25年3月來自三星中國研發中心、中科院自動化所和北京智源的論文“TLA: Tactile-Language-Action Model for Contact-Rich Manipulation”。
視覺-語言模型已取得顯著進展。然而,在語言條件下進行機器人操作以應對接觸-密集型任務方面,仍未得到充分探索,尤其是在觸覺感知方面。觸覺-語言-動作 (TLA) 模型,通過跨模態語言基礎有效地處理連續觸覺反饋,從而能夠在接觸-密集型場景中實現穩健的策略生成。此外,構建一個包含 24000 對觸覺動作指令數據的綜合數據集,該數據集針對指尖銷孔裝配進行定制,為 TLA 的訓練和評估提供必要的資源。結果表明,TLA 在有效動作生成和動作準確性方面顯著優于傳統的模仿學習方法(例如擴散策略),同時通過在以前未見過的裝配間隙和銷形上實現超過 85% 的成功率,表現出強大的泛化能力。
觸覺感知對于接觸-密集的機器人操作任務至關重要 [1]。例如,在精細裝配任務中,機器人需要精確感知物體表面的細微變化 [2], [3]。觸覺感知使機器人能夠對其接觸姿態進行細微調整,避免損壞或錯位 [4]。這種精確的接觸感知在許多復雜任務中都必不可少 [5]。先前的研究表明,整合觸覺反饋可以顯著增強操作技能的靈活性和魯棒性 [6], [7],尤其是在處理復雜或不可預見的接觸環境時,從而提高機器人的適應性。然而,當前的方法很大程度上依賴于在特定數據集上訓練的專用模型 [8], [9],這些模型在泛化方面受到限制,無法與通用模型的能力相媲美 [10], [11]。
近年來,大語言模型在類人推理方面取得了重大突破 [12],其中視覺-語言-動作 (VLA) 模型的開發進展迅速 [13],[14]。通過跨模態語言基礎,VLA 模型的表現優于傳統的模仿學習方法,尤其是在跨不同機器人平臺和任務設置的泛化方面。然而,目前大多數 VLA 模型主要側重于視覺任務 [15],缺乏關鍵的觸覺模態,這限制了它們在接觸-豐富操作任務中的適用性 [16]。盡管最近有研究致力于將語言和觸覺結合起來用于感知任務 [17],[18],[19],但這些研究依賴于排除機器人動作或將觸覺作為補充模態的數據集 [20],這限制了它們在策略訓練中的適用性,僅限于僅依賴感知或拾取放置的抓取任務。基于語言的觸覺技能學習,面臨的挑戰包括:1)缺乏針對接觸-密集型操作任務的專門觸覺動作指令數據集;2)缺乏合適的觸覺-語言-動作模型。
為了應對上述挑戰,本文構建一個針對指尖觸覺銷孔裝配場景的觸覺動作指令數據集 [21]。其提出一種用于通才機器人策略學習的微調方法,稱為觸覺-語言-動作 (TLA) 模型,該方法表明跨模態微調能夠通過語言落地獲取泛化的觸覺技能。所提出的 TLA 數據集和模型概覽如圖所示:
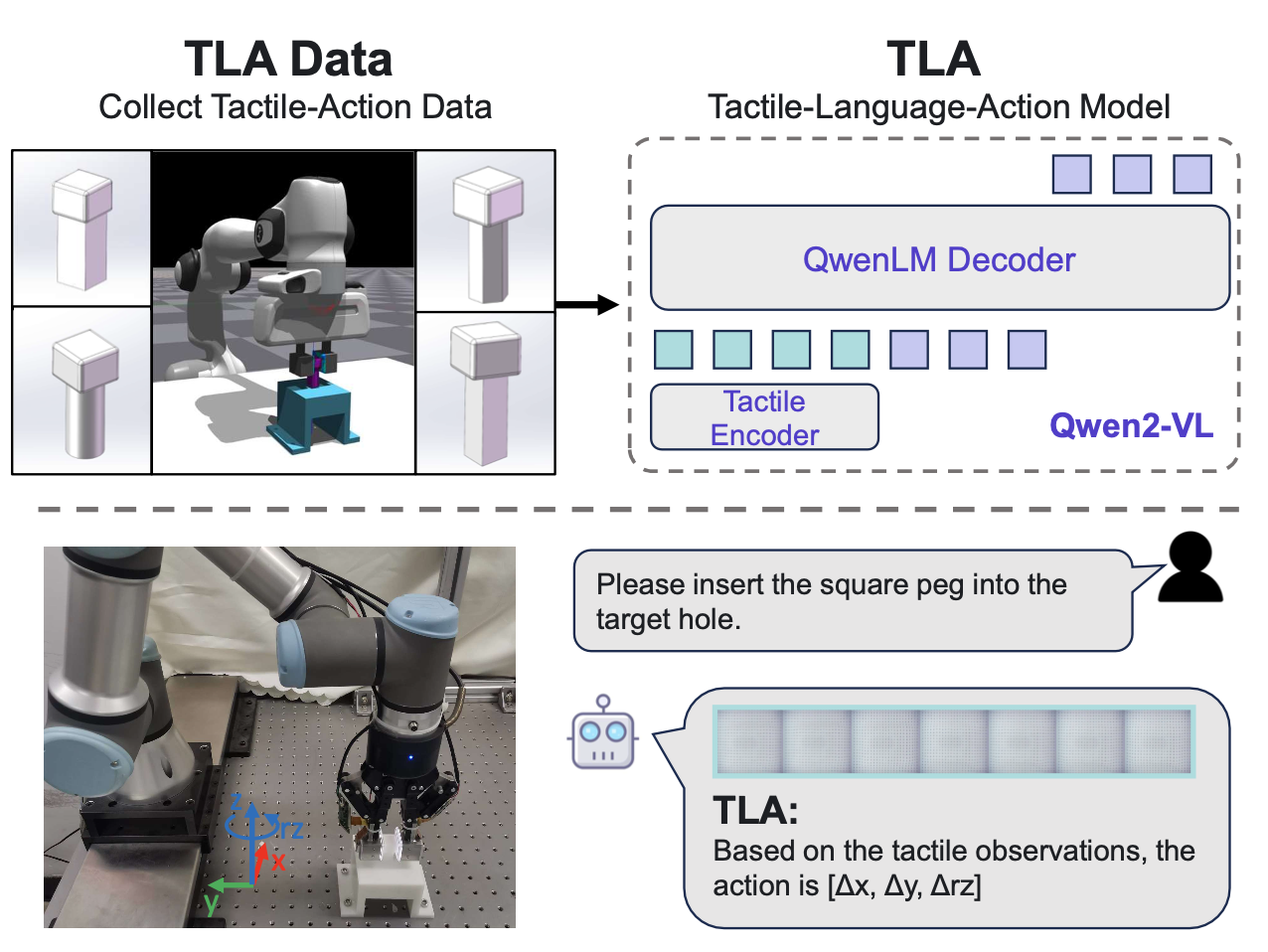
建立一個在釘孔裝配過程中收集的觸覺動作指令數據集。在此任務中,配備 GelStereo 2.0 視覺觸覺傳感器 [27] 的機器人,嘗試基于指尖觸覺感知和語言指令將釘子插入相應的孔中。為了高效地收集數據,在 NVIDIA Isaac Gym 中搭建此任務的模擬環境。基于有限元法 (FEM),使用 Flex 物理引擎模擬交互過程中視覺觸覺傳感器的變形。采用 [28] 中提出的觸覺銘刻渲染方法來模擬觸覺圖像。為了縮小模擬與真實的差距,使用從真實傳感器獲取的觸覺圖像進行紋理映射,而不是手動設計的圖案。通過這種方式,可以在插入嘗試過程中獲得高保真度的觸覺圖像。
釘孔任務的流程如下所述。夾持器首先抓住一個具有形狀描述的釘子,并移動到相應孔的頂部,在 x 軸、y 軸和繞 z 軸的旋轉上具有隨機的 3-DOF 錯位(用 rz 表示)。然后,夾持器向下移動嘗試插入。如果在向下移動過程中釘子和孔發生碰撞,則認為此次嘗試失敗,夾持器抬起等待下一次嘗試。碰撞期間的觸覺圖像序列被記錄下來,以推斷調整釘子姿態的機器人動作 (?x, ?y, ?rz)。如果在夾持器向下移動到預定位置時未發生碰撞,則任務被視為成功。最大嘗試次數為 15 次。否則,任務失敗。
在模擬中,對這個釘入孔任務采用隨機插入策略。對于每次嘗試,都會保存觸覺圖像序列和釘孔姿態誤差。然后,根據釘孔姿勢誤差 (e_x, e_y, e_rz) 創建動作標簽 (?x?, ?y?, ?r?z)。
為了方便模型訓練,收集的交互數據被轉換為指令格式。<|im start|> 和 <|im end|> token 標記每輪對話的開始和結束。觸覺圖像則以 <|vision start|> 和 <|vision end|> 輸入,分別表示視覺輸入的開始和結束。文本指令定義任務,闡明掛鉤類型和姿勢要求。機器人在數據收集過程中的動作被保存為真值。如圖展示 TLA 數據的示例:

觸覺-語言-動作模型,如圖所示。TLA 基于 Qwen2-VL [29] 構建,該模型包含用于編碼視覺輸入的視覺transformer (ViT) [30] 和用于理解多模態信息和生成文本的 Qwen2 語言模型 [31]。
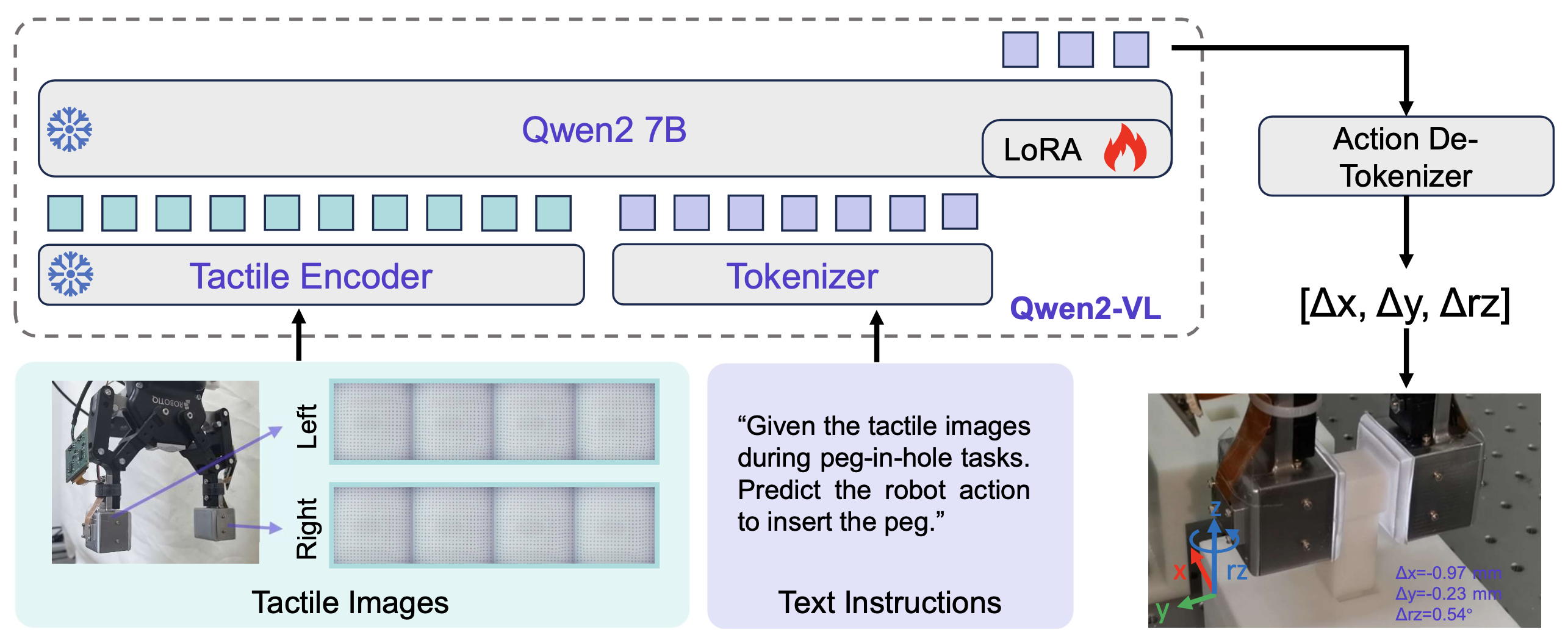
觸覺編碼器
如上文所述,視覺觸覺傳感器的觸覺信息以圖像的形式呈現。在機器人操作過程中,觸覺圖像會根據機器人夾持器的接觸狀態不斷變化。因此,觸覺編碼器需要處理兩個時間上對齊的圖像序列。
觸覺編碼器的挑戰在于從輸入的觸覺圖像中提取時間變化。為了解決這個問題,將兩個觸覺圖像序列合成為一個圖像,將時間信息轉換為空間信息,以便于基于視覺觸覺的特征提取。具體而言,輸入圖像集表示為 I = {I_lt, I_rt; t = 0, 1, 2, 3},其中 I_lt 和 I_r^t 分別表示時間戳 t 時左右指尖的觸覺圖像。這八幅圖像排列成 3×3 的網格,最后一個網格用白色圖像填充,并調整為 616×616 的尺寸作為模型輸入。
用 Qwen2-VL 的 ViT 作為觸覺編碼器,如上圖所示。連接后的觸覺圖像經觸覺編碼器處理后,獲得觸覺特征。此外,還使用多層感知器 (MLP) 層將 2×??2 范圍內的觸覺特征進一步壓縮為單個 token。因此,對于輸入的觸覺圖像 I,經過塊大小為 14 的 ViT 后,可以獲得 1936 個觸覺 tokens。
使用語言模型進行動作預測
使用 Qwen2 語言模型預測機器人動作,如上圖所示。語言模型的輸入是觸覺 token 和語言 token,它們分別由觸覺編碼器和 token 化器對原始多模態輸入進行編碼獲得。Qwen2 7B 是 TLA 的骨干模型,并在 TLA 數據集上進行微調。
使用離散標記器對連續數字進行編碼會影響模型在數字敏感任務中的表現 [32]。先前的研究 [13] 只是將最少使用的標記覆蓋為“特殊標記”,并為每個標記分配 bin ID。與之前的方法不同,我們保留了數字編碼方案,以確保在機器人操作任務中有效地利用訓練前獲得的數字知識。
然而,Qwen2 的 token 化器對數字進行單獨編碼。由于機器人動作數據中存在大量小數,這些冗余信息增加模型訓練的難度。為此,通過按比例縮放所有動作并四舍五入為整數來簡化真實動作。具體而言,處理過程計算為 A_gt = A_raw·s,其中 A_gt、A_raw、s 分別為真實動作、原始動作和縮放因子。
訓練與推理
先前的研究表明,在訓練期間凍結視覺編碼器可以使 VLM 獲得更好的性能 [29] [33]。因此,在微調期間凍結觸覺編碼器的參數。此外,使用低秩自適應 (LoRA) [34] 來有效地微調 Qwen2 7B 語言模型。真實動作被用作標簽來計算下一個分詞預測損失。
在推理過程中,TLA 根據輸入的觸覺觀察和指令文本,依次預測機器人動作的概率分布。生成過程通過波束搜索進行,直至生成最終的 token。最后,Action-De-Tokenizer 將所有生成的概率根據詞匯表映射到自然語言文本,并將其轉換為機器人可執行的浮點數。
基線方法和TLA比較試驗:
? 行為克隆 (BC) [35]:采用 ResNet-50 [36] 作為策略網絡。該網絡以觸覺圖像為輸入,輸出機器人動作,并采用監督學習的方式進行訓練。
? 擴散策略 (DP) [37]:[37] 中的擴散策略利用條件去噪擴散過程來學習釘入孔裝配策略。
? 單釘 TLA (SP-TLA):在方形釘插入數據集上訓練的 TLA 模型。
? 多釘 TLA (MP-TLA):在方形和三角形釘插入數據集上訓練的 TLA 模型。
實驗設置。
單釘。從 TLA 數據集中選取 8k 的方形樁插入數據,用于比較 TLA 與基線方法的性能。具體而言,訓練集和測試集分別拆分為 6k 和 2k。每個訓練樣本包含 8 張觸覺圖像,分別對應左右指尖,時長為 4。標簽為機器人動作 (?x, ?y, ?rz),分別表示水平方向的移動和繞 z 軸的旋轉。TLA 模型在 8 塊 Nvidia A6000 GPU 上訓練 20 個 epoch。
多釘。選取 16,000 個方形和三角形樁樣本進行訓練,并進行等分。此外,收集 8,000 個樣本進行評估:方形/三角形樁各 4,000 個,圓形/六邊形樁各 4,000 個。輸入、輸出和指標與單樁任務一致。訓練使用 8 塊 Nvidia A6000 GPU,進行 10 個 epoch。
測試不同模型在兩類銷孔裝配任務中的操作性能。首先,評估不同裝配間隙下的模型性能,包括裝配間隙分別為2.0 mm、1.6 mm和1.0 mm的方形銷孔裝配任務。然后,報告不同模型在方形、三角形、圓形和六邊形銷插入任務中的表現,所有裝配間隙均設置為 2.0 mm。每個任務重復 50 次以計算最終結果。
在每個回合開始時,機器人已經用夾持器抓住釘子,并將末端執行器隨機設置在靠近目標孔的起始位置。然后,機器人嘗試第一次插入并獲取觸覺圖像。隨后,TLA 或其他模型根據觸覺觀察預測機器人的動作,并控制機器人再次插入。機器人持續嘗試,直至插入成功或達到最大嘗試次數 15。成功率和成功回合的平均步數用于評估所有模型的性能。


![微信小程序 - [渲染層錯誤] Uncaught TypeError: Cannot read property ‘D‘ of undefined](http://pic.xiahunao.cn/微信小程序 - [渲染層錯誤] Uncaught TypeError: Cannot read property ‘D‘ of undefined)
)
)


:vivo X200 Ultra影像技術溝通會總結)





)

底層的實現:)



