我們繼續來看我們的優先級隊列:
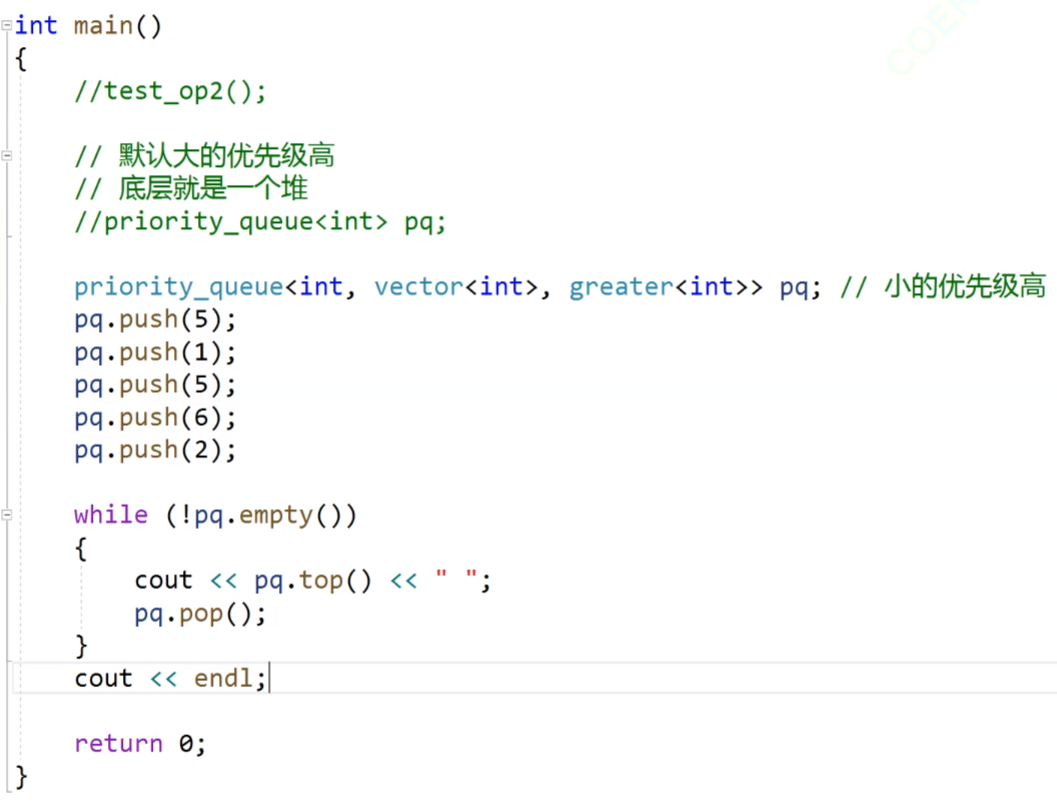
優先級隊列我們說過,他也是一個容器適配器,要依賴我們的容器來存儲數據;
他的第二個參數就是我們的容器,這個容器的默認的缺省值是vector,然后他的第三個參數,我們上節講到,他的top和pop接口都是按照優先級的順序來進行去取的,然后我們的優先級順序默認的是大的優先級比較高,這里有一個比較坑的點,那就是我們如果想讓大的數據優先級高的話,我們可以直接不傳,他的默認的缺省值就是大的優先級高,這個缺省值就是less,然后我們如果想讓小的數據的優先級高的話,我們就傳greater,是的,這里就是剛好相反的。
優先級隊列的實現:
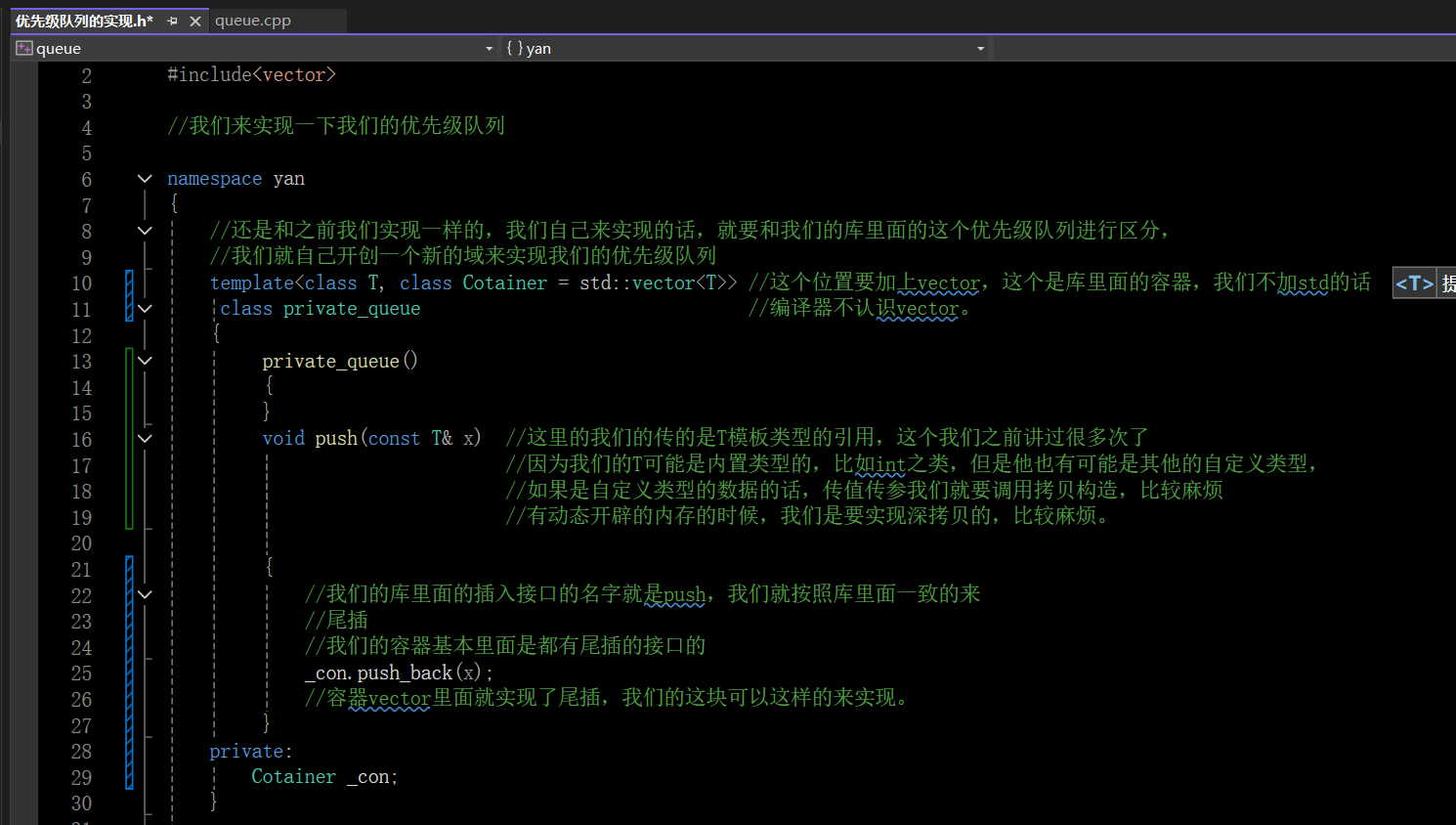
我們來實現我們的優先級隊列的底層,我們看這個push函數,我們的庫里面的插入函數就是push,我們在這里的名字就是push,這個函數表示的其實還是尾插,我們的容器vector里面也是實現了push_back() 函數接口的,我們直接調用;
我們看我們的插入函數的參數,我們這里還是使用了引用來進行,這個東西我們已經說過很多次了。
因為我們不能確定這個模板T到底是什么類型的,他可能是內置類型的,比如int,也可能是其他的自定義的類型,如果是自定義的類型的話,我們的傳值調用就要調用拷貝構造了,如果我們的自定義類型有動態開辟的內存的時候,我們調用拷貝構造就要給這個臨時的變量開辟一段內存空間,深拷貝就比較麻煩。我們這里就選擇傳引用來進行,就不需要調用拷貝構造了。
我們來接著看:
由于堆具有高效維護最大或最小元素的特性,它是實現優先級隊列的一種非常合適的數據結構。
我們的堆刪除數據也是刪除棧頂的數據,優先級最高的進行刪除。(優先級隊列也是先刪除優先級高的)。
優先級隊列的實現都是基于堆的。(我們的這個優先級隊列就是我們的堆二叉樹);

push函數的實現:
Adjustup函數的實現:

當我們的優先級隊列(堆)入數據的時候,這個數據的插入有可能會破壞我們的優先級隊列(堆)自身的結構,如果插入數據以后,我們的大堆的結構被改變,我們就要進行向上調整。
上面的這個數據的插入沒有改變我們的堆的類型,他還是大堆,我們就不進行調整了;
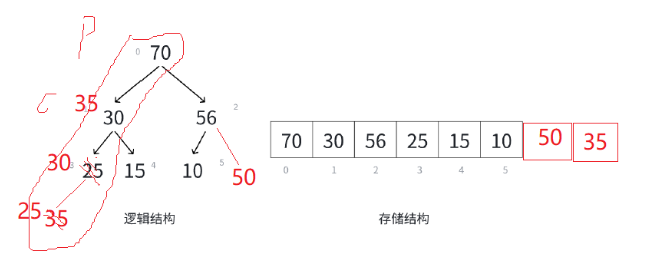
當我們再給他插入一個數據的時候,我們這時候的大堆就不成型了,我們就要進行調整,我們把插入的數據找出來,然后我們求出他的parent結點,然后比較大小,如果child比parent大的時候,我們就交換數據,然后不斷比較:


為什么我們要實現向上調整呢?

一般我們入數據的時候,我們就會用到向上調整。
我們看我們的push函數:

我們插入一個數據以后,我們一般都是插入到最后一個位置,然后我們對這個位置進行向上調整。
我們這里是size()-1,因為我們的堆二叉樹,我們的第一個數據是從下標0開始的。
pop函數的實現:

我們實現我們的刪除函數,想一下我們之前實現堆的時候的刪除數據是怎么刪除的:
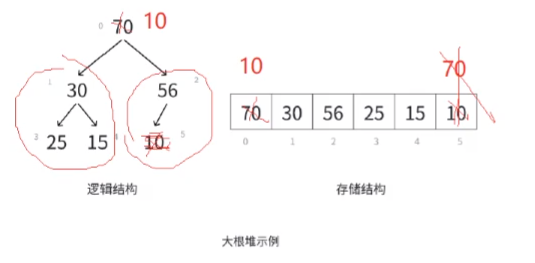
我們交換堆頂和最后一個數據,然后把最后一個數據刪除。這時候我們進行一個向下調整,這時候除了第一個堆頂的數據,其他的位置的數據都是有序的滿足堆的要求。(這個也剛好滿足向下調整的算法的條件)。
然后左右兩個堆都是有序的,我們就比較現在堆頂(10)的左右孩子,因為是大堆,我們就選出比較大的數據,然后我們的堆頂和這個位置進行交換。當然,比較完后我們的這棵發生交換的子樹還要和下面的孩子進行比較,直到最后合適。????????
Adjustdown向下調整的實現:
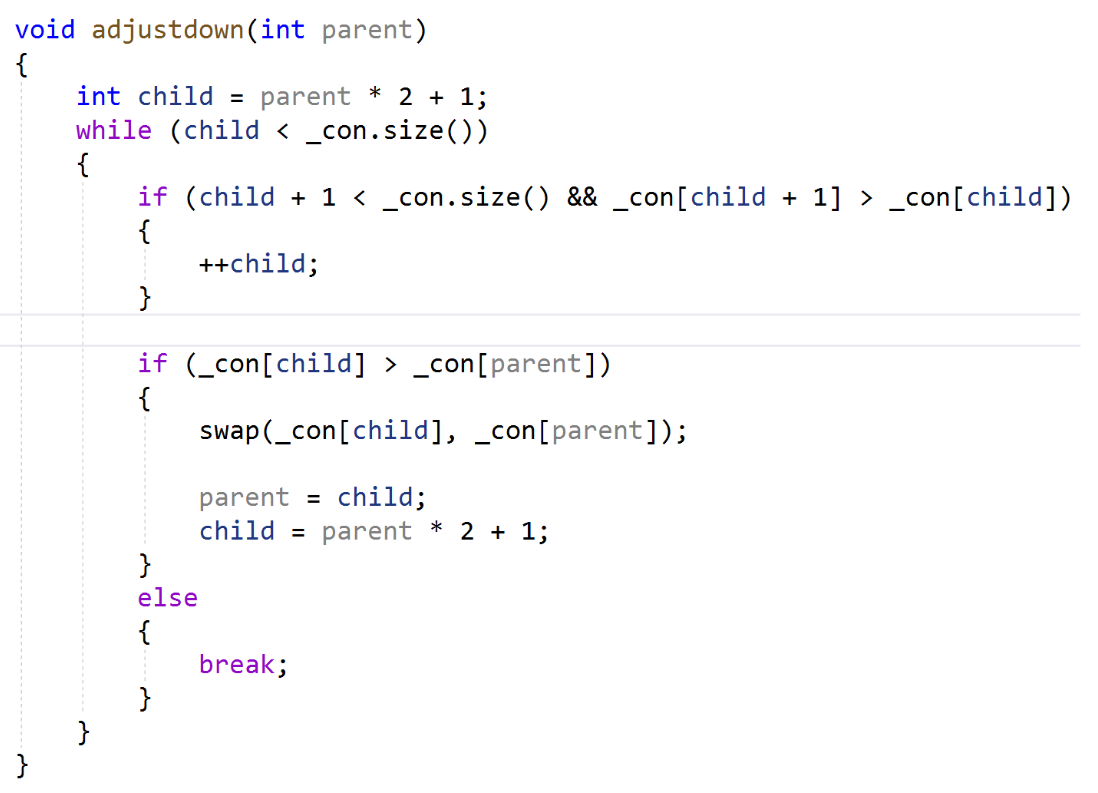
pop函數:


我們的向下調整的前體就是我們是pop數據的時候,我們會需要這個。
綜上所述:
向上調整的前提是向堆中插入新元素,向下調整的前提是從堆中刪除堆頂元素。
仿函數:
我們的仿函數是一個類
在 C++ 里,仿函數是重載了函數調用運算符?()?的類或結構體的對象。這意味著這些對象能夠像函數一樣被調用。

這個就是我們的仿函數,重載了()。
這個類的對象可以像函數一樣的去使用,這個類就是我們的仿函數。
我們來看一個仿函數:

我們在我們的優先級隊列里面的時候,我們的模板參數的第三個參數就是我們的仿函數,我們的仿函數也是一個類:

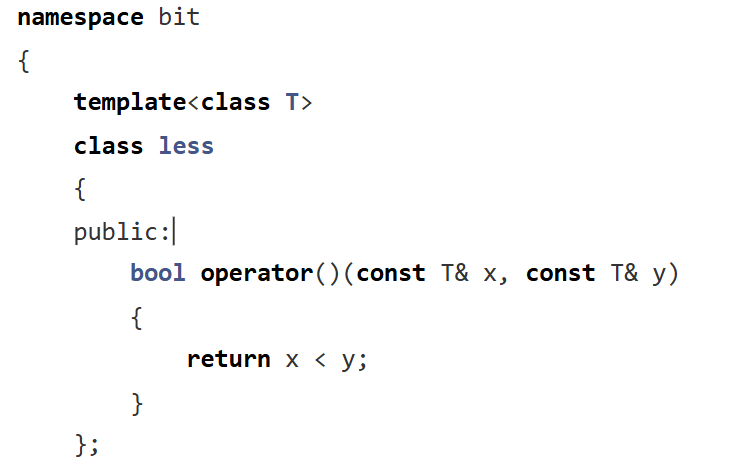
這個就是我們的仿函數。? 這個是less,我們重載的 () 是小于的類型。

這個是我們的greater,我們重載的 () 是大于的類型。
我們這里實現的和我們的庫里面的有所不同,我們的庫里面的,和我們的這里的相反,庫里面的gerater表示小于,less表示大于。
然后當我們的這個大模板下的函數想要使用比較的時候,我們就可以使用仿函數,我們看下面的向下調整的方法,我們里面的條件比較如果是小于的話,我們就可以直接調用仿函數,看他是不是滿足小于的,如果是滿足小于的,返回1,我們的if條件成立。
當然,使用的前提也是,我們要先使用這個類來實例化出一個對象。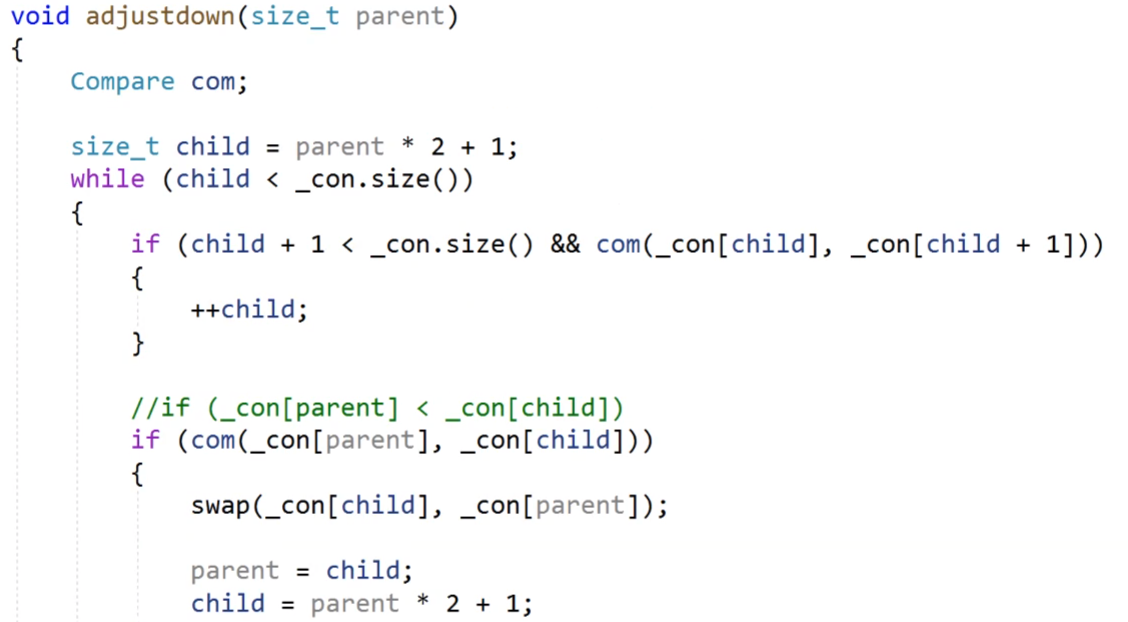
我們的compare是我們的仿函數,我們實例化出一個對象com,然后我們的這個類的對象我們可以直接的當作一個函數去使用。
我們這里調用仿函數可以是實例化出一個對象然后我們調用,這個有名調用是可以的,我們也可以是進行匿名調用。
上面的就是有名調用,匿名調用的話,我們就不實例化出對象,然后把圖中的com替換成less<int>。
我們接著看:
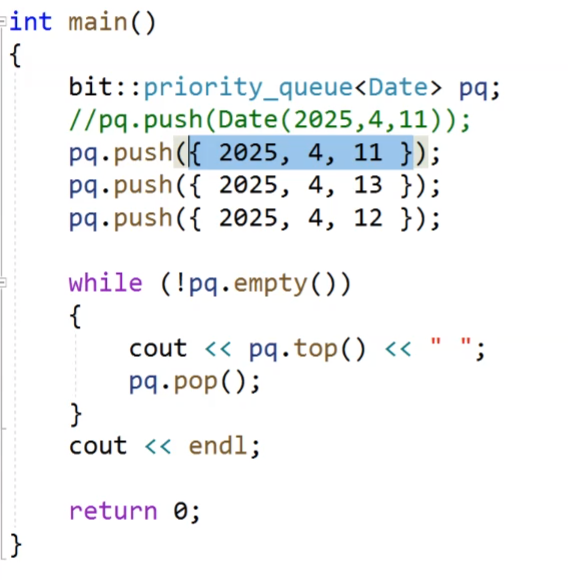
我們看這個,我們說我們push的話,我們可以傳有名對象,也可以傳匿名對象,我們也可以像我們的圖片中的樣子,我們傳我們要初始化的值,進行一個隱式類型轉換,也會生成一個匿名對象。和我們的上面的屏蔽的那個匿名對象的效果是一樣的。
我們接著來看我們的仿函數:

我們看一下這個代碼,我們的這個優先級隊列,我們的第一個參數為我們的日期類的地址,然后后面的兩個參數不傳,我們的第二個參數的缺省值為vector,第三個參數缺省值為less,然后我們進行打印,但是打印出來的結果不是我們想要的結果。
我們這次的模板T不是int,是我們的日期類的指針,我們進行push尾插,然后我們的new的返回值是我們的開辟的內存的指針,我們把指針插入到我們的數組里面,然后比較的時候,我們比較的就是我們的地址,我們的new開辟的內存的地址是隨機的,所以我們在這里比較出來的結果就是無意義的。
那怎么辦呢?
我們就可以利用我們的仿函數,我們這里的優先級隊列我們的第三個仿函數我們是沒有傳的,所以這時候我們的里面就是缺省值less,這樣的結果就是比較地址的大小,但是我們可以修改我們的仿函數,我們這里的仿函數是不期望使用指針來進行比較的,我們期望的是使用指針解引用后的數據來比較。
之前我們的仿函數:
我們就設置一個新的仿函數來解決我們的問題:
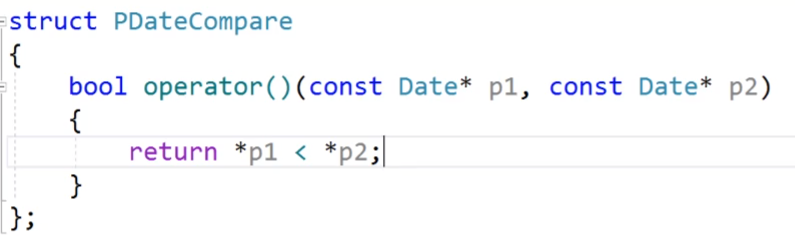
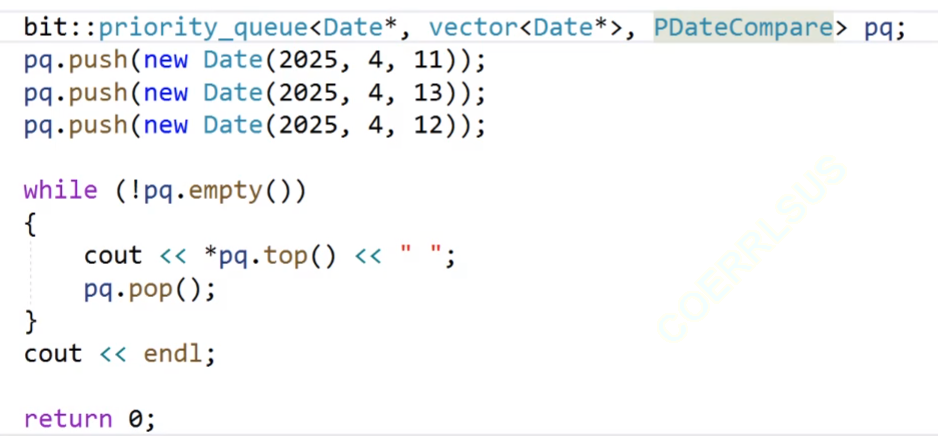
這時候得到的就是我們要的;(按照里面的數據來進行比較)。
還有:
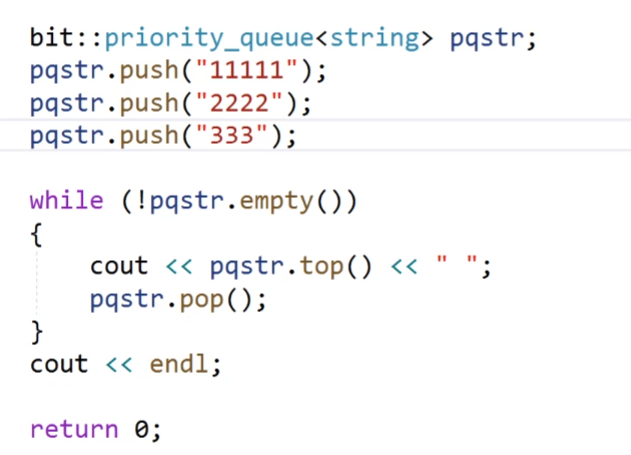
我們看這個代碼,這個代碼我們的優先級隊列傳過去的容器是string,然后我們的后面的兩個函數參數都是缺省值,我們的最后一個參數仿函數就是less。
我們然后尾插三個字符串,然后不斷的取然后pop,![]() 這個就是最后的結果,這個就是按照他的大小進行排列的。
這個就是最后的結果,這個就是按照他的大小進行排列的。
但是我們現在不想按照順序的給他進行排列了,我們想按照每個字符串的長度來進行排列;
我們這時候就可以使用仿函數來調整我們的比較邏輯;


我們看,我們自己來實現一個仿函數,來滿足我們的要求,我們比較兩個string的長度。
如果默認的函數不符合我們的邏輯,我們就自己來實現一個仿函數。





)

)
)


)

綁定導入表)





