
🎈個人主頁:豌豆射手^
🎉歡迎 👍點贊?評論?收藏
🤗收錄專欄:機器學習
🤝希望本文對您有所裨益,如有不足之處,歡迎在評論區提出指正,讓我們共同學習、交流進步!
【機器學習】包裹式特征選擇之遞歸特征消除法
- 一 初步了解
- 1.1 概念
- 1.2 類比
- 二 具體步驟
- 2.1 選擇模型
- 2.2 初始化:
- 2.3 模型訓練:
- 2.4 特征重要性評估:
- 2.5 特征排序:
- 2.6 剔除特征:
- 2.7 更新特征集:
- 2.8 停止條件檢查:
- 2.9 重復步驟:
- 三 優缺點以及適用場景
- 3.1 優點:
- 3.2 缺點:
- 3.3 適用場景:
- 四 代碼示例及分析
- 總結
引言:
在機器學習中,特征選擇是提高模型性能和泛化能力的關鍵步驟之一。
而包裹式特征選擇方法中的遞歸特征消除法 (Recursive Feature Elimination,簡稱RFE)是一種有效的特征選擇技術。
通過遞歸地剔除對模型性能貢獻較小的特征,RFE能夠選擇出最佳的特征子集,從而提高模型的預測性能。
本文將介紹遞歸特征消除法的概念、具體步驟、優缺點以及適用場景,并提供代碼示例進行詳細分析。

一 初步了解
1.1 概念
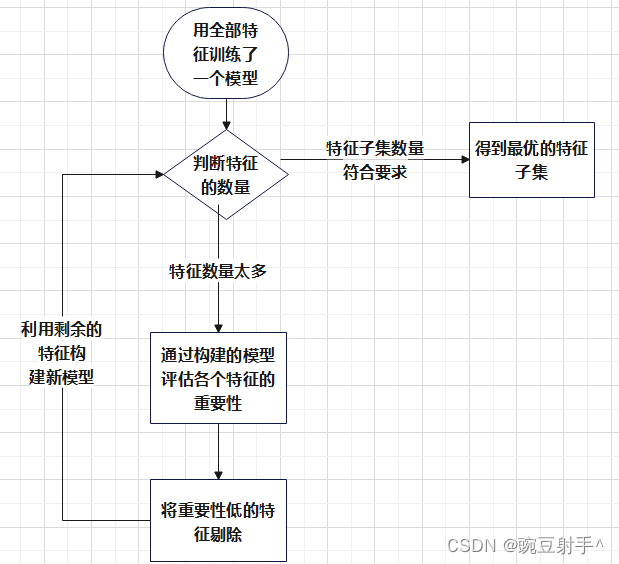
遞歸特征消除(RFE)是包裹式特征選擇法中的一種方法,它通過反復構建模型并剔除最不重要的特征來選擇最優特征子集。
首先,使用全部特征訓練一個模型,然后根據特征的重要性評估移除最不重要的特征。
特征訓練模型是指利用選定的特征集合來訓練一個機器學習模型,以便對數據進行預測或分類,也就是用數據來訓練了一個模型。
在特征選擇的上下文中,特征集是經過篩選或選擇的子集,通常包含數據集中最重要或最相關的特征。
這個過程迭代進行,每次更新特征集,直到達到預定的特征數量或其他停止條件。
遞歸地剔除特征的過程確保了最終選擇的特征子集對于模型性能至關重要,有助于提高預測性能并減少特征的維度,增強模型的泛化能力。
流程圖大概如下:
1.2 類比
假設你是一位園藝師,正在設計一座美麗的花園。
花園里的每一種植物都代表數據集中的一個特征。

現在,你的目標是選擇一組最適合花園美感的植物組合,以確保花園在四季都充滿色彩。
在這個情境中,遞歸特征消除(RFE)就像是你在挑選植物時的一種策略。
開始時,你選擇了各種各樣的植物,代表數據集中的所有特征。
然后,你根據每種植物對花園整體美感的貢獻,決定是否保留或剔除某些植物。
也許有些植物的顏色并不和諧,或者有些植物在某個季節并不怎么引人注目。
于是,你將影響美感的的植物剔除了,然后用剩下的植物重新構建新的花園。(用剩下的特征構建新的模型)
再根據新的的花園中,剩下的每種植物對花園整體美感的貢獻,又再次決定是否保留或剔除某些植物。
重復這個過程,你逐步剔除了這些對花園美感影響較小的植物,直到達到你心目中的理想花園,或者直到不能再提升花園的整體美感為止。
這個過程類似于遞歸特征消除的工作原理:
通過不斷嘗試和調整,逐步剔除對整體美感貢獻較小的植物(特征),最終得到一個最優的植物組合,使得花園在四季都呈現出最美的景色。
這樣,你就能更好地掌握花園設計的要訣,提高了花園整體美感的效果。
在這個類比中,重點強調了遞歸特征消除的迭代過程,其中每一輪剔除不重要的植物都伴隨著重新構建花園的步驟。

二 具體步驟
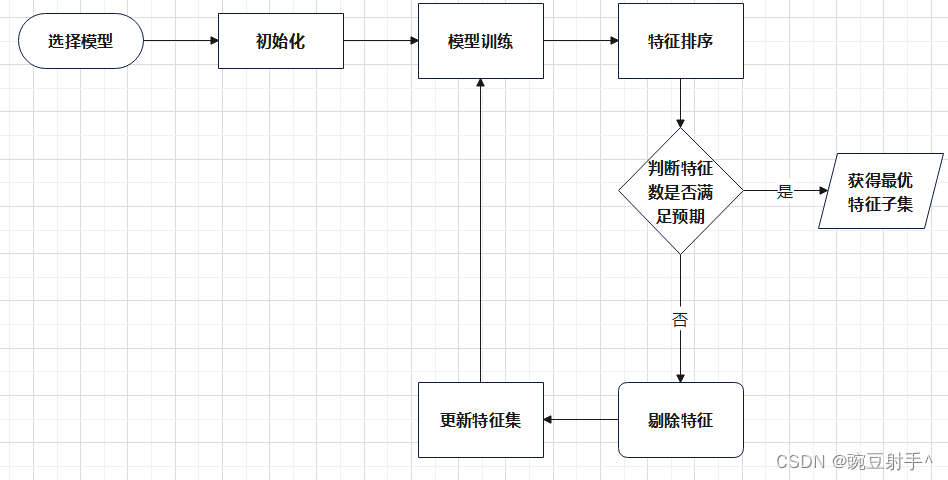
步驟流程圖如下:
接下來,我將詳細介紹每一個步驟的具體實現。
2.1 選擇模型
首先,選擇一個適合于特定任務的預測模型,例如線性回歸、邏輯回歸、支持向量機等。
這個模型將用于評估特征的重要性,并指導特征選擇的過程。
2.2 初始化:
將所有特征包含在特征集合中,作為初始的特征子集。
2.3 模型訓練:
使用選定的模型和所有特征來訓練一個初始模型。
2.4 特征重要性評估:
利用已訓練的模型,評估每個特征的重要性或對模型性能的貢獻程度。
這可以通過不同的方法來完成,如特征權重、系數、信息增益等。
2.5 特征排序:
根據特征的重要性進行排序,確定哪些特征對模型的性能影響最大,哪些對模型性能影響較小。
2.6 剔除特征:
移除排序后的特征列表中最不重要的特征。可以根據實際需要選擇一次剔除一個或多個特征。
剔除的特征通常是那些被認為對模型性能貢獻較小的特征。
2.7 更新特征集:
在剔除特征后,更新特征集,形成一個新的特征子集。
2.8 停止條件檢查:
檢查是否滿足停止條件,例如特征數量已達到預定值、模型性能已達到某個閾值等。
如果滿足停止條件,則停止迭代;否則,回到第3步,繼續進行下一輪迭代。
2.9 重復步驟:
重復步驟3到步驟8,直到滿足停止條件為止。
每一輪迭代都會剔除對模型性能影響較小的特征,直到找到一個最優的特征子集。

三 優缺點以及適用場景
3.1 優點:
1 考慮特征間的相互關系:
RFE在剔除特征時會考慮到特征間的相互影響,從而更加準確地選擇特征子集。
2 降低過擬合風險:
通過減少特征數量,RFE可以降低模型的復雜度,減少過擬合的風險。
3 提高模型性能:
通過選擇最優的特征子集,RFE可以提高模型的性能和泛化能力。
4 無需事先假設特征分布:
RFE不需要對特征分布做出假設,適用于各種類型的數據。
3.2 缺點:
1 計算成本高:
對于特征數量較多的數據集,RFE需要反復訓練模型,計算成本較高。
2 依賴模型選擇:
RFE的性能取決于所選擇的基礎模型,選擇不合適的模型可能導致特征選擇效果不佳。
3 可能丟失信息:
在剔除特征的過程中,有可能剔除了一些對模型有潛在貢獻的特征,導致丟失信息。
3.3 適用場景:
1 特征數量較多:
當數據集特征數量較多時,RFE可以幫助篩選出最重要的特征,減少特征的維度。
2 模型復雜度高:
當模型復雜度較高,存在過擬合風險時,RFE可以幫助減少特征數量,降低模型復雜度。
3 需要提高模型性能:
當模型性能需要提高時,RFE可以幫助選擇最優的特征子集,提高模型的性能和泛化能力。
總的來說,遞歸特征消除法在特征選擇方面具有一定的優勢,尤其適用于特征數量較多、模型復雜度較高或需要提高模型性能的情況下。
然而,使用RFE時需要注意計算成本和模型選擇的問題。

四 代碼示例及分析
我們可以通過Python中的scikit-learn模塊實現遞歸特征消除,在這個模塊中,實現遞歸特征消除法的具體方法是使用RFE(Recursive Feature Elimination)類。
通過該類,可以將基礎模型(如SVM分類器)和要選擇的特征數量作為參數,然后利用遞歸的方式不斷剔除特征,最終得到最佳的特征子集。
下面是具體步驟:
1 導入庫 (Import Libraries):
from sklearn.datasets import make_classification
from sklearn.feature_selection import RFE
from sklearn.svm import SVC
這些代碼導入了三個scikit-learn庫中的模塊:make_classification 用于生成分類數據集,RFE用于遞歸特征消除,SVC 是支持向量機的實現。
2 生成一個示例數據集 (Generate Example Dataset):
X, y = make_classification(n_samples=100, n_features=10, random_state=42)
使用 make_classification 函數生成一個包含 100 個樣本和 10 個特征的分類數據集,并將特征矩陣賦值給 X,目標變量賦值給 y。
3 創建一個SVM分類器作為基礎模型 (Create SVM Classifier as Base Model):
svc = SVC(kernel="linear")
創建一個基于線性核函數的支持向量機(SVM)分類器,將其實例化并賦值給變量 svc。
4 使用RFE進行特征選擇,選擇5個最重要的特征 (Use RFE for Feature Selection, Select 5 Most Important Features):
rfe = RFE(estimator=svc, n_features_to_select=5, step=1)
創建一個 RFE 對象,指定基礎模型為 svc,要選擇的特征數量為 5,步長為 1。
5 對數據進行特征選擇 (Perform Feature Selection on Data):
rfe.fit(X, y)
調用 RFE 對象的 fit 方法,使用數據 X 和目標變量 y 進行特征選擇。
6 輸出所選特征的排名 (Print Feature Rankings):
print("Feature Ranking:", rfe.ranking_)
打印輸出所選特征的排名,即每個特征在RFE過程中的重要性排序,排名越低表示特征越重要。
7 輸出所選特征 (Print Selected Features):
selected_features = [f"Feature {i+1}" for i in range(len(rfe.ranking_)) if rfe.support_[i]]
print("Selected Features:", selected_features)
使用列表推導式和條件判斷,確定被選中的特征,并打印輸出它們的名稱。 rfe.support_ 返回一個布爾類型的數組,指示哪些特征被選中。
運行結果如下:
Feature Ranking: [1 1 1 1 1 6 5 4 3 2]
Selected Features: ['Feature 1', 'Feature 2', 'Feature 3', 'Feature 4', 'Feature 5']
這表示在特征選擇過程中,前五個特征被選為最重要的特征,它們的排名為 1,而其余特征的排名分別為 2 到 6。
被選中的特征分別是 ‘Feature 1’, ‘Feature 2’, ‘Feature 3’, ‘Feature 4’, 和
‘Feature 5’。
完整代碼 :
# 導入庫
from sklearn.datasets import make_classification
from sklearn.feature_selection import RFE
from sklearn.svm import SVC# 生成一個示例數據集
X, y = make_classification(n_samples=100, n_features=10, random_state=42)# 創建一個SVM分類器作為基礎模型
svc = SVC(kernel="linear")# 使用RFE進行特征選擇,選擇5個最重要的特征
rfe = RFE(estimator=svc, n_features_to_select=5, step=1)# 對數據進行特征選擇
rfe.fit(X, y)# 輸出所選特征的排名
print("Feature Ranking:", rfe.ranking_)# 輸出所選特征
selected_features = [f"Feature {i+1}" for i in range(len(rfe.ranking_)) if rfe.support_[i]]
print("Selected Features:", selected_features)
總結
遞歸特征消除法(RFE)作為一種包裹式特征選擇方法,在特征選擇中具有一定的優勢。
通過遞歸地剔除對模型性能貢獻較小的特征,RFE能夠選擇出最佳的特征子集,從而提高模型的預測性能。
然而,RFE也存在一些缺點,例如計算開銷較大、對于大規模數據集可能不太適用等。
因此,在使用RFE時需要根據具體情況權衡其優缺點,并結合實際場景做出合適的選擇。
這篇文章到這里就結束了
謝謝大家的閱讀!
如果覺得這篇博客對你有用的話,別忘記三連哦。
我是豌豆射手^,讓我們我們下次再見


:電解電容低阻如何選擇詳解)


)
)






)


可行性分析)



)
Vue3路由傳參大全)