Kafka簡介
Kafka最初由Linkedin公司開發的分布式、分區的、多副本的、多訂閱者的消息系統。它提供了類似于JMS的特性,但是在設計實現上完全不同,此外它并不是JMS規范的實現。kafka對消息保存是根據Topic進行歸類,發送消息者稱為Producer;消息接受者稱為Consumer;此外kafka集群有多個kafka實例組成,每個實例(server)稱為broker。無論是kafka集群,還是producer和consumer都依賴于zookeeper來保證系統可用性集群保存一些meta信息(kafka的0.8版本之后,producer不在依賴zookeeper保存meta信息,而是producer自己保存meta信息)。本文不打算對Apache Kafka的原理和實現進行介紹,而在編程的角度上介紹如何使用Apache Kafka。我們分別介紹如何編寫Producer、Consumer以及Partitioner等。
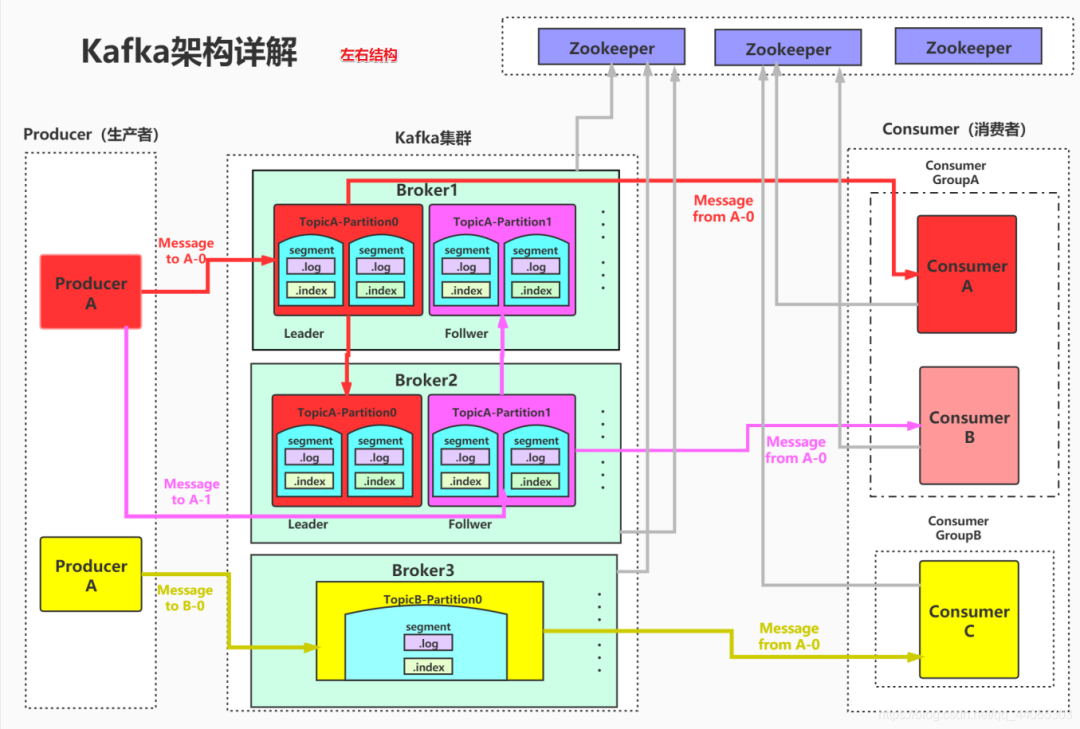
Producer發送的消息是如何定位到具體的broker
- 生產者初始化:Producer在初始化時會加載配置參數,并開啟網絡線程準備發送消息。
- 攔截器邏輯:Producer可以設置攔截器來預處理消息,例如,修改或者豐富消息內容。
- 序列化:Producer將處理后的消息key/value進行序列化,以便在網絡上傳輸。
- 分區策略:Producer會根據分區策略選擇一個合適的分區,這個分區策略可以是輪詢、隨機或者根據key的哈希值等。
- 選擇Broker:Producer并不直接將消息發送到指定的Broker,而是將消息發送到所選分區的leader副本所在的Broker。如果一個主題有多個分區,這些分區會均勻分布在集群中的Broker上。每個分區都有一個leader副本,Producer總是將消息發送到leader副本,然后由leader副本負責同步到follower副本。
- 發送模式:Producer發送消息的模式主要有三種:發后即忘(不關心結果),同步發送(等待結果),以及異步發送(通過Future對象跟蹤狀態)。
- 緩沖和批量發送:為了提高效率,Producer會先將消息收集到一個批次中,然后再一次性發送到Broker。
- 可靠性配置:Producer可以通過設置
request.required.acks參數來控制消息的可靠性級別,例如,設置為"all"時,需要所有in-sync replicas都確認接收后才認為消息發送成功。 - 失敗重試:如果請求失敗,Producer會根據配置的
retries參數來決定是否重試發送消息。
Kafka的Producer通過一系列步驟來確定消息的發送目標,其中分區策略和leader副本的選擇是關鍵步驟,確保了消息能夠正確地發送到相應的Broker。同時,通過合理的配置和重試機制,Producer能夠保證消息的可靠性和系統的健壯性。
Kafka存儲文件長什么樣
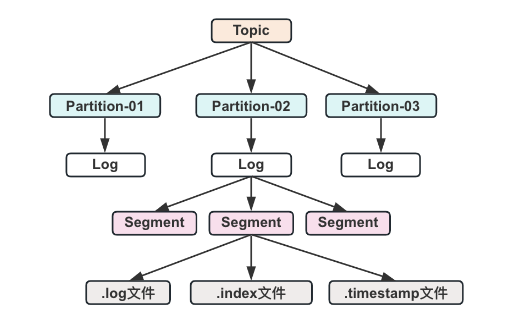
在kafka集群中,每個broker(一個kafka實例稱為一個broker)中有多個topic,topic數量可以自己設定。在每個topic中又有多個partition,每個partition為一個分區。kafka的分區有自己的命名的規則,它的命名規則為topic的名稱+有序序號,這個序號從0開始依次增加。
在每個partition中有可以分為多個segment file。當生產者往partition中存儲數據時,內存中存不下了,就會往segment file里面存儲。kafka默認每個segment file的大小是500M,在存儲數據時,會先生成一個segment file,當這個segment file到500M之后,再生成第二個segment file 以此類推。每個segment file對應兩個文件,分別是以.log結尾的數據文件和以.index結尾的索引文件。
具體來說,Kafka中的每個分區(Partition)由一個或多個Segment組成。每個Segment實際上是磁盤上的一個目錄,這個目錄下面會包含幾個特定的文件:
- .log文件:這是真正存儲消息數據的地方。每個Segment有一個對應的.log文件,它存儲了屬于這個Segment的所有消息。
- .index文件:索引文件,用于快速定位到.log文件中的具體消息。通過.index文件可以高效地查找消息所在的.log文件位置。
- .timeindex文件(可選):如果啟用了時間戳索引,還會有這個文件。它用于按時間戳高效檢索消息。
此外,Segment作為Kafka中數據組織的基本單位,設計成固定大小,這樣做可以方便地進行數據的清理和壓縮,同時保證性能。當一個Segment文件寫滿后,Kafka會自動創建一個新的Segment來繼續存儲數據。舊的Segment文件在滿足一定條件(如被消費且達到一定的保留期)后會被刪除,釋放磁盤空間。
每個segment file也有自己的命名規則,每個名字有20個字符,不夠用0填充。每個名字從0開始命名,下一個segment file文件的名字就是上一個segment file中最后一條消息的索引值。在.index文件中,存儲的是key-value格式的,key代表在.log中按順序開始第條消息,value代表該消息的位置偏移。但是在.index中不是對每條消息都做記錄,它是每隔一些消息記錄一次,避免占用太多內存。即使消息不在index記錄中在已有的記錄中查找,范圍也大大縮小了。?
Consumer如何消費數據
Kafka中的Consumer通過以下步驟來消費數據:
- 創建消費者實例:需要創建一個消費者實例,并指定一些關鍵配置,如消費者所屬的群組、Topic名稱以及與服務器通信的相關設置。
- 訂閱主題:創建好的消費者實例需要訂閱一個或多個主題,以便開始接收消息。
- 拉取數據:與一些消息系統采用的推送模式不同,Kafka的消費者采用的是“拉取”模式。這意味著消費者需要主動從Broker拉取數據,而不是等待Broker將數據推送過來。這種模式使得消費者可以根據自身處理能力來控制數據的獲取速度。
- 長輪詢機制:在沒有新消息可消費時,消費者會使用長輪詢機制等待新消息到達。消費者調用
poll()方法時可以設置超時時間(timeout),這樣如果沒有新消息,消費者會在等待一段時間后返回,并在下次調用poll()時繼續嘗試獲取新消息。 - 提交偏移量:消費者在消費過程中會跟蹤每個分區的消費進度,即偏移量(offset)。當消費者處理完消息后,它會提交當前的偏移量到Broker,以便在服務重啟或故障恢復的情況下可以從準確的位置繼續消費數據。
- 故障恢復:如果消費者發生宕機等故障,由于Kafka會持久化消費者的偏移量信息,消費者可以在恢復后繼續從之前提交的偏移量處消費數據,確保不丟失任何消息。
- 消費者群組:Kafka支持多個消費者組成一個群組共同消費一個主題。在一個群組內,每個消費者會被分配不同的分區來消費,從而實現負載均衡和橫向伸縮。同一個分區不能被一個群組內的多個消費者同時消費。
- 數據處理:消費者在拉取到數據后,可以根據自己的業務邏輯對數據進行處理,比如進行實時流處理或者存儲到數據庫中進行離線分析。
綜上所述,Kafka的Consumer通過上述流程高效地從Broker拉取并處理數據,這些特性使得Kafka能夠在高吞吐量和可擴展性方面表現出色,適合處理大規模數據流的場景。
Kafka中的過期數據處理機制
?kafka作為一個消息中間件,是需要定期處理數據的,否則磁盤就爆了。
處理的機制
- 根據數據的時間長短進行清理,例如數據在磁盤中超過多久會被清理(默認是168個小時)?
- 根據文件大小的方式給進行清理,例如數據大小超過多大時,刪除數據(大小是按照每個partition的大小來界定的)。
刪除過期的日志的方式
Kafka通過日志清理機制來刪除過期的日志,主要依賴于兩個配置參數來實現這一功能:
- 日志保留時間:通過設置
log.retention.hours參數,可以指定日志文件的保留時間。當日志文件的保存時間超過這個設定值時,這些文件將被刪除。 - 日志清理策略:Kafka支持兩種日志清理策略,分別是
delete和compact。delete策略會根據數據的保存時間或日志的最大大小來進行刪除。而compact策略則是根據消息中的key來進行刪除操作,通常用于特定類型的主題,如__consumer_offsets。
此外,在Kafka 0.9.0及更高版本中,日志清理功能默認是開啟的(log.cleaner.enable默認為true)。這意味著Kafka會自動運行清理線程來執行定時清理任務。
綜上所述,Kafka通過結合保留時間和清理策略的配置,實現了對過期日志的有效管理。這些機制確保了系統資源的合理利用,同時避免了因日志無限增長而導致的潛在問題

)
)
Python數據分析體系--九五小龐)



Qt窗口)
求解23個基準函數)



:電解電容低阻如何選擇詳解)


)
)


