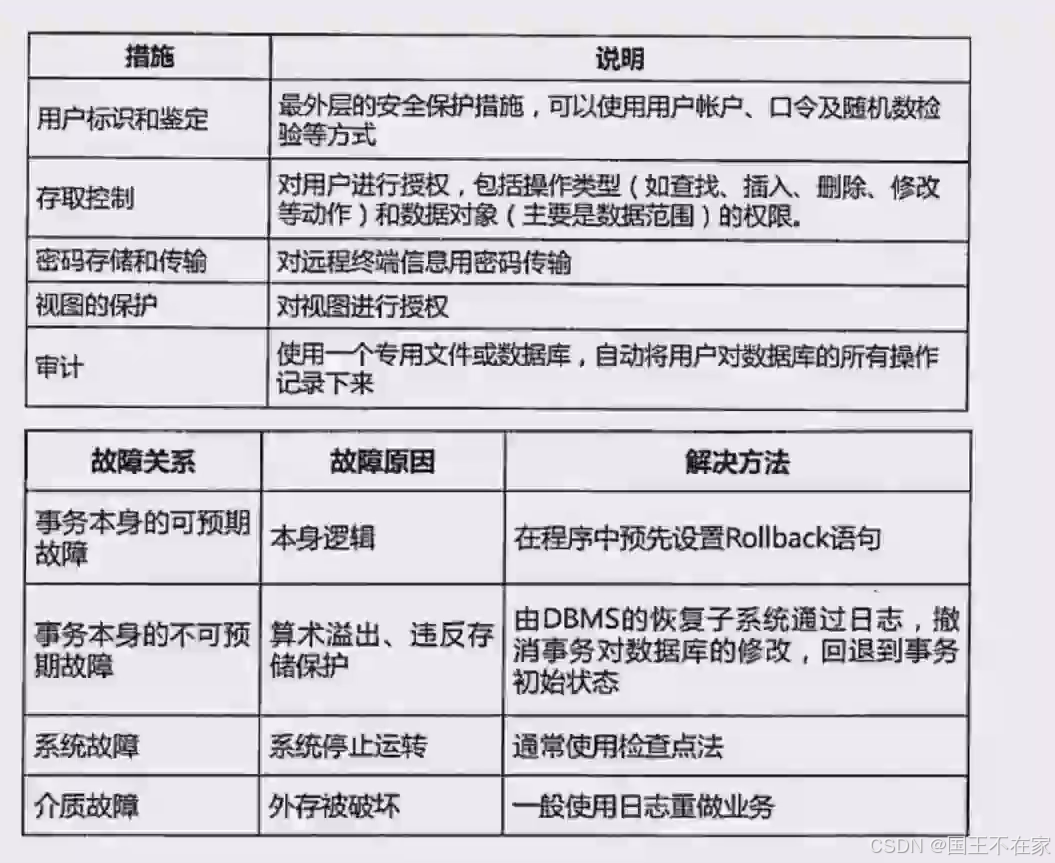
一、數據庫的安全
數據庫里面的安全措施:
- 用戶標識和鑒定:用戶的賬戶口令等
- 存取控制:對用戶操作進行控權,有對應權限碼才能操作。
- 密碼存儲和傳輸:加密存儲。
- 視圖的保護:視圖需要授權
- 審計:專門的文件或者數據庫記錄所有操作記錄。
數據庫里面的故障:看下圖
數據庫備份
數據庫備份的形式如下:
1、冷備份(靜態轉儲):轉儲期間不能對數據庫進行任何操作,優點是快速備份,容易存檔(直接物理復制)
2、熱備份(動態轉儲):轉儲期間允許對數據庫進行存取、修改操作。此時轉儲和用戶事務是并發執行。
優點是表空間或者數據庫文件級別備份,數據庫仍然可以使用,可達到秒級恢復;
缺點:不能出錯
3、完全備份:備份所有數據
4、差量備份:僅備份上一次完全備份之后變化的數據
5、增量備份:備份上一次備份之后變化的數據。(不管上一次是什么備份????????)
6、日志文件:事務每一次對數據庫的操作寫入日志文件,發生故障,利用日志文件撤銷事務對數據庫的改變,回退到四五的初始狀態。

數據故障恢復
數據庫故障恢復的技術:
- 事務故障的恢復:由系統自動完成,對用戶是透明的(不需要DBA的參與)。步驟就是把更新操作全部還原回去,直到事務的開始標記。
- 系統故障的恢復:系統重新啟動時自動完成,不需要用戶的干預。掃描日志文件,已提交的時候加入重做隊列,未完成的事務家務撤銷隊列。
- 介質故障與病毒破壞的恢復。硬盤壞了,裝入最新的數據庫副本,已提交的事務進入重做隊列,不用管未提交的事務
- 有檢查點的恢復技術:檢查點記錄的內容可包括建立檢查點時刻所有正在執行的事務清單,以及這些事務最近一個日志記錄的地址。類似ctrl+S。


數據庫性能優化
性能優化:
- 硬件升級:涉及處理器、內存、磁盤子系統和網絡
- 數據庫設計:從邏輯設計和物理設計入手
邏輯設計:常用的計算屬性(平均值、最大值)存儲到數據庫實體中。重新定義實體減少外部數據數據的開支
物理設計:給數據分配合適的存儲空間。頻繁使用的表分割開,這樣可以并行使用。文本和圖像存儲在單獨的物理設備上。 - 索引優化:索引類似目錄,索引能提高數據庫查詢速度,建立索引時應該選用不常更新經常查詢的屬性作為索引。索引過多會影響到增刪改。
- 查詢優化:sql語句優化,建立物化視圖(已經查好的數據),減少多表查詢;只檢索需要的屬性;用帶IN的條件子句等價替換OR;經常commit 釋放鎖。


二、分布式數據庫
????????局部數據庫位于不用的物理位置,使用一個全局DBMS(數據庫管理系統)將所有局部數據庫聯網管理,這就是分布式數據庫
分布式數據庫特點
- 數據獨立性
- 集中于自治共享結合的控制結構:
- 適當增加數據冗余度
- 全局的一致性、可串行和可恢復性

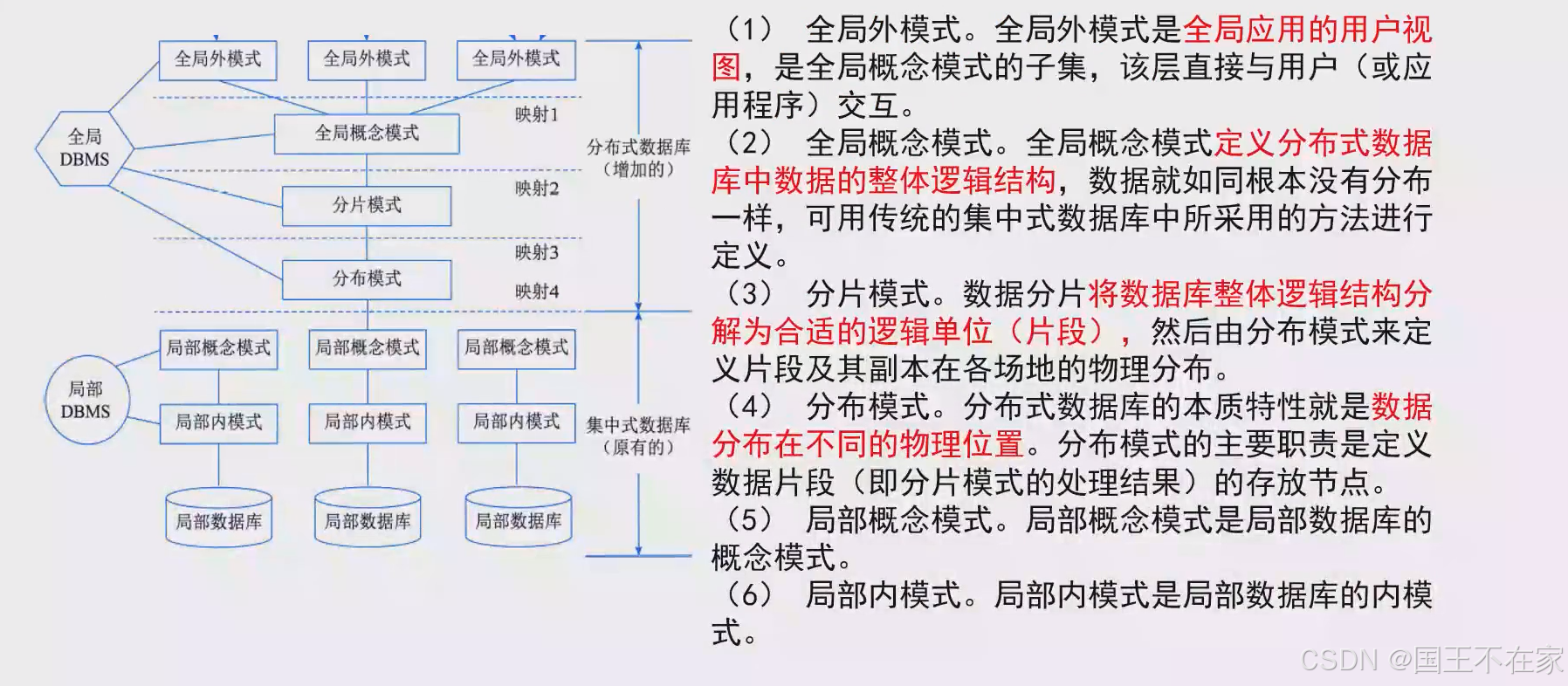
分布式數據庫各個模式
圖示:
分片方式

優點
- 解決企業部門分散而數據需要相互聯系的問題。
- 靈活增加新的相對自主的部門。
- 靈活組建全局應用下的多數據庫系統。
- 故障僅影響局部應用,可靠性更高。

數據倉庫
概要
數據倉庫是:面相主題的、集成的、非易失的、且隨時間變化的數據集合,用于管理決策(大數據決策)。
- 面相主題:用于特定品類大數據。
- 集成的:對分散數據庫數據抽取、清理、加工等操作。消除數據的不一致性,保證信息的主題性。
- 相對穩定:長期保留,包含大量的查詢操作,只需定義的加載、刷新。
- 反映歷史變化:包含歷史信息,是各個階段的信息,通過這些信息進行定量分析與預測。

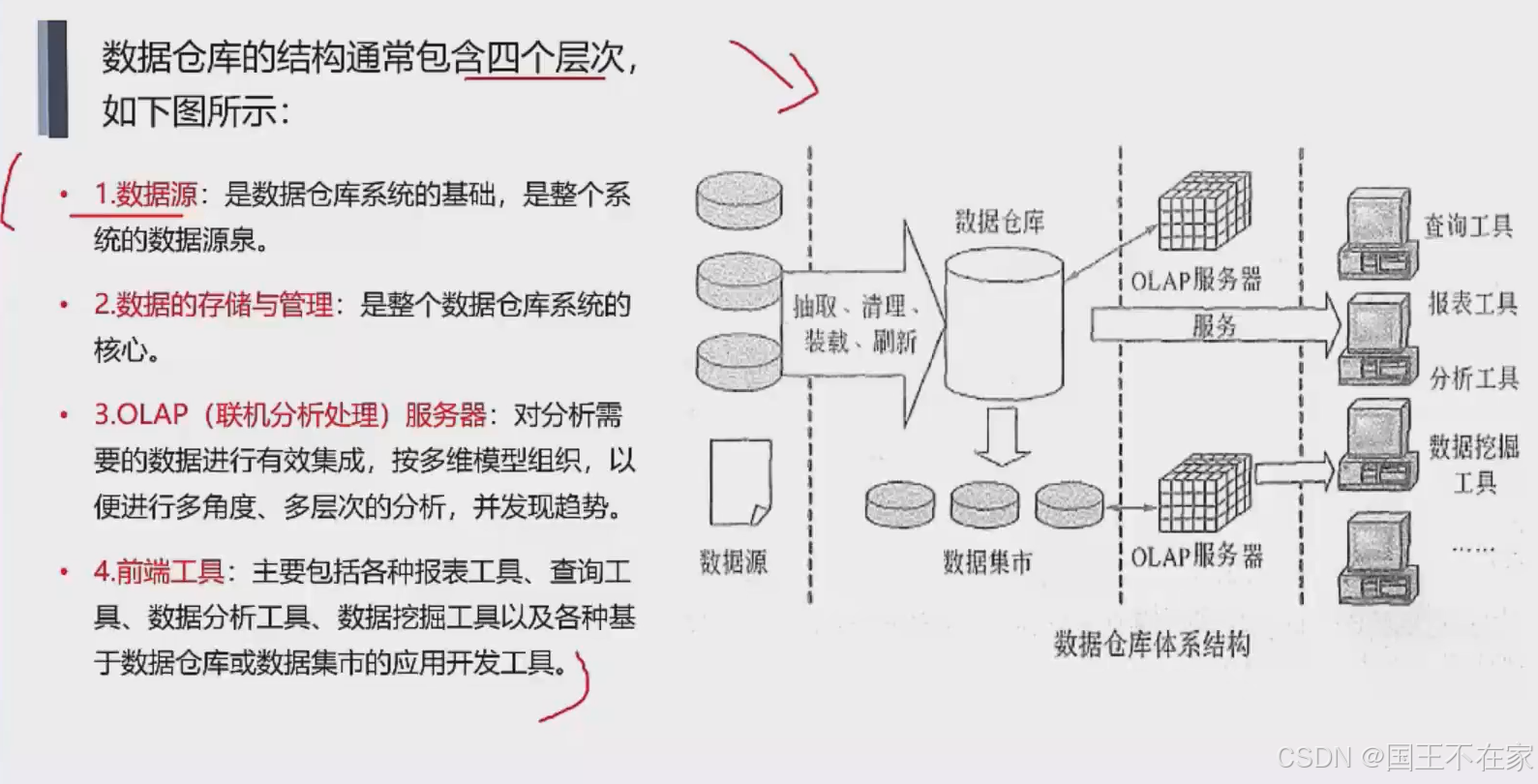
四個層次(重要)
層次
- 數據源:數據倉庫的基礎,整個系統的數據源泉。
- 數據的存儲和管理:數倉的核心。
- OLAP(聯機分析處理)服務器:
將原本不可能實時完成的深度分析變為可行——如同用天文望遠鏡替代肉眼觀星 ? - 前端工具:報表工具等,呈現olap的結果。
商業智能
BI系統的4個階段:數據預處理、建立數據倉庫、數據分析、數據展現。

數據倉庫分類
數據倉庫的分類:企業倉庫、數據集市、虛擬倉庫

數據倉庫設計方法
數據倉庫的設計方法:
- 自頂向下:用于企業級,建立數據倉庫后,各個部分再從數據倉庫中獲取部門所需的數據,形成數據集市。
- 自底向上:從企業中最關鍵的部門開始,最少投資完成當前需求,最先產生獨立數據集市。
- 混合.

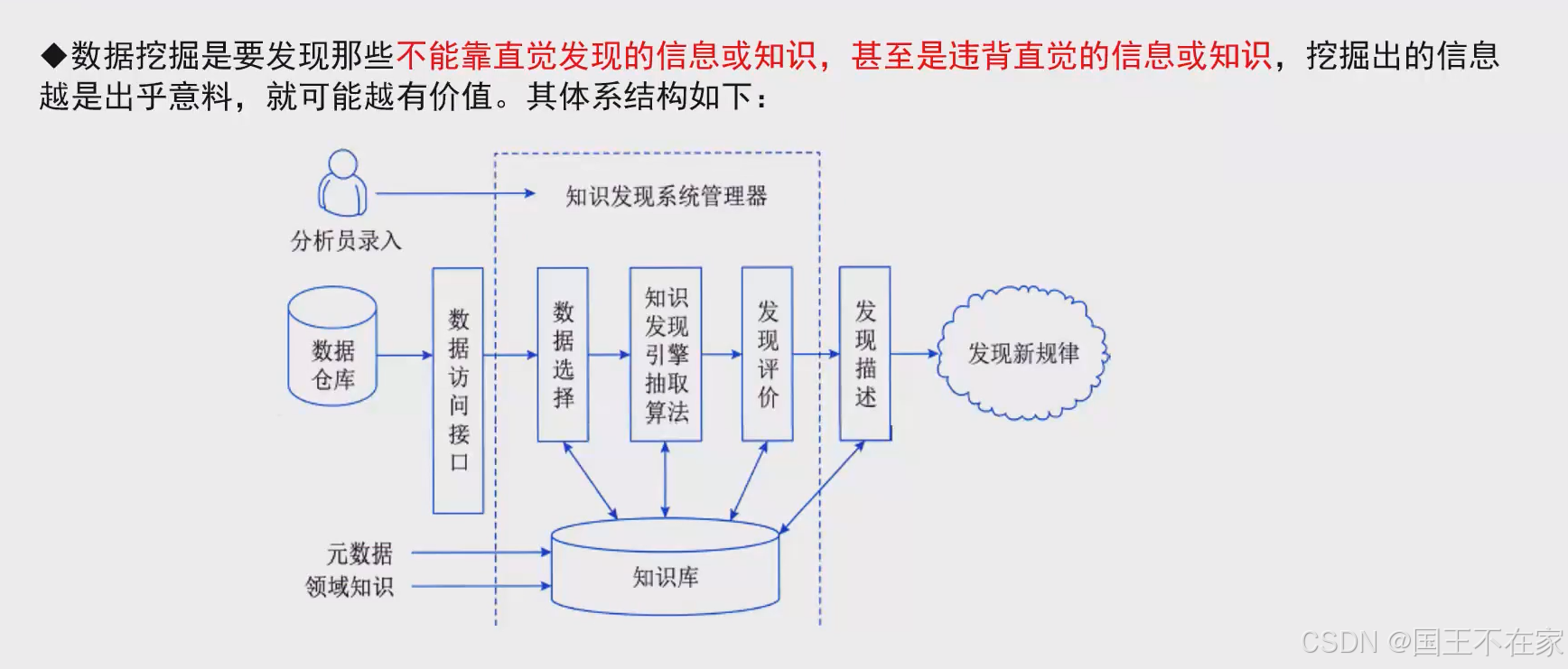
數據挖掘
結構
發現非直覺的信息。

流程

數據挖掘常用技術(記住)
數據挖掘的常用技術
- 決策樹:利用信息論中互信息(信息增益)尋找數據庫中具有最大信息量的屬性,建立決策樹的節點,再根據屬性的不同取值建立樹的分支。
- 分類:按照翻譯劃分成組
- 粗糙集:基于分類,一種類別對應于一個概念,知識由概念組成。粗糙集通過近似概念表示不精確的概念。
- 神經網絡:神經網絡通過學習待分析數據中的模式來構建模型。
- 關聯規則:搜索業務系統中所有細節和事務,找出重復出現的模式。
- 概念樹方法:按歸類的方式進行抽象,放大建立起來的層次結構稱為概念樹。
- 遺傳算法:模擬生物進化過程
- 依賴性分析:在數據倉庫的條目和對象之間抽取依賴性。
- 公式發現:進行數學運算
- 統計分析方法:找出數據庫屬性的函數關系和相關關系
- 模糊論:模糊性是客觀存在的,系統越復雜,精確度越低,越模糊
- 可視化分析:通過圖形化分析數據。


數據挖掘分析方法(了解)
- 關聯分析
- 序列分析
- 分類分析:首先為每個記錄設置一個標記,然后對這個分類進行分析,有監督。
- 聚類分析:對無標記的記錄進行相似性聚合,劃分、分析,屬于無監督。
- 預測分析
- 時間序列分析


![[NLP]多電源域設計的仿真驗證方法](http://pic.xiahunao.cn/[NLP]多電源域設計的仿真驗證方法)
的執行方式)
如何使用全文索引?)

)













