Faster-RCNN(RPN + CNN + ROI)概念
Faster RCNN可以分為4個主要內容:
- Conv layers:作為一種CNN網絡目標檢測方法,Faster RCNN首先使用一組基礎的conv+relu+pooling層提取 image的feature maps。該feature maps被共享用于后續 RPN層和全連接層。
- Region Proposal Networks:RPN網絡用于生成region proposals。通過softmax判斷anchors屬于positive或者 negative,再利用bounding box regression修正anchors 獲得精確的proposals。
- Roi Pooling:該層收集輸入的feature maps和proposals, 綜合這些信息后提取proposal feature maps,送入后續 全連接層判定目標類別。
- Classification:利用proposal feature maps計算 proposal的類別,同時再次bounding box regression獲 得檢測框最終的精確位置。

整體流程:

Faster-RCNN:conv layer
Conv layers包含了conv,pooling,relu三種層。共有13個conv層,13個relu層,4個pooling層。
在Conv layers中:
- 所有的conv層都是:kernel_size=3,pad=1,stride=1
- 所有的pooling層都是:kernel_size=2,pad=1,stride=2
在Faster RCNN Conv layers中對所有的卷積都做了pad處理( pad=1,即填充一圈0),導致原圖 變為 (M+2)x(N+2)大小,再做3x3卷積后輸出MxN 。正是這種設置,導致Conv layers中的conv層 不改變輸入和輸出矩陣大小。

類似的是,Conv layers中的pooling層kernel_size=2,stride=2。 這樣每個經過pooling層的MxN矩陣,都會變為(M/2)x(N/2)大小。
綜上所述,在整個Conv layers中,conv和relu層不改變輸入輸出大小,只有pooling層使輸出長 寬都變為輸入的1/2。
那么,一個MxN大小的矩陣經過Conv layers固定變為(M/16)x(N/16)。 這樣Conv layers生成的feature map都可以和原圖對應起來。
Faster-RCNN:Region Proposal Networks(RPN)
區域生成網絡Region Proposal Networks(RPN)
經典的檢測方法生成檢測框都非常耗時。直接使用RPN生成檢測框,是Faster R-CNN的巨大優勢,能極大提升檢測框的生成速度。
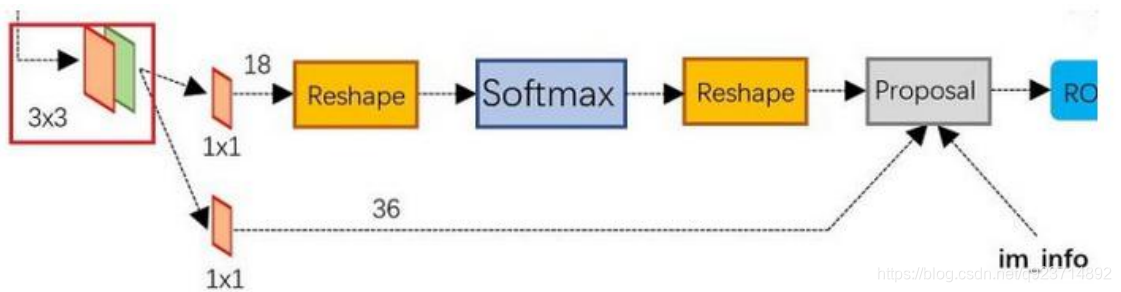
? 可以看到RPN網絡實際分為2條線:
- 上面一條通過softmax分類anchors獲得positive和negative分類;
- 下面一條用于計算對于anchors的bounding box regression偏移量,以獲得精確的proposal。
? 而最后的Proposal層則負責綜合positive anchors和對應bounding box regression偏移量獲取 proposals,同時剔除太小和超出邊界的proposals。
? 其實整個網絡到了Proposal Layer這里,就完成了相當于目標定位的功能。
anchors
RPN網絡在卷積后,對每個像素點,上采樣映射到原始圖像一個區域,找到這 個區域的中心位置,然后基于這個中心 位置按規則選取9種anchor box。
9個矩形共有3種面積:128,256,512; 3種形狀:長寬比大約為1:1, 1:2, 2:1。 (不是固定比例,可調) 每行的4個值表示矩形左上和右下角點坐標。
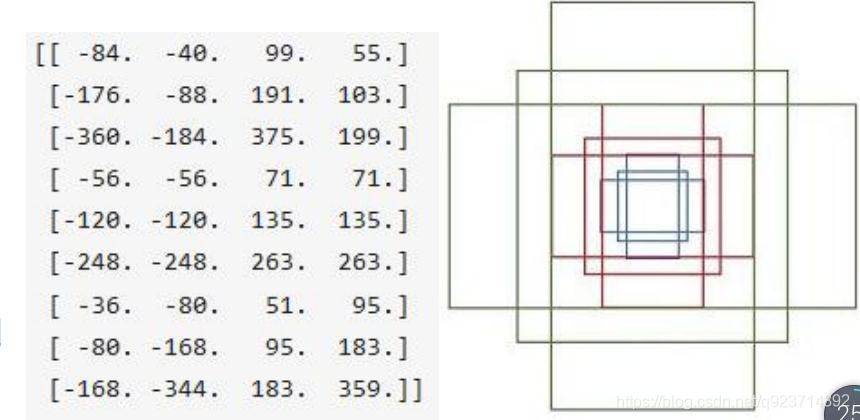
遍歷Conv layers獲得的feature maps,為每一個點都 配備這9種anchors作為初始的檢測框。
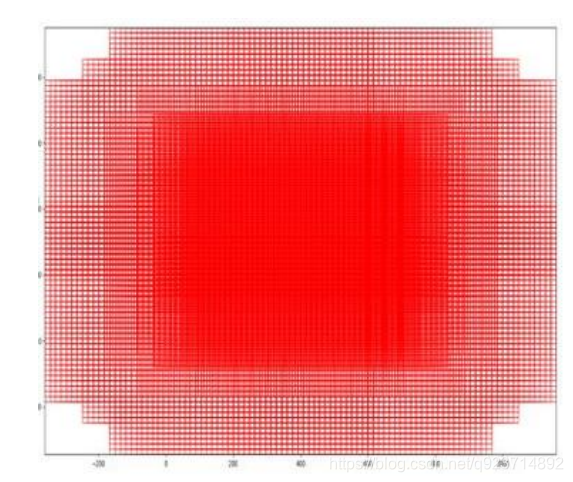
這些anchor box都是對應于原圖的尺寸,可以直接使用標記的候選框和分類結果進行訓練。其中:
- 把每個標定的ground-truth box與其重疊最大的anchor box記為正樣本。(保證每個ground-truth box 至少對應一個正樣本anchor)
- 剩余的anchor box與某個ground-truth box重疊大于0.7的記為正樣本。(每個ground-truth box可能 會對應多個正樣本anchor。但每個正樣本anchor只可能對應一個grand-truth box)
- 與任意一個標記ground-truth box重疊小于0.3的anchor box記為負樣本。
- 其余的舍棄。 這樣做獲得檢測框很不準確,通過后面的2次bounding box regression可以修正檢測框位置。
softmax判定positive與negative
其實RPN最終就是在原圖尺度上,設置了密密麻麻的候選Anchor。然后用cnn去判斷哪些Anchor是里面 有目標的positive anchor,哪些是沒目標的negative anchor。所以,僅僅是個二分類而已。

可以看到其num_output=18,也就是經過該卷積的輸出圖像為WxHx18大小。
這也就剛好對應了feature maps每一個點都有9個anchors,同時每個anchors又有可能是positive和 negative,所有這些信息都保存在WxHx(9*2)大小的矩陣。
注意這里的18,后面之所以reshape成為18也是因為對應這18個元素的原因
為何這樣做?
后面接softmax分類獲得positive anchors,也就相當于初步提取了檢測目標候選區域box (一般認為目標在positive anchors中)。
那么為何要在softmax前后都接一個reshape layer?
其實只是為了便于softmax分類。 前面的positive/negative anchors的矩陣,其在caffe中的存儲形式為[1, 18, H, W]。而在softmax 分類時需要進行positive/negative二分類,所以reshape layer會將其變為[1, 2, 9xH, W]大小,即 單獨“騰空”出來一個維度以便softmax分類,之后再reshape回復原狀。
對proposals進行bounding box regression

可以看到其 num_output=36,即經過該卷積輸出圖像為WxHx36。 這里相當于feature maps每個點都有9個anchors,每個anchors又都有4個用于回歸的變換量:

Proposal Layer
Proposal Layer負責綜合所有變換量和positive anchors,計算出精準的proposal,送入后續RoI Pooling Layer。
Proposal Layer有4個輸入:
- positive vs negative anchors分類器結果rpn_cls_prob_reshape,
- 對應的bbox reg的變換量rpn_bbox_pred,
- im_info
- 參數feat_stride=16
im_info:對于一副任意大小PxQ圖像,傳入Faster RCNN前首先reshape到固定MxN,im_info=[M, N, scale_factor]則保存了此次縮放的所有信息。
輸入圖像經過Conv Layers,經過4次pooling變為WxH=(M/16)x(N/16)大小,其中feature_stride=16則保 存了該信息用于計算anchor偏移量。
Proposal Layer 按照以下順序依次處理:
- 利用變換量對所有的anchors做bbox regression回歸
- 按照輸入的positive softmax scores由大到小排序anchors,提取前pre_nms_topN(e.g. 6000)個anchors, 即提取修正位置后的positive anchors。
- 限定超出圖像邊界的positive anchors為圖像邊界,防止后續roi pooling時proposal超出圖像邊界。
- 剔除尺寸非常小的positive anchors。
- 對剩余的positive anchors進行NMS(non-maximum suppression)。
- 之后輸出proposal。
注意,由于在第三步中將anchors映射回原圖判斷是否超出邊界,所以這里輸出的proposal是對應MxN輸 入圖像尺度的,這點在后續網絡中有用。
嚴格意義上的檢測應該到此就結束了,后續部分應該屬于識別了。
RPN網絡結構就介紹到這里,總結起來就是:
生成anchors -> softmax分類器提取positvie anchors -> bbox reg回歸positive anchors -> Proposal Layer生成proposals
Faster-RCNN:Roi pooling
RoI Pooling概念
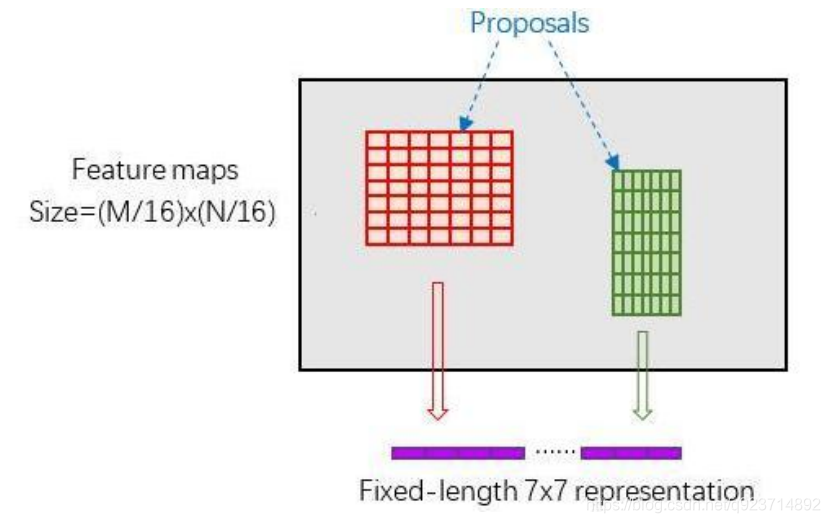
RoI Pooling層則負責收集proposal,并計算出proposal feature maps,送入后續網絡。
Rol pooling層有2個輸入:
- 原始的feature maps
- RPN輸出的proposal boxes(大小各不相同)
為何需要RoI Pooling?
對于傳統的CNN(如AlexNet和VGG),當網絡訓練好后輸入的圖像尺寸必須是固定值,同時網絡輸出也 是固定大小的vector or matrix。如果輸入圖像大小不定,這個問題就變得比較麻煩。
有2種解決辦法:
- 從圖像中crop一部分傳入網絡將圖像(破壞了圖像的完整結構)
- warp成需要的大小后傳入網絡(破壞了圖像原始形狀信息

RoI Pooling原理
新參數pooled_w、pooled_h和spatial_scale(1/16)
RoI Pooling layer forward過程:
- 由于proposal是對應MN尺度的,所以首先使用spatial_scale參數將其映射回(M/16)(N/16)大小 的feature map尺度;
- 再將每個proposal對應的feature map區域水平分為poold_w * pooled_h的網格;
- 對網格的每一份都進行max pooling處理。
這樣處理后,即使大小不同的proposal輸出結果都是poold_w * pooled_h固定大小,實現了固定長度輸出。
Faster-RCNN: Classification
Classification部分利用已經獲得的proposal feature maps,通過full connect層與softmax計算每個proposal具體屬于那個類別(如人,車,電視等),輸出cls_prob概率向量;
同時再次利用bounding box regression獲得每個proposal的位置偏移量bbox_pred,用于回歸更加精確的目標檢測框。

從RoI Pooling獲取到poold_w * pooled_h大小的proposal feature maps后,送入后續網絡,做了如下2 件事:
- 通過全連接和softmax對proposals進行分類,這實際上已經是識別的范疇了
- 再次對proposals進行bounding box regression,獲取更高精度的預測框
全連接層InnerProduct layers:

輸入X和輸出Y是固定大小。所以,這也就印證了之前Roi Pooling的 必要性
代碼實現:
因為代碼非常多,所以放在資源里面。
有偏見)


















)