參考:
GitHub - microsoft/BioGPT
https://github.com/microsoft/BioGPT
BioGPT:用于生物醫學文本生成和挖掘的生成式預訓練轉換器 |生物信息學簡報 |牛津學術 — BioGPT: generative pre-trained transformer for biomedical text generation and mining | Briefings in Bioinformatics | Oxford Academic
https://academic.oup.com/bib/article/23/6/bbac409/6713511
環境:
centos 7,anaconda3,CUDA 11.6
安裝方法:
centos-LLM-生物信息-BioGPT安裝-CSDN博客
https://blog.csdn.net/pxy7896/article/details/146982288
目錄
- 官方測試用例
- 使用hugging face
- 文本生成
- 報錯處理
- ModuleNotFoundError: No module named 'torch.distributed.tensor'
- A module that was compiled using NumPy 1.x cannot be run in NumPy 2.0.1
BioGPT 是一個基于 GPT 架構的生物醫學領域預訓練語言模型,適用于生成生物醫學文本或進行相關 NLP 任務。
官方測試用例
使用hugging face
文本生成
說明:
BioGptForCausalLM是GPT類型的因果語言模型,適用于:- 文本生成:如問答、摘要
- 生物醫學文本續寫:如生成診斷報告
BioGptForCausalLM是基于Transformer的Decoder-only架構,參數量:1.5B(Large 版本)或 345M(Base 版本)
import os
# 國內加速
os.environ['HF_ENDPOINT'] = 'https://hf-mirror.com'from transformers import BioGptTokenizer, BioGptForCausalLM
from transformers import pipeline, set_seed
# 加載分詞器tokenizer(1.將文本轉化為Token IDs供模型理解 2.處理特殊標記)
tokenizer = BioGptTokenizer.from_pretrained("microsoft/biogpt")
# 加載模型(加載時會下載預訓練權重)
model = BioGptForCausalLM.from_pretrained("microsoft/biogpt")
'''
text = "Replace me by any text you'd like."
# 返回 PyTorch 張量. tf是返回tensorflow張量, np是返回NumPy數組
# Hugging Face 的 Transformers 庫支持 PyTorch、TensorFlow 和 JAX,需明確指定張量格式
encoded_input = tokenizer(text, return_tensors='pt')
output = model(**encoded_input) #
'''
# 創建文本生成的流水線,能自動處理文本的分詞、模型調用和輸出解碼
generator = pipeline('text-generation', model=model, tokenizer=tokenizer)
# 設置隨機種子,確保生成結果可以復現
set_seed(42)
# 要求生成5條不同的文本(需要生成越多越增加顯存占用)
# 每條最大長度為20個token,啟用隨機采樣(非確定性生成)
# 模型會基于概率分布隨機選擇下一個 token(溫度參數默認為 1.0),因此每次調用結果可能不同
# 與 do_sample=False(貪心搜索)相比,結果更具多樣性
# 如果需要控制隨機性可以設置temperature,越小越保守
outputs = generator("COVID-19 is", max_length=20, num_return_sequences=5, do_sample=True)
# 打印結果
for i, output in enumerate(outputs):print(f"Result {i+1}: {output['generated_text']}")
'''
Result 1: COVID-19 is a disease that spreads worldwide and is currently found in a growing proportion of the population
Result 2: COVID-19 is one of the largest viral epidemics in the world.
Result 3: COVID-19 is a common condition affecting an estimated 1.1 million people in the United States alone.
Result 4: COVID-19 is a pandemic, the incidence has been increased in a manner similar to that in other
Result 5: COVID-19 is transmitted via droplets, air-borne, or airborne transmission.
'''Beam-Search:
Beam-Search(束搜索) 是一種用于序列生成(如文本生成、機器翻譯)的搜索算法,比貪心搜索(Greedy Search)更高效且能生成更優結果。其核心思想是:在每一步保留 Top-K(K = num_beams) 個最可能的候選序列,而不是只保留一個最優解(貪心策略)。
參數選擇:
num_beams:越大結果越好,但是計算量也越。通常5是平衡點early_stopping:當所有候選序列都達到結束標記時提前終止min_length和max_length:控制生成的文本的token數量,防止過早結束或者太長length_penalty:長度懲罰( <1 鼓勵短文本,>1 鼓勵長文本 )
import torch
from transformers import BioGptTokenizer, BioGptForCausalLM, set_seedtokenizer = BioGptTokenizer.from_pretrained("microsoft/biogpt")
model = BioGptForCausalLM.from_pretrained("microsoft/biogpt")sentence = "COVID-19 is"
inputs = tokenizer(sentence, return_tensors="pt")set_seed(42)with torch.no_grad():# 生成一個包含生成的token IDs的張量beam_output = model.generate(**inputs, min_length=100, max_length=1024, num_beams=5, early_stopping=True)
# 解碼
tokenizer.decode(beam_output[0], skip_special_tokens=True)
'''
COVID-19 is a global pandemic caused by severe acute respiratory syndrome coronavirus 2 (SARS-CoV-2), the causative agent of coronavirus disease 2019 (COVID-19), which has spread to more than 200 countries and territories, including the United States (US), Canada, Australia, New Zealand, the United Kingdom (UK), and the United States of America (USA), as of March 11, 2020, with more than 800,000 confirmed cases and more than 800,000 deaths.
'''報錯處理
ModuleNotFoundError: No module named ‘torch.distributed.tensor’
完整報錯:
>>> from transformers import pipeline, set_seed
Traceback (most recent call last):File "/home/xxx/anaconda3/envs/biogpt/lib/python3.10/site-packages/transformers/utils/import_utils.py", line 1967, in _get_modulereturn importlib.import_module("." + module_name, self.__name__)File "/home/xxx/anaconda3/envs/biogpt/lib/python3.10/importlib/__init__.py", line 126, in import_modulereturn _bootstrap._gcd_import(name[level:], package, level)File "<frozen importlib._bootstrap>", line 1050, in _gcd_importFile "<frozen importlib._bootstrap>", line 1027, in _find_and_loadFile "<frozen importlib._bootstrap>", line 1006, in _find_and_load_unlockedFile "<frozen importlib._bootstrap>", line 688, in _load_unlockedFile "<frozen importlib._bootstrap_external>", line 883, in exec_moduleFile "<frozen importlib._bootstrap>", line 241, in _call_with_frames_removedFile "/home/xxx/anaconda3/envs/biogpt/lib/python3.10/site-packages/transformers/pipelines/__init__.py", line 49, in <module>from .audio_classification import AudioClassificationPipelineFile "/home/xxx/anaconda3/envs/biogpt/lib/python3.10/site-packages/transformers/pipelines/audio_classification.py", line 21, in <module>from .base import Pipeline, build_pipeline_init_argsFile "/home/xxx/anaconda3/envs/biogpt/lib/python3.10/site-packages/transformers/pipelines/base.py", line 69, in <module>from ..modeling_utils import PreTrainedModelFile "/home/xxx/anaconda3/envs/biogpt/lib/python3.10/site-packages/transformers/modeling_utils.py", line 41, in <module>import torch.distributed.tensor
ModuleNotFoundError: No module named 'torch.distributed.tensor'The above exception was the direct cause of the following exception:Traceback (most recent call last):File "<stdin>", line 1, in <module>File "<frozen importlib._bootstrap>", line 1075, in _handle_fromlistFile "/home/xxx/anaconda3/envs/biogpt/lib/python3.10/site-packages/transformers/utils/import_utils.py", line 1955, in __getattr__module = self._get_module(self._class_to_module[name])File "/home/xxx/anaconda3/envs/biogpt/lib/python3.10/site-packages/transformers/utils/import_utils.py", line 1969, in _get_moduleraise RuntimeError(
RuntimeError: Failed to import transformers.pipelines because of the following error (look up to see its traceback):
No module named 'torch.distributed.tensor'
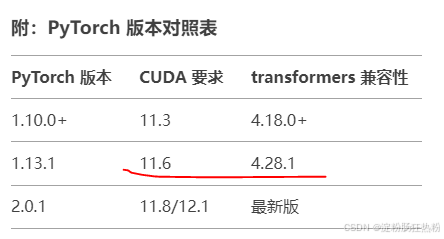
已知torch.distributed.tensor 模塊在 PyTorch 1.10+ 才引入,但我的 PyTorch 版本是1.12.0,考慮是transformers版本沖突,所以降級到4.28.1。
pip install transformers==4.28.1 -i https://pypi.tuna.tsinghua.edu.cn/simple
驗證:
>>> import torch
>>> print(torch.__version__)
1.12.0
>>> print(torch.distributed.is_available())
True
A module that was compiled using NumPy 1.x cannot be run in NumPy 2.0.1
完整報錯:
>>> model = BioGptForCausalLM.from_pretrained("microsoft/biogpt")A module that was compiled using NumPy 1.x cannot be run in
NumPy 2.0.1 as it may crash. To support both 1.x and 2.x
versions of NumPy, modules must be compiled with NumPy 2.0.
Some module may need to rebuild instead e.g. with 'pybind11>=2.12'.If you are a user of the module, the easiest solution will be to
downgrade to 'numpy<2' or try to upgrade the affected module.
We expect that some modules will need time to support NumPy 2.Traceback (most recent call last): File "<stdin>", line 1, in <module>File "/home/xxx/anaconda3/envs/biogpt/lib/python3.10/site-packages/transformers/modeling_utils.py", line 2560, in from_pretrainedstate_dict = load_state_dict(resolved_archive_file)File "/home/xxx/anaconda3/envs/biogpt/lib/python3.10/site-packages/transformers/modeling_utils.py", line 442, in load_state_dictreturn torch.load(checkpoint_file, map_location="cpu")File "/home/xxx/anaconda3/envs/biogpt/lib/python3.10/site-packages/torch/serialization.py", line 712, in loadreturn _load(opened_zipfile, map_location, pickle_module, **pickle_load_args)File "/home/xxx/anaconda3/envs/biogpt/lib/python3.10/site-packages/torch/serialization.py", line 1049, in _loadresult = unpickler.load()File "/home/xxx/anaconda3/envs/biogpt/lib/python3.10/site-packages/torch/_utils.py", line 138, in _rebuild_tensor_v2tensor = _rebuild_tensor(storage, storage_offset, size, stride)File "/home/xxx/anaconda3/envs/biogpt/lib/python3.10/site-packages/torch/_utils.py", line 133, in _rebuild_tensort = torch.tensor([], dtype=storage.dtype, device=storage._untyped().device)
/home/xxx/anaconda3/envs/biogpt/lib/python3.10/site-packages/torch/_utils.py:133: UserWarning: Failed to initialize NumPy: _ARRAY_API not found (Triggered internally at /opt/conda/conda-bld/pytorch_1656352645774/work/torch/csrc/utils/tensor_numpy.cpp:68.)t = torch.tensor([], dtype=storage.dtype, device=storage._untyped().device)
錯誤原因
- 錯誤日志中的
Failed to initialize NumPy: _ARRAY_API not found表明 PyTorch 正在嘗試調用 NumPy 1.x 的 API,但當前環境是 NumPy 2.0 - 許多科學計算庫(如 PyTorch、HuggingFace Transformers)在發布時是基于 NumPy 1.x 編譯的
- NumPy 2.0 修改了 ABI(應用程序二進制接口),導致舊版編譯的擴展模塊無法直接運行
解決方案
降級到比較低的版本。
pip install "numpy>=1.21,<2" -i https://pypi.tuna.tsinghua.edu.cn/simple
)

底層的實現:)





)

)
)


)

綁定導入表)


