目錄
Linux編輯器-vim
1. 基本概念
2. 基本操作
3. 正常模式命令集
4. 末行模式命令集
5. 其他操作
6. 簡單vim配置
Linux編譯器-gcc/g++
1、基本概念?
2、程序翻譯的過程
3. gcc如何完成程序翻譯
4、動靜態庫?
Linux項目自動化構建工具-make/Makefile
1、背景
2、創建makefile
3、原理
5、項目清理
進度條小程序
1、緩沖區刷新
2、原理?
3、實現?
Linux編輯器-vim
1. 基本概念
- 控制屏幕光標的移動,字符、字或行的刪除,移動復制某區段及進入Insert mode下,或者到 last line mode
- 只有在Insert mode下,才可以做文字輸入,按「ESC」鍵可回到命令行模式。該模式是我們后面用的最頻繁的編輯模式。
- 文件保存或退出,也可以進行文件替換,找字符串,列出行號等操作。 在命令模式下,shift+: 即可進入該模式。要查看你的所有模式:打開vim,底行模式直接輸入 :help vim-modes
2. 基本操作
- $ vim test.c ,進入vim之后,是處于[正常模式],要切換到[插入模式]才能夠輸入文字。
- 輸入a
- 輸入i
- 輸入o
- 目前處于[插入模式],就只能一直輸入文字,如果發現輸錯了字,想用光標鍵往回移動,將該字刪除,可以先按一下「ESC」鍵轉到[正常模式]再刪除文字。當然,也可以直接刪除。
- 「shift + ;」, 其實就是輸入「:」
- : w (保存當前文件): wq (輸入「wq」,存盤并退出vim)
- : q! (輸入q!,不存盤強制退出vim)
3. 正常模式命令集
- 按「i」切換進入插入模式「insert mode」,按“i”進入插入模式后是從光標當前位置開始輸入文件;
- 按「a」進入插入模式后,是從目前光標所在位置的下一個位置開始輸入文字;
- 按「o」進入插入模式后,是插入新的一行,從行首開始輸入文字。
- 按「ESC」鍵。
- vim可以直接用鍵盤上的光標來上下左右移動,但正規的vim是用小寫英文字母「h」、「j」、「k」、
- 「l」,分別控制光標左、下、上、右移一格
- 按「G」:移動到文章的最后
- 按「 $ 」:移動到光標所在行的“行尾”
- 按「^」:移動到光標所在行的“行首”
- 按「w」:光標跳到下個字的開頭
- 按「e」:光標跳到下個字的字尾
- 按「b」:光標回到上個字的開頭
- 按「#l」:光標移到該行的第#個位置,如:5l,56l
- 按[gg]:進入到文本開始
- 按[shift+g]:進入文本末端
- 按「ctrl」+「b」:屏幕往“后”移動一頁
- 按「ctrl」+「f」:屏幕往“前”移動一頁
- 按「ctrl」+「u」:屏幕往“后”移動半頁
- 按「ctrl」+「d」:屏幕往“前”移動半頁
- 「x」:每按一次,刪除光標所在位置的一個字符
- 「#x」:例如,「6x」表示刪除光標所在位置的“后面(包含自己在內)”6個字符
- 「X」:大寫的X,每按一次,刪除光標所在位置的“前面”一個字符
- 「#X」:例如,「20X」表示刪除光標所在位置的“前面”20個字符
- 「dd」:刪除光標所在行,dd+p實現剪切
- 「#dd」:從光標所在行開始刪除#行
- 「yw」:將光標所在之處到字尾的字符復制到緩沖區中。
- 「#yw」:復制#個字到緩沖區
- 「yy」:復制光標所在行到緩沖區。
- 「#yy」:例如,「6yy」表示拷貝從光標所在的該行“往下數”6行文字。
- 「p」:將緩沖區內的字符貼到光標所在位置。注意:所有與“y”有關的復制命令都必須與“p”配合才能完成復制與粘貼功能。
- 「r」:替換光標所在處的字符。
- 「R」:替換光標所到之處的字符,直到按下「ESC」鍵為止。
- [shift+r]?:進入替換模式
- 「u」:如果您誤執行一個命令,可以馬上按下「u」,回到上一個操作。按多次“u”可以執行多次回復。
- 「ctrl + r」: 撤銷的恢復
- 「cw」:更改光標所在處的字到字尾處
- 「c#w」:例如,「c3w」表示更改3個字
- 「ctrl」+「g」列出光標所在行的行號。
- 「#G」:例如,「15G」,表示移動光標至文章的第15行行首。
大小寫切換
- [shift]? +? [~]? ?按住不動可連續進行大小寫轉換。
4. 末行模式命令集
- 「set nu」: 輸入「set nu」后,會在文件中的每一行前面列出行號。
- 「#」:「#」號表示一個數字,在冒號后輸入一個數字,再按回車鍵就會跳到該行了,如輸入數字15,再回車,就會跳到文章的第15行。
- 「/關鍵字」: 先按「/」鍵,再輸入您想尋找的字符,如果第一次找的關鍵字不是您想要的,可以一直按 「n」會往后尋找到您要的關鍵字為止。
- 「?關鍵字」:先按「?」鍵,再輸入您想尋找的字符,如果第一次找的關鍵字不是您想要的,可以一直 按「n」會往前尋找到您要的關鍵字為止。
- 「q」:按「q」就是退出,如果無法離開vim,可以在「q」后跟一個「!」強制離開vim。
- 「wq」:一般建議離開時,搭配「w」一起使用,這樣在退出的時候還可以保存文件。
- !+q/w/wq 強制執行命令
不退出vim執行命令
- !+命令
5. 其他操作
- 使用vim打開一個不存在的文件,對該文件進行編輯后保存,vim會自動幫你創建該文件。
- vs + 文件名:在當前窗口創建一個新的垂直分屏,并在其中打開指定的文件。
6. 簡單vim配置
- 在目錄 /etc/ 下面,有個名為vimrc的文件,這是系統中公共的vim配置文件,對所有用戶都有效。
- 而在每個用戶的主目錄下,都可以自己建立私有的配置文件,命名為:“.vimrc”。例如,/root目錄下,
- 通常已經存在一個.vimrc文件,如果不存在,則創建之。
- 切換用戶成為自己執行 su ,進入自己的主工作目錄,執行 cd ~
- 打開自己目錄下的.vimrc文件,執行 vim .vimrc
- 設置語法高亮: syntax on
- 顯示行號: set nu
- 設置縮進的空格數為4: set shiftwidth=4
Linux編譯器-gcc/g++
1、基本概念?
gcc是GNU Compiler Collection(GNU編譯器集合)的縮寫,是一個廣泛使用的編程工具,用于編譯和鏈接C、C++、Objective-C和其他語言的源代碼。
gcc主要用于將高級編程語言(如C、C++等)的源代碼轉換為可執行文件或庫文件。它執行以下主要任務:
-
編譯:
gcc將源代碼文件(如.c、.cpp等)編譯為機器代碼文件(如.o、.obj等)。編譯過程將源代碼轉換為匯編語言,然后再轉換為機器代碼。 -
鏈接:
gcc將編譯生成的目標文件(.o、.obj等)以及所需的庫文件鏈接在一起,生成最終的可執行文件或庫文件。鏈接過程將解析和解決符號引用,將多個目標文件和庫文件組合成一個完整的可執行文件。
除了編譯和鏈接源代碼,gcc還提供了許多選項和功能,用于優化代碼、調試程序、生成調試信息、處理預處理指令等。
2、程序翻譯的過程
- 預處理(進行去注釋、宏替換、頭文件展開、條件編譯)
- 編譯(C/C++ >>> 匯編)
- 匯編(匯編 >> 可重定向二進制目標文件)
- 連接(鏈接多個 .o .obj 合并形成可執行文件.exe)
3. gcc如何完成程序翻譯
格式 gcc [選項] 要編譯的文件 [選項] [目標文件]
- 預處理功能主要包括宏定義,文件包含,條件編譯,去注釋等。
- 預處理指令是以#號開頭的代碼行。
- 實例:?gcc -E hello.c -o hello.i
- 選項“-E”,該選項的作用是讓 gcc 在預處理結束后停止編譯過程。
- 選項“-o”是指目標文件,“.i”文件為已經過預處理的C原始程序,-o后面緊跟生成的目標文件。
- 在這個階段中,gcc 首先要檢查代碼的規范性、是否有語法錯誤等,以確定代碼的實際要做的工作,在檢查
- 無誤后,gcc 把代碼翻譯成匯編語言。
- 選項“-S”:從現在開始進行程序的翻譯,如果編譯完成就停下來。
- 實例: gcc –S hello.i –o hello.s
- 匯編階段是把編譯階段生成的“.s”文件轉成目標文件(二進制文件)。
- 選項“-c”從現在開始進行程序的翻譯,如果匯編完成就停下來。
- 實例: gcc –c hello.s –o hello.o
- 在成功編譯之后,就進入了鏈接階段。
- 實例: gcc hello.o –o hello
4、動靜態庫?
- 在我們的C程序中,雖然沒有定義“printf”函數的實現,且在預編譯中包含的“stdio.h”中只有該函數的聲明,但實際上,“printf”等標準庫函數的實現被存放在名為?
libc.so.6?的庫文件中。 - 當使用gcc編譯時,如果沒有特別指定,它會默認在系統的搜索路徑(通常是
/usr/lib)下查找這個庫文件。通過鏈接到libc.so.6,程序能夠實現對“printf”等函數的調用,這就是鏈接階段的作用。
在Linux系統中,庫文件主要有兩種形式:動態庫(.so文件)和靜態庫(.a文件)。相應地,在Windows系統中,這兩種類型的庫文件分別以.dll(動態庫)和.lib(靜態庫)作為后綴名。
靜態庫在編譯鏈接過程中,將庫文件中的代碼全部加入到生成的可執行文件中。這種方式會導致可執行文件體積較大,但好處是運行時不再依賴外部的庫文件。靜態庫文件在Linux中一般以.a作為后綴名。
動態庫的處理方式則不同,它在編譯鏈接時不會將庫文件的代碼直接加入到可執行文件中。
- 相反,程序在運行時會動態地加載所需的庫文件。這種方式可以減少系統資源的占用,因為多個程序可以共享同一個庫文件的單個副本。
- 動態庫文件在Linux中的后綴名通常為
.so,例如之前提到的libc.so.6便是一個動態庫。 - 在編譯時,GCC默認采用動態庫鏈接,從而生成的二進制程序通常是動態鏈接的。這一點可以通過使用
file命令來驗證。例如,編譯生成可執行文件的命令可以是:gcc hello.o -o hello,這里GCC會默認鏈接到動態庫。
- -E 只激活預處理,這個不生成文件,你需要把它重定向到一個輸出文件里面
- -S? 編譯到匯編語言不進行匯編和鏈接
- -c? 編譯到目標代碼
- -o 文件輸出到 文件
- -static 此選項對生成的文件采用靜態鏈接
- -g?生成調試信息。GNU 調試器可利用該信息。
- -shared?此選項將盡量使用動態庫,所以生成文件比較小,但是需要系統由動態庫.
- -O0 -O1 -O2 -O3
- 編譯器的優化選項的4個級別,-O0表示沒有優化,-O1為缺省值,-O3優化級別最高
- -w? 不生成任何警告信息。
- -Wall 生成所有警告信息。
Linux項目自動化構建工具-make/Makefile
1、背景
- 會不會寫makefile,從一個側面說明了一個人是否具備完成大型工程的能力
- 一個工程中的源文件不計數,其按類型、功能、模塊分別放在若干個目錄中,makefile定義了一系列的規則來指定,哪些文件需要先編譯,哪些文件需要后編譯,哪些文件需要重新編譯,甚至于進行更復雜的功能操作
- makefile帶來的好處就是——“自動化編譯”,一旦寫好,只需要一個make命令,整個工程完全自動編譯,極大的提高了軟件開發的效率。
- make是一個命令工具,是一個解釋makefile中指令的命令工具,一般來說,大多數的IDE都有這個命令,比如:Delphi的make,Visual C++的nmake,Linux下GNU的make。可見,makefile都成為了一種在工程方面的編譯方法。
- make是一條命令,makefile是一個文件,兩個搭配使用,完成項目自動化構建。
2、創建makefile
要使用Makefile,您可以按照以下步驟進行:
1. 創建Makefile文件:在項目的根目錄或適當的位置創建一個名為“Makefile”(或“makefile”)的文件。
2. 定義目標和規則:在Makefile中,定義您的目標和相應的規則。每個目標表示一個輸出文件,而規則則指定如何生成目標。
target: dependencies//依賴關系command//依賴方法? ? 例如,如果您有一個C程序(如“hello.c”)需要編譯成可執行文件(如“hello”),Makefile可能如下所示:
hello: hello.ogcc hello.o -o hellohello.o: hello.c ? ? ? gcc -c hello.c -o hello.o- hello: hello.o 就是依賴關系
- gcc hello.o -o hello,就是依賴方法
3. 運行make命令:在命令行中,進入到包含Makefile的目錄,并運行`make`命令。
make? ? 這將根據Makefile中的規則自動構建項目。
這樣,Makefile就會根據定義的規則構建和管理您的項目。這對于大型項目和多文件項目的構建過程特別有用。
3、原理
hello: hello.ogcc hello.o -o hellohello.o: hello.sgcc -c hello.s -o hello.ohello.s: hello.igcc -S hello.i -o hello.shello.i: hello.cgcc -E hello.c -o hello.i.PHONY:clean
clean:rm -f hello.i hello.s hello.o hello- 上面的文件 hello ,它依賴 hell.o
- hello.o , 它依賴 hello.s
- hello.s , 它依賴 hello.i
- hello.i , 它依賴 hello.c
- 尋找Makefile:Make首先在當前目錄下尋找名為“Makefile”或“makefile”的文件。
- 確定目標文件:在Makefile中,Make會查找第一個目標(target),例如“hello”,并將其作為構建過程的最終目標。
- 檢查文件依賴和更新:如果目標文件“hello”不存在,或者它依賴的文件(如“hello.o”)比“hello”更新(這可以通過
touch命令模擬),Make將執行相應的命令來生成“hello”文件。 - 遞歸解析依賴:如果“hello”依賴的“hello.o”文件不存在,Make會在Makefile中尋找生成“hello.o”的規則,并遞歸地解析直到所有依賴都被構建。這個過程類似于堆棧操作,Make會一層層地解析文件依賴關系,直到所有必需的文件都被編譯或更新。
- 編譯和構建:在所有的C文件和H文件存在的情況下,Make將根據規則生成“hello.o”文件,然后使用它來完成最終目標“hello”的構建。
Make的核心在于管理文件之間的依賴關系。它會一步步地檢查和滿足這些依賴,直到達到最終的構建目標。如果在解析依賴的過程中遇到無法找到的文件,Make會停止并報錯。然而,對于命令執行錯誤或編譯失敗,Make不會中斷其過程,因為它主要關注的是文件依賴性。
總結來說,Make通過逐層解析和滿足文件依賴,自動化地管理編譯過程。這種方式極大地簡化了復雜項目的構建過程,使開發者能夠專注于代碼開發,而不是構建過程的每一個細節。
5、項目清理
工程是需要被清理的。
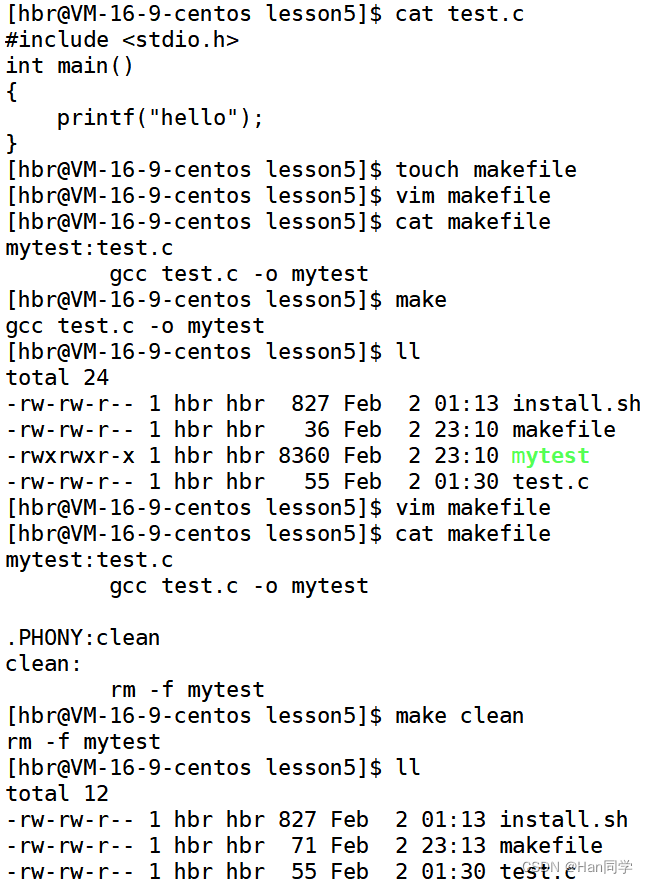
- 像clean這種,沒有被第一個目標文件直接或間接關聯,那么它后面所定義的命令將不會被自動執行, 不過,我們可以顯示要make執行。即命令——“make clean”,以此來清除所有的目標文件,以便重編譯。
- 但是一般我們這種clean的目標文件,我們將它設置為偽目標,用 .PHONY 修飾,偽目標的特性是,總是被執行的,總是會根據依賴關系執行依賴方法。
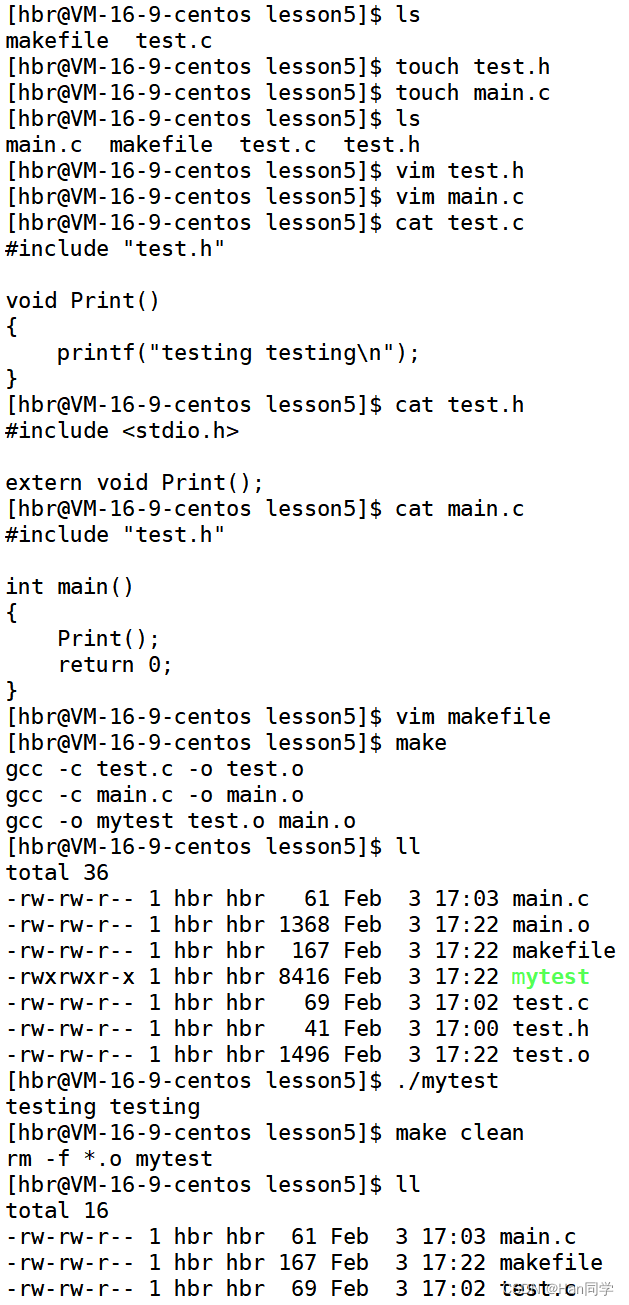
例: 鏈接三個文件
其中makefile如下:?
[hbr@VM-16-9-centos lesson5]$ cat makefile
mytest:test.o main.ogcc -o mytest test.o main.o
test.o:test.cgcc -c test.c -o test.o
main.o:main.cgcc -c main.c -o main.o.PHONY:clean
clean:rm -f *.o mytest
進度條小程序
1、緩沖區刷新
[hbr@VM-16-9-centos program1]$ touch test.c
[hbr@VM-16-9-centos program1]$ vim test.c
[hbr@VM-16-9-centos program1]$ cat test.c
#include <stdio.h>
#include <unistd.h>int main()
{printf("hello\n");sleep(3);return 0;
}
[hbr@VM-16-9-centos program1]$ gcc test.c
[hbr@VM-16-9-centos program1]$ ls
a.out makefile proc proc.c test.c
[hbr@VM-16-9-centos program1]$ ./a.out
hello
[hbr@VM-16-9-centos program1]$ vim test.c
[hbr@VM-16-9-centos program1]$ cat test.c
#include <stdio.h>
#include <unistd.h>int main()
{printf("hello");sleep(3);return 0;
}
[hbr@VM-16-9-centos program1]$ gcc test.c
[hbr@VM-16-9-centos program1]$ ./a.out 第一次輸出時:先輸出Hello然后3秒后結束。
第二次去掉“\n”輸出時:先等待三秒然后輸出Hello后結束。
當第一次執行編譯后的程序時,程序會立即輸出"hello",然后等待3秒鐘后結束。這是因為printf函數遇到換行符\n時,會立即刷新輸出緩沖區,使得"hello"緊接著被輸出到屏幕上。
而在第二次執行時,由于從printf的字符串中移除了換行符\n,輸出的行為有所不同。
- 在這種情況下,
printf輸出的"hello"首先被存儲在輸出緩沖區中,并不會立即顯示。 - 由于C語言的輸出緩沖區是根據特定的刷新策略來刷新的,對于到顯示器這種設備,其一般的刷新策略是在遇到換行符
\n時進行刷新。 - 因此,當沒有換行符引導的直接刷新時,輸出緩沖區會等待直到程序結束或遇到其他刷新條件才進行刷新。這就是為什么在移除
\n后,"hello"會在等待了3秒后才顯示出來的原因。
2、原理?
\n換行本質上是:換行(到下一行)+回車(到行首),先看代碼。
[hbr@VM-16-9-centos program1]$ vim test.c
[hbr@VM-16-9-centos program1]$ cat test.c
#include <stdio.h>
#include <unistd.h>int main()
{int n = 6;while(n >= 0){printf("n=%d\n",n);n--;sleep(1);}return 0;
}
[hbr@VM-16-9-centos program1]$ gcc test.c
[hbr@VM-16-9-centos program1]$ ./a.out
n=6
n=5
n=4
n=3
n=2
n=1
n=0
[hbr@VM-16-9-centos program1]$ vim test.c //\n換成\r
[hbr@VM-16-9-centos program1]$ gcc test.c
[hbr@VM-16-9-centos program1]$ ./a.out //沒有輸出結果
[hbr@VM-16-9-centos program1]$ vim test.c
[hbr@VM-16-9-centos program1]$ cat test.c
#include <stdio.h>
#include <unistd.h>int main()
{int n = 6;while(n >= 0){printf("n=%d\r",n);n--;fflush(stdout);sleep(1);}return 0;
}
[hbr@VM-16-9-centos program1]$ gcc test.c
[hbr@VM-16-9-centos program1]$ ./a.out
[hbr@VM-16-9-centos program1]$//會按照倒計時輸出,此處不方便展示效果- 第一個示例中,
\n用于在每次輸出后換行并回到行首,這是標準的行為,使得每個輸出結果都在新的一行顯示,因此可以看到從n=6遞減到n=0的過程,每個數字都在新的一行上。 - 然而,將
\n替換為\r時,行為發生了變化。在計算機中,\r是回車符,它的作用是將光標移回行首,但不會進入新行。這意味著如果只用\r而不是\n,所有的輸出都會在同一行上發生,而且后面的輸出會覆蓋前面的輸出。 - 在沒有
fflush(stdout);的情況下,由于輸出緩沖區不會因\r而刷新,可能在程序執行完畢之前看不到任何輸出。這是因為輸出緩沖區通常在滿了或者程序結束時才會自動刷新,導致在第二次嘗試中看不到輸出結果。 - 引入
fflush(stdout);后,每次調用printf之后立即強制刷新輸出緩沖區,使得即使是\r也能即時看到效果。這導致光標回到行首,然后用新的數字覆蓋舊的數字,實現了一個簡單的倒計時效果。因為光標每次都回到行首,而且立即刷新,所以你可以看到n的值從6遞減到0,但這個過程中你只會在屏幕上看到一個數字的變化,而不是多行輸出。
3、實現?
該程序的可視化效果是一個逐步填充的進度條,旁邊有一個旋轉的符號表示進度正在進行,直到進度條完全填滿,并顯示100%。通過這種方式,可以在執行較長時間的操作時給用戶一個視覺上的反饋。
[hbr@VM-16-9-centos program1]$ tree
.
├── makefile
├── proc.c
└── test.c0 directories, 3 files
[hbr@VM-16-9-centos program1]$ cat makefile
proc:proc.cgcc -o proc proc.c.PHONY:clean
clean:rm -f proc
[hbr@VM-16-9-centos program1]$ vim proc.c
[hbr@VM-16-9-centos program1]$ cat proc.c
#include <stdio.h>
#include <string.h>
#include <unistd.h>
#define NUM 51int main()
{char bar[NUM];memset(bar,0,sizeof(bar));const char *lable="|/-\\";int i=0;while(i<=50){printf("[%-50s][%d%%] %c\r",bar,i*2,lable[i%4]);bar[i++]='#';fflush(stdout);usleep(30000);}printf("\n");return 0;
}
[hbr@VM-16-9-centos program1]$ make
gcc -o proc proc.c
[hbr@VM-16-9-centos program1]$ ls
makefile proc proc.c test.c
[hbr@VM-16-9-centos program1]$ ./proc
[##################################################][100%] -在proc.c中,定義了一個進度條,使用字符數組bar來模擬進度條的填充情況,并通過循環逐漸增加bar數組中的#字符數量來表示進度的增加。下面是代碼的逐行解釋:
- 包含必要的頭文件
stdio.h(用于輸入輸出)、string.h(用于內存操作),和unistd.h(用于usleep函數,暫停執行)。 - 定義宏
NUM為51,這個值用于定義字符數組bar的長度。 - 在
main函數中,聲明字符數組bar并通過memset函數將其初始化為全0,這意味著開始時進度條是空的。 - 定義一個字符串
lable,包含四個字符"|/-\\",用于在進度條旁邊顯示旋轉的效果,模仿一個正在進行的操作。 - 使用
while循環,條件為i小于等于50,這意味著進度條的最大填充長度為50個#字符。 - 在循環內部,使用
printf函數打印進度條。[%-50s]用于左對齊打印字符串bar,寬度固定為50個字符;[%d%%]顯示當前進度的百分比,因為循環是到50,所以用i*2來計算百分比;%c用于打印旋轉符號,通過lable[i%4]選擇"|/-\\"中的一個字符,隨著i的增加而變化。 - 每次循環時,將
bar[i]設置為#,通過遞增i來模擬進度條的填充。 - 使用
fflush(stdout)強制刷新標準輸出,確保每次循環的輸出都能立即顯示而不是等緩沖區滿。 usleep(30000)暫停30毫秒(30000微秒),這樣用戶可以看到進度條的逐步填充和旋轉符號的動態變化。- 循環結束后,打印一個換行符
\n,以避免在命令行提示符出現之前光標停留在進度條的末尾。 - 函數返回0,表示程序正常結束。
Qt窗口)
求解23個基準函數)



:電解電容低阻如何選擇詳解)


)
)






)


可行性分析)