自從 Wan 2.1 發布以來,AI 視頻生成領域似乎進入了一個發展瓶頸期,但這也讓人隱隱感到:“DeepSeek 時刻”即將到來!就在前幾天,浙江大學與月之暗面聯合推出了一款全新的文本到視頻(T2V)生成模型——**LanDiff** 。這款模型通過融合語言模型和擴散模型的優勢,為高質量視頻生成帶來了突破性進展。接下來,我們一起來深入了解這款引人注目的技術成果。
LanDiff 被譽為視頻生成領域的“混血兒”,它巧妙地將擅長語義理解的語言模型與專注于圖像質量的擴散模型結合在一起 。具體來說,LanDiff 首先利用語義分詞器將視頻內容壓縮成簡潔的“故事大綱”,這一步類似于搭建骨架;隨后,擴散模型在此基礎上逐步細化,將大綱轉化為細節豐富、視覺效果出色的完整視頻 。這種“先搭框架再精雕細琢”的設計,不僅確保了生成內容高度契合文本描述,還顯著提升了視頻的視覺質量。
在性能表現上,LanDiff 同樣令人驚艷。根據 VBench 基準測試結果顯示,LanDiff 以 **85.43 的高分**成功登頂,遠超其他開源模型的表現 。尤其值得一提的是,LanDiff 在長視頻生成任務中展現出了強大的能力,能夠穩定輸出連貫且高質量的內容,充分證明了其在復雜場景下的適應性和魯棒性 。這一創新無疑為視頻生成領域注入了新的活力,也為未來的應用拓展提供了更多可能性。
核心特色 | Method
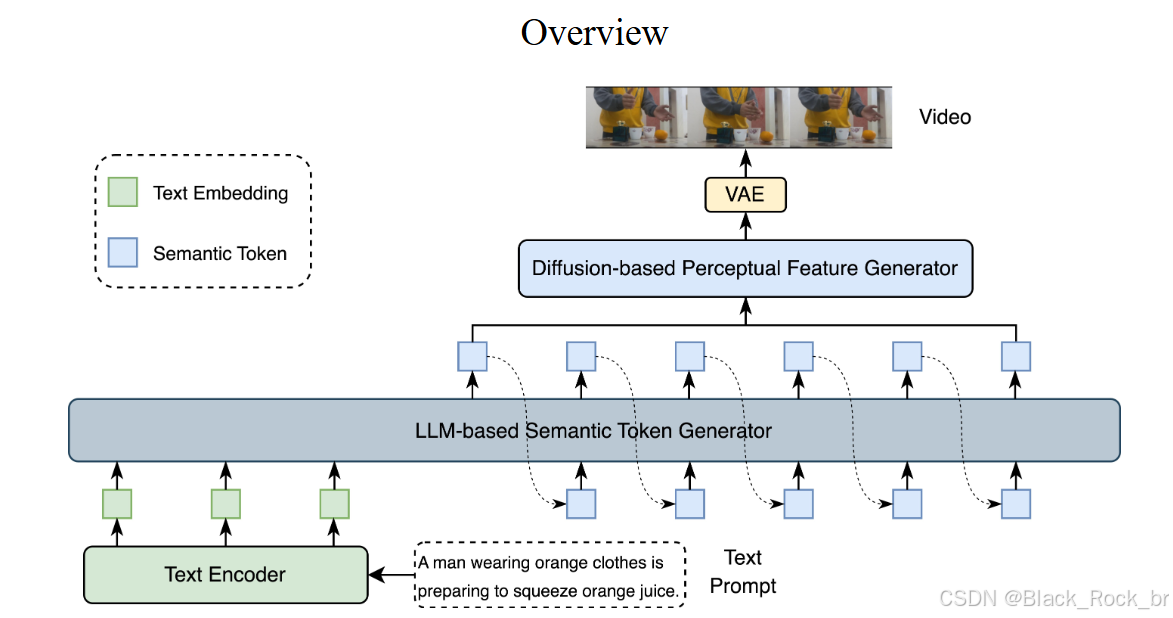
LanDiff是一種混合架構,它通過粗到精的生成范式,結合了語言模型和擴散模型的優點,其架構圖如下。模型的核心架構主要分為以下三個部分:視頻語義分詞器、基于LLM的語義Token生成器和基于擴散模型的感知特征生成器。
視頻語義Tokenizer | Video Semantic Tokenizer
“壓縮與理解的雙重魔法”:LanDiff 中的視頻語義 Tokenizer
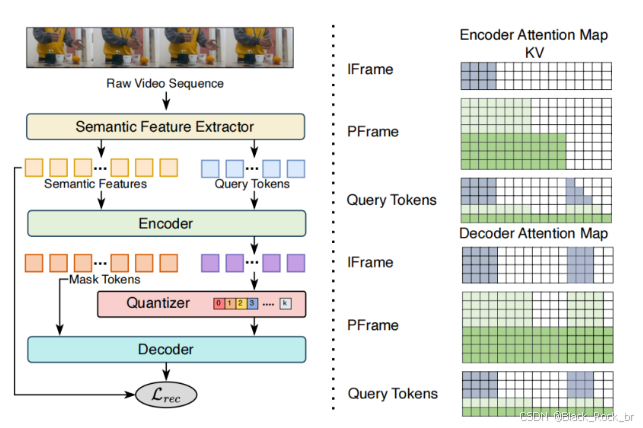
在 LanDiff 模型中,視頻語義 Tokenizer 被譽為整個架構的“壓縮大師”,其核心任務是將復雜的視頻信息壓縮成簡潔的語義表達,同時保留視頻的核心語義和細節。這種能力不僅減輕了后續語言模型和擴散模型的負擔,還顯著提升了生成效率和質量 。
---
查詢分詞:聚焦關鍵信息
Tokenizer 的一大創新在于**查詢分詞(Query Tokens)**,這是一種隨機初始化的標記機制,用于與視頻的語義特征交互,提取出最能代表視頻內容的關鍵信息。這些查詢 tokens 就像“信息雷達”,能夠在龐大的視頻數據中精準鎖定重要語義點,從而實現高效的語義壓縮與理解 。
---
視頻語義表示:選擇更優的特征提取方式
LanDiff 并未直接使用自編碼器學習的特征,而是選擇了預訓練的**自監督學習特征(SSL)** 作為視頻表示,并采用 Theia 模型進行視覺特征提取。這種設計的原因在于,SSL 特征能夠更好地保留視頻的高層次語義信息,而 Theia 模型經過多個視覺任務模型(如 CLIP、SAM、DINOv2、ViT 和 Depth-Anything)的提煉,確保了編碼后的特征具有豐富的語義內涵 。
---
Tokenizer 的具體實現
在技術實現上,LanDiff 的 Tokenizer 采用了基于 Transformer 的結構,并結合查詢嵌入來聚合視覺特征,從而實現極高的壓縮率。具體流程如下:
1. 語義特征提取
? ?首先,使用 Theia 模型提取視頻的語義特征,并將其扁平化處理,以便后續操作 。
2. 查詢 tokens 的引入
? ?然后,引入一組隨機初始化的查詢 tokens,并將它們與提取的語義特征拼接在一起。這些查詢 tokens 在語義特征中扮演了“信息提取器”的角色。
3. Transformer 編碼?
? ?使用 Transformer 編碼器對拼接后的特征進行編碼,最終僅保留查詢 tokens 的編碼結果,作為后續處理的基礎。
4. 向量量化
? ?接下來,通過訓練 VQ-VAE 模型對查詢 tokens 的編碼特征進行向量量化,得到離散的語義 tokens。這一過程以最小化視頻語義特征的重建損失為目標,并采用 EMA(指數移動平均)的方式更新模型參數。
5. 解碼階段??
? ?在解碼階段,量化后的特征被用作條件輸入,并在其前添加一系列 mask tokens,形成解碼器的輸入序列 。
視頻幀分組策略:高效壓縮與建模
LanDiff 的視頻幀分組策略靈感來源于 MP4 視頻編碼算法,通過將視頻幀分為**關鍵幀(I-Frame)** 和**非關鍵幀(P-Frame)**,大幅減少了計算量和數據量:
1. 分組與建模?
?
? ?將 N 幀視頻劃分為 N/T 組,每組包含 T 幀。每一組獨立建模,確保處理效率。
2. 關鍵幀與非關鍵幀的差異化處理
??
? ?- 關鍵幀(I-Frame):完整編碼每組的第一幀,賦予大量查詢 tokens,以實現高質量重建。 ?
? ?- 非關鍵幀(P-Frame):僅捕捉時間上的變化,參考先前的關鍵幀進行編碼,并分配少量查詢 tokens,迫使模型專注于幀間差異。
3. 掩碼機制
? ?在編碼過程中,對特征序列應用幀級別的因果掩碼,確保每個 token 只能關注相應幀及之前的幀特征 。
4. 解碼中的上下文依賴
?
? ?在解碼階段,每個幀對應的 mask token 不僅可以看到自身的查詢 tokens,還可以參考先前幀的特征和查詢 tokens,從而實現上下文依賴的高效解碼。
壓縮率與質量的雙贏
LanDiff 的視頻語義 Tokenizer 在壓縮率和生成質量之間實現了完美的平衡。對于一段分辨率為 480x720 的一秒視頻,LanDiff 平均僅需生成約 200 個 tokens,而常見的 MagViT2 tokenizer 則需要生成約 10,000 個 tokens 。這意味著 LanDiff 的序列長度僅為 MagViT2 的 1/50,顯著降低了計算復雜度和資源消耗。與此同時,LanDiff 在語義保留和視頻重建質量方面依然表現出色,真正實現了高效壓縮與高質量輸出的雙贏 。
用于語義Token生成的語言模型
語言模型與高效分詞器的結合:通過訓練高效的分詞器,利用語言模型進行自回歸生成語義化的分詞,從而實現從文本到視頻的生成過程。
多模態特征提取:借助預訓練的T5-XXL模型提取文本特征,并利用視頻語義Tokenizer(在前一節中介紹)將視頻轉換為離散的分詞序列,實現文本與視頻的跨模態融合。
可控生成條件:引入幀條件和運動分數條件等控制條件,增強對生成視頻的控制能力,以滿足不同場景的需求。
模型結構與訓練:采用LLaMA模型結構,從頭開始訓練,并使用交叉熵損失函數,確保模型的生成性能和穩定性。
用于生成感知特征的擴散模型
目標:將上一章節中生成的語義tokens轉換為VAE潛在向量,作為視頻detokenizer,負責將語義tokens轉換成視頻。
架構:
- 采用類似于MMDiT的架構。
- 使用視頻tokenizer解碼器將語義tokens解碼為語義特征 \(\hat{F}\)。
- 以語義特征 \(\hat{F}\) 作為條件,指導擴散模型生成視頻。
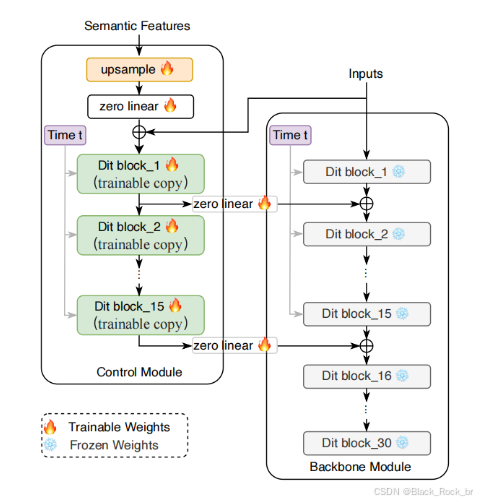
- 引入類似于ControlNet風格的控制模塊,基于語義特征指導模型生成感知特征。在訓練期間,主模型的參數保持不變,控制模塊復制主模型前半部分層的參數,并在經過一個用零初始化的線性層后添加到主模型的輸出。
- 為了使語義特征在空間維度上與目標VAE特征匹配,額外添加了一個上采樣模塊。
訓練:


Chunk-wise流式策略:

?
模型參數:
- 整個視頻detokenizer的總參數為3B,其中可訓練的控制模塊參數數量為1B。
- 以CogVideoX-2B模型作為視頻detokenizer的基礎模型。
為了不重復之前的表述,我將對這段內容進行重新組織和潤色,同時保留原文的核心觀點和信息,以下是改寫后的內容:
我們暫且不深入探討更多的實驗細節與評測數據,但可以肯定的是,該模型的表現無疑是處于行業頂尖水平(SOTA)。至于模型是否開源,目前尚未有明確消息。不過,LanDiff的成功無疑凸顯了混合架構在突破單一方法固有局限性方面的巨大潛力,為依據文本描述生成連貫、語義忠實且視覺效果卓越的視頻開辟了新的道路。當下,從單模態生成邁向多模態生成,從Janus到dLLM,越來越多的研究致力于實現語言模型與擴散模型的融合。基于此,我們有充分的理由相信,文本到視頻生成技術的融合與成功,必將為創意表達與內容創作注入新的活力,帶來前所未有的機遇。
開源地址:LanDiff


)

底層的實現:)





)

)
)


)

綁定導入表)
