一、LangSmith
????????LangSmith是LangChain的一個子產品,是一個大模型應用開發平臺。它提供了從原 型到生產的全流程工具和服務,幫助開發者構建、測試、評估和監控基于LangChain 或其他 LLM 框架的應用程序。
安裝 LangSmith
????????pip install langsmith==0.1.137
官網:LangSmith
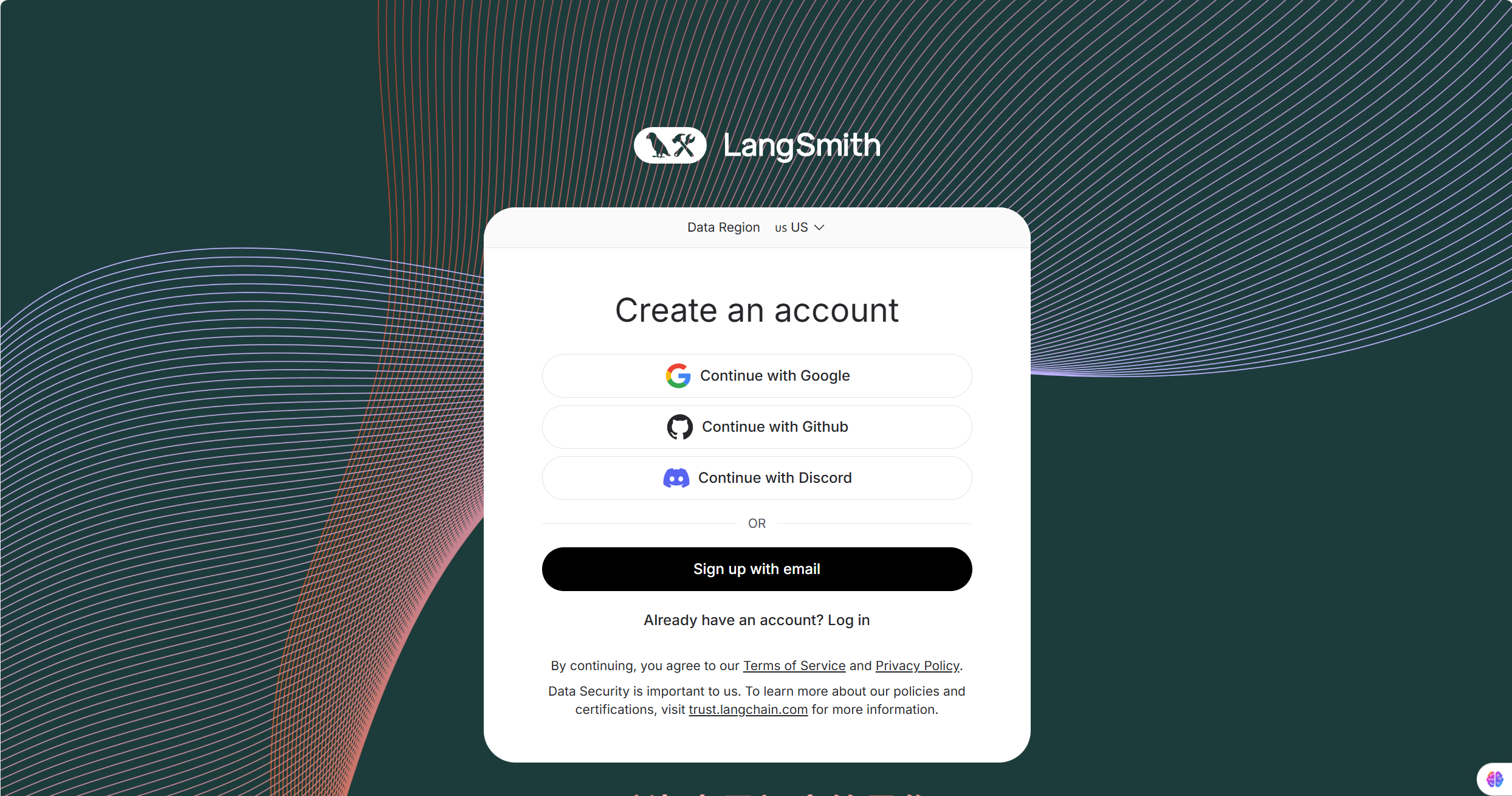
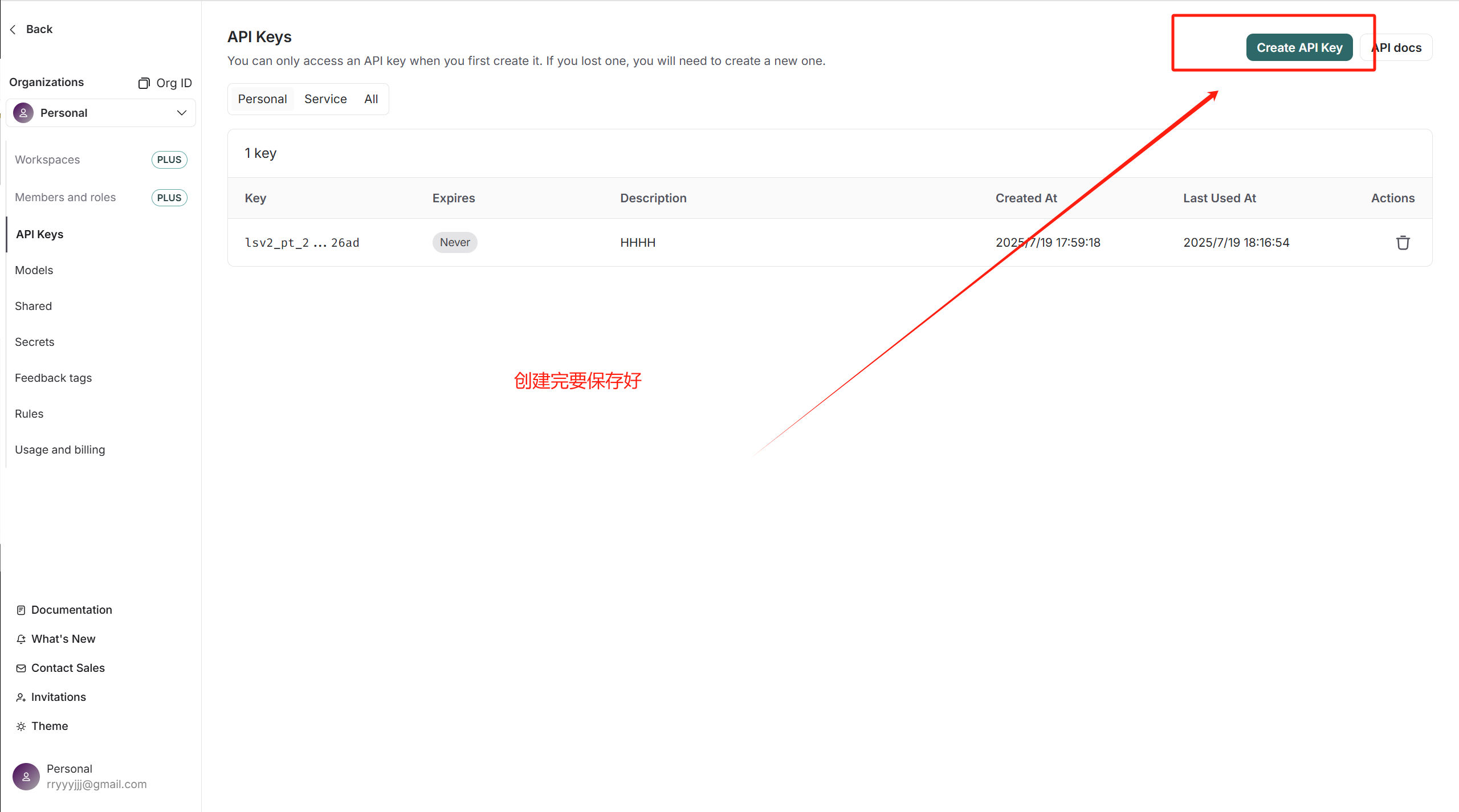
api_key創建
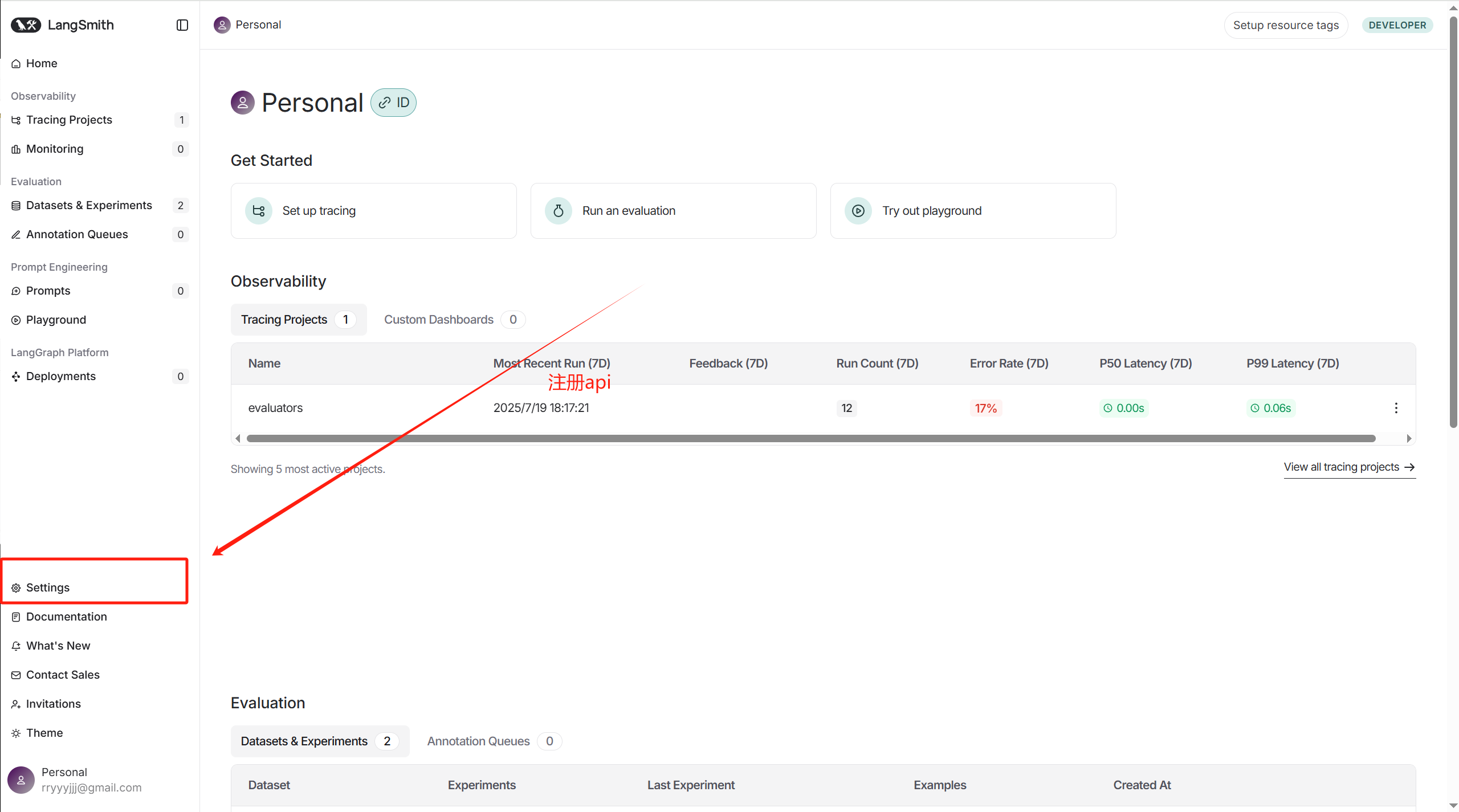
導入測試數據
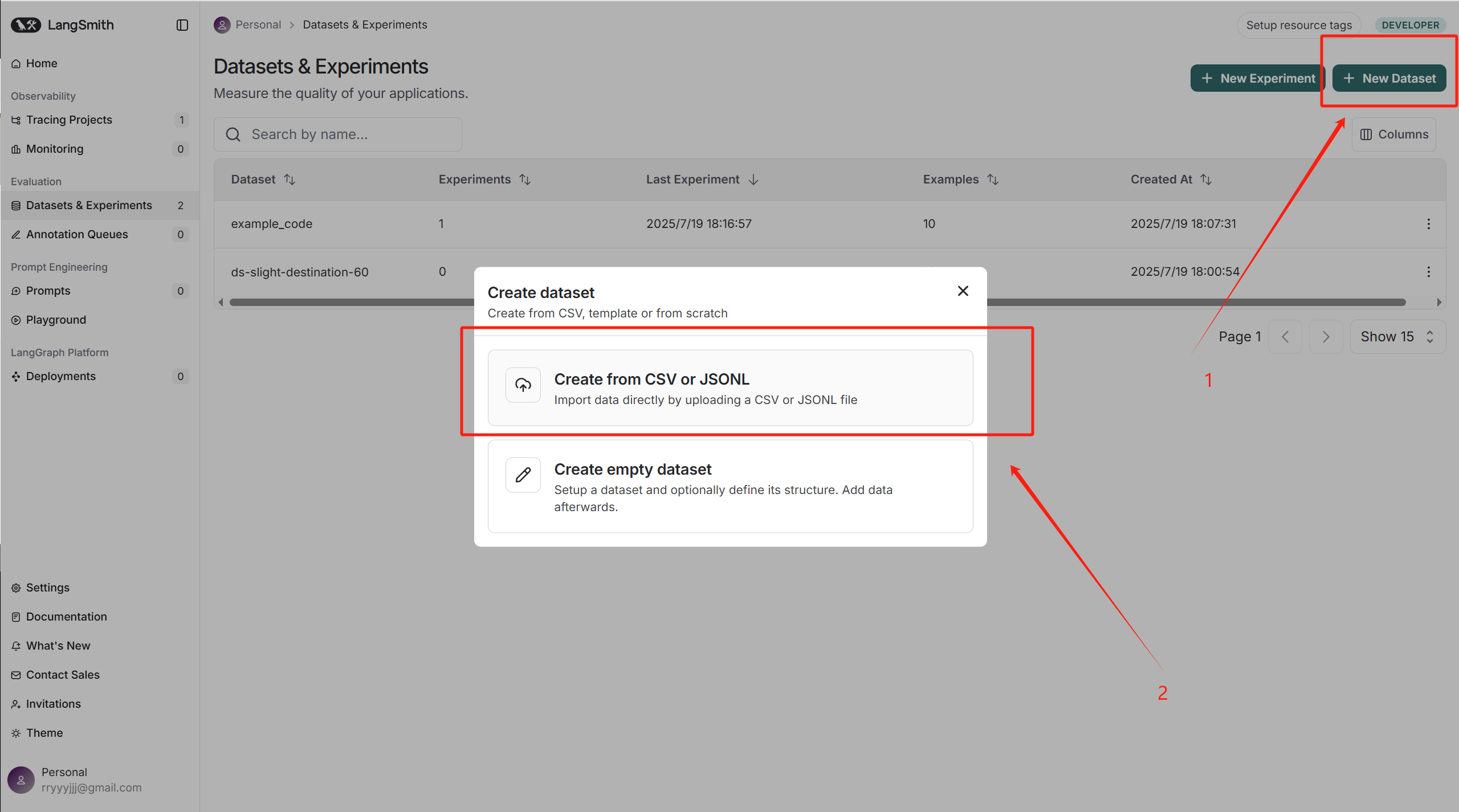
新建一個測試集
import pandas as pd df=pd.read_csv('黑悟空.csv') example=list(df.itertuples(index=False,name=None))from langsmith import Client client=Client(api_key="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") dataset_name="example_code"dataset=client.create_dataset(dataset_name=dataset_name) for q,a in example:client.create_example(inputs={"問題": q}, outputs={"答案": a}, dataset_id=dataset.id)api_key要替換為自己的
二、使用LangSmith進行評估
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
import os
from langsmith import evaluate, Client
from langsmith.schemas import Example, Run1. 初始化模型
# ChatOpenAI 是一個封裝了 OpenAI API 的類
chat_model = ChatOpenAI(# api_key 設置為 'EMPTY',因為本地服務通常不要求密鑰api_key='EMPTY',# base_url 指向本地運行的兼容 OpenAI API 的服務,如 Qwen 或 ollamabase_url='http://127.0.0.1:10222/v1',# model 指定要使用的模型名稱model='Qwen2.5-7B-Instruct'
)2.定義聊天提示詞模板
# ChatPromptTemplate 用于構建結構化的聊天輸入
system_message = "你是一個機器人"
prompt = ChatPromptTemplate.from_messages([# ("system", ...) 定義了系統角色指令("system", system_message),# ("user", ...) 定義了用戶的輸入模板,{問題} 是一個占位符("user", "{問題}")
])3. 定義輸出解析器
# StrOutputParser 將模型的輸出從對象格式解析為純字符串
output_parser = StrOutputParser()4. 使用 LCEL (LangChain 表達式語言) 將各個組件串聯成一個鏈
# 管道符 "|" 將數據流依次從 prompt -> chat_model -> output_parser
chain = prompt | chat_model | output_parser5. 設置 LangSmith 相關的環境變量
# 這些變量用于將本地的運行軌跡上傳到 LangSmith 平臺
os.environ["LANGCHAIN_TRACING_V2"] = "true" # 開啟追蹤功能
os.environ["LANGCHAIN_ENDPOINT"] = "https://api.smith.langchain.com" # LangSmith API 地址
# 注意:此處的 API 密鑰是公共示例,生產環境請勿泄露
os.environ["LANGCHAIN_API_KEY"] = "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"
6.創建并/或選擇數據集
# Client 用于與 LangSmith 平臺交互
client = Client()
dataset_name = "example_code"
# 從 LangSmith 公共庫克隆一個數據集,作為評估的“黃金標準”
dataset = client.clone_public_dataset("https://smith.langchain.com/public/a63525f9-bdf2-4512-83e3-077dc9417f96/d", dataset_name=dataset_name)
7.定義一個自定義評估器
# 評估器是一個函數,用于根據LLM的輸出和數據集的黃金標準來打分
def is_concise_enough(root_run: Run, example: Example) -> dict:# 評估邏輯:檢查模型的輸出長度是否小于黃金標準答案長度的3倍score = len(root_run.outputs["output"]) < 3 * len(example.outputs["答案"])# 返回一個字典,其中 key 是評估指標名稱,score 是分數return {"key": "is_concise", "score": int(score)}8.運行評估
# evaluate() 函數用于執行自動化評估
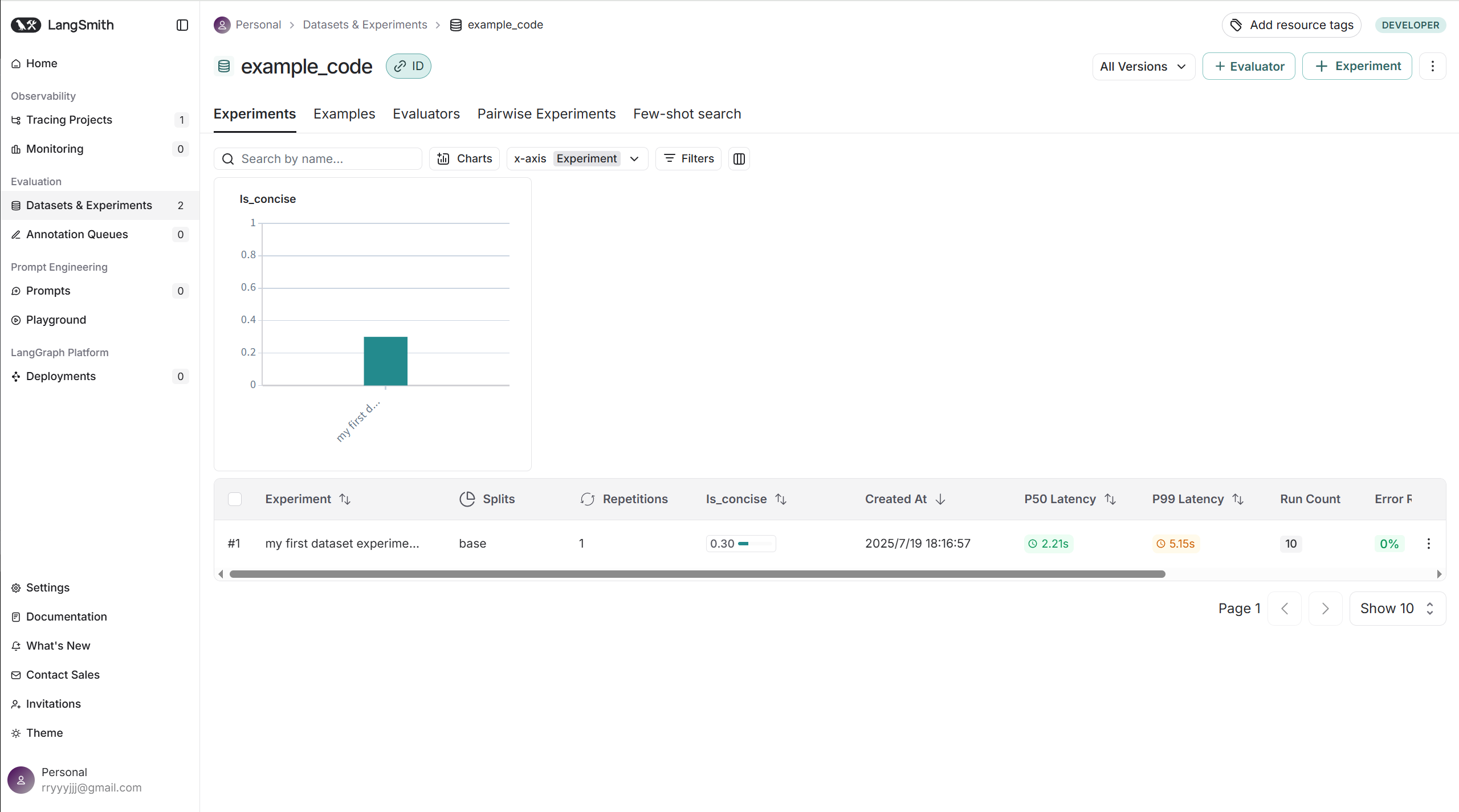
evaluate(# 第一個參數是“待評估的函數”,即我們的 LLM 鏈# lambda x: chain.invoke(x["問題"]) 將數據集中的“問題”字段傳遞給鏈lambda x: chain.invoke(x["問題"]),data=dataset_name, # 指定要使用的數據集evaluators=[is_concise_enough], # 傳入自定義評估器列表experiment_prefix="my first dataset experiment " # 為本次評估添加一個前綴
)完整代碼
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
import os
from langsmith import evaluate, Client
from langsmith.schemas import Example, Run# 1. 實例化 LLM 模型,并配置其連接到本地服務
# ChatOpenAI 是一個封裝了 OpenAI API 的類
chat_model = ChatOpenAI(# api_key 設置為 'EMPTY',因為本地服務通常不要求密鑰api_key='EMPTY',# base_url 指向本地運行的兼容 OpenAI API 的服務,如 Qwen 或 ollamabase_url='http://127.0.0.1:10222/v1',# model 指定要使用的模型名稱model='Qwen2.5-7B-Instruct'
)# 2. 定義聊天提示詞模板
# ChatPromptTemplate 用于構建結構化的聊天輸入
system_message = "你是一個機器人"
prompt = ChatPromptTemplate.from_messages([# ("system", ...) 定義了系統角色指令("system", system_message),# ("user", ...) 定義了用戶的輸入模板,{問題} 是一個占位符("user", "{問題}")
])# 3. 定義輸出解析器
# StrOutputParser 將模型的輸出從對象格式解析為純字符串
output_parser = StrOutputParser()# 4. 使用 LCEL (LangChain 表達式語言) 將各個組件串聯成一個鏈
# 管道符 "|" 將數據流依次從 prompt -> chat_model -> output_parser
chain = prompt | chat_model | output_parser# 5. 設置 LangSmith 相關的環境變量
# 這些變量用于將本地的運行軌跡上傳到 LangSmith 平臺
os.environ["LANGCHAIN_TRACING_V2"] = "true" # 開啟追蹤功能
os.environ["LANGCHAIN_ENDPOINT"] = "https://api.smith.langchain.com" # LangSmith API 地址
# 注意:此處的 API 密鑰是公共示例,生產環境請勿泄露
os.environ["LANGCHAIN_API_KEY"] = "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" # 6. 創建并/或選擇數據集
# Client 用于與 LangSmith 平臺交互
client = Client()
dataset_name = "example_code"
# 從 LangSmith 公共庫克隆一個數據集,作為評估的“黃金標準”
dataset = client.clone_public_dataset("https://smith.langchain.com/public/a63525f9-bdf2-4512-83e3-077dc9417f96/d", dataset_name=dataset_name)# 7. 定義一個自定義評估器
# 評估器是一個函數,用于根據LLM的輸出和數據集的黃金標準來打分
def is_concise_enough(root_run: Run, example: Example) -> dict:# 評估邏輯:檢查模型的輸出長度是否小于黃金標準答案長度的3倍score = len(root_run.outputs["output"]) < 3 * len(example.outputs["答案"])# 返回一個字典,其中 key 是評估指標名稱,score 是分數return {"key": "is_concise", "score": int(score)}# 8. 運行評估
# evaluate() 函數用于執行自動化評估
evaluate(# 第一個參數是“待評估的函數”,即我們的 LLM 鏈# lambda x: chain.invoke(x["問題"]) 將數據集中的“問題”字段傳遞給鏈lambda x: chain.invoke(x["問題"]),data=dataset_name, # 指定要使用的數據集evaluators=[is_concise_enough], # 傳入自定義評估器列表experiment_prefix="my first dataset experiment " # 為本次評估添加一個前綴
)
三、使用 LangSmith平臺自動化評估
準備工作
from langchain_community.vectorstores import FAISS # 導入FAISS向量存儲庫
from langchain_huggingface import HuggingFaceEmbeddings # 導入Hugging Face嵌入模型
from langchain_community.document_loaders import TextLoader # 導入文本加載器
from langchain.text_splitter import RecursiveCharacterTextSplitter # 導入遞歸字符文本分割器
from langchain_openai import ChatOpenAI # 導入ChatOpenAI模型# 使用 OpenAI API 的 ChatOpenAI 模型,但配置為連接本地服務
# 這是評估的核心:需要被測試的 LLM 模型
chat_model = ChatOpenAI(api_key='EMPTY', # 本地服務通常不需要密鑰base_url='http://127.0.0.1:10222/v1', # 指定本地模型的 API 地址model='Qwen2.5-7B-Instruct'
)數據加載與處理模塊
# 加載文本文件 "黑悟空.txt",編碼格式為 'utf-8'
loader = TextLoader("黑悟空.txt", encoding='utf-8')
docs = loader.load() # 將文件內容加載到變量 docs 中# 把文本分割成 200 字一組的切片,每組之間有 20 字重疊
text_splitter = RecursiveCharacterTextSplitter(chunk_size=200, chunk_overlap=20)
chunks = text_splitter.split_documents(docs) # 將文檔分割成多個小塊# 初始化嵌入模型,使用預訓練的語言模型 'bge-large-zh-v1___5'
# 這個模型用于將文本塊轉換為向量
embedding = HuggingFaceEmbeddings(model_name='models/AI-ModelScope/bge-large-zh-v1___5')# 構建 FAISS 向量存儲和對應的 retriever
vs = FAISS.from_documents(chunks, embedding) # 將文本塊轉換為向量并存儲在FAISS中# 創建一個檢索器,用于根據問題從向量存儲中查找最相關的文檔
retriever = vs.as_retriever()
RAG 鏈構建模塊
from langchain.prompts import (ChatPromptTemplate,SystemMessagePromptTemplate,HumanMessagePromptTemplate,
)# 創建一個系統消息,用于定義機器人的角色和輸入格式
# {context} 是一個占位符,用于填充檢索到的相關信息
system_message = SystemMessagePromptTemplate.from_template("根據以下已知信息回答用戶問題。\n 已知信息{context}"
)# 創建一個人類消息,用于接收用戶的輸入
# {question} 是一個占位符,用于填充用戶的原始問題
human_message = HumanMessagePromptTemplate.from_template("用戶問題:{question}"
)# 將這些模板結合成一個完整的聊天提示
chat_prompt = ChatPromptTemplate.from_messages([system_message,human_message,
])"""使用LCEL實現"""
# 格式化文檔,將多個文檔連接成一個大字符串
def format_docs(docs):return "\n\n".join(doc.page_content for doc in docs)# 創建字符串輸出解析器,用于解析LLM的輸出
from langchain_core.output_parsers import StrOutputParser
output_parser = StrOutputParser()from langchain_core.runnables import RunnablePassthrough
# 創建 rag_chain,這是整個 RAG 流程的核心管道
rag_chain = (# 這部分使用字典語法,并行執行兩個任務:# 1. 'context': 使用 retriever 檢索文檔并用 format_docs 格式化# 2. 'question': 使用 RunnablePassthrough 將原始問題原樣傳遞{"context": retriever | format_docs, "question": RunnablePassthrough()}| chat_prompt # 將格式化后的上下文和問題傳遞給提示模板| chat_model # 將提示詞傳遞給 LLM 模型| output_parser # 將 LLM 的輸出解析為字符串
)
# print(rag_chain.invoke("黑熊精自稱為?")) # 這是一個用于手動測試的示例
LangSmith 評估配置模塊
import os# 設置 LangSmith 相關的環境變量,用于連接平臺并上傳運行軌跡
os.environ["LANGCHAIN_TRACING_V2"] = "true"
os.environ["LANGCHAIN_ENDPOINT"] = "https://api.smith.langchain.com"
os.environ["LANGCHAIN_API_KEY"] = "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"
評估器定義與選擇模塊
from langsmith import evaluate, Client from langsmith.schemas import Example, Run# 1. 創建并/或選擇你的數據集 client = Client() dataset_name = "example_code" # 克隆一個 LangSmith 公共數據集,作為評估的黃金標準 dataset = client.clone_public_dataset("https://smith.langchain.com/public/a63525f9-bdf2-4512-83e3-077dc9417f96/d", dataset_name=dataset_name)1、方式1:原始的代碼:評估簡潔度。這是一個基于長度的簡單評估器。
def is_concise_enough(root_run: Run, example: Example) -> dict:# 比較 LLM 輸出的長度是否小于標準答案長度的3倍score = len(root_run.outputs["output"]) < 3 * len(example.outputs["答案"])return {"key": "is_concise", "score": int(score)}2、更大的模型將原始答案與生成答案進行準確度評估。這是一個基于LLM的定性評估。
from langsmith.evaluation import LangChainStringEvaluator eval_model = ChatOpenAI(model="/home/AI_big_model/models/Qwen/Qwen2.5-7B-Instruct",api_key="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",base_url="https://api.siliconflow.cn/v1", )3、通過余弦相似度進行評估。這是一個基于向量相似度的定量評估
from sentence_transformers import SentenceTransformer from sklearn.metrics.pairwise import cosine_similarity # 加載與用于生成向量數據庫的embedding模型相同的模型 model = SentenceTransformer("/home/AI_big_model/models/AI-ModelScope/bge-large-zh-v1___5") def cal_cosine_similarity(root_run: Run, example: Example) -> dict:model_output = root_run.outputs["output"]reference_answer = example.outputs["答案"]# 將模型輸出和標準答案編碼成向量embeddings = model.encode([model_output, reference_answer])# 計算兩個向量之間的余弦相似度similarity = cosine_similarity([embeddings[0]], [embeddings[1]])[0][0]# 定義一個分數:當相似度大于等于0.75時,得分為1,否則為0score = similarity >= 0.75return {"key": "cosine_similarity", "score": int(score)}
運行自動化評估
# 最終的評估執行函數
evaluate(# 傳入要評估的鏈,lambda 函數用于從數據集行中提取問題lambda x: rag_chain.invoke(x["問題"]),# chain.invoke# graph.invokedata=dataset_name, # 指定用于評估的數據集evaluators=[cal_cosine_similarity], # 傳入要使用的評估器(這里是方式3)experiment_prefix="my first dataset experiment " # 為實驗添加一個唯一前綴
)








![[NLP]多電源域設計的仿真驗證方法](http://pic.xiahunao.cn/[NLP]多電源域設計的仿真驗證方法)
的執行方式)
如何使用全文索引?)

)





