實例分割
實例分割(instance segmentation)的難點在于:
需要同時檢測出目標的位置并且對目標進行分割,所以這就需要融合目標檢測(框出目標的位置)以及語義分割(對像素進行分類,分割出目 標)方法。
實例分割–Mask R-CNN
Mask R-CNN可算作是Faster R-CNN的升級版。
Faster R-CNN廣泛用于對象檢測。對于給定圖像,它會給圖中每個對象加上類別標簽與邊界框坐標。 Mask R-CNN框架是以Faster R-CNN為基礎而架構的。因此,針對給定圖像, Mask R-CNN不僅會 給每個對象添加類標簽與邊界框坐標,還會返回其對象掩膜。

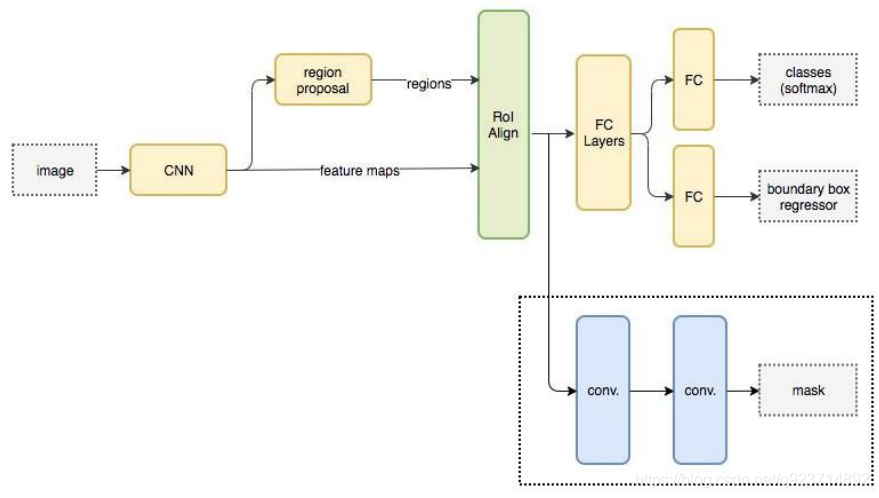
Mask R-CNN的抽象架構:
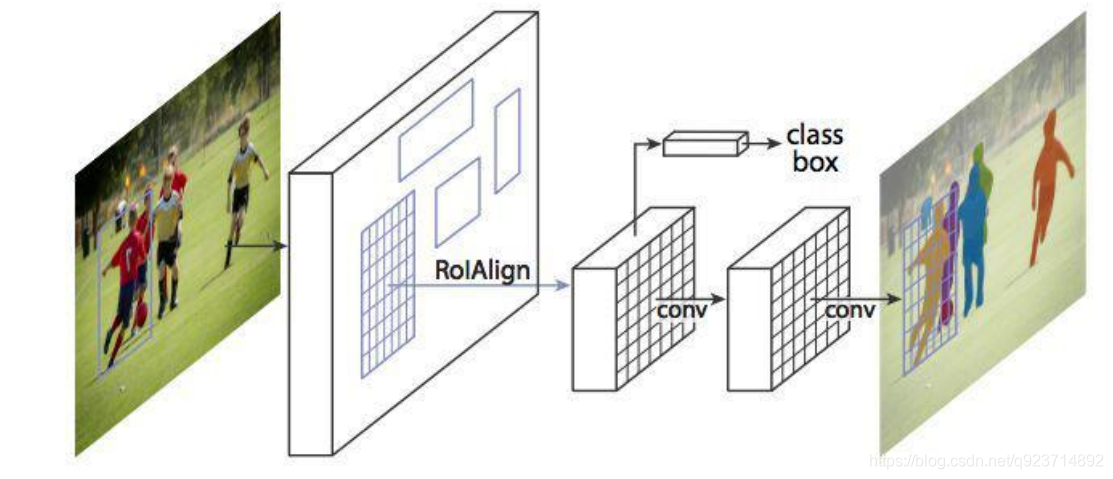
Mask R-CNN在進行目標檢測的同時進行實例分割,取得了出色的效果
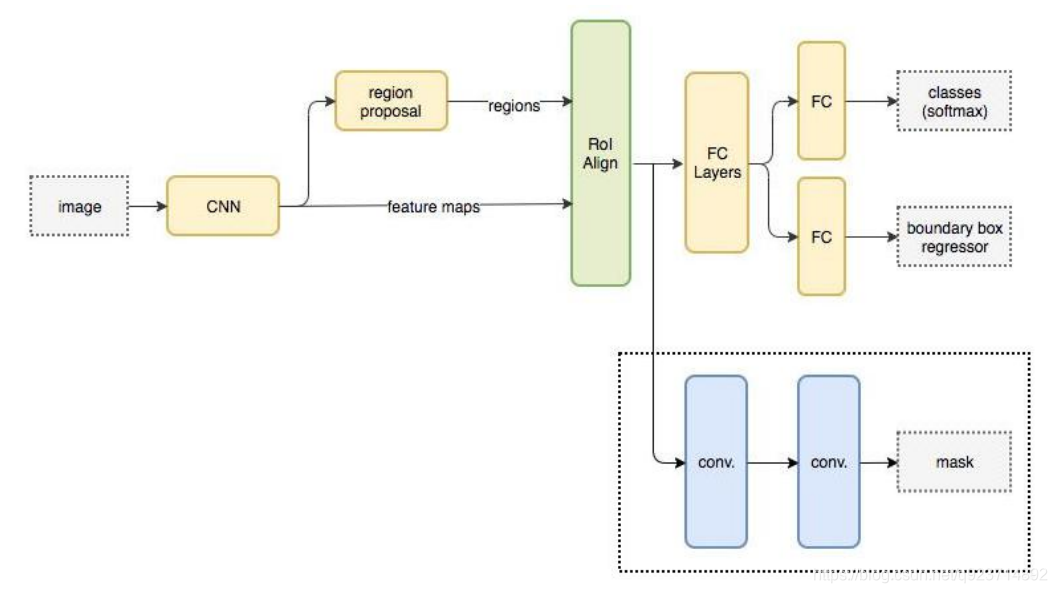
Faster R-CNN與 Mask R-CNN
Mask-RCNN 大體框架還是 Faster-RCNN 的框架,可以說在基礎特征網絡之后又加入了全連接的分割 子網,由原來的兩個任務(分類+回歸)變為了三個任務(分類+回歸+分割)。Mask R-CNN 是一個 兩階段的框架,第一個階段掃描圖像并生成提議(proposals,即有可能包含一個目標的區域),第二 階段分類提議并生成邊界框和掩碼。
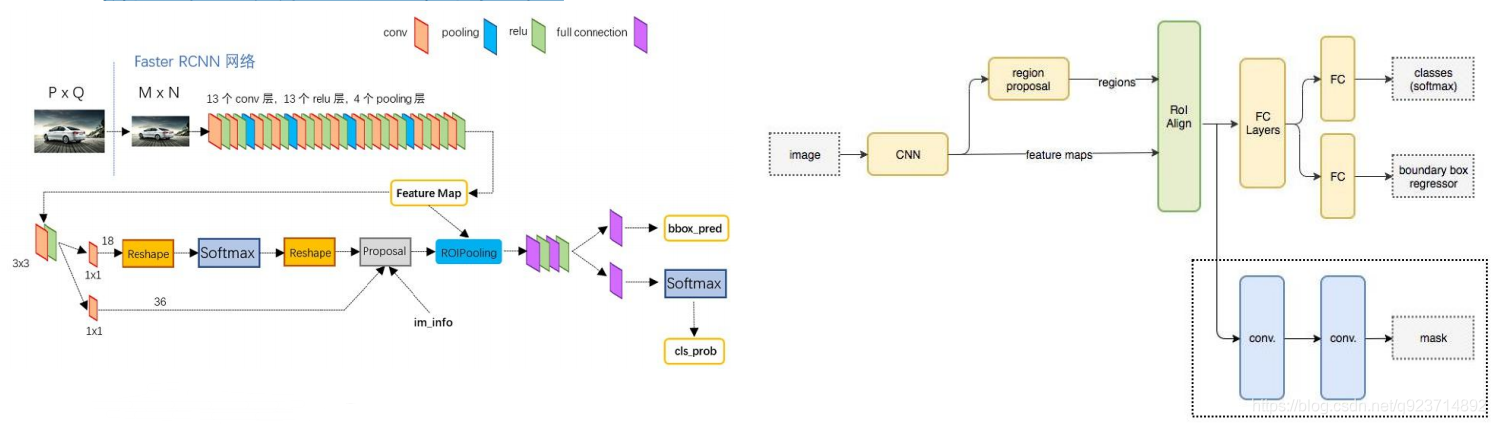
與Faster RCNN的區別:
1)使用ResNet網絡
2)將 Roi Pooling 層替換成了 RoiAlign;
3)添加并列的 Mask 層;
4)引入FPN
Mask R-CNN流程
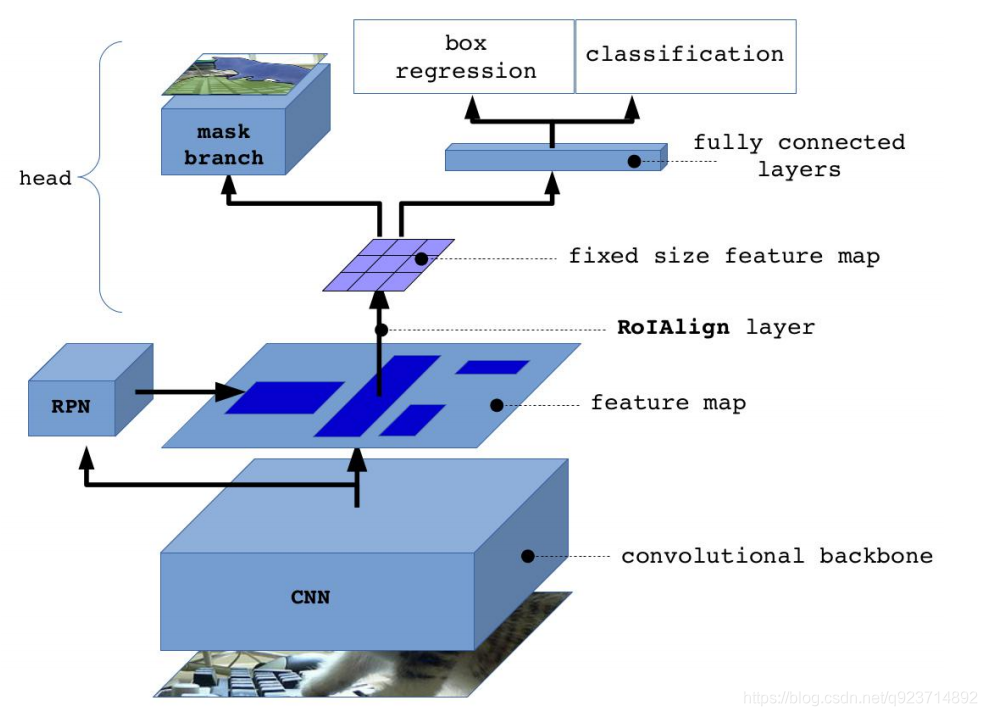
Mask R-CNN 流程:
- 輸入一幅你想處理的圖片,然后進行對應的預處理操作,獲得預處理后的圖片;
- 將其輸入到一個預訓練好的神經網絡中(ResNet等)獲得對應的feature map;
- 對這個feature map中的每一點設定預定個的ROI,從而獲得多個候選ROI;
- 將這些候選的ROI送入RPN網絡進行二值分類(positive或negative)和BB回歸,過濾掉一部分候 選的ROI(截止到目前,Mask和Faster完全相同);
- 對這些剩下的ROI進行ROIAlign操作(ROIAlign為Mask R-CNN創新點1,比ROIPooling有長足進 步);
- 最后,對這些ROI進行分類(N類別分類)、BB回歸和MASK生成(在每一個ROI里面進行FCN操作) (引入FCN生成Mask是創新點2,使得此網絡可以進行分割型任務)。
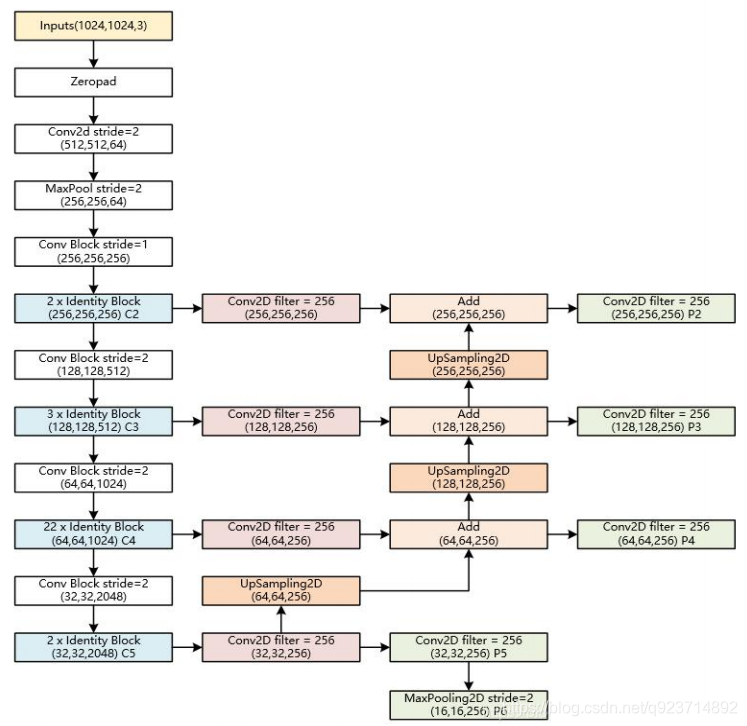
? backbone:Mask-RCNN使用 Resnet101作為主干特征提取網絡, 對應著圖像中的CNN部分。(當然 也可以使用別的CNN網絡)
? 在進行特征提取后,利用長寬壓縮了 兩次、三次、四次、五次的特征層來 進行特征金字塔結構的構造。
Mask R-CNN:Resnet101
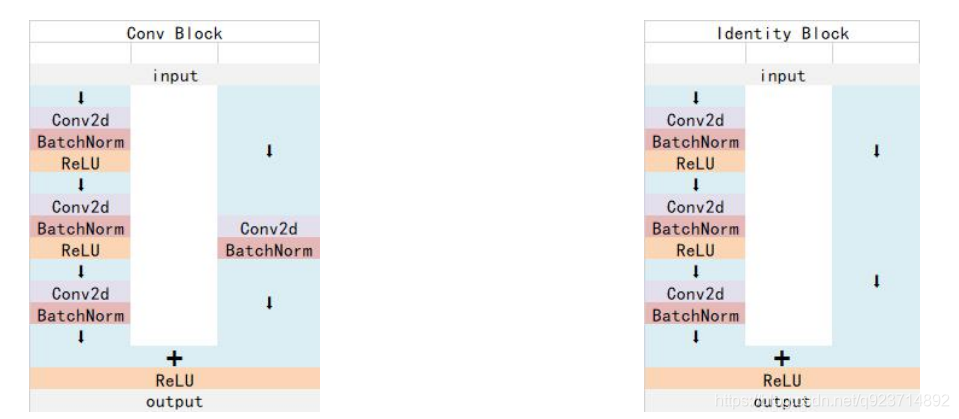
1.Resnet 中 Conv Block和Identity Block的結構:
其中Conv Block輸入和輸出的維度是不一樣的,所以不能連續串聯,它的作用是改變網絡的維度; Identity Block輸入維度和輸出維度相同,可以串聯,用于加深網絡
特征金字塔-Feature Pyramid Networks(FPN)
? 目標檢測任務和語義分割任務里面常常需要檢測小目標。但是當小目標比較小時,可能在原 圖里面只有幾十個像素點。
? 對于深度卷積網絡,從一個特征層卷積到另一個特征層,無論步長是1還是2還是更多,卷積 核都要遍布整個圖片進行卷積,大的目標所占的像素點比小目標多,所以大的目標被經過卷 積核的次數遠比小的目標多,所以在下一個特征層里,會更多的反應大目標的特點。
? 特別是在步長大于等于2的情況下,大目標的特點更容易得到保留,小目標的特征點容易被跳 過。
? 因此,經過很多層的卷積之后,小目標的特點會越來越少。
特征圖(feature map)用藍色輪廓表示, 較粗的輪廓表示語義上更強的特征圖。
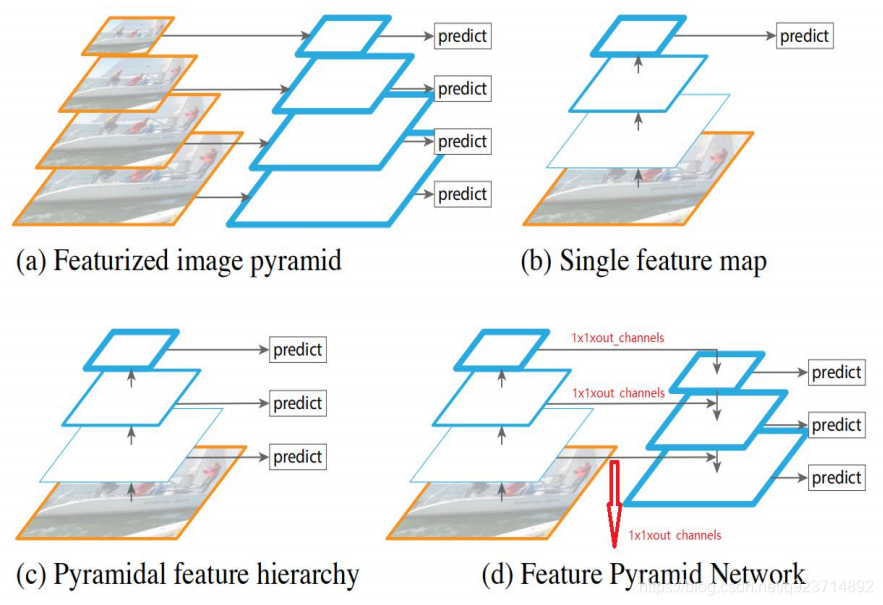
a. 使用圖像金字塔構建特征金字塔。 特征是根據每個不同大小比例的圖 像獨立計算的,每計算一次特征都 需要resize一下圖片大小,耗時, 速度很慢。
b. 檢測系統都在采用的為了更快地檢 測而使用的單尺度特征檢測。
c. 由卷積計算的金字塔特征層次來進 行目標位置預測,但底層feature map特征表達能力不足。
d. 特征金字塔網絡(FPN)和b,c一樣快, 但更準確。
FPN的提出是為了實現更好的feature maps融合,一般的網絡都是直接使用最后一層的feature maps,雖然最后一層的 feature maps 語義強,但是位置和分辨率都比較低,容易 檢測不到比較小的物體。FPN的功能就是融合了底層到高層 的feature maps ,從而充分的利用了提取到的各個階段的 特征(ResNet中的C2-C5)。
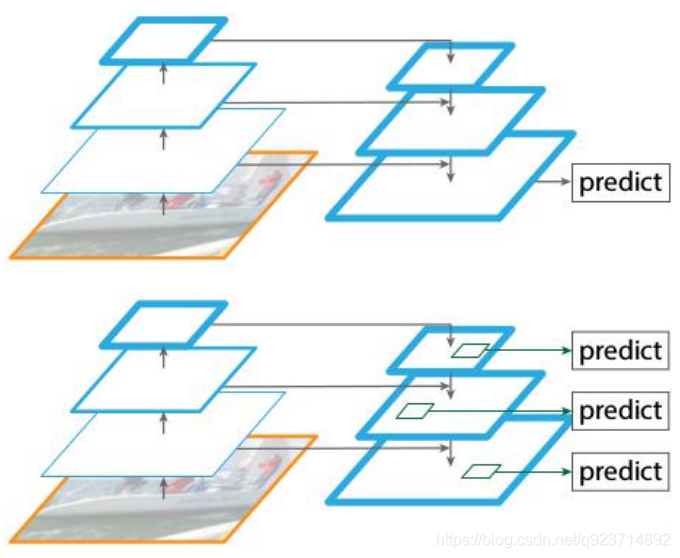
2. 特征金字塔FPN的構建
? 特征金字塔FPN的構建是為了實現特征多 尺度的融合,在Mask R-CNN當中,我們取出在主干特征提取網絡中長寬壓縮了兩次 C2、三次C3、四次C4、五次C5的結果來進 行特征金字塔結構的構造。
? P2-P5是將來用于預測物體的bbox,box- regression,mask的。
? P2-P6是用于訓練RPN的,即P6只用于RPN 網絡中。
Mask R-CNN:Roi-Align
3.Roi-Align
Mask-RCNN中提出了一個新的思想就是RoIAlign,其實RoIAlign就是在RoI pooling上稍微改動過 來的,但是為什么在模型中不繼續使用RoI pooling呢?
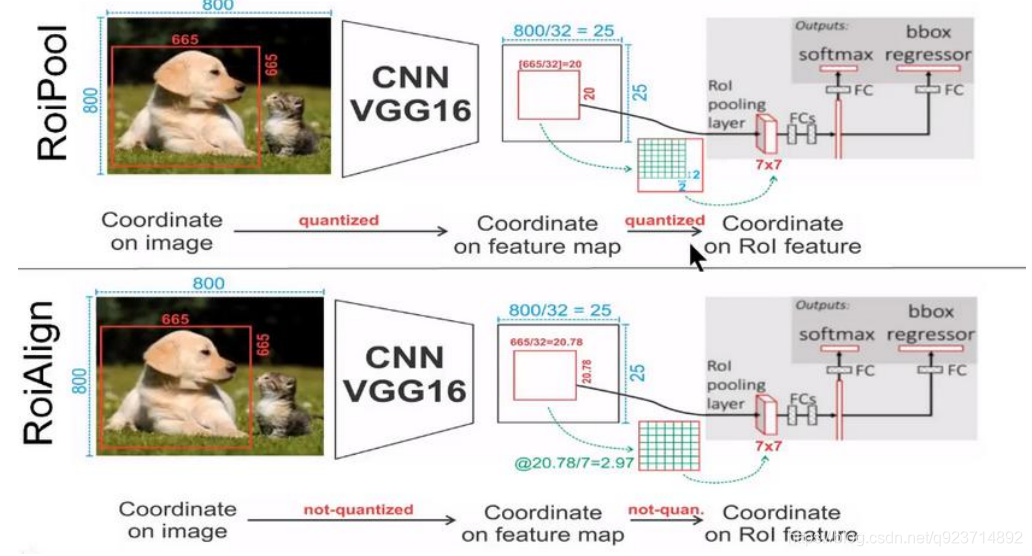
在RoI pooling中出現了兩次的取整,雖然在feature maps上取整看起來只是小數級別的數,但是當 把feature map還原到原圖上時就會出現很大的偏差,比如第一次的取整是舍去了0.78(665/32=20.78),還原到原圖時是20*32=640,第一次取整就存在了25個像素點的偏差,在第二 次的取整后的偏差更加的大。對于分類和物體檢測來說可能這不是一個很大的誤差,但是對于實例分割而言,這是一個非常大的偏差,因為mask出現沒對齊的話在視覺上是很明顯的。而RoIAlign 的提出就是為了解決這個不對齊問題。
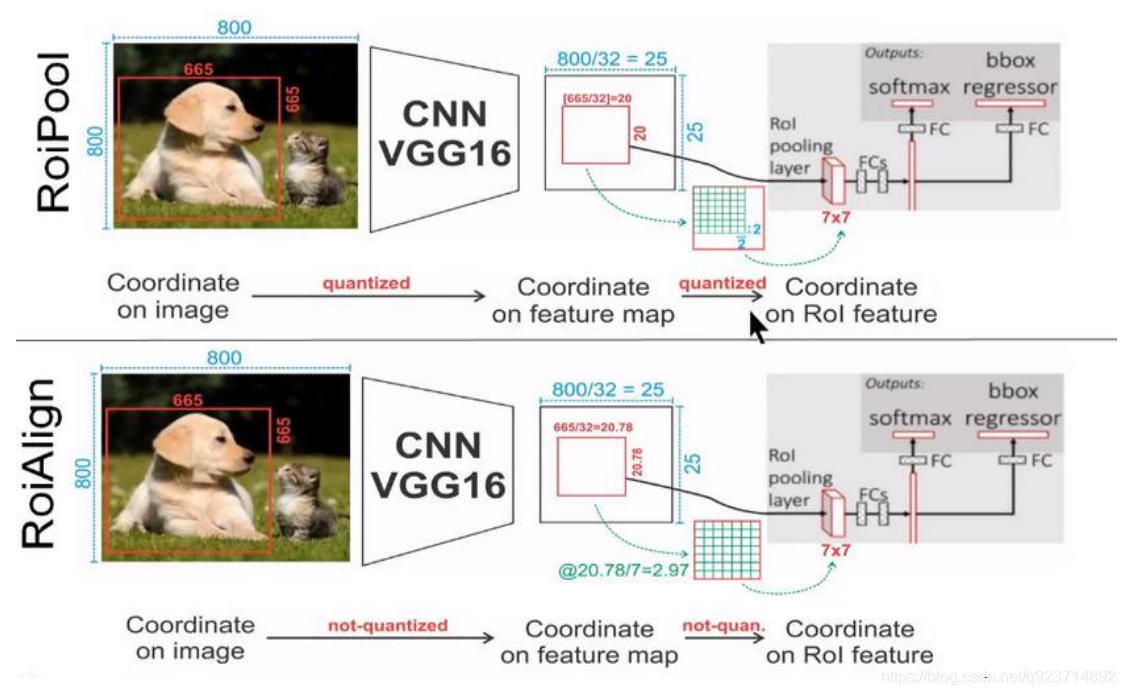
RoIAlign的思想其實很簡單,就是取消了取整的這種粗暴做法,而是通過雙線性插值來得到固定四 個點坐標的像素值,從而使得不連續的操作變得連續起來,返回到原圖的時候誤差也就更加的小。 它充分的利用了原圖中虛擬點(比如20.56這個浮點數。像素位置都是整數值,沒有浮點值)四周 的四個真實存在的像素值來共同決定目標圖中的一個像素值,即可以將20.56這個虛擬的位置點對 應的像素值估計出來。
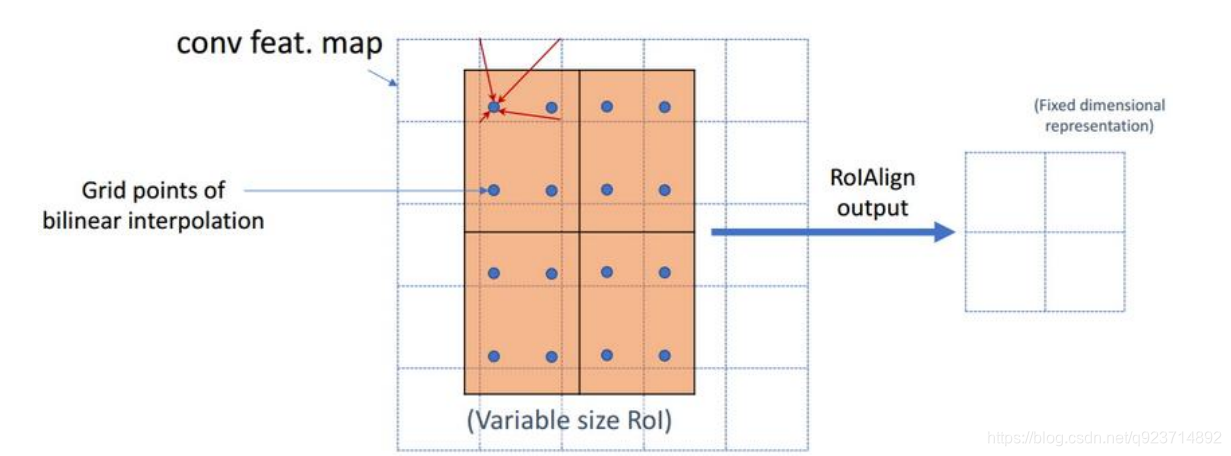
? 藍色的虛線框表示卷積后獲得的feature map,黑色實線框表示ROI feature。
? 最后需要輸出的大小是2x2,那么我們就利用雙線性插值來估計這些藍點(虛擬坐標點,又稱雙線 性插值的網格點)處所對應的像素值,最后得到相應的輸出。
? 然后在每一個橘紅色的區域里面進行max pooling或者average pooling操作,獲得最終2x2的輸出結果。我們的整個過程中沒有用到量化操作,沒有引入誤差,即原圖中的像素和feature map中的 像素是完全對齊的,沒有偏差,這不僅會提高檢測的精度,同時也會有利于實例分割。
Mask R-CNN:分割掩膜
4. 分割掩膜
基于交并比值獲得感興趣區域(ROI)后,給已有框架加上一個掩膜分支,每個囊括特定對象的區域都會被賦予一個掩膜。每個區域都會被賦予一個m×n掩膜,并按比例放大以便推斷。

mask語義分割信息的獲取
在之前的步驟中,我們獲得了預測框,我們把這個預測框作為mask模型的區域截取部分,利用這個預測框對mask模型中用到的公用特征層進行截取。
截取后,利用mask模型再對像素點進行分類,獲得語義分割結果。
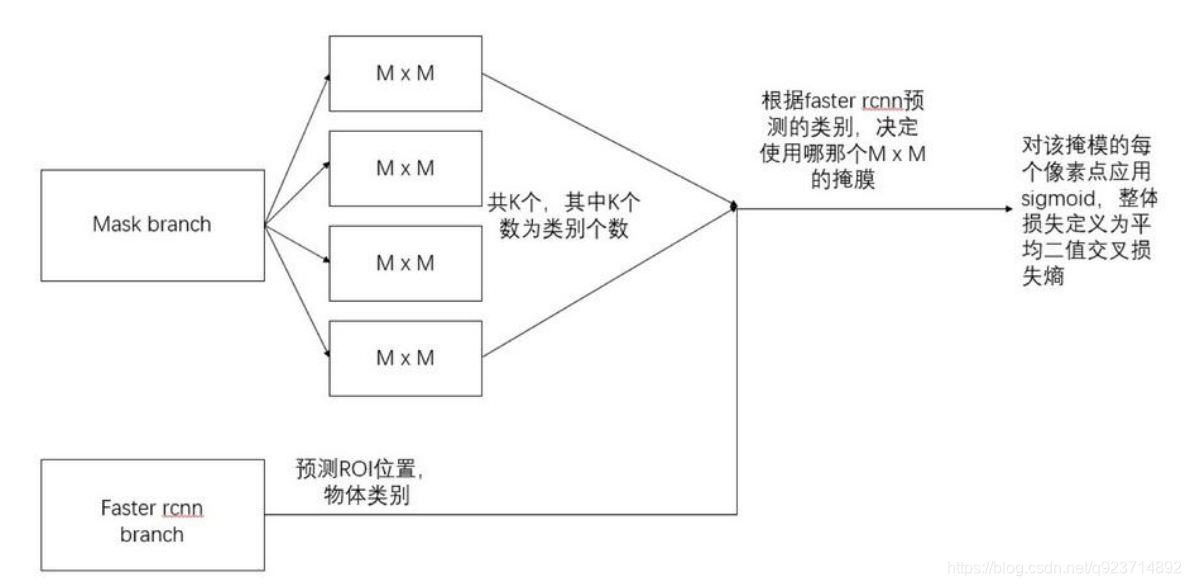
mask分支采用FCN對每個RoI產生一個Kmm的輸出,即K個分辨率為mm的二值的掩膜,K為分類物體的種類數目。
Kmm二值mask結構解釋:最終的FCN輸出一個K層的mask,每一層為一類。用0.5作為閾值進行二值化,產生背景和前景的分割Mask。
對于預測的二值掩膜輸出,我們對每個像素點應用sigmoid函數(或softmax等),整體損失定義為平均二值交叉損失熵。引入預測K個輸出的機制,允許每個類都生成獨立的掩膜,避免類間競爭。這樣做解耦了掩膜和種類預測。
Mask R-CNN的損失函數為:

Lmask 使得網絡能夠輸出每一類的 mask,且不會有不同類別 mask 間的競爭:
? 分類網絡分支預測 object 類別標簽,以選擇輸出 mask。對每一個ROI,如果檢測得到的ROI屬于哪 一個分類,就只使用哪一個分支的交叉熵誤差作為誤差值進行計算。
? 舉例說明:分類有3類(貓,狗,人),檢測得到當前ROI屬于“人”這一類,那么所使用的Lmask為 “人”這一分支的mask,即每個class類別對應一個mask可以有效避免類間競爭(其他class不貢獻Loss)
? 對每一個像素應用sigmoid,然后取RoI上所有像素的交叉熵的平均值作為Lmask。
**最后網絡輸出為1414或者28*28大小的mask,如何與原圖目標對應?**
需要一個后處理,將模型預測的mask通過resize得到與proposal中目標相同大小的mask。

Mask R-CNN—總結
主要改進點:
- 基礎網絡的增強,ResNeXt-101+FPN的組合可以說是現在特征學習的王牌了;
- 分割 loss 的改進, 二值交叉熵會使得每一類的 mask 不相互競爭,而不是和其他類別的 mask 比較 ;
- ROIAlign解決不對齊的問題,就是對 feature map 的插值。直接的ROIPooling的那種量化操作會使得 得到的mask與實際物體位置有一個微小偏移,是工程上更好的實現方式。
Mask R-CNN:COCO數據集
MS COCO的全稱是Microsoft Common Objects in Context,起源于微軟于2014年出資標注的 Microsoft COCO數據集,與ImageNet競賽一樣,被視為是計算機視覺領域最受關注和最權威的 比賽之一。
COCO數據集是一個大型的、豐富的物體檢測,分割和字幕數據集。這個數據集以scene understanding為目標,主要從復雜的日常場景中截取圖像中的目標,通過精確的segmentation 進行位置的標定。
包括:
- 對象分割;
- 在上下文中可識別;
- 超像素分割;
- 330K圖像(> 200K標記);
- 150萬個對象實例;
- 80個對象類別;
- 91個類別;
- 每張圖片5個字幕;
- 有關鍵點的250,000人;
代碼實現
在資源中







)









)

