一、概述
1、是什么
? ? 是單模態“小”語言模型,是一個“Bidirectional Encoder Representations fromTransformers”的縮寫,是一個語言預訓練模型,通過隨機掩蓋一些詞,然后預測這些被遮蓋的詞來訓練雙向語言模型(編碼器結構)。可以用于句子分類、詞性分類等下游任務,本身旨在提供一個預訓練的基礎權重。
2、亮點
? ? 文章中總結為三點:
? ? *?展示了雙向預訓練對語言表示的重要性。
? ? *?預訓練的特征表示對特定任務降低了精心設計架構的需求。
? ? *?BERT 提高了 11 個 NLP 任務的最新指標。
PS
? ? * base版本整體結構和OpenAI的GPT是相同的,只是掩碼機制不同,甚至訓練數據和策略也盡可能可GPT相同來做對比,并驗證了在下游任務的高效性。large是進行了模型縮放。
?? ?* 但是如今2024年還是Open AI 的GPT這種純解碼器一統天下,并且后續針對bert的改進,反而移除一些本文的tick,比如NSP任務等。
? ? * 原版論文還是建議看看,因為本文是提供了一個預訓練模型,然后可以用于各種下游任務(并且文章解釋了怎么處理數據和改動模型),并且也簡要介紹了對應的下游任務,可以對NLP領域有個很好的認識。
二、模型
? ? 1、模型結構
? ??? ?輸入需要進行多種embedding處理,模型整體就是標準的transformer編碼器,只不過針對不同的任務出入輸出頭稍有改動:
? ? 1)預訓練任務:兩個loss,分別是預測掩碼token和預測兩個句子是不是連貫的。也就是后面的Mask LM 和NSP任務。文中訓練了base 和 large兩個版本。
? ? 2)下游任務:主要分為四大類,兩個句子的關系分類、單句分類(比如情感分類)、問答(不是生成模型,所以答案是提供的文本中的一個片段,預測起止點)、句子內次分類(比如實體識別)。?? ?
? ? 輸入如下。針對不同的任務,BERT模型的輸入可以是單句或者句對。對于每一個輸入的Token,它的表征由其對應的詞表征(Token Embedding)、段表征(Segment Embedding)和位置表征(Position Embedding)相加產生。其中BERT的分詞是“Case-preserving WordPiece model”,它在分詞的同時保留了原始文本的大小寫信息。
?? ?
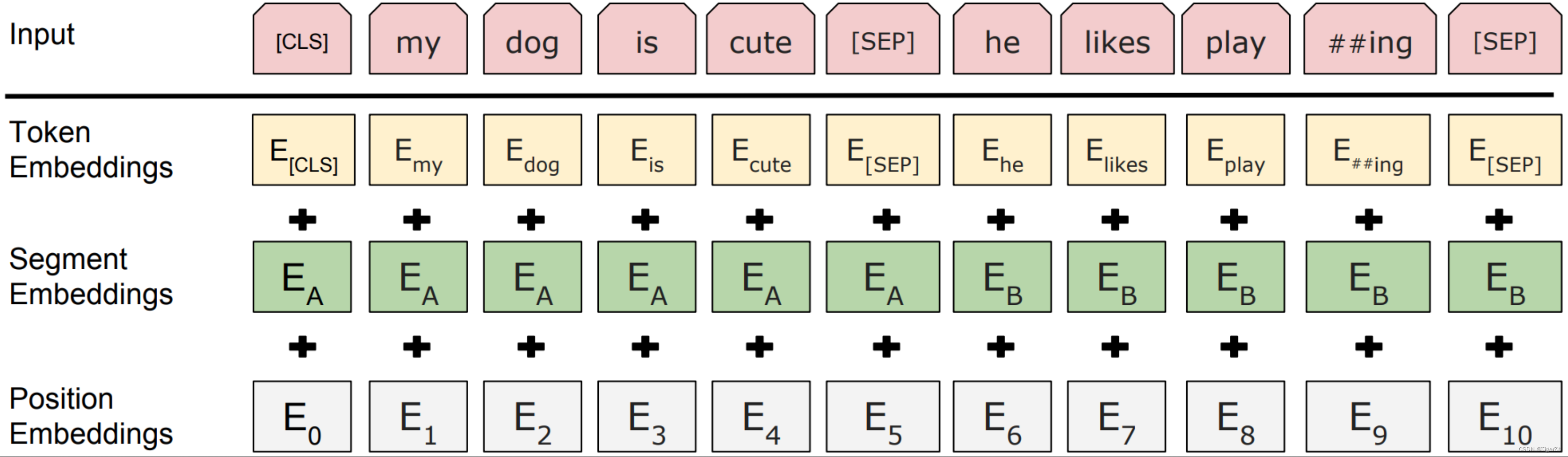
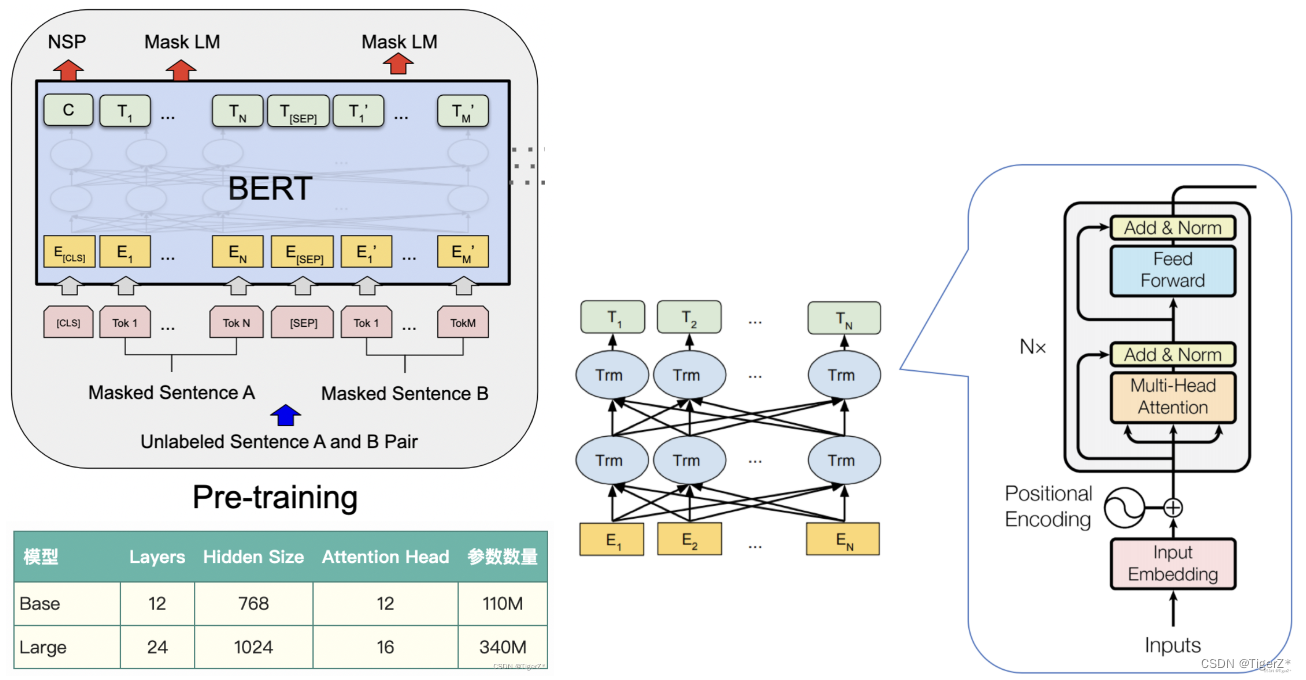
? ? 預訓練整體對應的網絡結構如下:
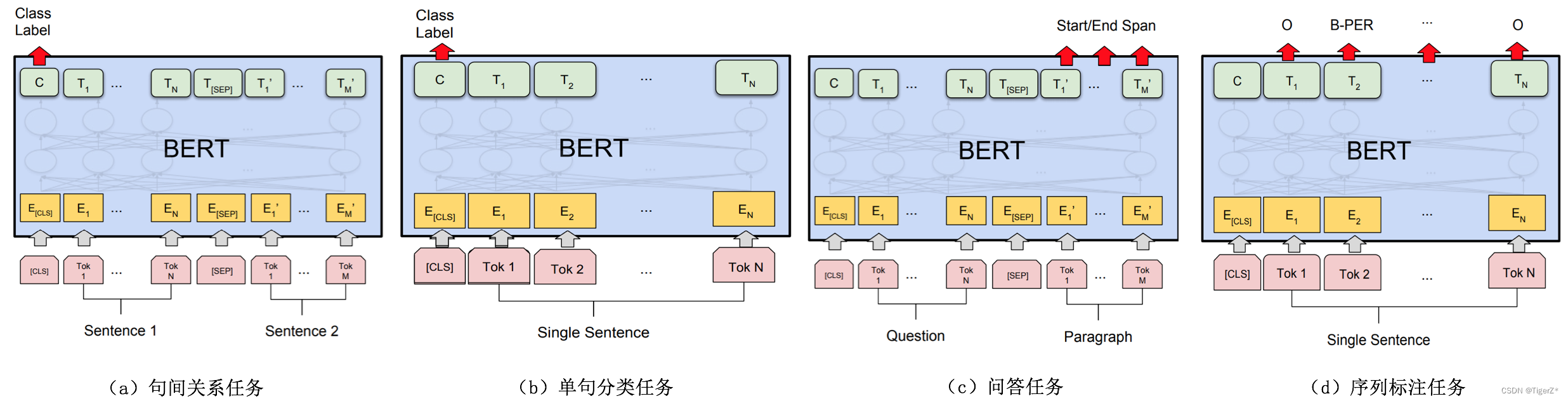
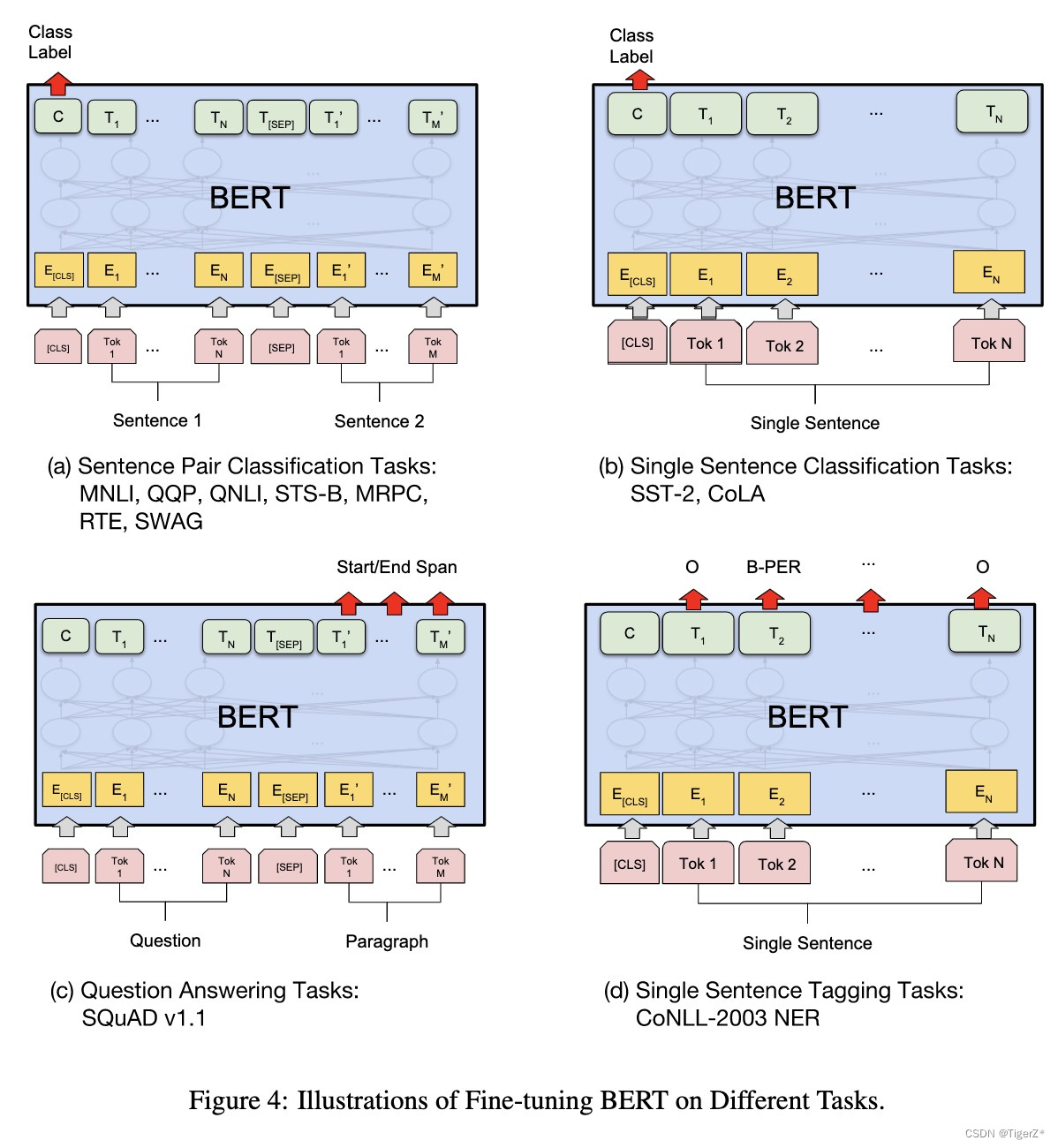
? ? 不同的下游任務的模型結構如下圖:
? ? 下游任務對應到數據集
? ? 2、模型亮點
? ? 雙向注意力訓練的解碼器,并且有單詞和句子兩個任務。
? ? PS
? ? 可惜現在GPT的decoder 一統天下了。
三、數據
? ? 1、數據標簽
?? ?對于英文模型,使用了Wordpiece模型來產生Subword從而減小詞表規模;對于中文模型,直接訓練基于字的模型。 具體因為涉及到預訓練和不同類型的下游任務,這里稍微有點復雜,一條一條梳理。
?? ?預訓練目標:BERT預訓練過程包含兩個不同的預訓練任務,分別是Masked Language Model和Next Sentence Prediction任務。
? ? 下游任務:分為句子分類、token分類。
? ? 1-1)Masked Language Model任務
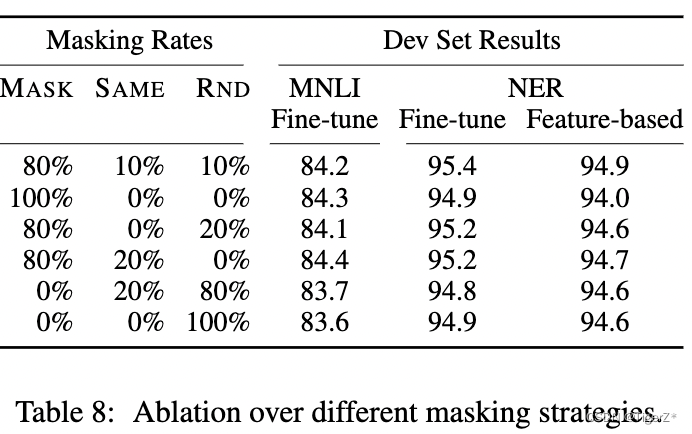
?? ?就是預測被mask掉的詞,文章提出一種mask策略(這個過程發生在WordPiece tokenization之后,而且對所有token一視同仁,后面有對應的消融實驗):在一個batch 內先隨機選取15%的單詞作為mask候選,然后對這15%單詞進行二次抽樣,其中80%需要被替換成[MASK]的詞進行替換,10%的隨機替換為其他詞,10%保留原詞。原因是:在微調時[MASK]總是不可見,會造成預訓練和微調時的不一致。論文中的例子如下:
?? ?

? ? 1-2)Next Sentence Prediction任務
?? ?模型輸入需要附加一個起始Token,記為[CLS],對應最終的Hidden State(即Transformer的輸出)可以用來表征整個句子,用于下游的分類任務。
?? ?模型能夠處理句間關系。為區別兩個句子,用一個特殊標記符[SEP]進行分隔,另外針對不同的句子,將學習到的Segment Embeddings 加到每個Token的Embedding上。對于單句輸入,只有一種Segment Embedding;對于句對輸入,會有兩種Segment Embedding。
? ? 論文中的例子如下,構造方法是隨機構造50%是成對的句子,50%不是成對的句子,并且也要保證整個句子長度小于512個token。和上面的mask策略是共同作用的。
?? ?
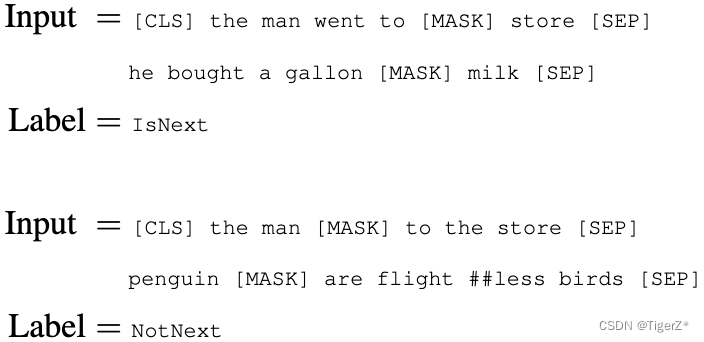
? ? 2-1)GLUE 句子分類下游任務
? ? 可以為單個句子或者句子對。
?? ?輸入和預訓練一樣,有cls、sep token,沒有Mask。
? ? 輸出使用cls token對應的最后一個隱層的向量作為句子的整體表示,僅僅引入一個全連接層,映射到分類類別數,計算標準的softmax 分類損失。
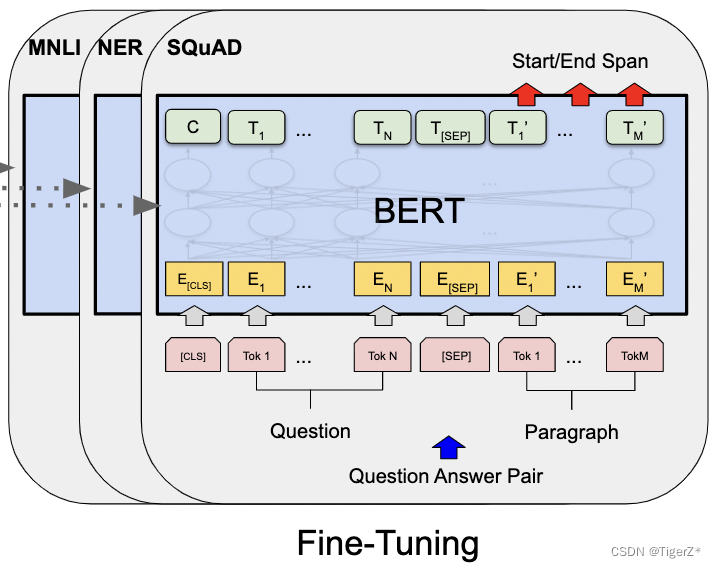
? ? 2-2)SQuAD v1.1
? ? 其實就是給定問題,在指定段落里面找答案的起止點,不需要改寫答案。這里確實有點繞,所以再重復貼一下模型圖。這里輸入如下圖,比較好理解。輸出增加了兩個可學習的verctor(就是兩個變量分別稱為S、E),然后對每個輸出單詞做點乘,計算為起點的概率(終點同理):![]() 。然后起點到終點的整個段落的概率定義如下:
。然后起點到終點的整個段落的概率定義如下:![]() 。
。
?? ?2-3)SQuAD v2.0
?? ?我們將沒有答案的問題視為在 [CLS] 標記處具有開始和結束的答案跨度。預測的時候沒有對應答案得分Snull =S·C + E·C,有對應的答案的得分最大值![]() ,然后當
,然后當![]() ,閾值t是在驗證集使F1最大調節出來的。
,閾值t是在驗證集使F1最大調節出來的。
?? ?2-4)SWAG
? ? 本身是多選,這里將問題分別匹配一個答案,構成N個文本對,然后對每個文本對單獨像句子對分類任務一樣,在cls token上訓練分類器。? ??
? ? 2、數據構成
? ? 預訓練
?? ?為了和GPT作對比,數據等也盡可能相同:BERT使用BooksCorpus (800M words)、Wikipedia (2,500M words),其中GPT使用的僅僅為BooksCorpus (800M words)。
? ? 下游任務
? ? MNLI:Multi-Genre Natural Language Inference,兩個句子的蘊含分類任務。給定一對句子,目標是預測第二個句子是否是相對于第一個句子的蘊涵、矛盾或中性。
? ? QQP:Quora Question Pairs,兩個句子分類任務。目標是確定 Quora (果殼問答網站,類似知乎)上提出的兩個問題在語義上是否等價。
? ? QNLI:Question Natural Language Inference,標準的問答任務。被轉換為二元分類任務,正例是(問題、句子)對,包含正確答案,負例是來自同一段落的(問題、句子),不包含答案。
? ? SST-2:Stanford Sentiment Treebank,二元單句分類任務,包括從電影評論中提取的句子及其情感的注釋。
? ? CoLA:The Corpus of Linguistic Acceptability,二元單句分類任務,其目標是預測英語句子在語法上是否“可接受”。
?? ?STS-B:The Semantic Textual Similarity Benchmark,一組從新聞標題和其他來源中提取的句子對。他們用從 1 到 5 的分數進行注釋,表示兩個句子在語義含義方面的相似程度。
?? ?MRPC:Microsoft Research Paraphrase Corpus,從在線新聞源中自動提取的句子對組成,人工注釋對中的句子在語義上是否等價。
?? ?WNLI Winograd NLI:小型自然語言推理數據集,GLUE 網頁指出,該數據集的構建存在問題。
?? ?RTE:Recognizing Textual Entailment,類似于 MNLI 的二元蘊涵任務,但訓練數據要少得多。
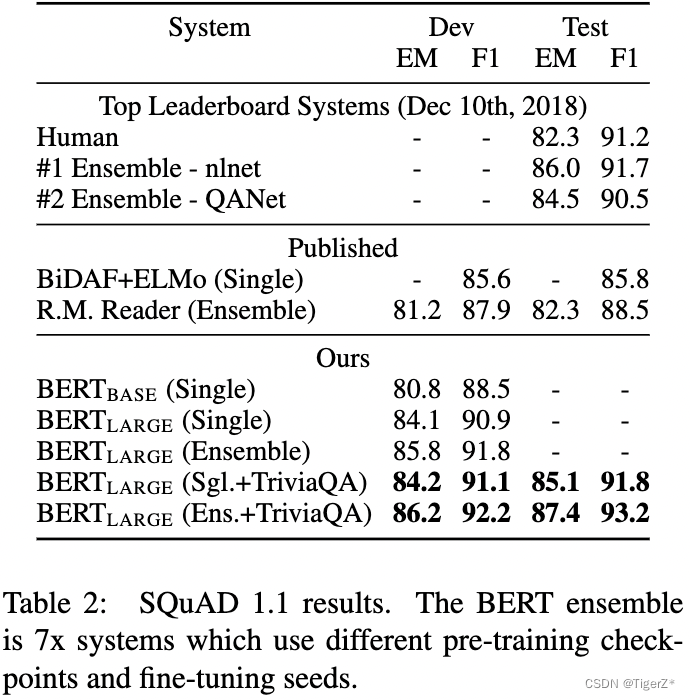
?? ?SQuAD v1.1:10w個眾包問題/答案對的集合。給定一個來自維基百科的段落和對應的問題,任務是預測答案在文章中的跨度(也就是起止點)。
?? ?SQuAD v2.0:對比V1.1,還有可能對應的段落沒有問題的答案。
?? ?SWAG:Situations With Adversarial Generations,包含 113k 個句子對,用于評估常識推理。
? ? 3、數據清洗
? ? 可能都是開源數據,并且為了保持和Open AI相同,文章并沒有提到如何清洗這兩個數據源。
四、策略
? ? 1、訓練過程
? ? 預訓練
? ? 單階段訓練,訓練所有網絡參數,兩個任務的loss取平均。值得注意的一個預訓練加速細節(原理是transformer的自注意力隨著序列長度二次方增加運算量):使用序列長度為 128 訓練90% 的Step,然后使用 512 序列長度訓練其余10% 來學習位置嵌入。
? ? 訓練超參數如下:
? ? *bs = 256、sequence length = 512、Step = 100W,相當于:128,000 token/batch、訓練了40個epoch。
? ? *學習率為 1e-4 的 Adam,β1 = 0.9,β2 = 0.999,L2 權重衰減為 0.01,學習率在前 10,000 步預熱,學習率的線性衰減。
? ? *在所有層上使用 0.1 的 dropout 概率。
? ? *激活函數和GPT相同為gelu。
? ? *訓練損失是平均掩碼 LM 似然和平均下一句預測似然的總和。
? ? *BERTBASE 的訓練是在4 cloud Pod (總共 16 個 TPU 芯片),LARGE 的訓練是在 16 個 Cloud TPU pod(總共 64 個 TPU 芯片)上進行的。均需要 4 天完成訓練。
? ? 下游任務Finetune整體總結
?? ?如模型結構部分,應用與不同的下游任務(不同下游任務都略有區別,大的數據集,比如10W+樣本的對超參數選擇不敏感),超參數整體和預訓練相同,但是batch size、學習率、訓練epoch不同,如下:
? ? *batch size 選擇16 或32.
? ? *Learning rate (Adam): 5e-5, 3e-5, 2e-5。
? ? *epochs數: 2, 3, 4
?? ?下游任務Finetune-GLUE句子分類
?? ?主要在模型輸出的增加一個分類層,對應輸入的cls token。batch size 32 訓練3 個epoch,學習率嘗試5e-5, 4e-5, 3e-5, 2e-5并選擇驗證集效果最好的。
?? ??注意:這里發現BERT large版本訓練不穩定,采取的策略是隨機多訓練幾個版本,然后選擇驗證集上效果好的,這里的隨機包含:數據隨機shuffle和分類層隨機初始化。
?? ?下游任務SQuAD v1.1句子分類
?? ?batch size 32 訓練3 個epoch,學習率5e-5。
?? ?下游任務SQuAD v2.0句子分類
? ???batch size 48 訓練2 個epoch,學習率5e-5。
?? ?下游任務SWAG句子分類
?? ?batch size 16 訓練3 個epoch,學習率2e-5。
? ? 2、推理過程
? ? 暫無
五、結果
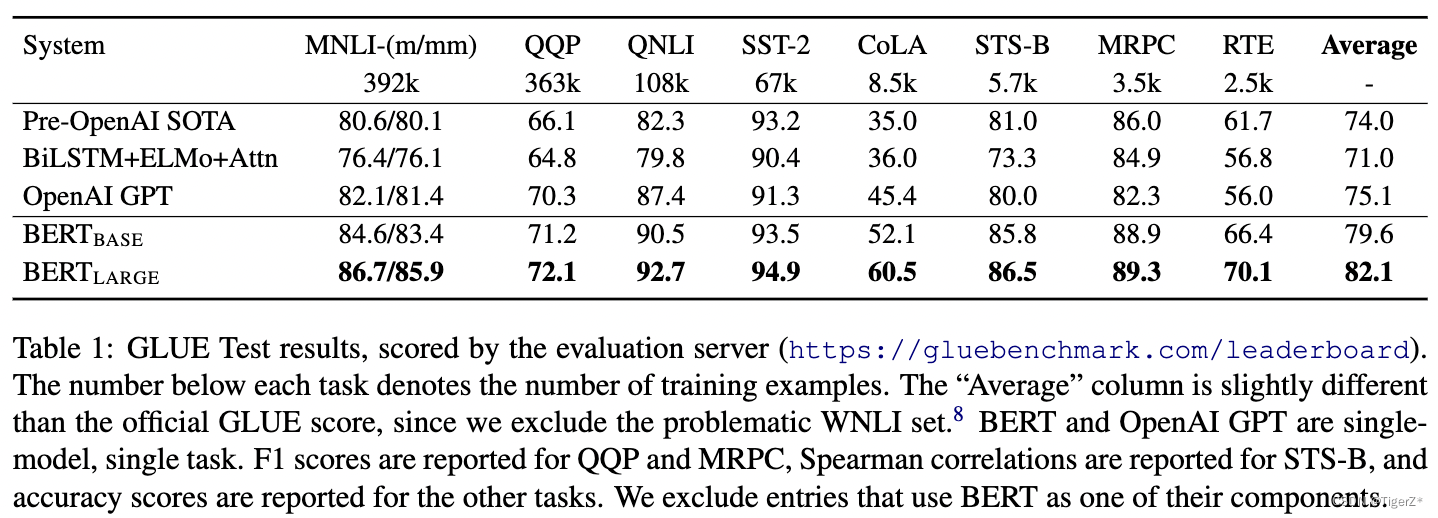
1、多維度對比。
? ? 四個下游任務,分別見四個表。
?? ?GLUE:發現large版本結果都比base版本好(包含哪些訓練數據很少的場景),并且好于Open AI。
?? ?
? ??
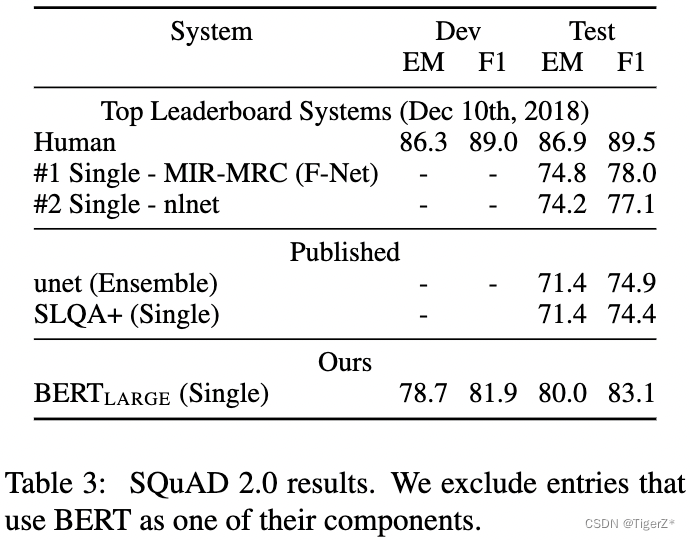

2、消融實驗
訓練任務
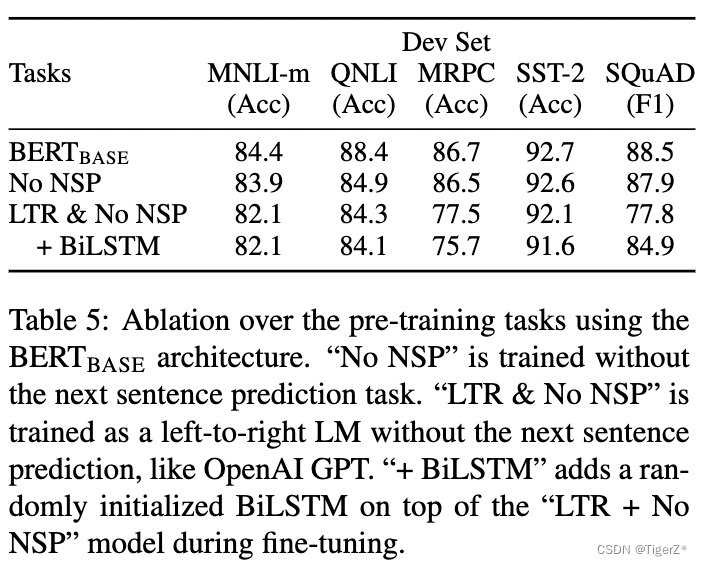
?? ?涉及:有無預測下一個句子任務(NSP)、MLM對比LTR任務(預測中間詞和從左預測右面即GPT)。他的結果顯示預測下一個句子能提升性能,MLM好于LTR。(PS:然而后面bert的改進去掉了NSP任務,GPT系列數據上來效果強悍。所以這些經驗真的會隨著數據和模型規模上來反而成為阻礙。)
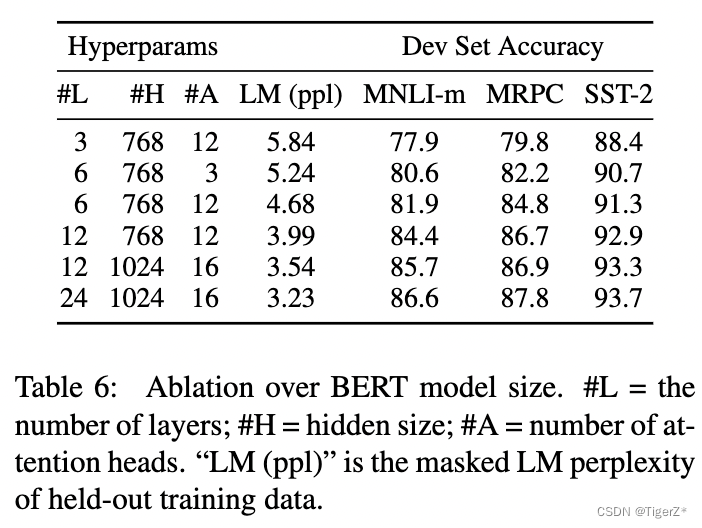
模型大小
?? ?除了模型的層數、隱層維度、head 頭數外,其余訓練超參一致。這里作者證明隨著模型規模的提升,下游任務的性能也提升,即使下游任務數據很少也可以finetune(接一個分類頭,并且bert的參數也更新),然后獲得穩定提升(隨著模型規模)。這里作者特別提到之前有人做實驗,證明模型規模不能太大,不然反而性能會降低這里是通過特征的方式,沒有finetune。
?? ?PS:這里感覺有點后面GPT系列對齊的苗頭了。
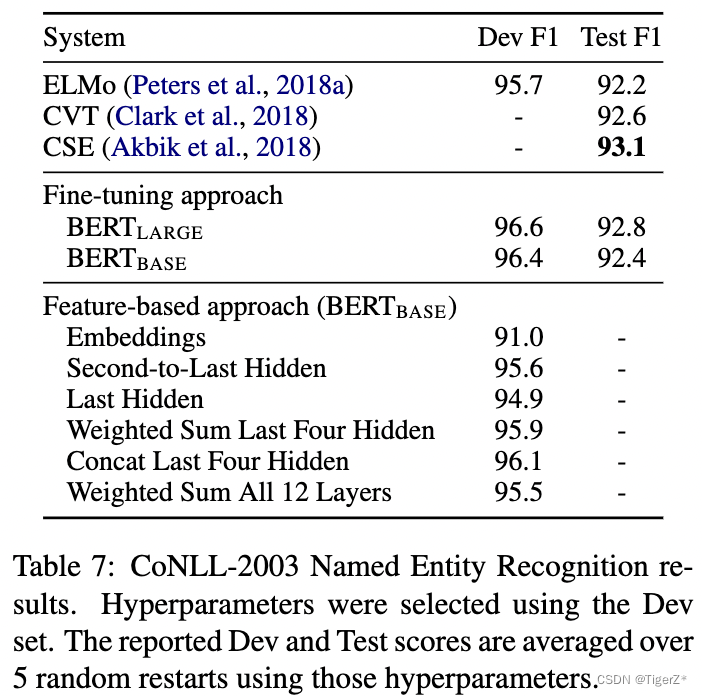
基于特征
?? ?這里和圖像領域不太一樣哈,對應CLIP里面的叫Liner prob策略,也就是凍結bert參數,然后對bert的輸出再訓練一個分類器。而該論文的finetune就是全部bert跟著分類器更新參數。對比結果如下,證明bert的特征也挺好(當然低于finetune)。
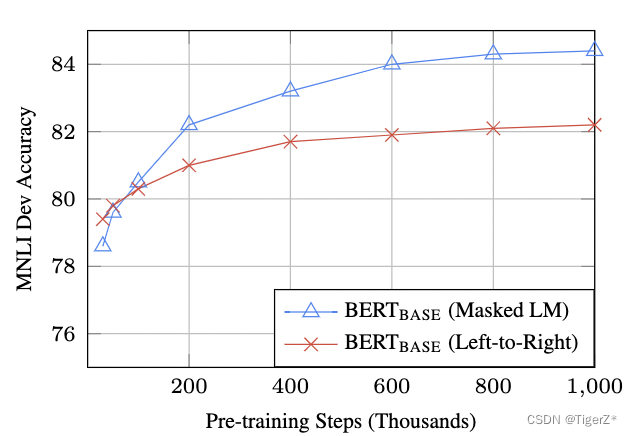
訓練時長(Step數)
?? ?*與 500k 步相比,BERTBASE 在 1M 步上訓練時在 MNLI 上實現了幾乎 1.0% 的額外準確度。
?? ?*MLM 模型的收斂速度略慢于 LTR 模型。然而,就絕對準確性而言,MLM 模型幾乎很快就開始優于 LTR 模型。
不同的mask策略
? ? 需要注意,對于基于特征的方法,將 BERT 的最后 4 層作為特征連接起來,這在第 5.3 節中被證明是最好的方法。其實差距不是特別大。
?? ?
六、使用方法
?? ?見git和上面的下游任務模型結構介紹部分,對不同下游任務不同。
七、待解決
?論文提到的缺點
?? ?由于每個Batch中只有15%的詞會被預測,因此模型的收斂速度比起單向的語言模型會慢,訓練花費的時間會更長。(作者認為從提升收益的角度來看,付出的代價是值得的。)
?改進算法
?? ?并且很多原始認為很有用的tick已經不再使用,比如預測句子任務。BERT的主要創新在于它的雙向訓練結構,它能夠在預訓練階段同時考慮上下文中的左側和右側信息。自從BERT發布以來,許多研究者和工程師都在嘗試改進這個模型。以下是一些BERT改進的論文總結:
1、RoBERTa(A Robustly Optimized BERT Pretraining Approach)
發現:BERT可能由于其訓練過程沒有被充分優化而受到限制。
改進:更長時間的訓練、更大的數據集、更大的batch size、不使用Next Sentence Prediction(NSP)任務。
結果:在多個基準測試上取得了比原始BERT更好的結果。
2、ALBERT(A Lite BERT for Self-supervised Learning of Language Representations)
發現:BERT模型非常龐大,需要大量的內存和計算資源。
改進:參數共享、降低模型大小的同時保持性能。
結果:減小了模型的內存占用,同時在某些任務上保持或超越了BERT的性能。
3、DistilBERT(Distilling the Knowledge in a Neural Network)
發現:BERT模型過于龐大,對于某些應用來說不夠高效。
改進:利用知識蒸餾技術,將BERT的知識轉移到更小的模型。
結果:模型大小減少了40%,速度提升了60%,同時保持了97%的BERT性能。
4、XLNet(Generalized Autoregressive Pretraining for Language Understanding)
發現:BERT的雙向上下文理解能力強,但是受限于其掩蔽語言模型(MLM)的預訓練方式。
改進:結合了自回歸語言模型和BERT的優點,提出了置換語言模型(PLM)。
結果:在多項NLP任務上超越了BERT和GPT的性能。
5、ERNIE(Enhanced Representation through kNowledge Integration)
發現:BERT沒有充分利用外部知識,如實體、短語和語義關系等。
改進:整合了外部知識,通過實體掩蔽和短語掩蔽來增強語言表示。
結果:在特定任務上,如情感分析和實體識別,性能得到了顯著提升。
6、SpanBERT(SpanBERT: Improving Pre-training by Representing and Predicting Spans)
發現:BERT的單個詞掩蔽可能不足以捕捉到更長的依賴關系。
改進:專注于跨度的預測而不是單個詞的預測,以更好地表示和預測文本跨度。
結果:在句子級和跨度級任務上均顯示出改進。
八、參考鏈接
Transformer 源碼解讀:Transformer源碼詳解(Pytorch版本) - 知乎
bert 源碼解讀:Bert源碼詳解(Pytorch版本) - 知乎
)
)






)


可行性分析)



)
Vue3路由傳參大全)


