兩個維度,保留batch_size,第二個維度自動計算為3×28×28=2352。
總結
批量維度不變性:無論進行flatten、view還是reshape操作,第一個維度batch_size通常保持不變。
動態維度指定:使用-1讓PyTorch自動計算該維度的大小,但需確保其他維度的指定合理,避免形狀不匹配錯誤。
二、彩色圖片的規范寫法
彩色的通道也是在第一步被直接展平,其他代碼一致
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
import numpy as np# 設置中文字體支持
plt.rcParams["font.family"] = ["SimHei"]
plt.rcParams['axes.unicode_minus'] = False # 解決負號顯示問題# 1. 數據預處理
transform = transforms.Compose([transforms.ToTensor(), # 轉換為張量transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)) # 標準化處理
])# 2. 加載CIFAR-10數據集
train_dataset = datasets.CIFAR10(root='./data',train=True,download=True,transform=transform
)test_dataset = datasets.CIFAR10(root='./data',train=False,transform=transform
)# 3. 創建數據加載器
batch_size = 64
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)# 4. 定義MLP模型(適應CIFAR-10的輸入尺寸)
class MLP(nn.Module):def __init__(self):super(MLP, self).__init__()self.flatten = nn.Flatten() # 將3x32x32的圖像展平為3072維向量self.layer1 = nn.Linear(3072, 512) # 第一層:3072個輸入,512個神經元self.relu1 = nn.ReLU()self.dropout1 = nn.Dropout(0.2) # 添加Dropout防止過擬合self.layer2 = nn.Linear(512, 256) # 第二層:512個輸入,256個神經元self.relu2 = nn.ReLU()self.dropout2 = nn.Dropout(0.2)self.layer3 = nn.Linear(256, 10) # 輸出層:10個類別def forward(self, x):# 第一步:將輸入圖像展平為一維向量x = self.flatten(x) # 輸入尺寸: [batch_size, 3, 32, 32] → [batch_size, 3072]# 第一層全連接 + 激活 + Dropoutx = self.layer1(x) # 線性變換: [batch_size, 3072] → [batch_size, 512]x = self.relu1(x) # 應用ReLU激活函數x = self.dropout1(x) # 訓練時隨機丟棄部分神經元輸出# 第二層全連接 + 激活 + Dropoutx = self.layer2(x) # 線性變換: [batch_size, 512] → [batch_size, 256]x = self.relu2(x) # 應用ReLU激活函數x = self.dropout2(x) # 訓練時隨機丟棄部分神經元輸出# 第三層(輸出層)全連接x = self.layer3(x) # 線性變換: [batch_size, 256] → [batch_size, 10]return x # 返回未經過Softmax的logits# 檢查GPU是否可用
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")# 初始化模型
model = MLP()
model = model.to(device) # 將模型移至GPU(如果可用)criterion = nn.CrossEntropyLoss() # 交叉熵損失函數
optimizer = optim.Adam(model.parameters(), lr=0.001) # Adam優化器# 5. 訓練模型(記錄每個 iteration 的損失)
def train(model, train_loader, test_loader, criterion, optimizer, device, epochs):model.train() # 設置為訓練模式# 記錄每個 iteration 的損失all_iter_losses = [] # 存儲所有 batch 的損失iter_indices = [] # 存儲 iteration 序號for epoch in range(epochs):running_loss = 0.0correct = 0total = 0for batch_idx, (data, target) in enumerate(train_loader):data, target = data.to(device), target.to(device) # 移至GPUoptimizer.zero_grad() # 梯度清零output = model(data) # 前向傳播loss = criterion(output, target) # 計算損失loss.backward() # 反向傳播optimizer.step() # 更新參數# 記錄當前 iteration 的損失iter_loss = loss.item()all_iter_losses.append(iter_loss)iter_indices.append(epoch * len(train_loader) + batch_idx + 1)# 統計準確率和損失running_loss += iter_loss_, predicted = output.max(1)total += target.size(0)correct += predicted.eq(target).sum().item()# 每100個批次打印一次訓練信息if (batch_idx + 1) % 100 == 0:print(f'Epoch: {epoch+1}/{epochs} | Batch: {batch_idx+1}/{len(train_loader)} 'f'| 單Batch損失: {iter_loss:.4f} | 累計平均損失: {running_loss/(batch_idx+1):.4f}')# 計算當前epoch的平均訓練損失和準確率epoch_train_loss = running_loss / len(train_loader)epoch_train_acc = 100. * correct / total# 測試階段model.eval() # 設置為評估模式test_loss = 0correct_test = 0total_test = 0with torch.no_grad():for data, target in test_loader:data, target = data.to(device), target.to(device)output = model(data)test_loss += criterion(output, target).item()_, predicted = output.max(1)total_test += target.size(0)correct_test += predicted.eq(target).sum().item()epoch_test_loss = test_loss / len(test_loader)epoch_test_acc = 100. * correct_test / total_testprint(f'Epoch {epoch+1}/{epochs} 完成 | 訓練準確率: {epoch_train_acc:.2f}% | 測試準確率: {epoch_test_acc:.2f}%')# 繪制所有 iteration 的損失曲線plot_iter_losses(all_iter_losses, iter_indices)return epoch_test_acc # 返回最終測試準確率# 6. 繪制每個 iteration 的損失曲線
def plot_iter_losses(losses, indices):plt.figure(figsize=(10, 4))plt.plot(indices, losses, 'b-', alpha=0.7, label='Iteration Loss')plt.xlabel('Iteration(Batch序號)')plt.ylabel('損失值')plt.title('每個 Iteration 的訓練損失')plt.legend()plt.grid(True)plt.tight_layout()plt.show()# 7. 執行訓練和測試
epochs = 20 # 增加訓練輪次以獲得更好效果
print("開始訓練模型...")
final_accuracy = train(model, train_loader, test_loader, criterion, optimizer, device, epochs)
print(f"訓練完成!最終測試準確率: {final_accuracy:.2f}%")# # 保存模型
# torch.save(model.state_dict(), 'cifar10_mlp_model.pth')
# # print("模型已保存為: cifar10_mlp_model.pth")
開始訓練模型...
Epoch: 1/20 | Batch: 100/782 | 單Batch損失: 1.8807 | 累計平均損失: 1.9089
Epoch: 1/20 | Batch: 200/782 | 單Batch損失: 1.5888 | 累計平均損失: 1.8412
Epoch: 1/20 | Batch: 300/782 | 單Batch損失: 1.7336 | 累計平均損失: 1.7983
Epoch: 1/20 | Batch: 400/782 | 單Batch損失: 1.5493 | 累計平均損失: 1.7679
Epoch: 1/20 | Batch: 500/782 | 單Batch損失: 1.5747 | 累計平均損失: 1.7443
Epoch: 1/20 | Batch: 600/782 | 單Batch損失: 1.5258 | 累計平均損失: 1.7273
Epoch: 1/20 | Batch: 700/782 | 單Batch損失: 1.8130 | 累計平均損失: 1.7144
Epoch 1/20 完成 | 訓練準確率: 39.63% | 測試準確率: 45.20%
Epoch: 2/20 | Batch: 100/782 | 單Batch損失: 1.3518 | 累計平均損失: 1.4666
Epoch: 2/20 | Batch: 200/782 | 單Batch損失: 1.4150 | 累計平均損失: 1.4644
Epoch: 2/20 | Batch: 300/782 | 單Batch損失: 1.6774 | 累計平均損失: 1.4667
Epoch: 2/20 | Batch: 400/782 | 單Batch損失: 1.5217 | 累計平均損失: 1.4600
Epoch: 2/20 | Batch: 500/782 | 單Batch損失: 1.3729 | 累計平均損失: 1.4601
Epoch: 2/20 | Batch: 600/782 | 單Batch損失: 1.5887 | 累計平均損失: 1.4555
Epoch: 2/20 | Batch: 700/782 | 單Batch損失: 1.5309 | 累計平均損失: 1.4560
Epoch 2/20 完成 | 訓練準確率: 48.49% | 測試準確率: 49.26%
Epoch: 3/20 | Batch: 100/782 | 單Batch損失: 1.4234 | 累計平均損失: 1.3375
Epoch: 3/20 | Batch: 200/782 | 單Batch損失: 1.3234 | 累計平均損失: 1.3256
Epoch: 3/20 | Batch: 300/782 | 單Batch損失: 1.2906 | 累計平均損失: 1.3335
Epoch: 3/20 | Batch: 400/782 | 單Batch損失: 1.1346 | 累計平均損失: 1.3364
Epoch: 3/20 | Batch: 500/782 | 單Batch損失: 1.5469 | 累計平均損失: 1.3391
Epoch: 3/20 | Batch: 600/782 | 單Batch損失: 1.3636 | 累計平均損失: 1.3389
Epoch: 3/20 | Batch: 700/782 | 單Batch損失: 1.3753 | 累計平均損失: 1.3411
Epoch 3/20 完成 | 訓練準確率: 52.59% | 測試準確率: 51.27%
...
Epoch: 20/20 | Batch: 500/782 | 單Batch損失: 0.3417 | 累計平均損失: 0.3713
Epoch: 20/20 | Batch: 600/782 | 單Batch損失: 0.4816 | 累計平均損失: 0.3757
Epoch: 20/20 | Batch: 700/782 | 單Batch損失: 0.6223 | 累計平均損失: 0.3821
Epoch 20/20 完成 | 訓練準確率: 86.27% | 測試準確率: 52.40%
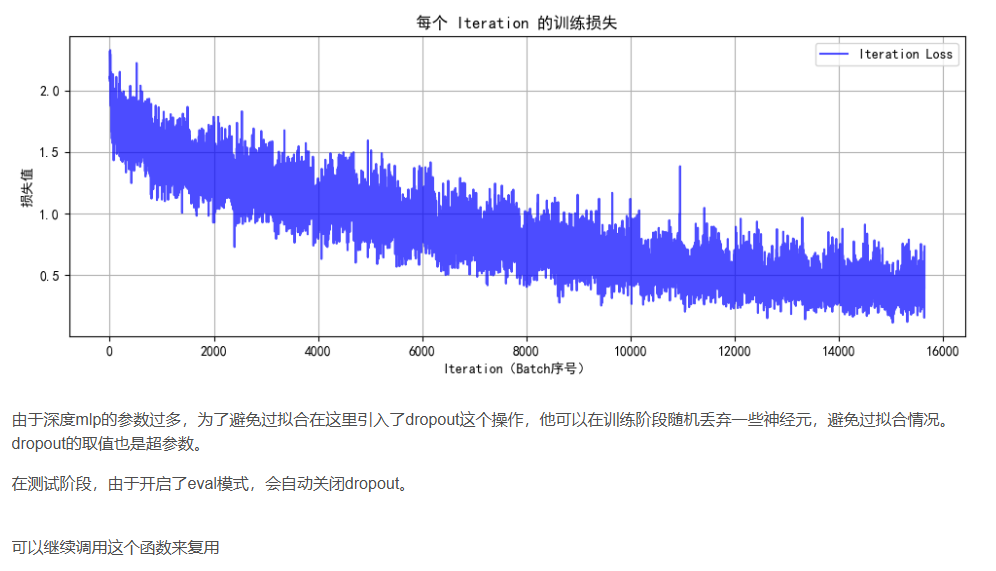
# 7. 執行訓練和測試
epochs = 20 # 增加訓練輪次以獲得更好效果
print("開始訓練模型...")
final_accuracy = train(model, train_loader, test_loader, criterion, optimizer, device, epochs)
print(f"訓練完成!最終測試準確率: {final_accuracy:.2f}%")
開始訓練模型...
Epoch: 1/20 | Batch: 100/782 | 單Batch損失: 1.4619 | 累計平均損失: 1.3271
Epoch: 1/20 | Batch: 200/782 | 單Batch損失: 1.2312 | 累計平均損失: 1.2557
Epoch: 1/20 | Batch: 300/782 | 單Batch損失: 1.1511 | 累計平均損失: 1.2159
Epoch: 1/20 | Batch: 400/782 | 單Batch損失: 0.9654 | 累計平均損失: 1.1774
Epoch: 1/20 | Batch: 500/782 | 單Batch損失: 1.2084 | 累計平均損失: 1.1537
Epoch: 1/20 | Batch: 600/782 | 單Batch損失: 1.2039 | 累計平均損失: 1.1260
Epoch: 1/20 | Batch: 700/782 | 單Batch損失: 1.0381 | 累計平均損失: 1.1123
Epoch 1/20 完成 | 訓練準確率: 63.63% | 測試準確率: 52.61%
Epoch: 2/20 | Batch: 100/782 | 單Batch損失: 0.3717 | 累計平均損失: 0.4796
Epoch: 2/20 | Batch: 200/782 | 單Batch損失: 0.3691 | 累計平均損失: 0.4380
Epoch: 2/20 | Batch: 300/782 | 單Batch損失: 0.3134 | 累計平均損失: 0.4115
Epoch: 2/20 | Batch: 400/782 | 單Batch損失: 0.3479 | 累計平均損失: 0.3937
Epoch: 2/20 | Batch: 500/782 | 單Batch損失: 0.3160 | 累計平均損失: 0.3820
Epoch: 2/20 | Batch: 600/782 | 單Batch損失: 0.4037 | 累計平均損失: 0.3761
Epoch: 2/20 | Batch: 700/782 | 單Batch損失: 0.4130 | 累計平均損失: 0.3708
Epoch 2/20 完成 | 訓練準確率: 87.23% | 測試準確率: 53.91%
Epoch: 3/20 | Batch: 100/782 | 單Batch損失: 0.3526 | 累計平均損失: 0.2483
Epoch: 3/20 | Batch: 200/782 | 單Batch損失: 0.4958 | 累計平均損失: 0.2644
Epoch: 3/20 | Batch: 300/782 | 單Batch損失: 0.2418 | 累計平均損失: 0.2742
Epoch: 3/20 | Batch: 400/782 | 單Batch損失: 0.2887 | 累計平均損失: 0.2823
Epoch: 3/20 | Batch: 500/782 | 單Batch損失: 0.2651 | 累計平均損失: 0.2902
Epoch: 3/20 | Batch: 600/782 | 單Batch損失: 0.4208 | 累計平均損失: 0.2969
Epoch: 3/20 | Batch: 700/782 | 單Batch損失: 0.5297 | 累計平均損失: 0.3066
Epoch 3/20 完成 | 訓練準確率: 88.99% | 測試準確率: 52.74%
...
Epoch: 20/20 | Batch: 500/782 | 單Batch損失: 0.3291 | 累計平均損失: 0.2262
Epoch: 20/20 | Batch: 600/782 | 單Batch損失: 0.3049 | 累計平均損失: 0.2267
Epoch: 20/20 | Batch: 700/782 | 單Batch損失: 0.2965 | 累計平均損失: 0.2274
Epoch 20/20 完成 | 訓練準確率: 92.31% | 測試準確率: 52.40%
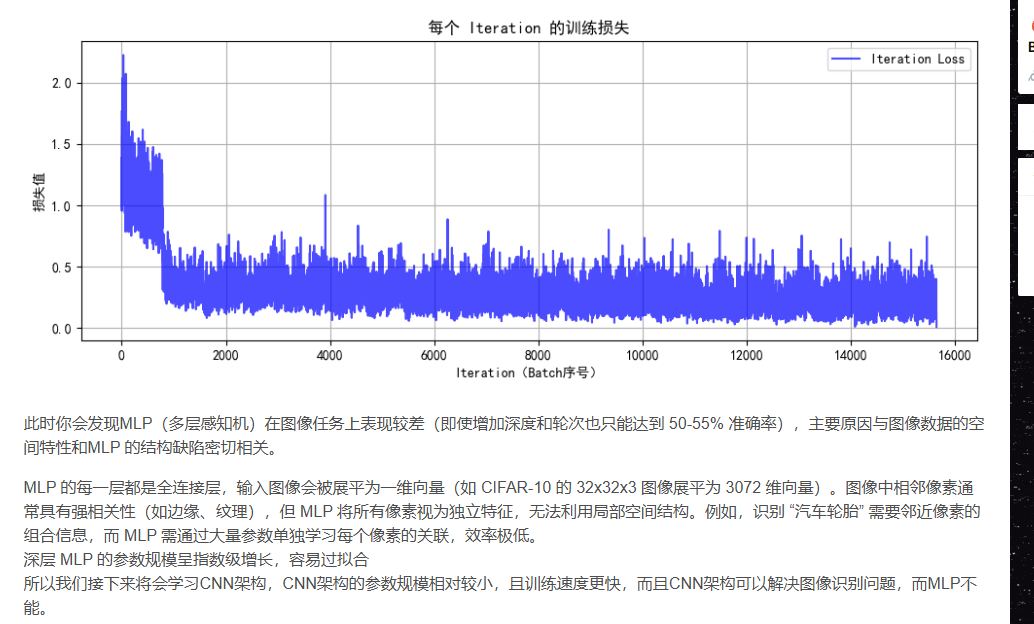
@浙大疏錦行




![[每周一更]-(第155期):深入Go反射機制:架構師視角下的動態力量與工程智慧](http://pic.xiahunao.cn/[每周一更]-(第155期):深入Go反射機制:架構師視角下的動態力量與工程智慧)
)
)












)