Redis是什么
Redis是開源的,使用C語言編寫的,支持網絡交互,可基于內存也可持久化到本地磁盤的Key-Value數據庫。
優點:
- 因為Redis是基于內存的,所以數據的讀取速度很快
- Redis支持多種數據結構,包括字符串String、列表List、字典Hash、集合Set、有序集合Zset、位圖、地理空間等
- Redis支持事務,且所有的操作都是原子性的,要么都執行,要不都不執行
- Redis支持持久化存儲,提供RDB快照和AOF日志追加的兩種持久化方式,解決了Redis宕機后數據丟失問題
- 支持高可用,內置了Redis Sentinel哨兵機制,提供高可用方案,實現故障轉移。內置了Redis Cluster,提供集群方案,實現基于槽的分片方案,從而支持更大的Redis規模
- Redis還由其它豐富的功能,比如Key過期、計數、分布式鎖、消息隊列等
缺點:
- 由于Redis是基于內存的,所以單臺機器存儲的數據量受限于機器本身的內存大小。雖然Redis也支持了多種數據淘汰策略,但還是需要提前預估和節約內存。如果內存增長過快,還需要定期刪除數據
- 修改配置文件進行重啟后,將磁盤中的數據加載到內存,這個時間比較久。在這個過程中,Redis不能對外提供服務
Redis為什么執行這么快
- 首先Redis是C語言實現的,效率高
- Redis是基于內存操作的,不受磁盤IO瓶頸限制
- Redis是單線程模型可以避免因上下文切換及資源競爭導致耗時問題,也不用考慮各種鎖競爭問題
- Redis采用了非阻塞IO多路復用機制提高了網絡IO的傳輸性能
Redis的線程模型
Redis內部使用了文件事件處理器(file event handler),這個文件事件處理器是單線程的,所以Redis才叫做單線程模型。另外還采用了非阻塞的IO多路復用機制同時監聽多個socket,根據socket上的事件來選擇對應的事件處理器進行處理。
文件事件處理器包含4個部分:
- 多個socket
- IO多路復用程序
- 文件事件分派器
- 事件處理器(連接應答處理器、命令請求處理器、命令回復處理器)
多個socket可能會產生不用的操作,每個操作對應不同的文件事件,IO多路復用程序監聽多個socket,會將socket上的事件放入等待隊列中排隊,事件分派器每次從隊列中取出一個事件,把該事件交給對應的事件處理器進行處理。
Redis的數據類型及底層實現
Redis中有5中基礎的數據結構,分別是:String字符串、List列表、Hash、Set集合、Zset有序集合,此外還支持4種不常用的數據結構:BitMap位圖、HyperLogLog基數統計、Geo地理位置、Stream流
String
字符串是最常用的數據類型,在Redis中一個字符串的最大容量是512MB,但是一般建議Key的大小不要超過1KB,這樣既節省空間又有利于檢索。
應用場景:
- 緩存結構信心
- 分布式鎖
- 計數器
LIst
List的底層實現是一個雙向鏈表,支持兩端插入和彈出,并且里面存放的元素是有序的,可以通過索引獲取元素。
應用場景:
- 比如Twitter的關注列表和粉絲列表等都可以用List列表實現,另外還可以通過lrange命令,做分頁功能
- 可以基于rpush和lpop指令,實現消息隊列
Hash
哈希的底層實現是數組+鏈表,通過鏈地址法來解決哈希沖突,沒有用到紅黑樹。
應用場景:
- Hash特別適合存儲對象信息,比如存儲用戶對象信息,用戶id可以作為Key,Value是一個map,map中存放了所有的屬性信息
Set
內部實現是一個Value為null的HashMap,通過hash值去重
應用場景:
- 主要用于存儲不希望又重復數據的場景
Zset
內部使用HashMap和跳躍表來保證數據的不重復且有序。通過提供一個優先級Score參數來保證元素有序。
應用場景:
- 排行榜,比如百度熱搜排行榜
- 也可以用來實現延時隊列,把想要執行時間的時間戳作為score,消息內容作為key,調用zadd來生產消
息,消費者zrangebyscore指令來獲取N秒之前的消息輪詢進行處理
為啥Zset用跳躍表而不用紅黑樹實現?
- skiplist的復雜度和紅黑樹一樣O(log n),而且實現起來更簡單
- 在并發場景下紅黑樹在插入和刪除是都需要rebalance,性能不如跳躍表
跳躍表
? 在一般的鏈表中,如果我們需要查詢一個元素,可能需要遍歷鏈表,這樣的時間復雜度是O(n)。而跳
躍表通過維護一個多層的鏈表,為鏈表查詢提供了“快速通道”。在跳躍表中,每一個節點包含多個
“層”,每一層都有一個前進指針指向下一個節點,通過這種方式,跳躍表能夠在橫向和縱向上進行查
詢,大大提高了查詢效率。
? 跳躍表的查詢、插入和刪除操作都能夠在O(log n)的時間復雜度內完成,這是因為跳躍表中的每一個節
點都包含了多個層,這些層通過前進指針和后退指針,實現了在不同層之間的快速跳轉。
每個跳躍表節點包含以下信息:
- 層(level):每個節點包含多個層,每一層都包含一個前進指針(forward)和一個跨度
(span)。 - 前進指針(forward):指向同一層中的下一個節點。通過前進指針,跳躍表可以在同一層中快速
地定位目標節點。 - 跨度(span):記錄前進指針所跨越的節點個數。跨度的作用是在跳躍表中快速定位目標節點。
后退指針(backward):指向同一層中的前一個節點。通過后退指針,跳躍表可以在同一層中快
速地定位前一個節點。
Redis事務
REdis事務時一組有序命令的集合,是Redis的最小執行單位。可以保證一次執行多個命令,每個事務是一個單獨的隔離操作,事務中的命令按順序執行。不支持回滾。
Redis事務涉及的4個指令:
- Multi 開啟事務
- Exec 執行事務內的命令
- Discard 取消事務
- Watch 監聽一個或多個Key,如果事務執行前Key被改動,事務被打斷
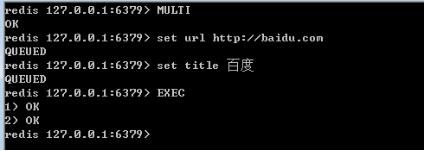
在項目中不使用Redis事務的原因:
- Redids是集群部署的,有16個節點,項目中不同的Key可能分布在不同的節點上,Redis事務對不同節點上的數據操作會失效
- Redis單條命令保證原子性,但事務不保證原子性。
- Redis事務不支持回滾,所以一般不用
Redis的同步機制
Redis支持個主從同步、從從同步,如果第一次進行主從同步,主節點需要使用bgsave命令,再將后續的修改操作記錄保存到內存的緩沖區,等RDB快照文件全部同步到從節點,且從節點加載到內存后,從節點再通知主節點把復制期間修改的操作記錄再次同步到從節點,即可完成同步過程
pipeline 有什么好處,為什么要用 pipeline?
使用pipeline管道的好處在于可以將多次IO往返的事件縮短為一次,但要求管道中執行的命令沒有先后因果關系。
使用pipeline的原因在于客戶端不用每次等待服務器響應后才能處理后續請求,可以將多個請求發送到服務器,只需在最后一步讀取回復即可
Redis的持久化方式
Redis提供兩種持久化方式 RDB快照 和 AOF日志追加:
RDB持久化方式:
RDB 持久化方式能夠在指定的時間間隔對緩存中的數據進行快照存儲。Redis 會段都創建(fork)一個子進程來進行持久化,會先將數據寫入到臨時文件中,待持久化過程都結束了,再用這個臨時文件替換上次持久化好的文件。整個過程中,主進程是不進行任何IO 操作的,這就確保了極高得性能,如果需要進行大規模數據的恢復,且對數據恢復得完整性不是非常敏感,那么RDB 方式要比 AOF 方式更加高效。
保存策略:
save 900 1 900 秒內如果至少有 1 個 key 的值變化,則保存
save 300 10 300 秒內如果至少有 10 個 key 的值變化,則保存
save 60 1 0000 60 秒內如果至 10000 個 key 的值變化,則保存
優點:
- 只有一個dump.rdb文件,方便持久化
- 容災性好,一個文件可以保存到安全的磁盤
- 高性能,fork子進程來完成寫操作,讓主進程繼續處理命令,IO最大化
- 當數據量比較大時,比AOF的啟動效率更高
缺點:
- 數據安全性低,因為RDB時間隔一段時間進行持久化,如果持久化之間發生故障,那么就會導致數據丟失。所以這種方式更適合數據要求不嚴謹的業務場景。
AOF=Append-only file 持久化方式:
將所有執行的命令以追加的方式記錄到AOF日志文件中。Redis 重新啟動時讀取這個文件,重新執行日志文件中的命令達到恢復數據目的。
保存策略:
appendfsync always:每次產生一條新的修改數據的命令都執行保存操作;會影響性能,但是安全!
appendfsync everysec:每秒執行一次保存操作。如果在未保存當前秒內操作時發生了斷電,仍然會導致一部分數據丟失(即 1 秒鐘的數據)。
appendfsync no:命令僅寫入 AOF 緩沖區,由操作系統決定何時同步到磁盤(通常依賴操作系統的頁緩存機制,可能每 30 秒左右同步一次)。性能影響最小,也更不安全的選擇。推薦(并且也是默認)的措施為每秒 fsync 一次, 這種 fsync 策略可以兼顧速度和安全性。
優點:
- 數據安全,可以在配置文件中配置命令寫入的頻次,避免數據丟失
- 通過 append 模式寫文件,即使中途服務器宕機,可以通過 redis-check-aof 工具解決數據
一致性問題 - AOF機制的rewrite模式。AOF文件沒被rewrite之前,可以對文件中的命令調整。
缺點:
- AOF文件比RDB文件大,且恢復速度慢
- 數據集大的時候,比RDB啟動效率低。
兩種持久化方式,要搭配使用:
- 不要僅僅使用 RDB ,因為那樣會導致你丟失很多數據。
- 也不要僅僅使用 AOF ,因為那樣有兩個問題,第一,你通過 AOF 做冷備沒有 RDB 做冷備的恢
復速度更快; 第二, RDB 每次簡單粗暴生成數據快照,更加健壯,可以避免 AOF 這種復雜的備
份和恢復機制的 bug 。 - Redis 支持同時開啟開啟兩種持久化方式,我們可以綜合使用 AOF 和 RDB 兩種持久化機制,
用 AOF 來保證數據不丟失,作為數據恢復的第一選擇; 用 RDB 來做不同程度的冷備,在 AOF
文件都丟失或損壞不可用的時候,還可以使用 RDB 來進行快速的數據恢復。 - 如果同時使用 RDB 和 AOF 兩種持久化機制,那么在 Redis 重啟的時候,會使用 AOF 來重新
構建數據,因為 AOF 中的數據更加完整。
假如Redis中有1億個key,找出其中所有指定前綴的key
使用keys指令可以掃出指定模式的key列表,但使用keys指令會阻塞正在提供服務,因為Redis時單線程的,直到keys指令執行完畢,服務才能恢復。也可以使用scan指令,scan指令可以無阻塞提取指定模式的key列表,但是會有一定的重復概率,需要在客戶端做去重處理,另外耗時較長。
怎么使用 Redis 實現消息隊列?
一般使用 list 結構作為隊列, rpush 生產消息, lpop 消費消息。當 lpop 沒有消息的時候,要適當
sleep 一會兒再重試。
- 面試官可能會問可不可以不用 sleep 呢?list 還有個指令叫 blpop ,在沒有消息的時候,它會
阻塞住直到消息到來。 - 面試官可能還問能不能生產一次消費多次呢?使用 pub / sub 主題訂閱者模式,可以實現 1:N
的消息隊列。 - 面試官可能還問 pub / sub 有什么缺點?在消費者下線的情況下,生產的消息會丟失,得使用
專業的消息隊列如 rabbitmq 等。 - 面試官可能還問 Redis 如何實現延時隊列?使用sortedset ,拿時間戳作為 score ,消息內容作為
key 調用 zadd 來生產消息,消費者用zrangebyscore 指令獲取 N 秒之前的數據輪詢進行處理
什么是 bigkey?會存在什么影響?
bigkey 是指鍵值占用內存空間非常大的 key。例如一個字符串 a 存儲了 200M 的數據。
bigkey 的主要影響有:
- 網絡阻塞;獲取 bigkey 時,傳輸的數據量比較大,會增加帶寬的壓力。
- 超時阻塞;因為 bigkey 占用的空間比較大,所以操作起來效率會比較低,導致出現阻塞的可能
性增加。
為什么Redis操作是原子性的,怎么保證原子性?
Redis中,命令的原子性是指:一個操作不可再分,要么執行,要么不執行。
Redis的操作之所以是原子性的,是因為Redis是單線程的。單個命令都是原子性的,若要保證多個命令具有原子性,可以通過Redis+Lua腳本的方式實現。
緩存雪崩、緩存穿透、緩存擊穿、緩存更新、緩存降級等問題
緩存雪崩
緩存中的Key在同一時間大面積到期,導致大量請求都直接訪問數據庫,對數據庫CPU和內存造成巨大壓力,甚至宕機。
解決方案:
- 將緩存的失效時間分散開
- 訪問數據庫時上鎖,避免同一時間大量請求發到數據庫
緩存穿透
查詢的數據在數據庫中也沒有,在緩存中自然也沒有,每次首先查緩存查不到,都會再次查詢數據庫。若存在大量的這種請求,就會對數據庫造成巨大壓力。
解決方案:
- 使用布隆過濾器:對所有的key都做哈希放到一個足夠大的bitmap中,bitmap中存放的都是0,1,在查詢時若經過hash計算后,在bitmap中對應位置是0,那么數據肯定就不存在,可以直接返回空。為避免hash沖突,可以考慮多次hash。存在誤判的情況。
- 若查詢數據庫為空,那么仍然緩存一個空置,并且設置一個很短的過期時間,比如1分鐘。這樣在短時間內,就避免了查詢數據庫。
緩存擊穿
熱點Key在緩存中失效的瞬間,大量并發請求直接穿透緩存訪問數據庫,導致數據庫壓力驟增甚至崩潰的現象。
解決方案:
- 熱點Key永不過期,但犧牲了一致性,可以通過定時任務定期更新緩存
- 互斥鎖:在緩存失效時,通過鎖確保只有一個請求可以訪問數據,其他請求等待鎖釋放后從緩存讀取數據。
如何保證緩存和數據庫的一致性
核心策略:先更新數據庫,再刪除緩存
- 優勢
- 邏輯簡單,避免復雜緩存更新邏輯
- 窗口期短(僅 DB 更新成功 → 緩存刪除之間可能不一致)
- 存在的問題及解決方案
- 緩存刪除失敗:引入異步重試機制,寫數據庫后,將
刪除緩存操作發到 消息隊列 (Kafka/RabbitMQ),消費者自動重試直到成功。 - 短暫不一致窗口期:
- 設置 合理的緩存過期時間 (如 30s),作為兜底策略。
- 對一致性要求高的數據,在讀取時采用 互斥鎖(降低并發讀舊數據概率)。
- 緩存刪除失敗:引入異步重試機制,寫數據庫后,將
終極一致性方案:訂閱數據庫變更日志 (Binlog)
? 工作流程:
- 使用 Canal 或 Debezium 監聽 MySQL Binlog。
- 將數據變更事件發到消息隊列。
- 消費者根據事件 刪除/更新 Redis 緩存。
💡 優勢:
- 徹底解耦:應用無需關注緩存刪除邏輯
- 強順序保證:Binlog 天然有序,避免并發導致的數據錯亂
- 高可靠性:即使應用重啟,也能從斷點繼續處理
應對高并發寫:延遲雙刪
? 使用場景:
- 在"先刪緩存再更新DB"策略中,防止舊數據在更新期間被重新加載到緩存
- 第二次刪除用于清理可能存在的臟數據
?? 注意:
- 延遲時間需根據業務讀寫耗時調整(通常 200ms~1s)
- 需配合消息隊列實現可靠延遲
延時雙刪(解決并發讀問題)
-
流程
- 先刪除緩存
- 更新數據庫
- 延遲 N 秒(通常 1-3 秒)再次刪除緩存
-
作用:
處理 “刪除緩存后,有讀請求在數據庫更新前讀取舊值并重建緩存” 的問題。
Redis哈希槽
Redis 集群沒有使用一致性 hash,而是引入了哈希槽的概念,Redis 集群有 16384 個哈希槽,每個 key 通
過 CRC16 校驗后對 16384 取模來決定放置哪個槽,集群的每個節點負責一部分 hash 槽。
Redis集群模式
Redis 集群(Redis Cluster)是 Redis 官方提供的分布式解決方案,用于解決單機 Redis 的性能瓶頸(內存、QPS)和單點故障問題。它通過 數據分片(Sharding)、高可用(HA) 和 自動故障轉移 三大核心能力,實現大規模數據存儲與高性能訪問
一、核心特性
| 特性 | 說明 |
|---|---|
| 數據分片 | 將數據自動拆分到 16384 個 Slot 中,分散在多個節點(分片)存儲 |
| 去中心化架構 | 節點間使用 Gossip 協議 通信,無需代理層(如 Twemproxy/Codis) |
| 高可用 | 每個分片包含 主節點(Master) + 從節點(Replica),支持自動故障轉移 |
| 客戶端路由 | 客戶端直接連接集群,通過 CRC16(key) mod 16384 計算 Slot 并路由到正確節點 |
| 線性擴展 | 支持動態增刪節點,數據自動重平衡(Resharding) |
二、集群架構
- 最小集群規模:3 個主節點 + 3 個從節點(生產環境推薦至少 6 節點)
- Slot 分配:每個主節點負責一部分 Slot(如節點 A 管理 Slot 0-5500,節點 B 管理 5501-11000 等)
- 故障轉移:主節點宕機時,從節點自動升主(由其他主節點投票選舉)
集群方案對比
| 方案 | 優點 | 缺點 | 適用場景 |
|---|---|---|---|
| 官方集群 | 原生支持、去中心化、自動故障轉移 | 客戶端需支持集群協議、跨Slot操作復雜 | 大規模數據、高可用要求 |
| Codis | 兼容舊客戶端、Proxy 層透明 | 引入代理層(性能損耗)、依賴 ZooKeeper | 平滑遷移、多語言生態 |
| Redis Sentinel | 簡單、主從自動切換 | 不分片(單機內存受限) | 中小規模、高可 |
Redis常見的性能問題和解決方案
- Master最好不要做任何持久化工作,避免因負載導致服務崩潰
- 如果數據比較重要,某個Slave開啟AOF備份數據,策略設置為每秒同步一次
- 為了主從復制的速度和連接的穩定性,Master 和 Slave最好在同一個局域網內
- 盡量避免在壓力很大的主庫上增加從庫
- 主從復制不要用圖狀結構,用單向鏈表結構更為穩定,即:Master <- Slave1 <- Slave2…;這樣的結構方便解決單點故障問題,實現Slave對Master的替換
什么情況下可能會導致 Redis 阻塞?
Redis 產生阻塞的原因主要有內部和外部兩個原因導致:
內部原因:
- 如果 Redis 主機的 CPU 負載過高,也會導致系統崩潰;
數據持久化占用資源過多; - 對 Redis 的 API 或指令使用不合理,導致 Redis 出現問題。
外部原因:
? 外部原因主要是服務器的原因,例如服務器的 CPU 線程在切換過程中競爭過大,內存出現問題、網
絡問題等。
Redis中的數據淘汰策略
Redis中的內存淘汰策略時當內存使用達到預設值maxmemory限制時,刪除部分數據釋放空間。
-
noeviction(默認策略)
- 行為:內存滿時,不再支持寫入操作(OOM錯誤),僅支持讀/刪除命令
- 場景:需要保證數據的完整性(如金融交易數據)
-
volatile-ttl
- 行為:從所有設置有過期時間key中,找出剩余生存時間最短的數據刪除
- 場景:需要優先清理即將過期的數據(如限時優惠券)
-
volatile-random
- 行為:隨機淘汰有過期時間的鍵
- 場景:數據不重要且無訪問規律(如臨時會話數據)
-
volatile-lru
- 行為:基于LRU(Least Recently Used),淘汰設置了過期時間的鍵中最近最少使用的鍵
- 場景:區分冷熱數據且需要持久化部分關鍵數據(如用戶登錄會話)
-
volatile-lfu
- 行為:基于LFU(Least Frequently Used),淘汰設置了過期時間中使用頻率最低的鍵
- 場景:適用于緩存短時高頻訪問數據(如突發熱點新聞數據)
-
allkeys-random
- 行為:從所有鍵中隨機淘汰鍵,無論是否設置過期時間
- 場景:數據無冷熱區分或訪問均勻(如靜態資源緩存)
-
allkeys-lru
- 行為:基于LRU(Least Recently Used),淘汰所有鍵中最近最少使用的鍵
- 場景:緩存場景需保留高頻訪問數據(如電商熱點數據)
-
allkeys-lfu
- 行為:基于LFU(Least Frequently Used),淘汰所有鍵中使用頻率最低的鍵
- 場景:需要長期保留高頻訪問數據(如用戶行為畫像數據)
Redis實現分布式鎖
核心設計原則
分布式鎖五大特性
| 特性 | 說明 | 實現方案 |
|---|---|---|
| 互斥性 | 同一時刻只能有一個客戶端持有鎖 | Redis的原子操作 |
| 防死鎖 | 鎖必須支持自動釋放 | key設置過期時間 |
| 容錯性 | Redis節點故障時仍可用 | 多節點部署 |
| 身份安全 | 只能由鎖持有者釋放鎖 | 唯一標識校驗 |
| 可重入性 | 同一客戶端可多次獲取鎖 | 計數器實現 |
基礎實現方案
單節點Redis鎖(SETNX方案)
// 加鎖
String lockKey = "order_lock_123";
String clientId = UUID.randomUUID().toString();
boolean locked = jedis.set(lockKey, clientId, "NX", "PX", 30000) != null;// 解鎖(Lua腳本保證原子性)
String script = "if redis.call('get', KEYS[1]) == ARGV[1] then " +" return redis.call('del', KEYS[1]) " +"else " +" return 0 " +"end";
jedis.eval(script, Collections.singletonList(lockKey), Collections.singletonList(clientId));
| 參數 | 值 | 作用 |
|---|---|---|
| NX | 不存在才設置 | 保證互斥性 |
| PX | 3000ms | 30s自動過期防止死鎖 |
| clientId | UUID | 唯一標識持有者,保證身份安全 |
分布式高可用方案(RedLock算法)
Java實現(Redisson庫)
Config config = new Config();
config.useClusterServers().addNodeAddress("redis://node1:6379").addNodeAddress("redis://node2:6379").addNodeAddress("redis://node3:6379");RedissonClient redisson = Redisson.create(config);
RLock lock = redisson.getLock("orderLock");try {// 嘗試加鎖,最多等待10秒,鎖自動釋放時間30秒if (lock.tryLock(10, 30, TimeUnit.SECONDS)) {// 執行業務邏輯}
} finally {lock.unlock();
}
鎖續期(Watchdog機制)
// Redisson的看門狗實現(默認每10秒續期)
private void scheduleExpirationRenewal(String threadId) {Timeout task = commandExecutor.getConnectionManager().newTimeout(new TimerTask() {@Overridepublic void run(Timeout timeout) {// 異步續期操作renewExpirationAsync(threadId);}}, internalLockLeaseTime / 3, TimeUnit.MILLISECONDS);
}
可重入鎖實現
-- 加鎖Lua腳本(支持可重入)
local counter = redis.call('hget', KEYS[1], ARGV[1])
if counter thenredis.call('hincrby', KEYS[1], ARGV[1], 1)redis.call('pexpire', KEYS[1], ARGV[2])return 1
elseif redis.call('exists', KEYS[1]) == 0 thenredis.call('hset', KEYS[1], ARGV[1], 1)redis.call('pexpire', KEYS[1], ARGV[2])return 1endreturn 0
end
性能優化策略
鎖分段優化(提升并發)
// 將大鎖拆分為多個小鎖
String[] segmentLocks = new String[16];
for (int i = 0; i < 16; i++) {segmentLocks[i] = "order_lock_" + i;RLock lock = redisson.getLock(segmentLocks[i]);// 分別加鎖
}
容災處理方案
Redis節點故障處理
| 場景 | 解決方案 |
|---|---|
| 主節點宕機 | 啟用哨兵自動切換 |
| 網絡分區 | 使用NTP時間同步 |
| 持久化丟失 | 啟用AOF+RDB備份 |
鎖狀態監控
# Redis監控命令
redis-cli info stats | grep sync_full # 檢查主從同步
redis-cli slowlog get # 分析慢查詢
最佳實踐
-
TTL設置原則
- 業務最大執行時間 < TTL < Redis主從切換時間
- 推薦值:30s-120s
-
集群部署建議
-
壓測指標參考
指標 單節點 三節點集群 加鎖QPS 15,000 45,000 解鎖延遲 <2ms <5ms 鎖續期間隔 10秒 10秒
多種分布式鎖對比
| 方案 | 優點 | 缺點 | 適用場景 |
|---|---|---|---|
| Redis鎖 | 高性能、易擴展 | 需要處理時鐘漂移 | 高并發業務 |
| Zookeeper | 強一致性 | 性能較低 | 金融交易 |
| Etcd | 高可用、租約機制 | 部署復雜 | 云原生系統 |
| DB鎖 | 簡單直接 | 性能瓶頸 | 低頻操作 |
推薦選擇:對于大多數業務場景,使用Redis分布式鎖(配合Redisson庫)是最佳平衡方案
典型問題解決方案
問題1:鎖提前過期
- 方案:實現鎖續期機制(Watchdog)
- 代碼:
lock.tryLock(0, 30, SECONDS) // 自動續期
問題2:主從切換丟鎖
- 方案:使用RedLock算法
- 配置:至少3個獨立Redis實例
問題3:客戶端阻塞導致超時
- 方案:設置合理的等待時間
- 代碼:
lock.tryLock(100, TimeUnit.MILLISECONDS)
問題4:鎖重入需求
- 方案:使用可重入鎖(RLock)
- 代碼:
redisson.getLock().lock() // 可多次調用
watch dog 自動延期機制
? 客戶端 1 加鎖的鎖 key 默認生存時間才 30 秒,如果超過了 30 秒,客戶端 1 還想一直持有這把
鎖,怎么辦呢?
? 簡單!只要客戶端 1 一旦加鎖成功,就會啟動一個 watch dog 看門狗, 他是一個后臺線程,會
每隔 10 秒檢查一下,如果客戶端 1 還持有鎖 key,那么就會不斷的延長鎖 key 的生存時間。
Redis 在項目中的應用
Redis 一般來說在項目中有幾方面的應用
-
作為緩存,將熱點數據進行緩存,減少和數據庫的交互,提高系統的效率
-
作為分布式鎖的解決方案,解決緩存擊穿等問題
-
作為消息隊列,使用 Redis 的發布訂閱功能進行消息的發布和訂閱
Redis 服務器的的內存是多大
可以在配置文件中設置 redis得內存。如果不設置或者設置為0,則redis得默認內存為:32位下默認是 3G,64位下不受限制。一般推薦 Redis設置內存位最大物理內存的四分之三,也就是0.75。也可以通過命令 config set maxmemory <內存大小,單位字節> 來配置內存大小,但服務器重啟后失效。config get maxmemory 獲取當前內存大小
哨兵模式
在主從模式下,如果Master 節點異常,則會進行 主從切換,將其中一個 Slave 從節點作為 Master節點,將之前的Master節點作為Salve節點
判斷主節點下線:
- 主觀下線:指的是某個Sentinel哨兵節點 對某個 redis 服務器節點做出下線判斷
- 客觀下線:指的是某個Sentinel哨兵節點對 Master節點做出了主觀下線判斷,并且通過 sentinel is-master-down-by-addr 命令互相交流后,得出master主節點下線判斷,然后開啟failover 失敗轉移
工作原理:
- 每個 Sentinel 哨兵以每秒一次的頻率向它所知得master、slave以及其它sentinel 實例發送一個 PING命令;
- 如果某個實例距離最后一次有效回復 PING命令得時間超過 down-after-milliseconds 選項設定的值,則這個實例就會被標記為主觀下線
- 如果一個Master被標記為主觀下線,則正在監視這個Master 得所有 Sentinel 要以每秒一次得頻率確認 Master 的確進如了主觀下線狀態
- 當有足夠數量的 Sentinel(大于等于配置文件中指定的值)在指定時間范圍內確認 Master 的確進入了主觀下線狀態,則Master 會被標記為客觀下線
- 一般情況下,每個Sentinel 會以每10秒一次的頻率向它已知的所有Master,Slave 發送INFO命令
- 當Master 被Sentinel標記為客觀下線時,Sentinel向下線的Master的所有Slave 發送 INFO 命令的頻率會從10秒一次改為每秒一次
- 若沒有足夠數量的 Sentinel統一 Master已經下線,Master的客觀下線狀態就會被移除
entinel哨兵節點 對某個 redis 服務器節點做出下線判斷 - 客觀下線:指的是某個Sentinel哨兵節點對 Master節點做出了主觀下線判斷,并且通過 sentinel is-master-down-by-addr 命令互相交流后,得出master主節點下線判斷,然后開啟failover 失敗轉移
工作原理:
- 每個 Sentinel 哨兵以每秒一次的頻率向它所知得master、slave以及其它sentinel 實例發送一個 PING命令;
- 如果某個實例距離最后一次有效回復 PING命令得時間超過 down-after-milliseconds 選項設定的值,則這個實例就會被標記為主觀下線
- 如果一個Master被標記為主觀下線,則正在監視這個Master 得所有 Sentinel 要以每秒一次得頻率確認 Master 的確進如了主觀下線狀態
- 當有足夠數量的 Sentinel(大于等于配置文件中指定的值)在指定時間范圍內確認 Master 的確進入了主觀下線狀態,則Master 會被標記為客觀下線
- 一般情況下,每個Sentinel 會以每10秒一次的頻率向它已知的所有Master,Slave 發送INFO命令
- 當Master 被Sentinel標記為客觀下線時,Sentinel向下線的Master的所有Slave 發送 INFO 命令的頻率會從10秒一次改為每秒一次
- 若沒有足夠數量的 Sentinel統一 Master已經下線,Master的客觀下線狀態就會被移除
- 若 Master 重新向 Sentinel 的PING 命令返回有效恢復,Master 的主觀下線狀態就會被移除;











-什么是以太幣)







