Mysql高級
DQL查詢語句
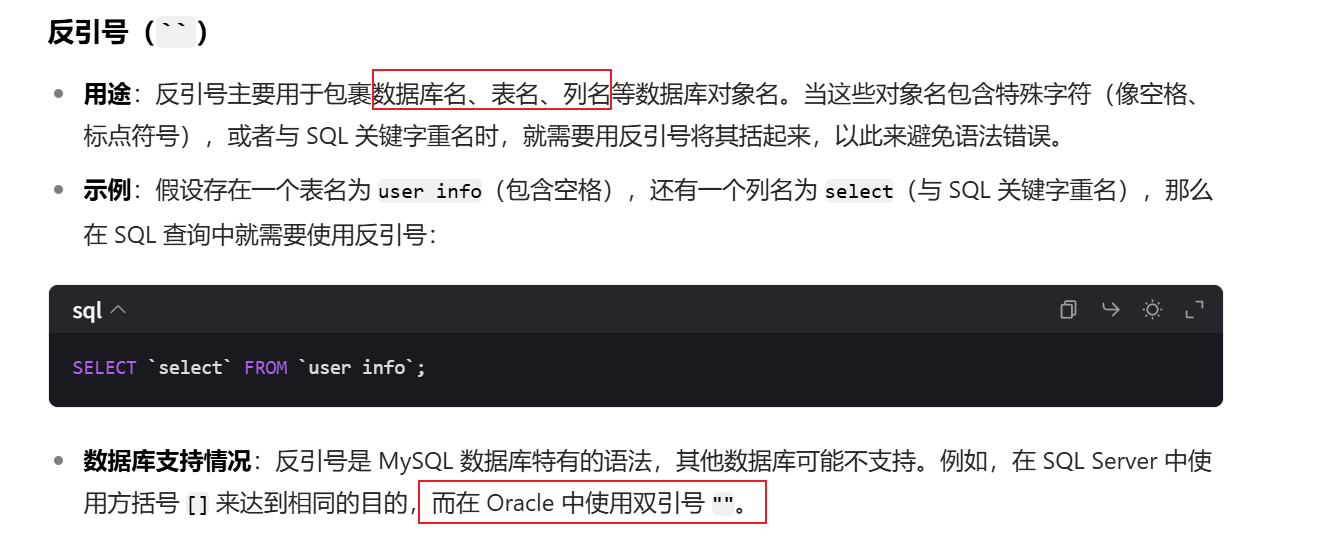
反引號
模糊查詢避免%出現在開頭,會造成索引失效
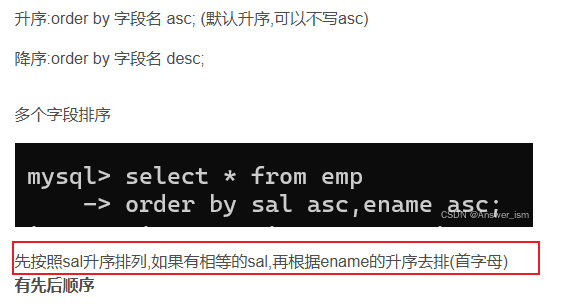
order by排序先后
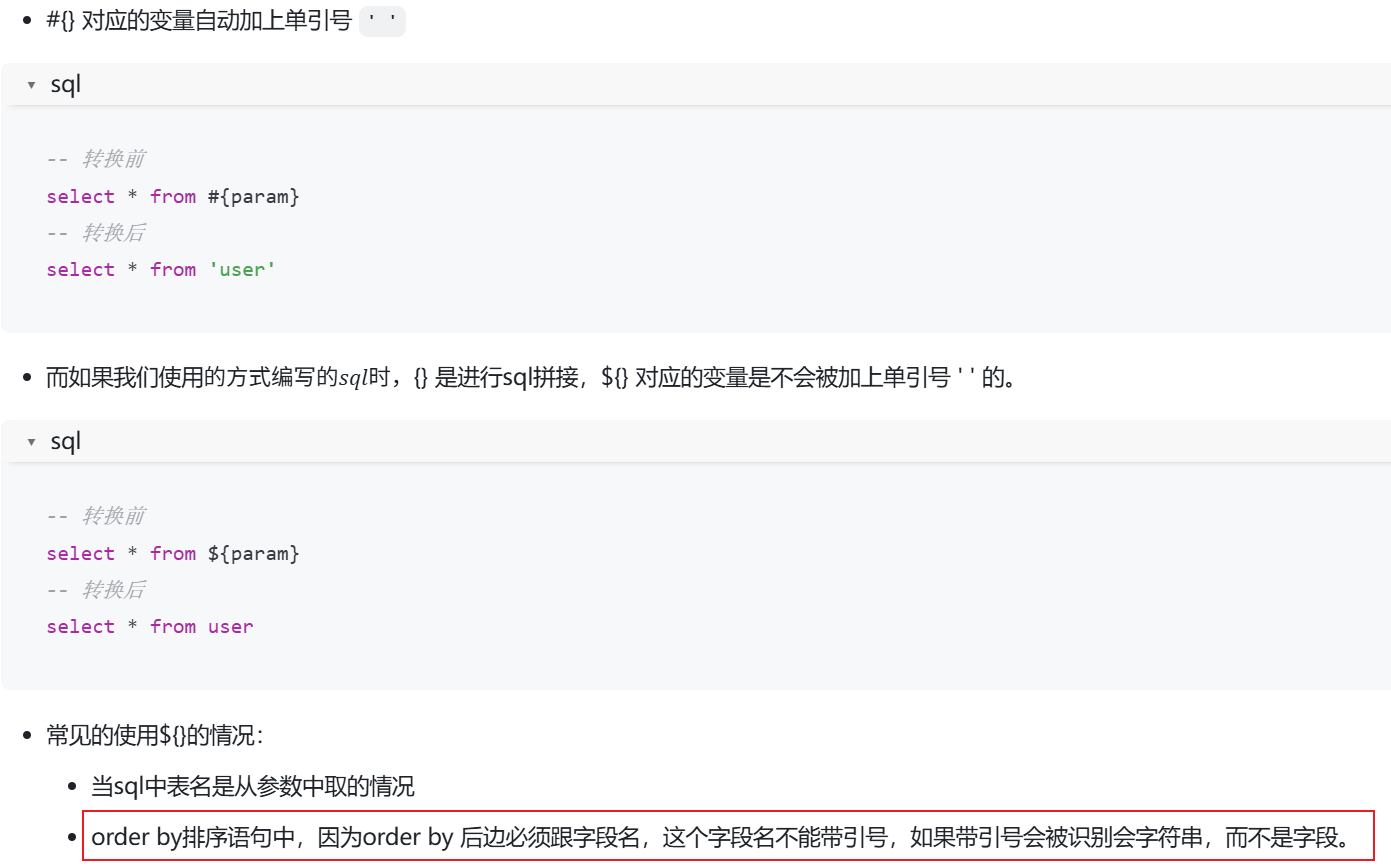
表名列名都需要用${},他們不能帶’’
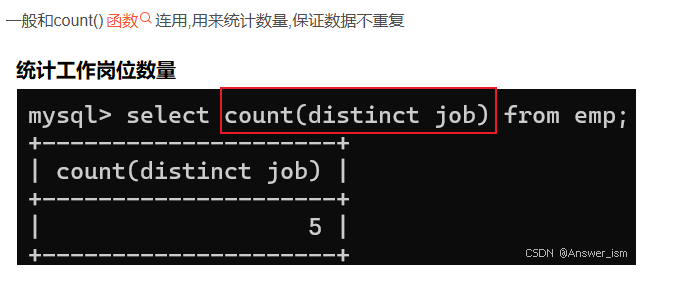
去重+統計數量

null的運算
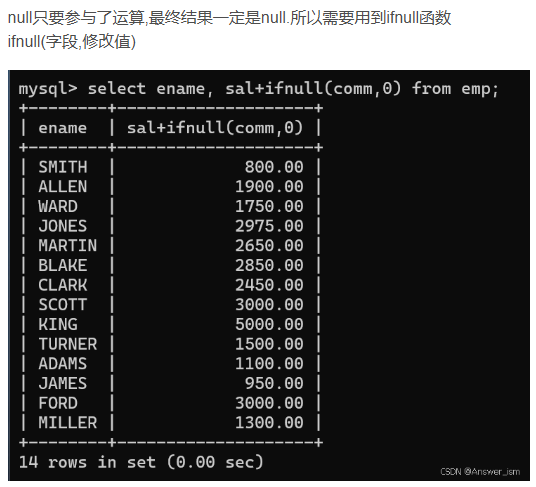
分組函數會自動忽略null,不用對null進行處理
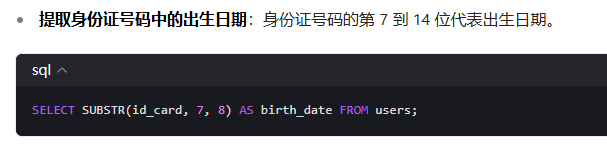
截取子串substr(字段,下標,截取長度)
下標從1開始
trim去重字段空格

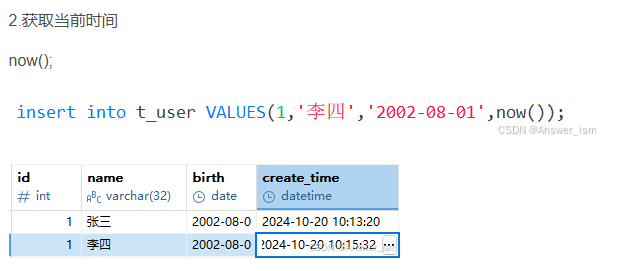
now()
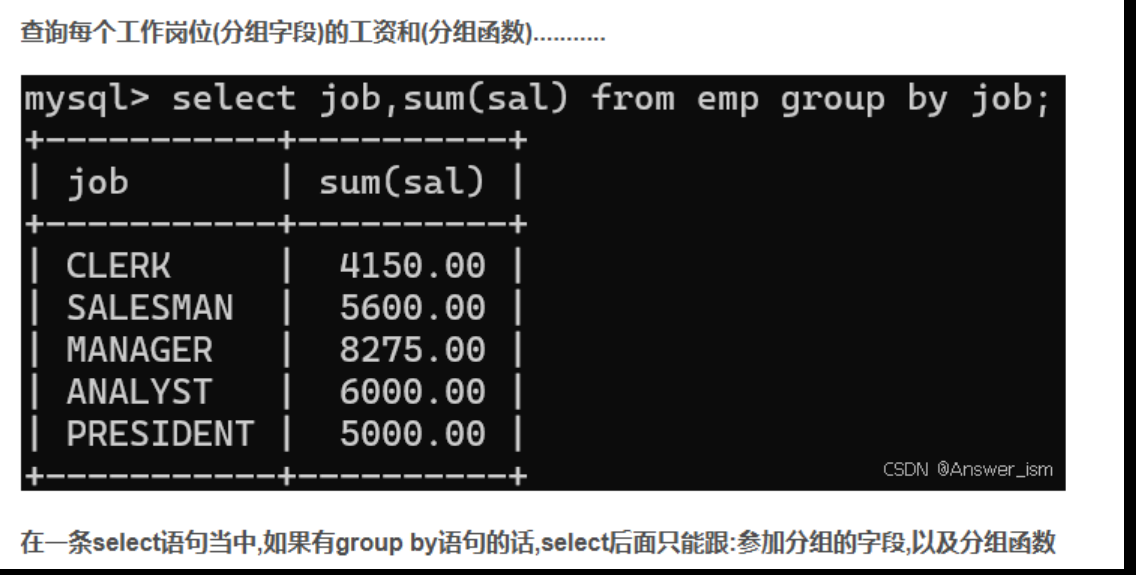
分組函數和分組查詢group by


可以聯合分組
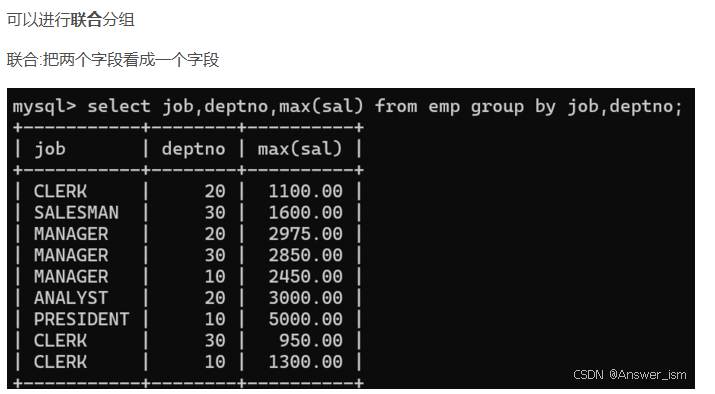
having和where區別和使用
having可以用分組函數,但是必須先group by 分組后再用having過濾
而where不可以用分組函數,必須先過濾后用group by 分組

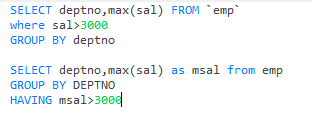
where效率比having高
因為執行順序,先where后group by 后 having


連接查詢
笛卡爾積,直接from 兩張表,沒有join和on條件(外鍵),直接n*n行查詢,效率慢

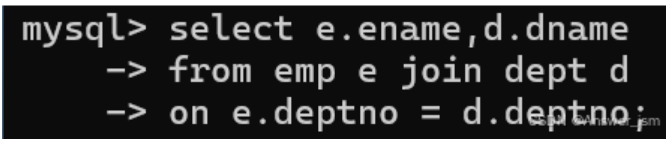
執行順序先from后select
on條件相等,一般為外鍵

非等值查詢
自連接
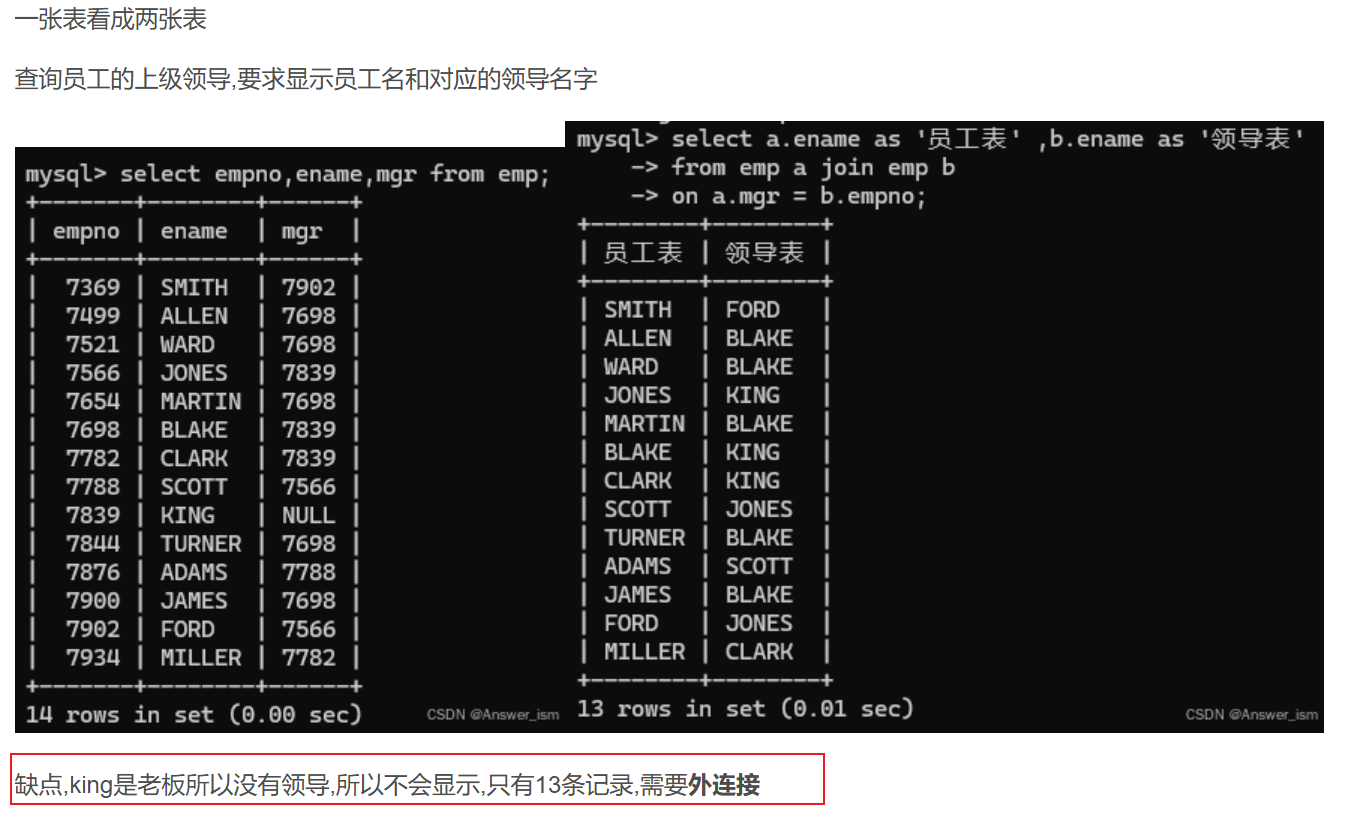
外連接
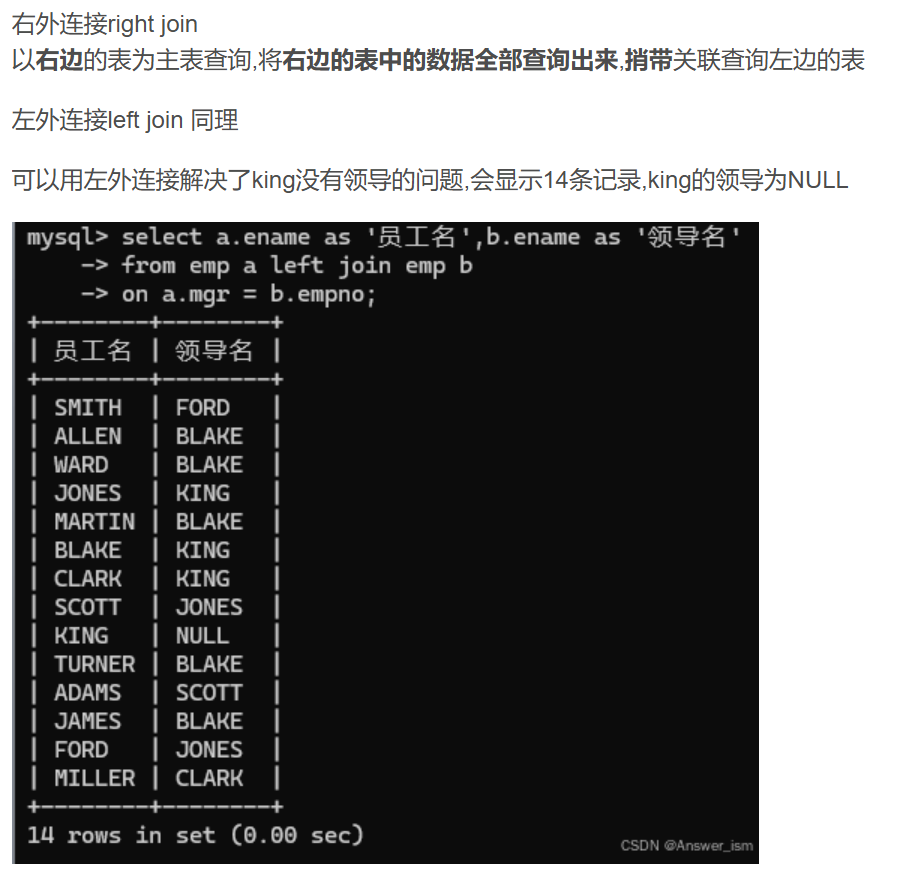
主次關系,需要把員工名全查出來,捎帶查領導
多表連接

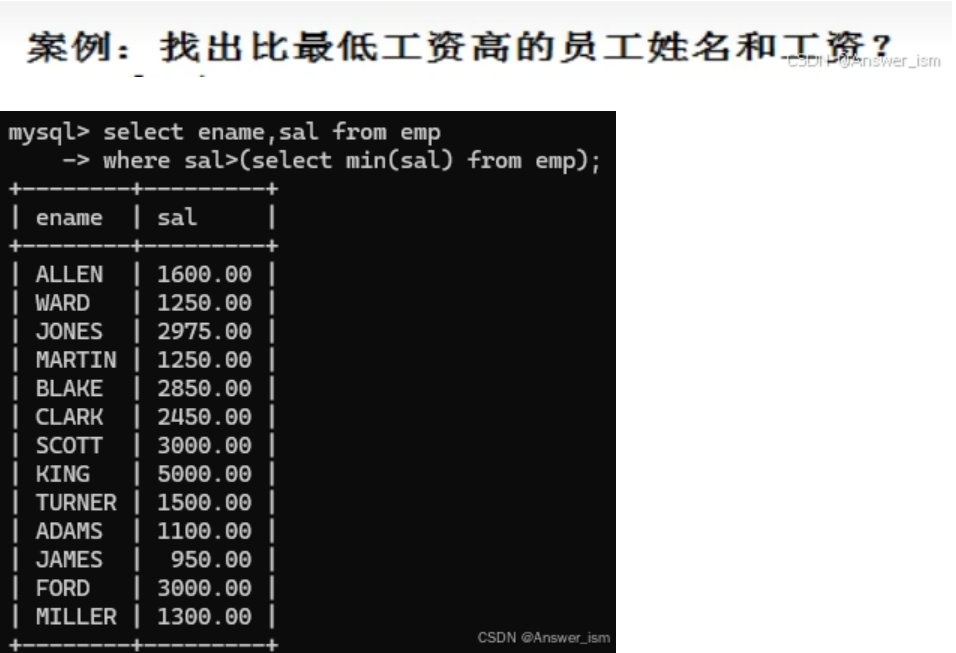
子查詢(select嵌套)

where中子查詢
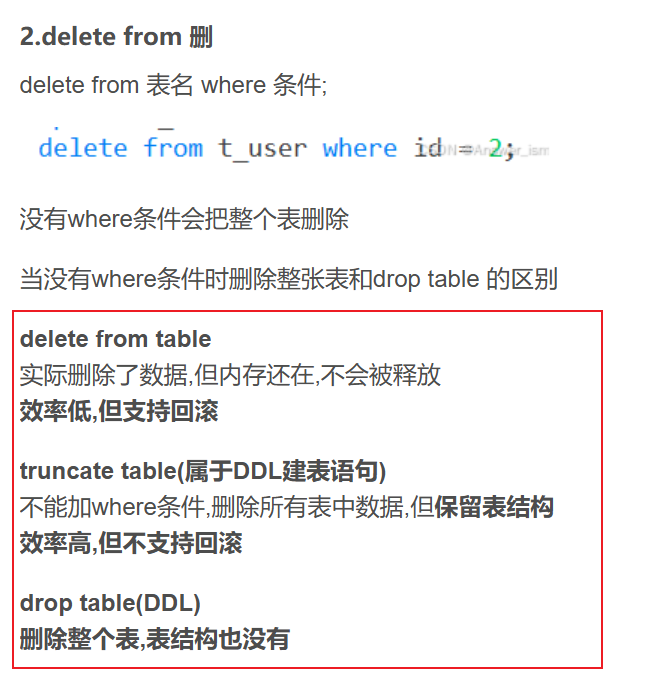
DML增刪改語句


事務
事務的本質就是多條DML語句同時成功或者同時失敗

每一句DML語句都會儲存在日志文件中
提交事務commit或者回滾事務rollback,都會清空日志文件
commit提交到表中(硬盤中),rollback回滾到上次提交,都是結束事務的標志
事務的特性

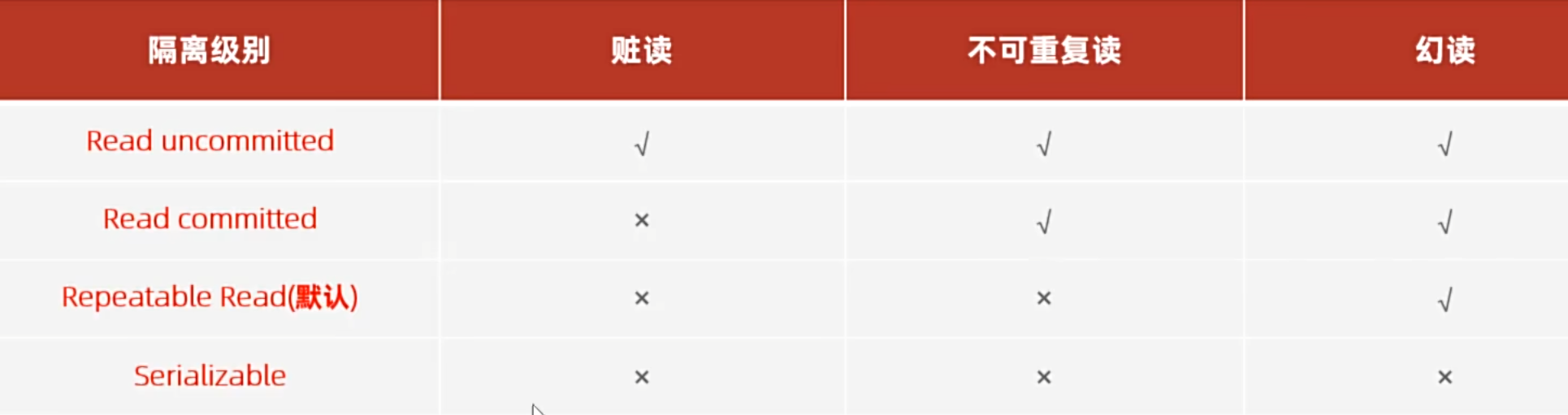
事務的隔離級別

重復:同一事務中,對相同數據進行多次讀取
不可重復讀

也就是事務先讀取a,被別的事務修改了,再讀取同一條記錄,得到的結果不一樣,所以不可重復讀

每次讀到的數據都一樣,可重復讀會給讀取的數據加鎖,其他事務無法修改這個數據
幻讀就是第一次讀取a,發現不存在,于是insert 這個a,發現insert失敗,這時候就是另一個事務已經insert了這個a
但是第二次讀取a,發現還是不存在,依舊insert失敗,好像出現了幻覺

單線程不能并發
三范式

第二范式
修改前(聯合主鍵,部分依賴)

修改后,三張表,關系表兩個外鍵
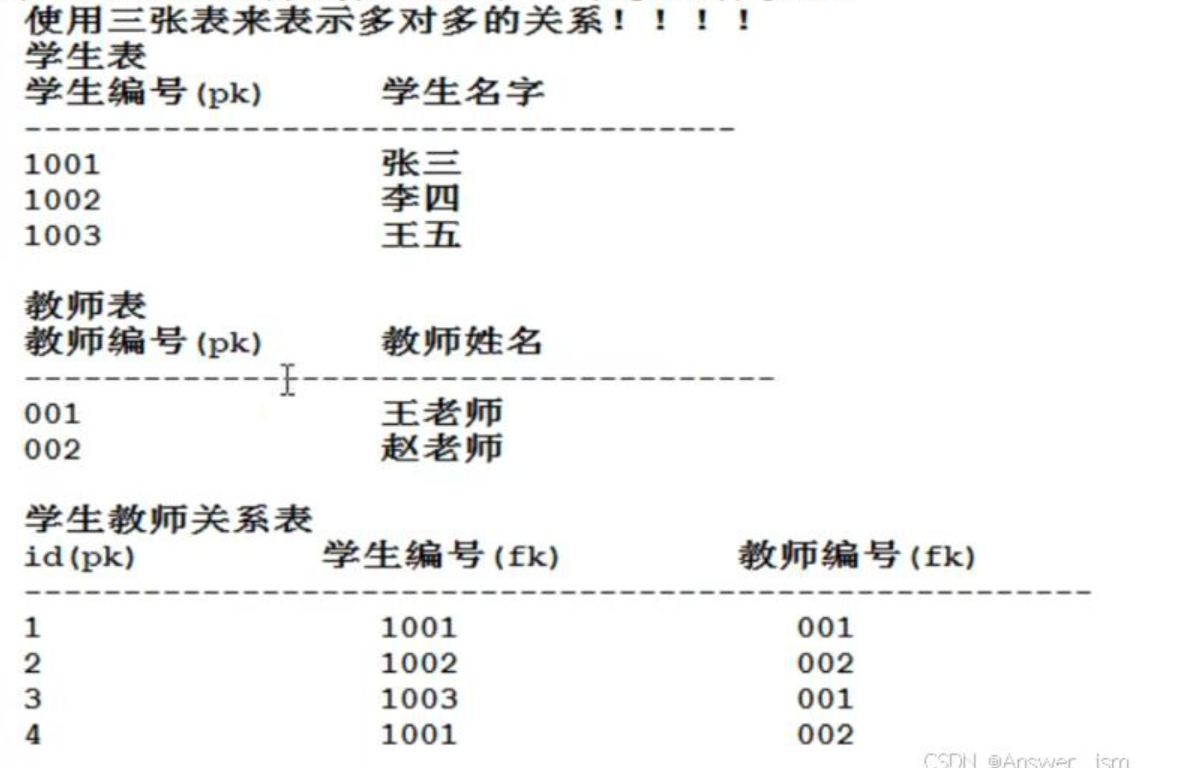
不能產生復合主鍵,部分依賴就是某個字段只依賴其中一個主鍵,和另一個主鍵沒關系
多對多關系,需要設計三張表A表,B表,關系表
多對多,三張表,關系表兩外鍵
第三范式
修改前(班級依賴01,01依賴1001)產生傳遞依賴
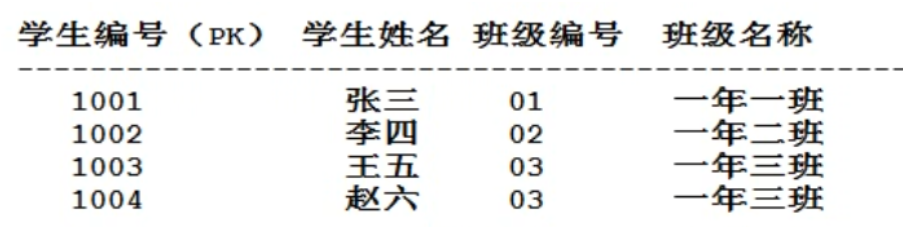
修改后(多的表加外鍵)
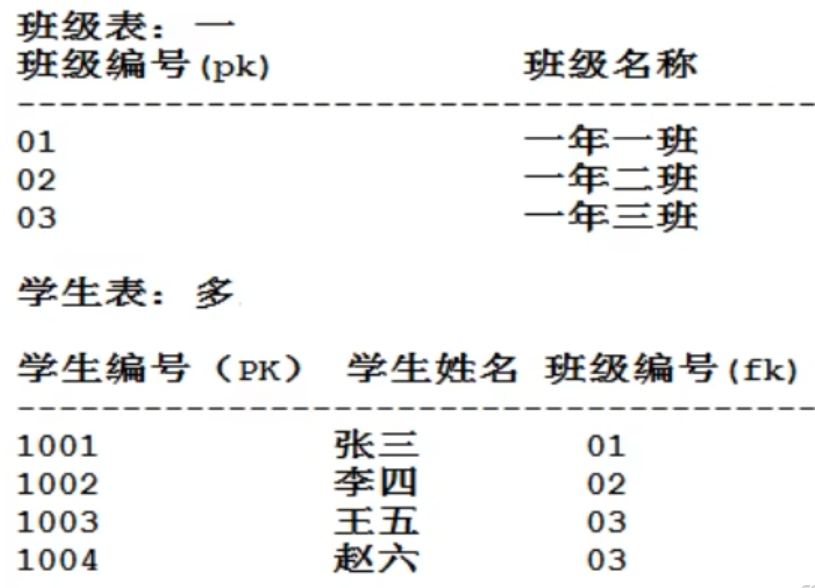
一對多,兩張表,多的表加外鍵
大部分情況下,公司都不會遵循設計三范式
為了滿足客戶需求,速度要快的情況下,哥們不需要節省空間,有的是空間,不怕數據冗余
可以寫在一張表內,就不會出現笛卡爾積現象
因為表與表連接次數越多,效率越慢
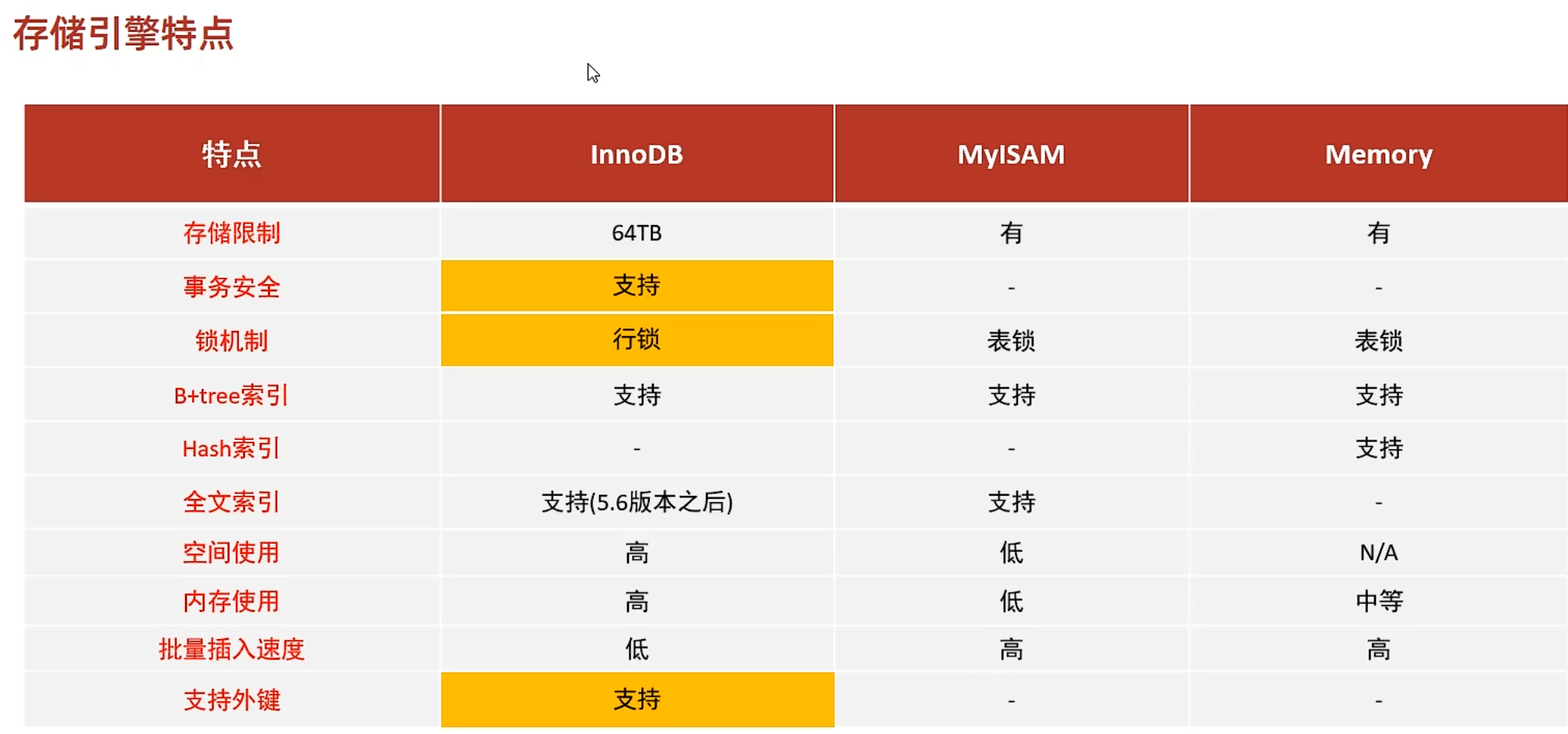
存儲引擎
是以表為單位的,同一個數據庫不同表可以有多種不同的存儲引擎
mysql體系結構
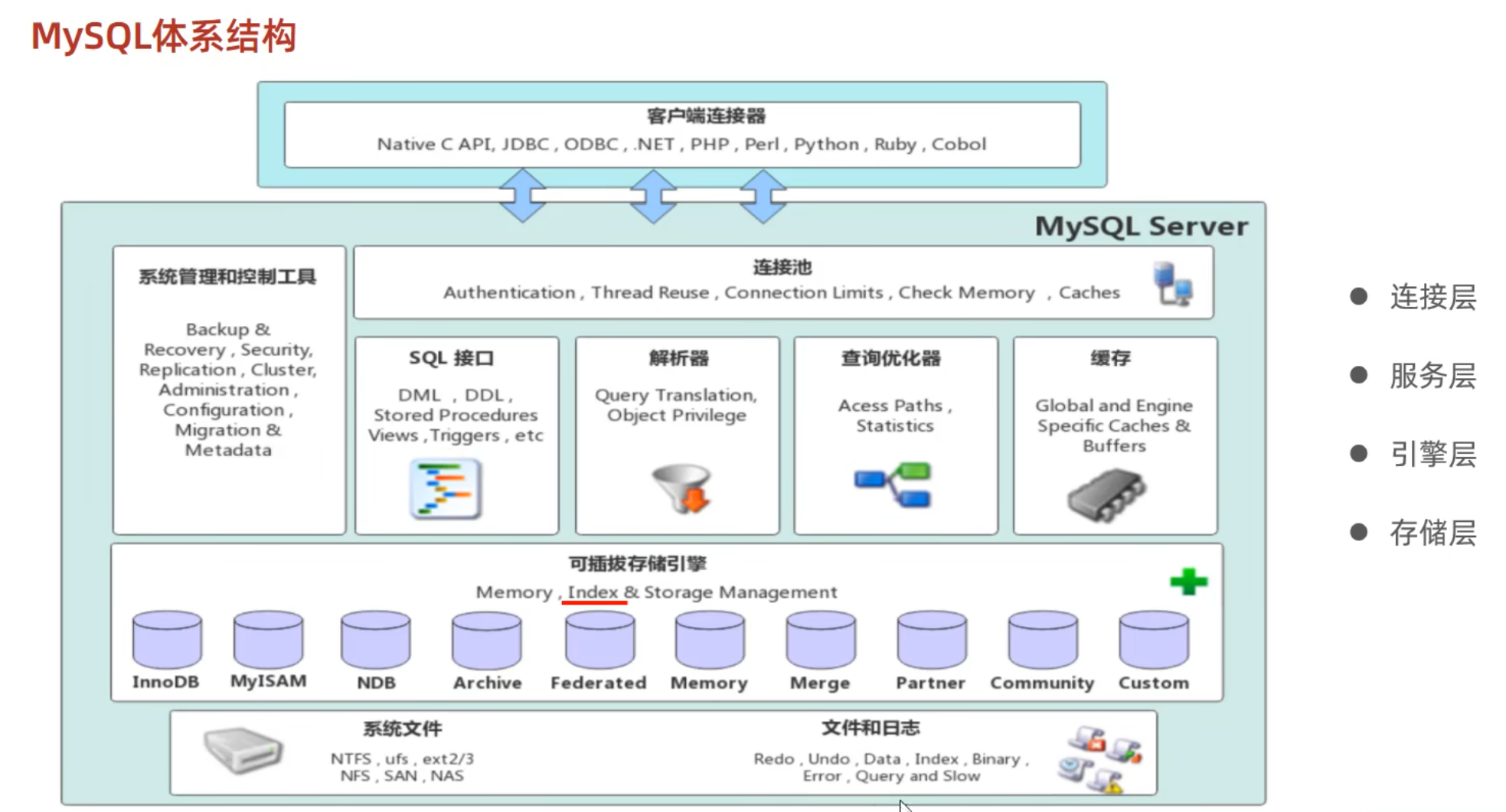
索引在引擎層
InnoDB存儲引擎
支持事務,行級鎖,外鍵

表結構,數據,索引全部都在表空間文件.ibd中
8.0之后表結構從.frm----->.sdi
邏輯存儲結構
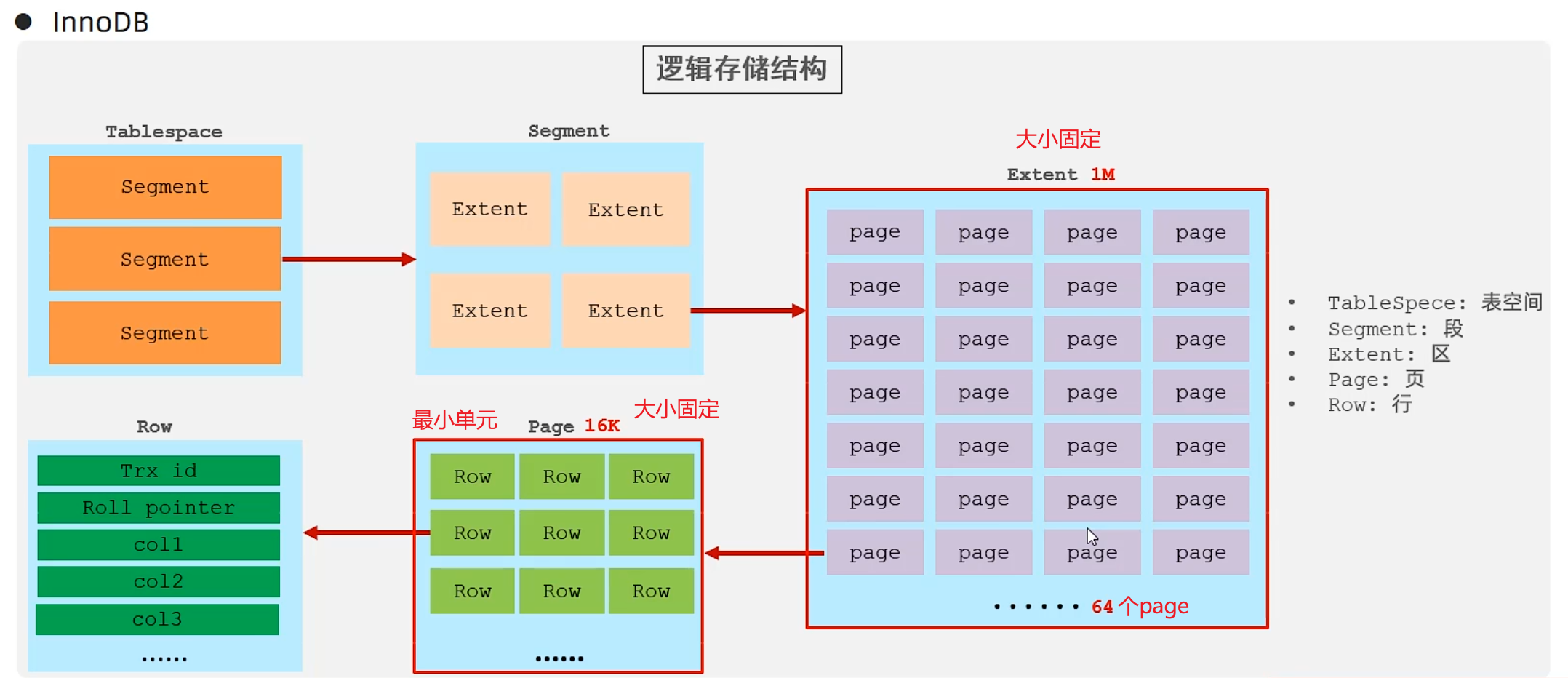
MyISAM(MongoDB)

Memory(Redis)

只有一個.sdi表結構數據在硬盤中,數據和索引都在內存中

索引
是一種優化后的B+ Tree數據結構
SQL優化都是根據索引來優化

索引在引擎層實現


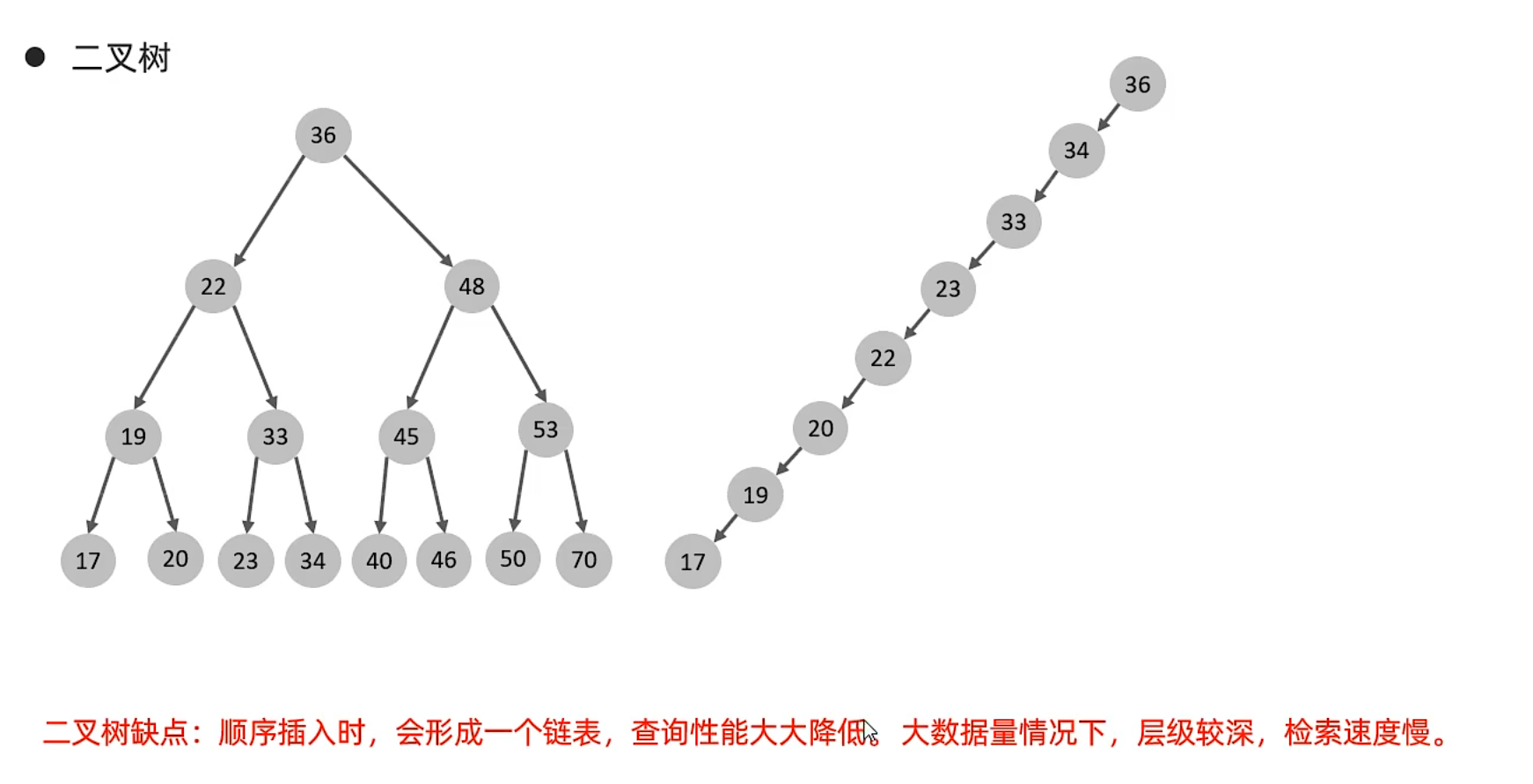
B樹
二叉樹
缺點:1.順序插入形成單向鏈表
2.一個節點只能有兩個子節點,數據量大時,層級較深,檢索速度慢
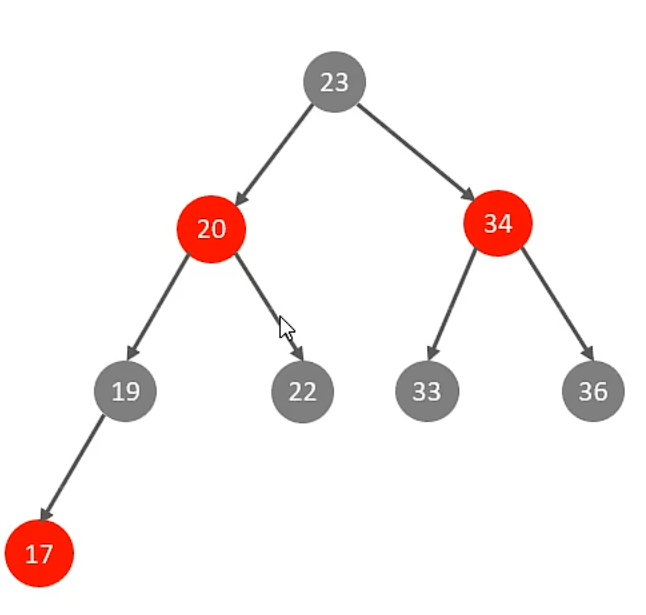
對于第一個問題,可以使用紅黑樹,自平衡,但是第二個問題不能解決
B樹(多路平衡查找樹)(一個節點下可以有多個子節點,解決第二個問題),同樣也是自平衡的
度數:樹的度數指的是一個節點的子節點個數
數據掛在key下面
B樹插入規則
以5階B樹為例,最多四個key
 插入1200
插入1200
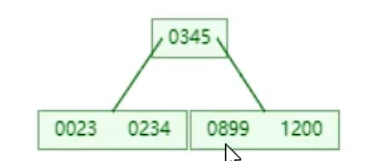
插入后中間的數向上分裂(這里是345)
B+樹
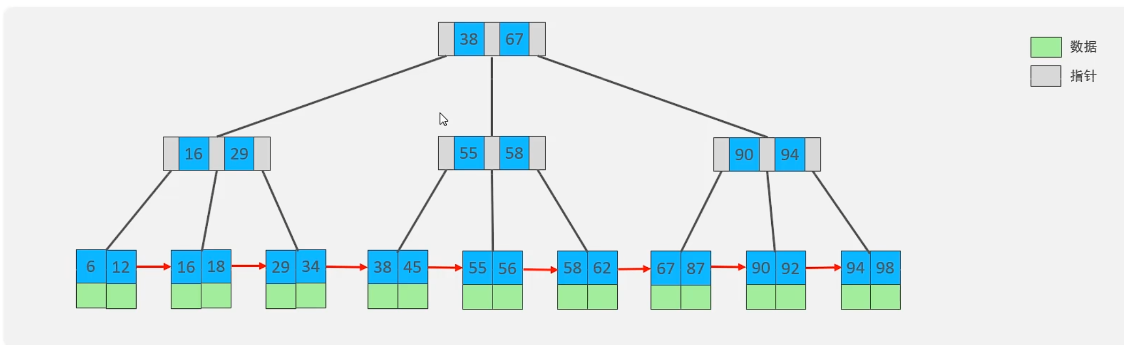
所有的元素都會出現在葉子節點中,上面的非葉子節點起到索引的作用,葉子節點是存放數據的
形成單向鏈表
B+樹插入規則
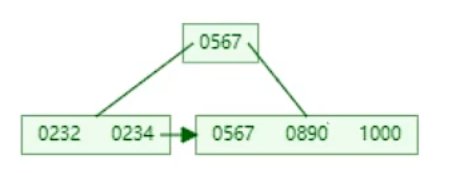
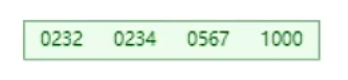 插入890
插入890
同樣,567向上分裂,但是葉子節點也會有567,出現指針,形成單向鏈表

Mysql索引對B+樹做了優化
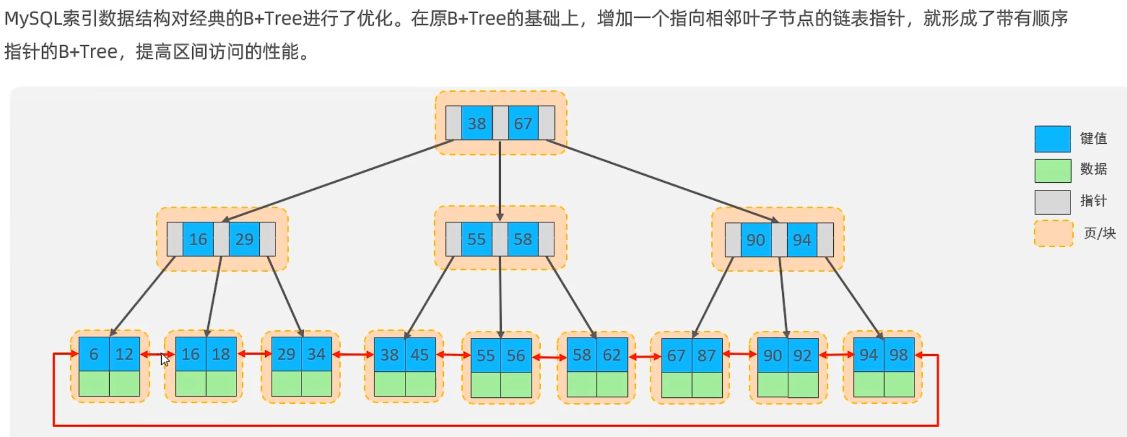
葉子節點是雙向鏈表,每一個節點都是存儲在頁中的
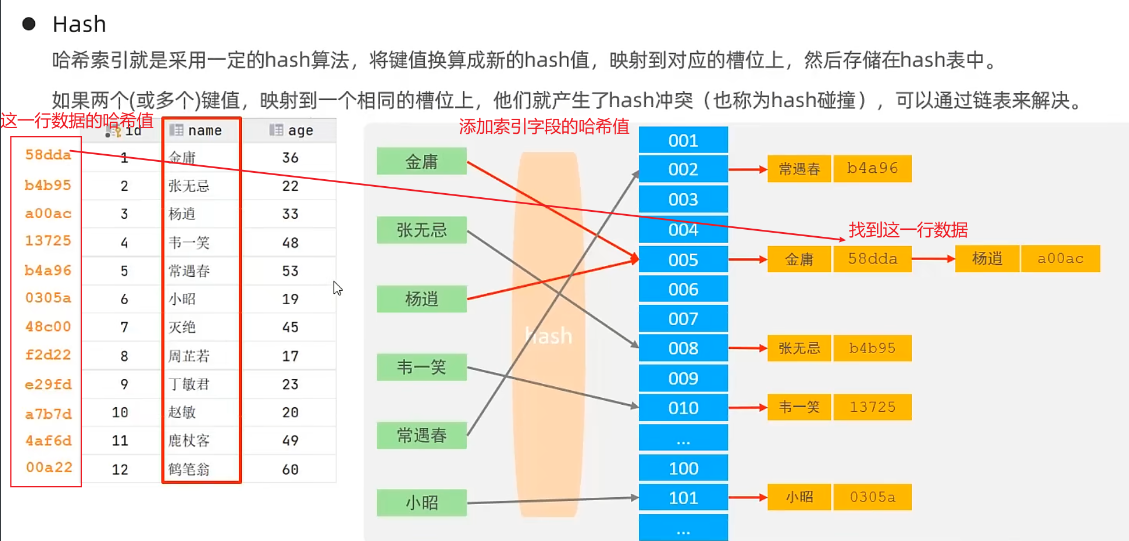
Hash索引數據結構
查詢效率高(不發生哈希沖突的情況)
不支持范圍查詢和排序

為什么InnoDB存儲引擎使用B+樹索引結構
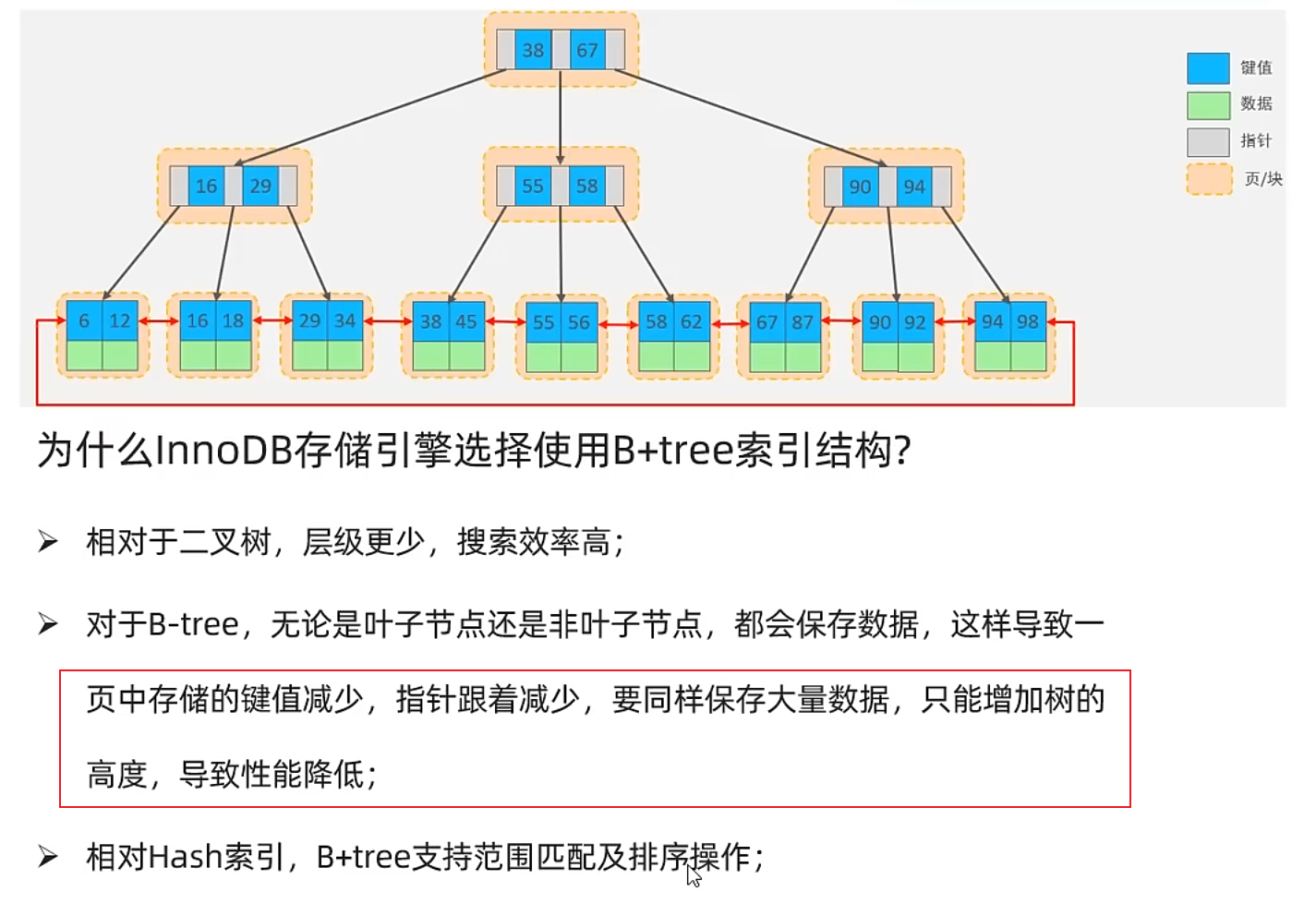
對于B樹和B+樹來說,每個節點都是存儲在頁page中,而page的大小是固定為16k的,所以對于B樹來說,page中存儲數據的話,會搶占key和指針的空間
key和指針減少,層級就會增多,導致性能降低
索引分類
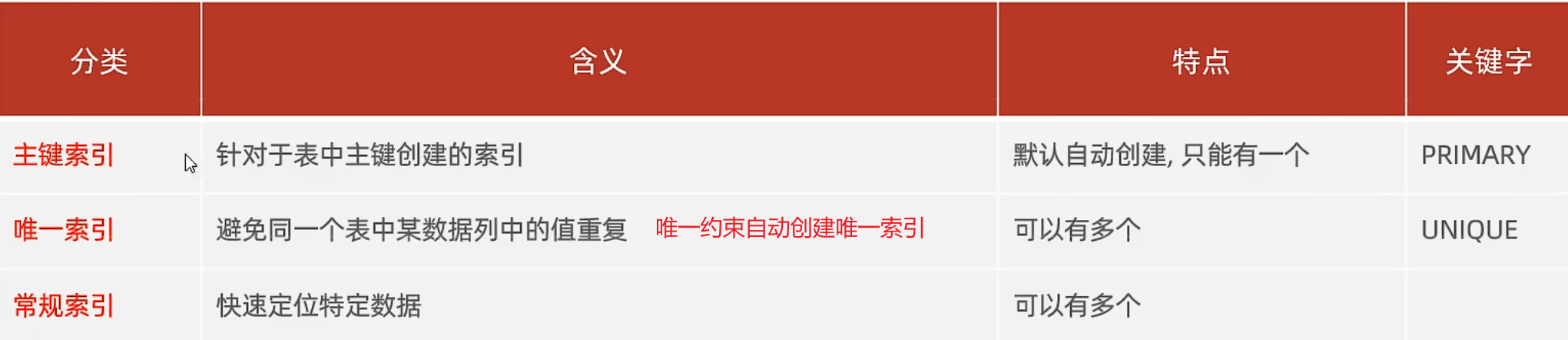
單列索引,聯合索引都是常規索引
常規索引屬于二級索引

聚簇索引,葉子節點保存了整行數據
非聚簇索引,葉子節點保存的是對應的主鍵id,如果有常規索引,也會保存常規索引字段數據

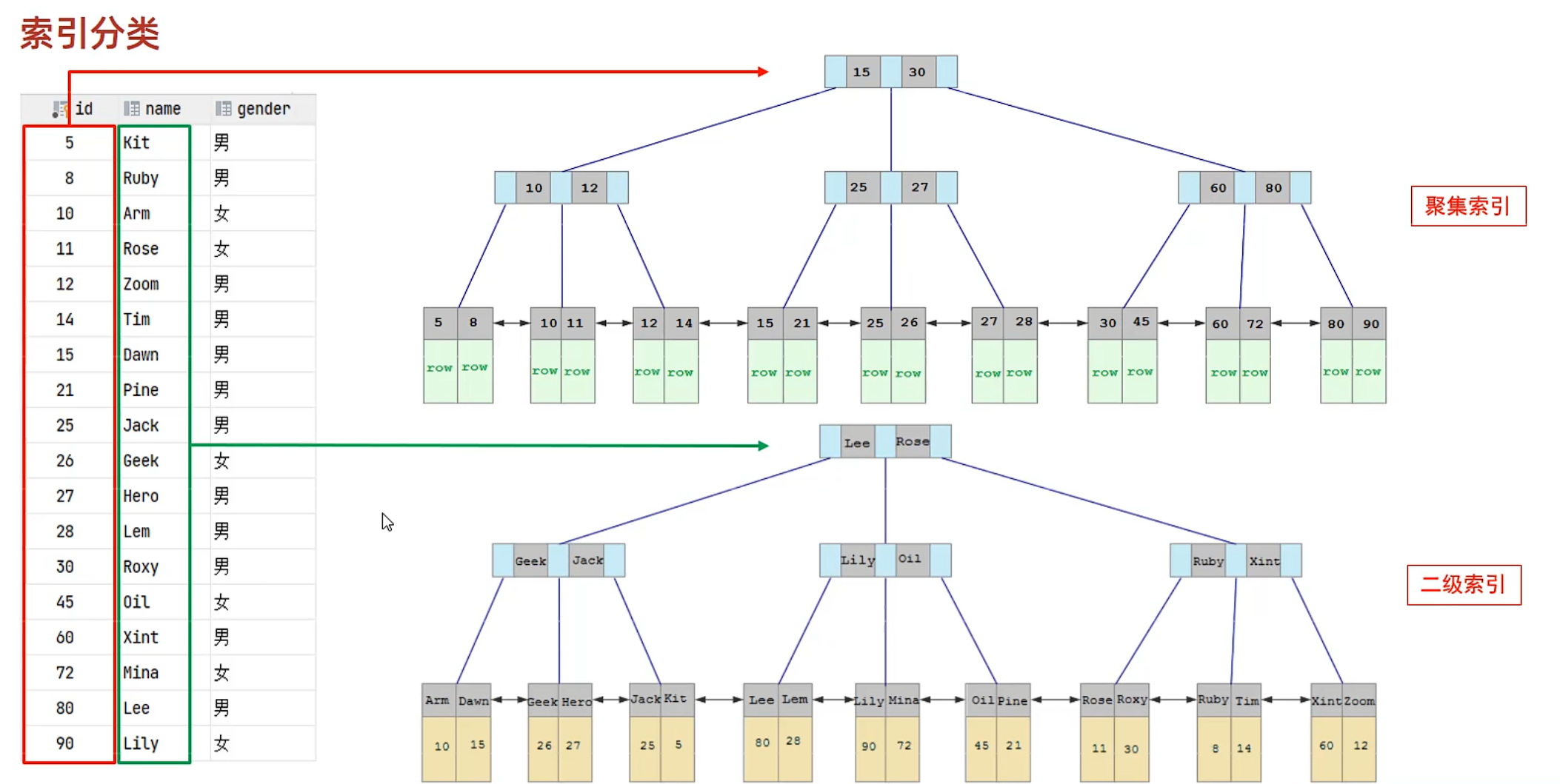
回表
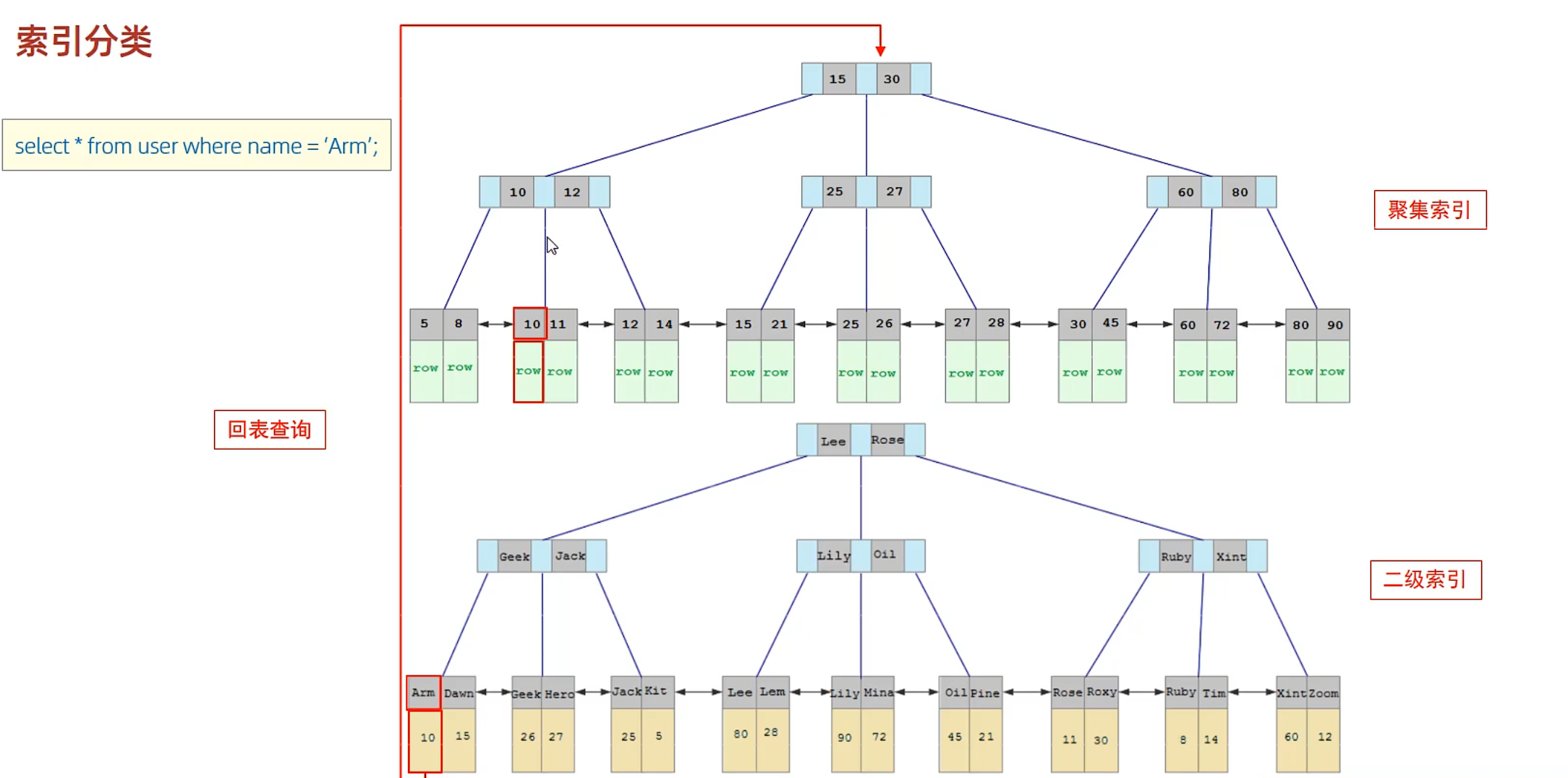
先查arm 索引找到主鍵id,然后根據主鍵id再找到對應的一整行數據
性能調優
主要對于索引來優化查詢語句
com后七個_
? 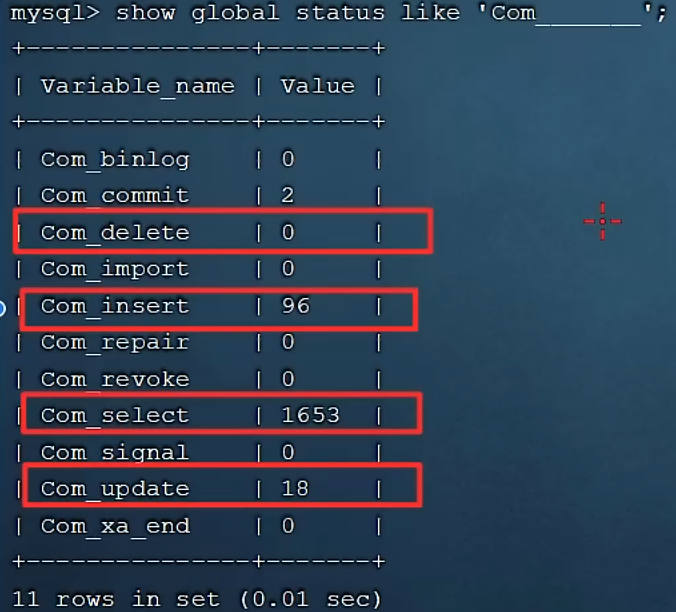
看當前數據庫是插入,更新,刪除,誰為主
如果發現查詢占主導,就需要進行sql優化
慢查詢日志
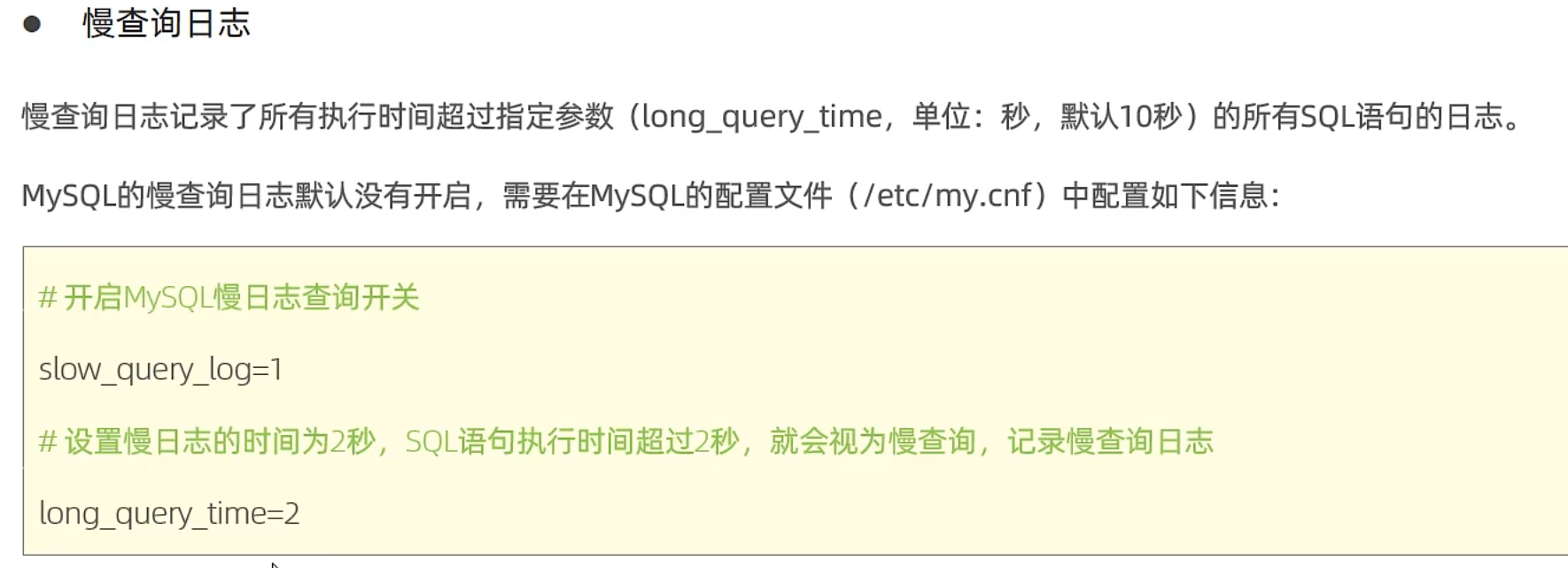
以上都是根據sql語句的執行時間來判斷sql的性能,我們不能只看執行時間
explain 執行計劃


多表查詢
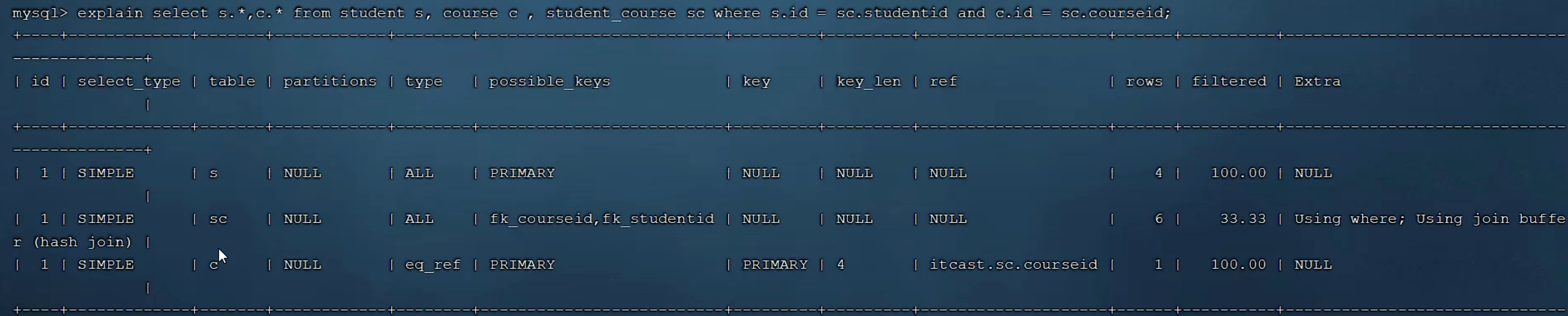
id相同,表結構執行順序從上往下,先執行student,再執行連接表,最后執行course表
子查詢(select嵌套)

id不同,值越大越先執行,先執行最內層的表,一層層執行出去

select_type意義不大,只說明當前sql的查詢類型

type

對于正常業務來說,const就是最好的了,NULL是不查表,system是查詢系統表
where對主鍵和唯一索引查詢一般是const和eq_ref,對于非唯一性索引一般是ref
index雖然用了索引,但也是對索引進行全表掃描,all是全表掃描
possible_key

顯示可能用到的索引
key

實際用到的索引



返回條數和實際掃描條數占比,越大越好
索引的使用
最左前綴法則(聯合索引)

針對于聯合索引,查詢時從索引最左側列(必須存在)開始,不跳過索引中間的列,如果跳過某一列,這一列后面的索引將會失效
創建聯合索引

profession,age,status,按順序聯合,profession是最左字段


表示status這個字段索引長度是5

表示age索引長度是2

全表掃描,索引失效,因為沒有最左字段

缺少中間字段,所以之后的索引部分失效,只走了profession的索引
和字段使用順序無關,只要出現就行
范圍查詢(聯合索引)
針對于聯合索引


索引失效情況
1.對索引列進行運算操作(函數substr等)
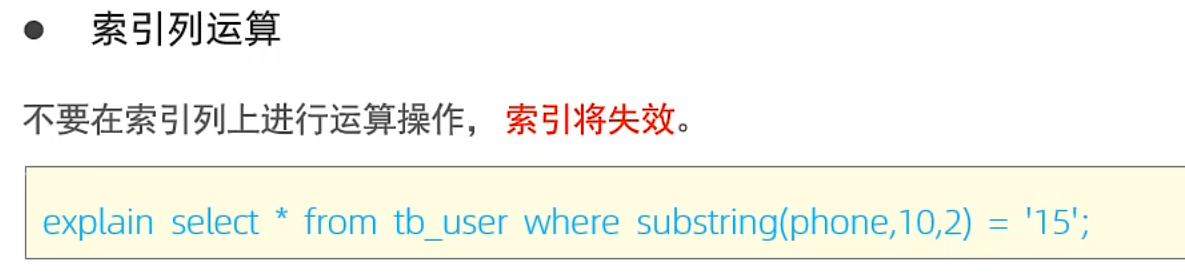
2.字符串字段沒有加’’

3.頭部模糊匹配,索引失效

4.or前后字段都要有索引才會走索引,不然失效
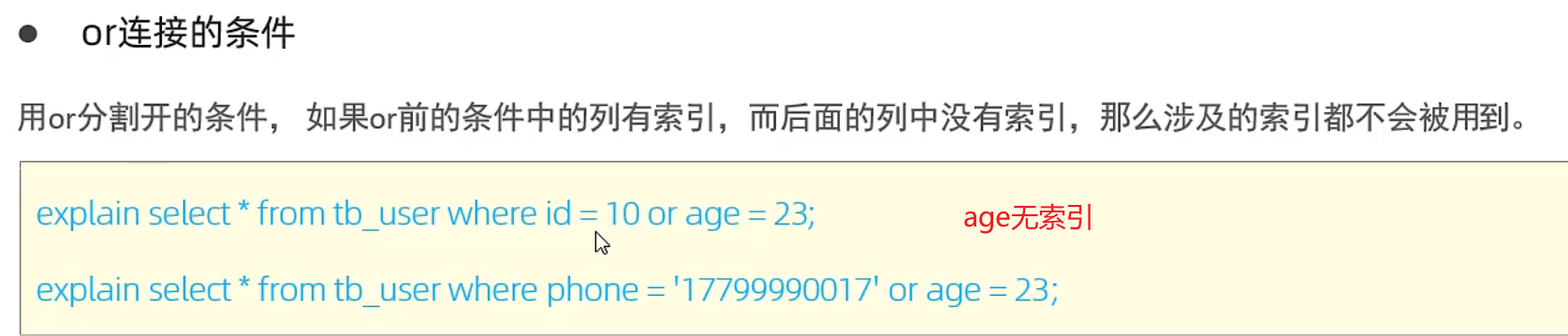

5.數據分布影響
有時候使用索引比全表掃描還慢,就不會使用索引
比如:當我們要一個條件把全表都查出來(或者表的絕大部分都是滿足條件的),肯定走全表掃描比走索引快
is null (因為絕大部分都不是null,不滿足)一般走索引
is not null(因為絕大部分都不是null,滿足)一般不走索引
所以null要看表中數據絕大部分滿不滿足,如果滿足,就不走,如果不滿足,就走索引
SQL提示
可以給一個字段添加多個索引,比如聯合索引和單列索引
mysql默認會執行聯合索引(前提滿足最左前綴法則)
可以指定來使用哪個索引


use index 只是一個建議,mysql可能不會用
force index 是必須用
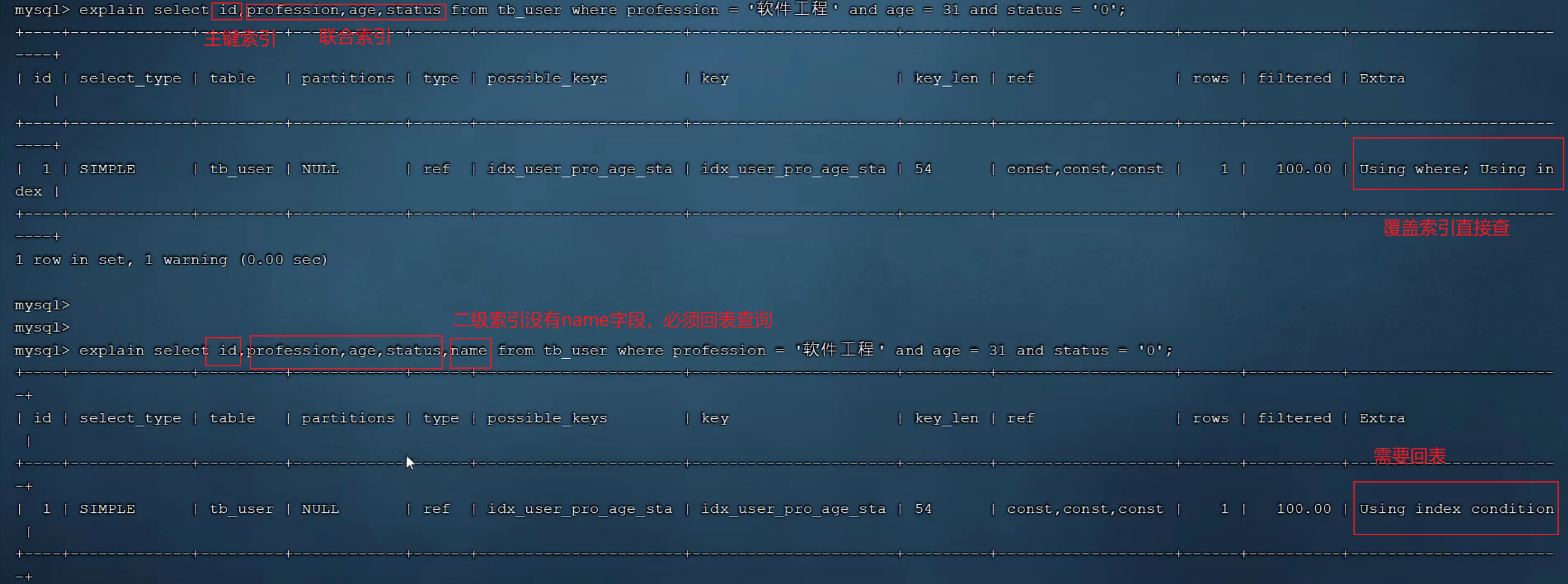
覆蓋索引
select返回的字段在索引列中都能找到,而不需要回表查詢,這樣的索引就是覆蓋索引
盡量避免select *

測試
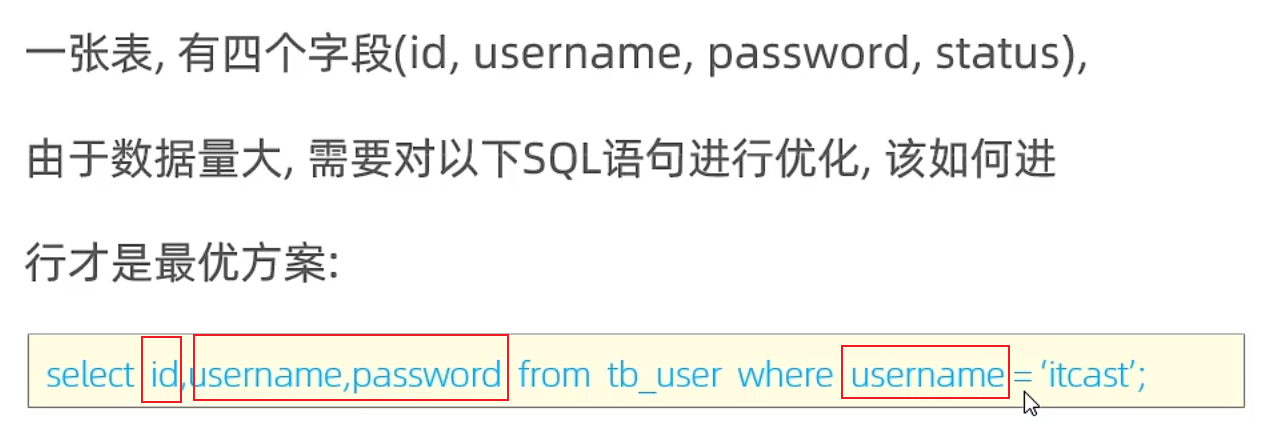
對username和password加聯合索引,就不需要回表了
前綴索引

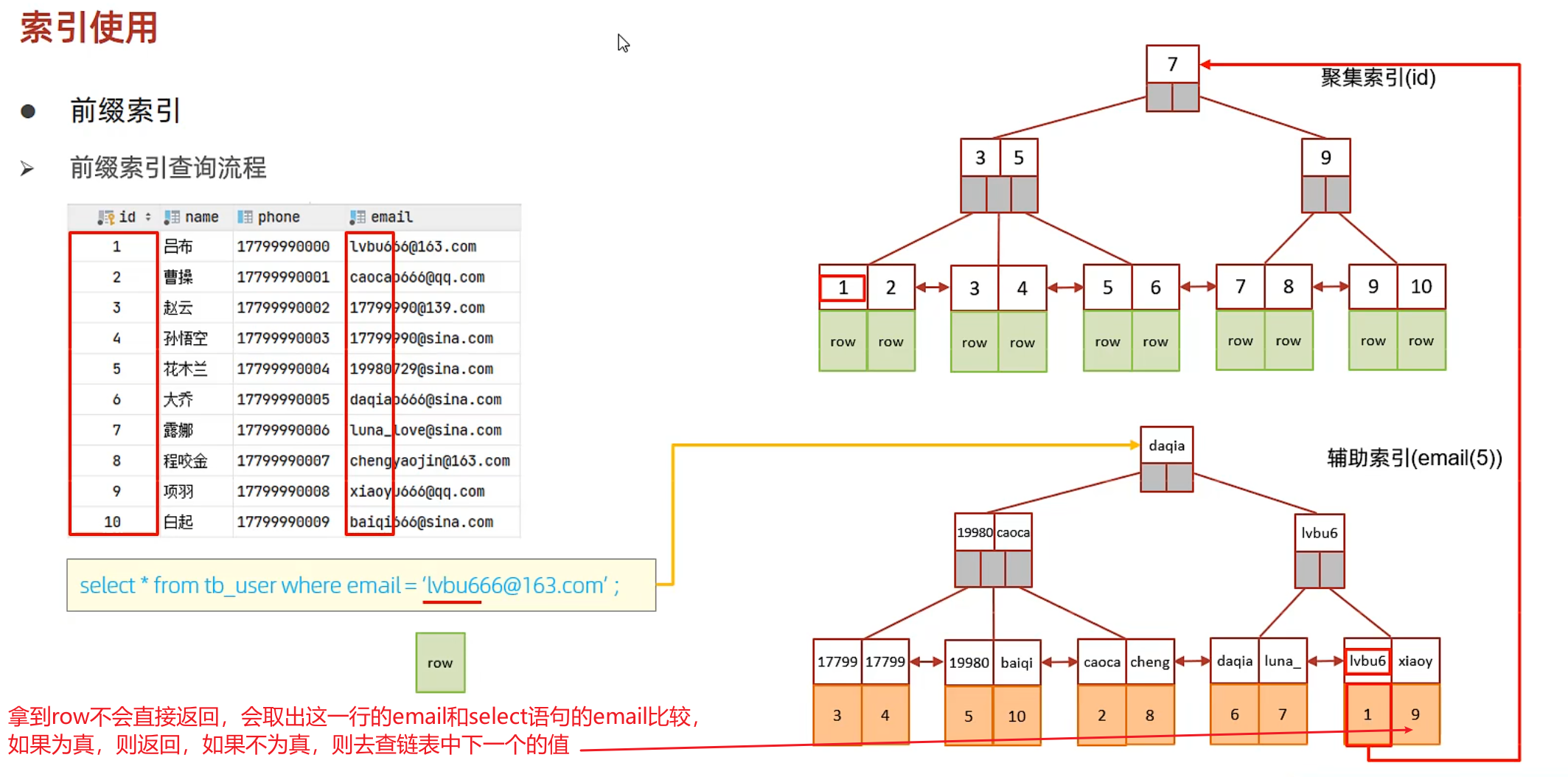
前綴索引中,回表查詢拿到row這一行的數據不會直接返回,而是會對比這條數據中前綴索引字段和select語句的字段是否一致,如果一致則返回結果,如果不一致,則順著二級索引的鏈表繼續查找下一個判斷
單列和聯合索引的選擇

一個字段可以有多個索引,比如自己的單列索引再加上和別人的聯合索引
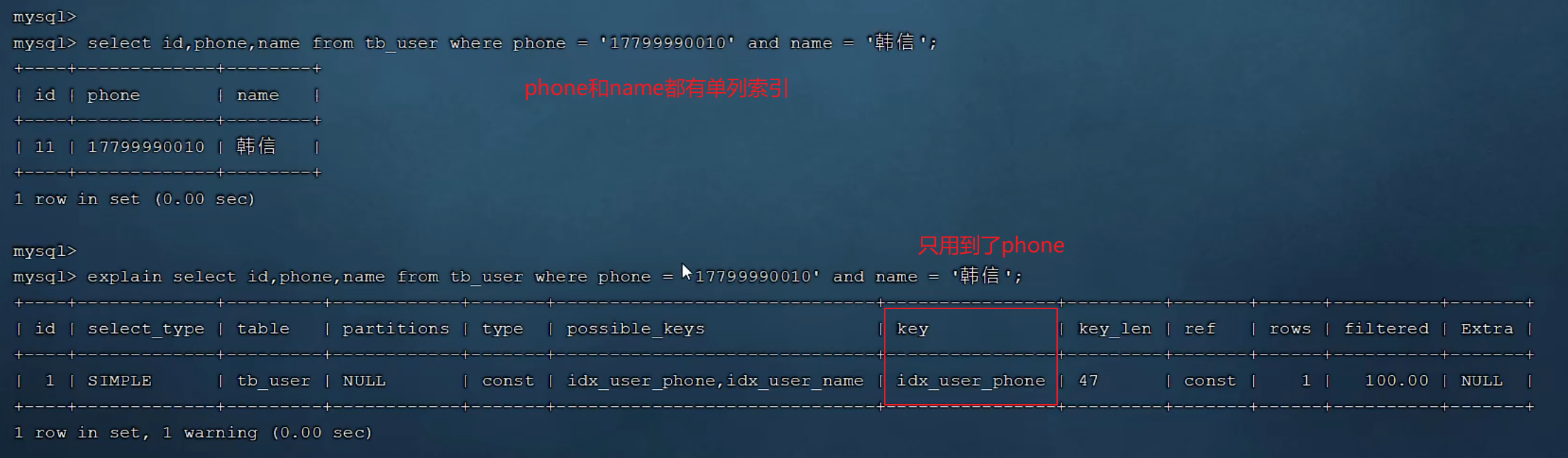
mysql會評估哪個字段的索引效率更高,會選擇改索引,也就是phone索引
此時在phone的單列索引中不包含name字段,所以會進行回表查詢
我們給phone和name添加上聯合索引后,還是使用的phone的單列索引(單列索引干擾),還是會回表

所以我們可以用sql提示(use index)來指定mysql使用聯合索引
所以,如果存在多個查詢條件,我們一般建立聯合索引(覆蓋索引,不會回表查詢)
聯合索引的數據結構
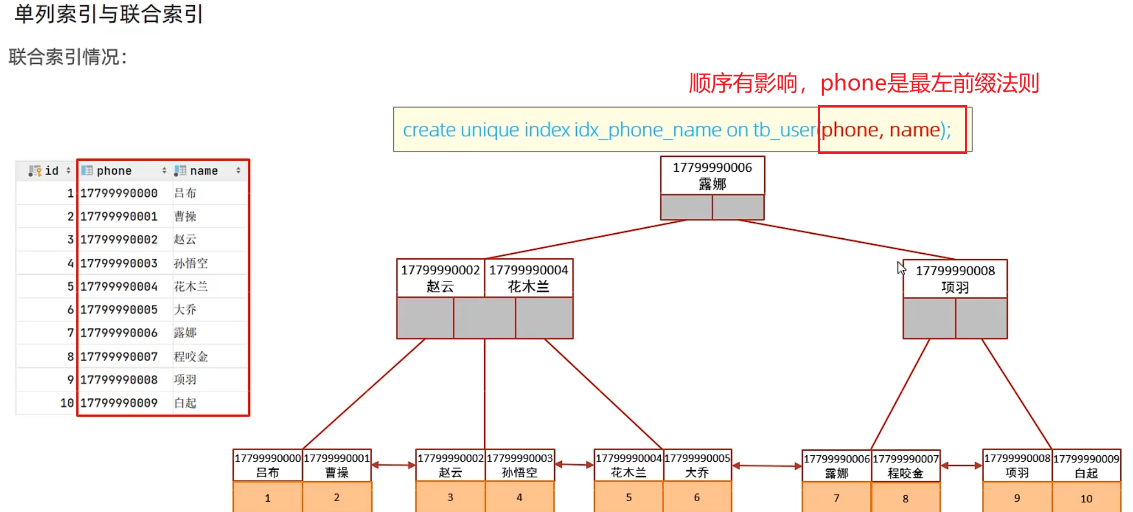
索引設計原則

)


:vivo X200 Ultra影像技術溝通會總結)





)

底層的實現:)





)

)