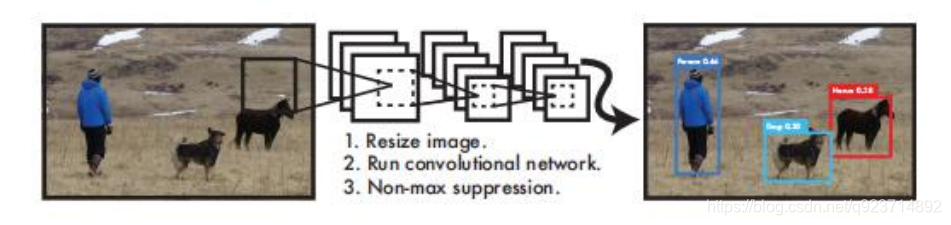
Yolo-You Only Look Once
YOLO算法采用一個單獨的CNN模型實現end-to-end的目標檢測:
- Resize成448448,圖片分割得到77網格(cell)
- CNN提取特征和預測:卷積部分負責提取特征。全鏈接部分負責預測:
- 過濾bbox(通過nms)
? YOLO算法整體來說就是把輸入的圖片劃分為SS格子,這里是33個格子。
? 當被檢測的目標的中心點落入這個格子時,這個格子負責檢測這個目標,如圖中的人。
? 我們把這個圖片輸入到網絡中,最后輸出的尺寸也是SSn(n是通道數),這個輸出的SS與原輸 入圖片SS相對應(都是33)。
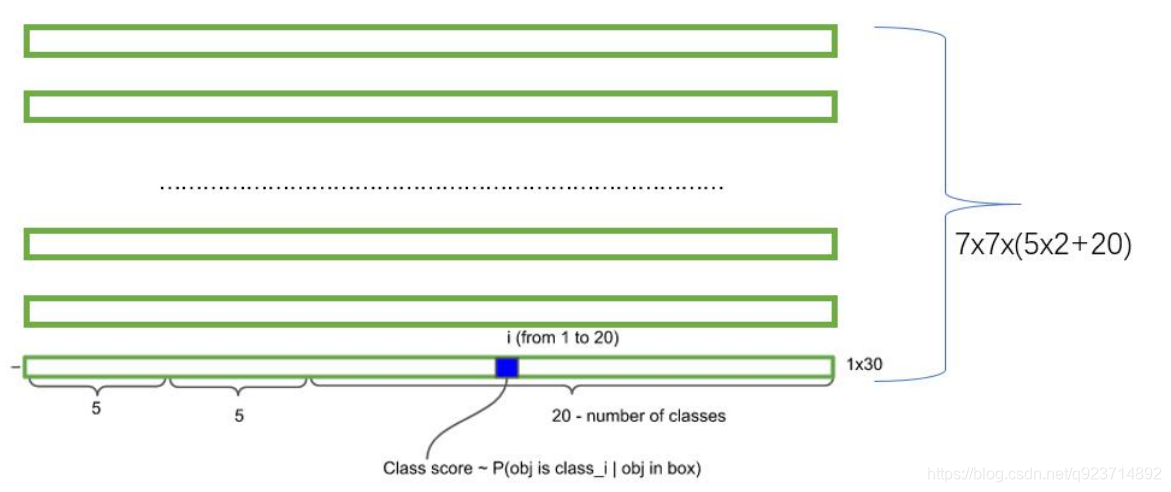
? 假如我們網絡一共能檢測20個類別的目標,那么輸出的通道數n=2(4+1)+20=30。這里的2指 的是每個格子有兩個標定框(論文指出的),4代表標定框的坐標信息, 1代表標定框的置信度, 20是檢測目標的類別數。
? 所以網絡最后輸出結果的尺寸是SSn=3330。
關于標定框:
? 網絡的輸出是S x S x (5*B+C) 的一個 tensor(S-尺寸,B- 標定框個數,C-檢測類別數,5-標定框的信息)。
? 5分為4+1:
? 4代表標定框的位置信息。框的中心點(x,y),框的高寬 h,w。
? 1表示每個標定框的置信度以及標定框的準確度信息。
一般情況下,YOLO 不會預測邊界框中心的確切坐標。它預測:
?與預測目標的網格單元左上角相關的偏移;
?使用特征圖單元的維度進行歸一化的偏移。
例如: 以上圖為例,如果中心的預測是 (0.4, 0.7),則中心在 13 x 13 特征圖上的坐標是 (6.4, 6.7)(紅色單 元的左上角坐標是 (6,6))。
但是,如果預測到的 x,y 坐標大于 1,比如 (1.2, 0.7)。那么預測的中心坐標是 (7.2, 6.7)。注意該中心在紅色單元右側的單元中。這打破了 YOLO 背后的理論,因為如果我們假設紅色框負責預測目 標狗,那么狗的中心必須在紅色單元中,不應該在它旁邊的網格單元中。 因此,為了解決這個問題,我們對輸出執行 sigmoid 函數,將輸出壓縮到區間 0 到 1 之間,有效 確保中心處于執行預測的網格單元中。
每個標定框的置信度以及標定框的準確度信息:
左邊代表包含這個標定框的格子里是否有目標。有=1沒有=0。 右邊代表標定框的準確程度, 右邊的部分是把兩個標定框(一個是Ground truth一個是預測的標 定框)進行一個IOU操作,即兩個標定框的交集比并集,數值越大,即標定框重合越多,越準確。
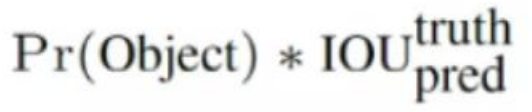
我們可以計算出各個標定框的類別置信度(class-specific confidence scores/ class scores): 表達的是該標定框中目標屬于各個類別的可能性大小以及標定框匹配目標的好壞。
每個網格預測的class信息和bounding box預測的confidence信息相乘,就得到每個bounding box 的class-specific confidence score。
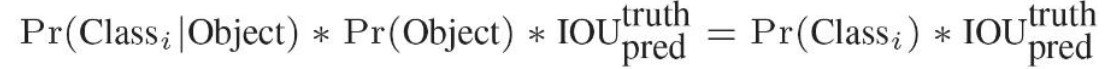
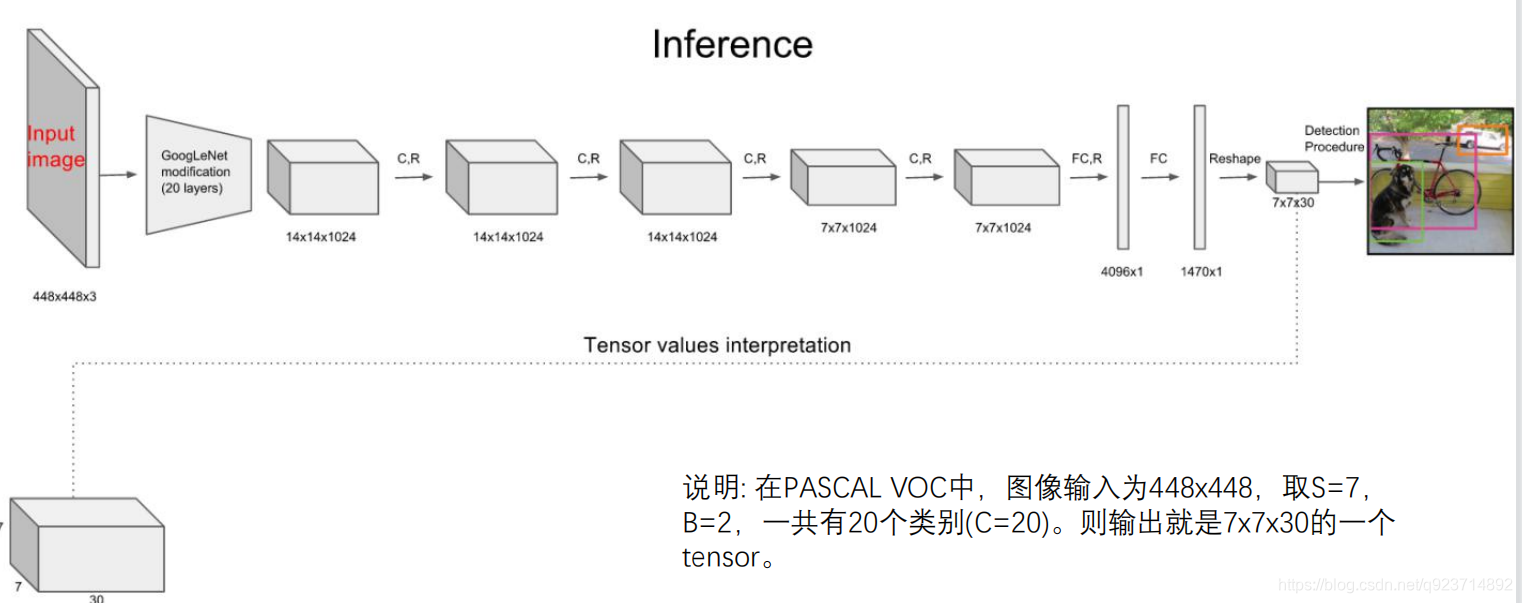
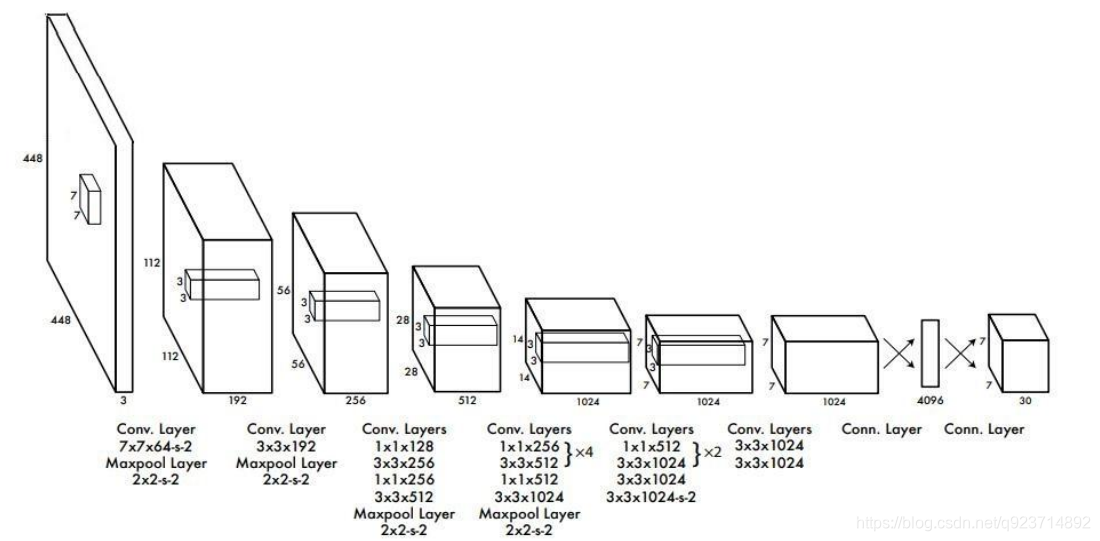
? 其進行了二十多次卷積還有四次最大池化。其中3x3卷積用于提取特征,1x1卷積用于壓縮特征,最后將圖像 壓縮到7x7xfilter的大小,相當于將整個圖像劃分為7x7的網格,每個網格負責自己這一塊區域的目標檢測。
? 整個網絡最后利用全連接層使其結果的size為(7x7x30),其中7x7代表的是7x7的網格,30前20個代表的是預測 的種類,后10代表兩個預測框及其置信度(5x2)。
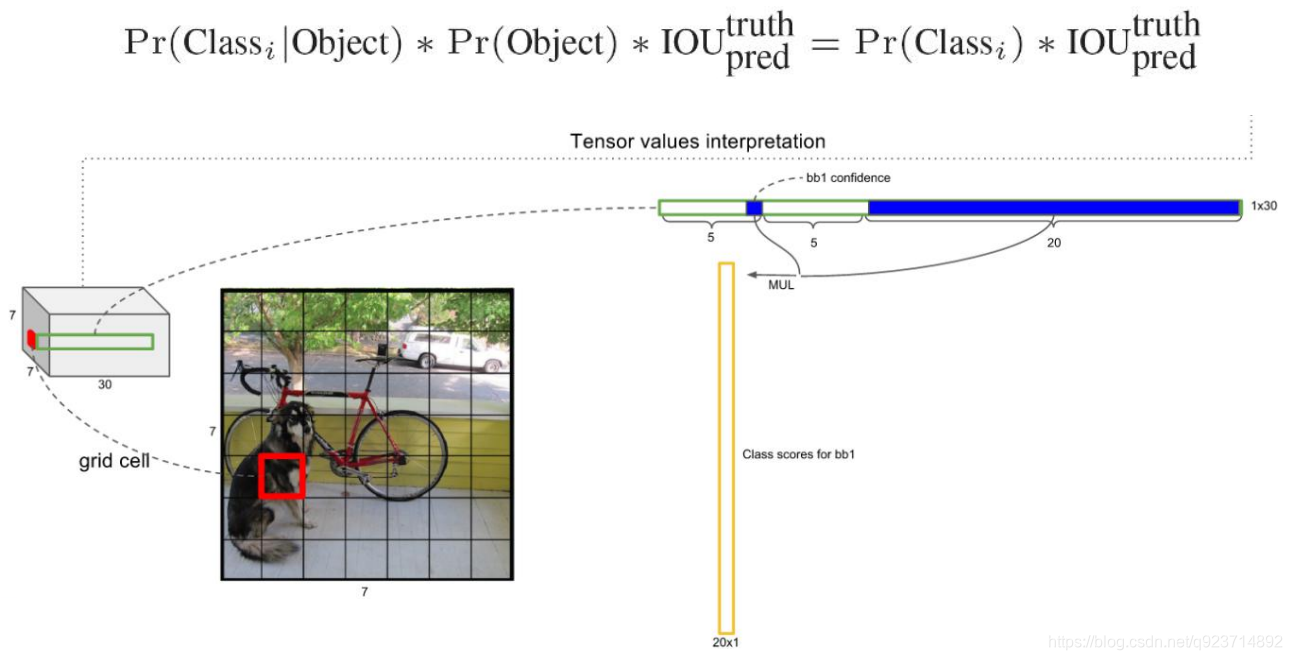
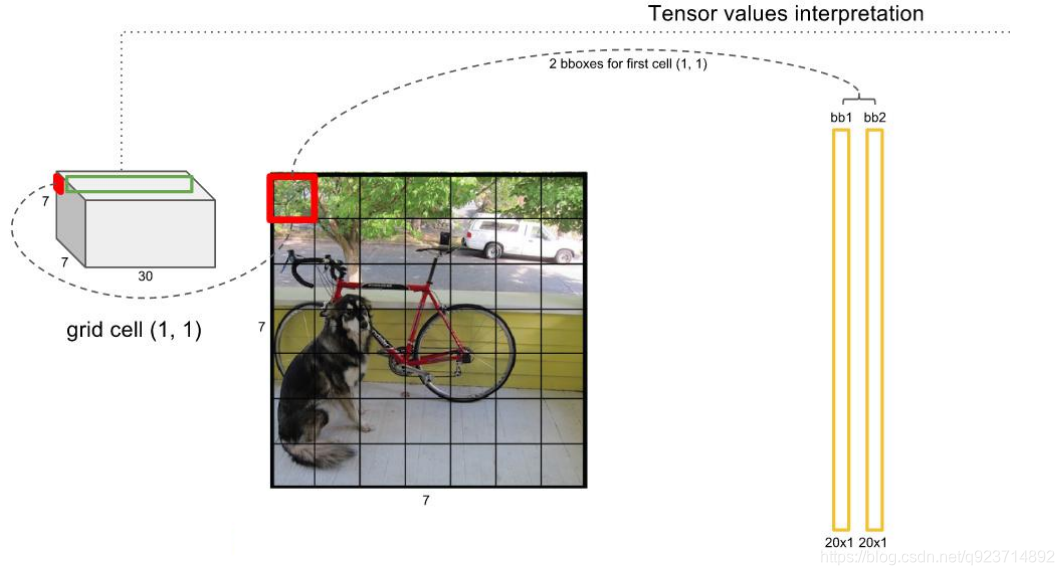
對每一個網格的每一個bbox執行同樣操作: 7x7x2 = 98 bbox (每個bbox既有對應的class信息又有坐標信息)
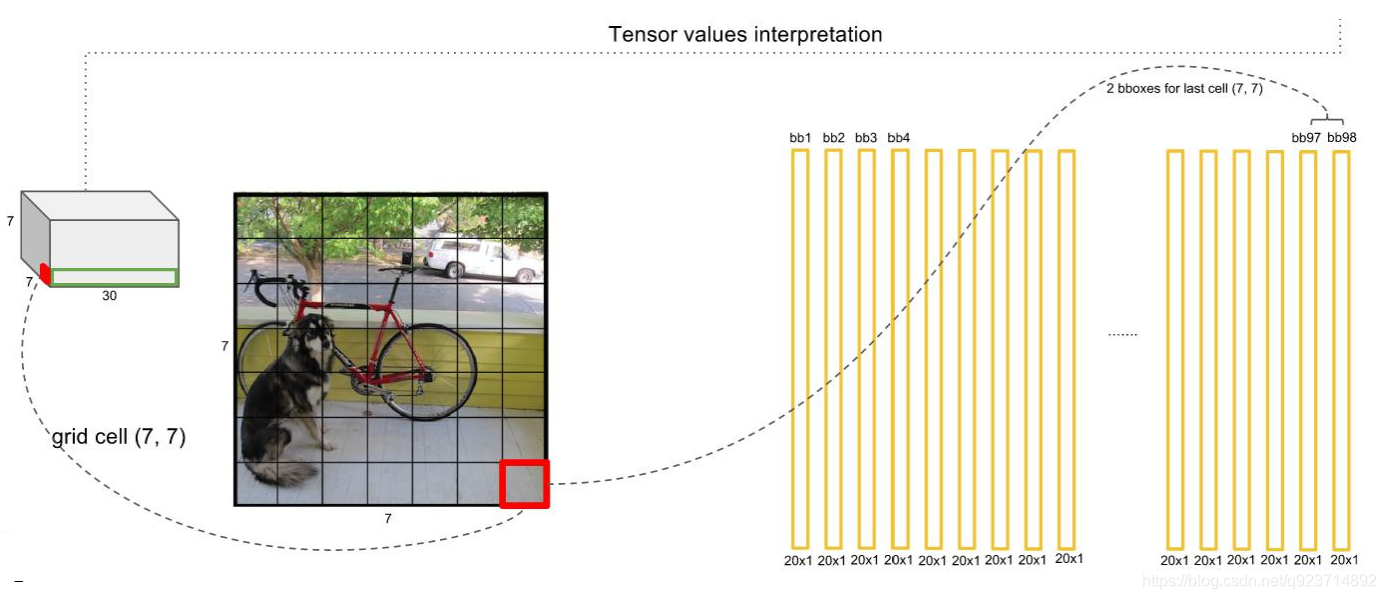
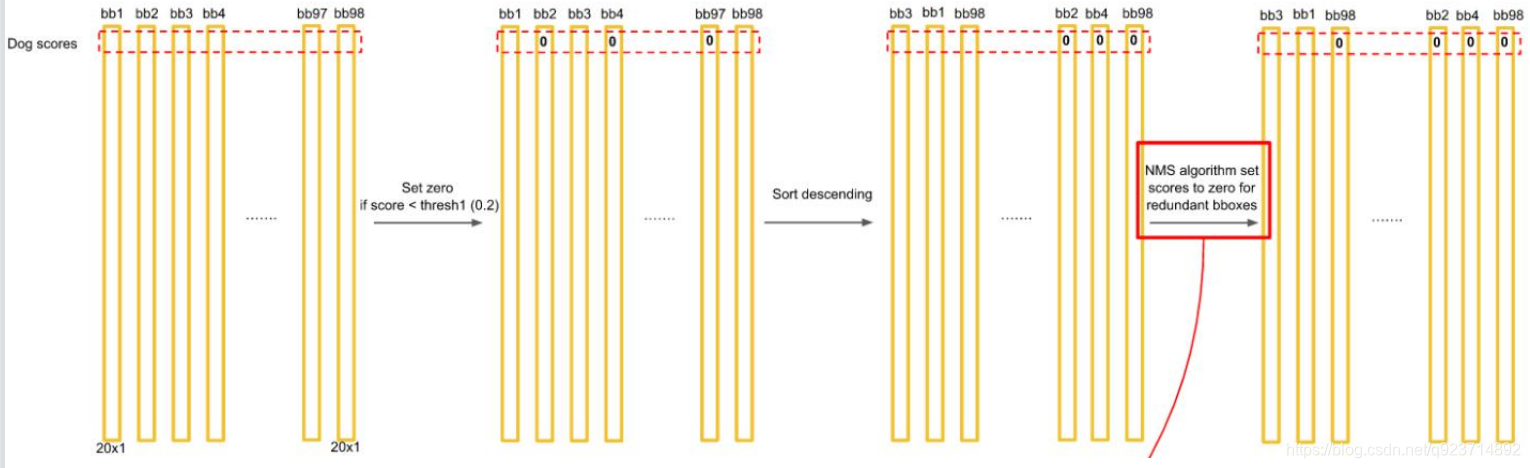
得到每個bbox的class-specific confidence score以后,設置閾值,濾掉得分低的boxes,對保留的 boxes進行NMS處理,就得到最終的檢測結果。
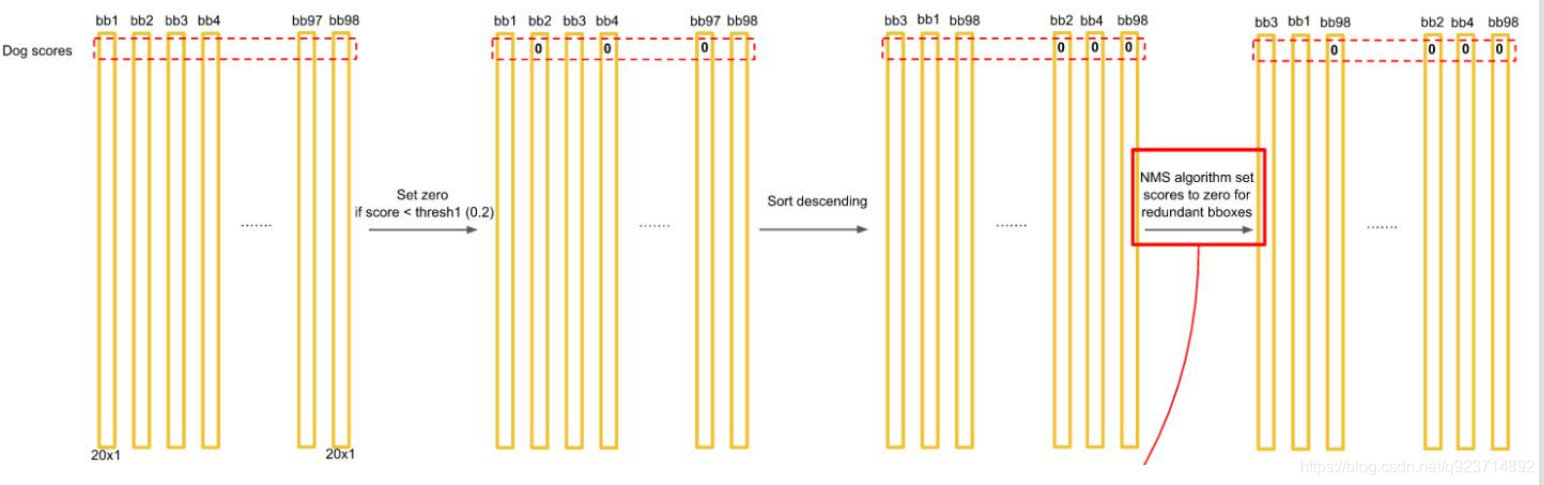
排序后,不同位置的框內,概率不同:
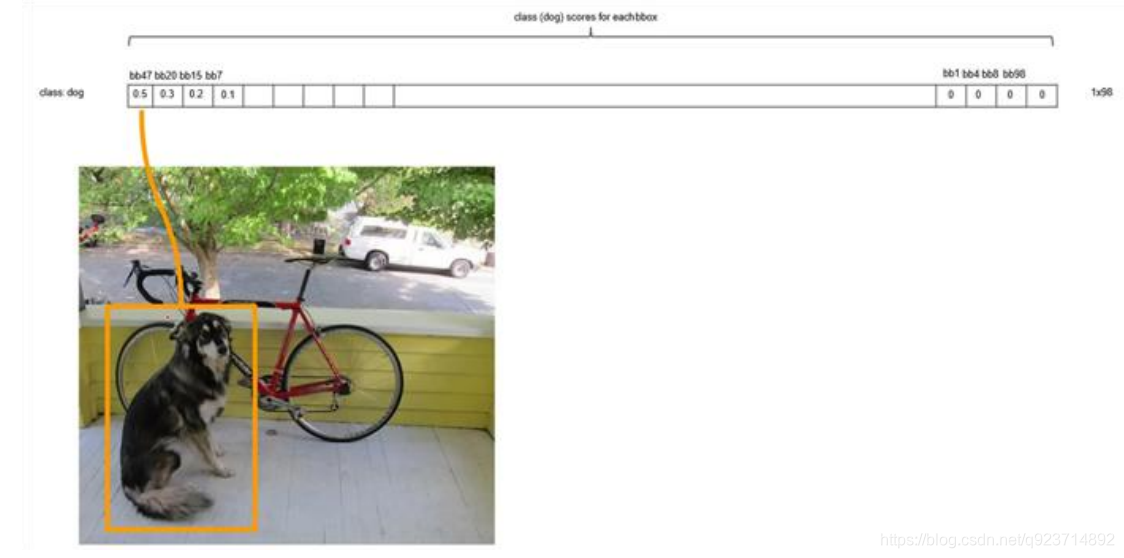
以最大值作為bbox_max,并與比它小的非0值(bbox_cur)做比較:IOU
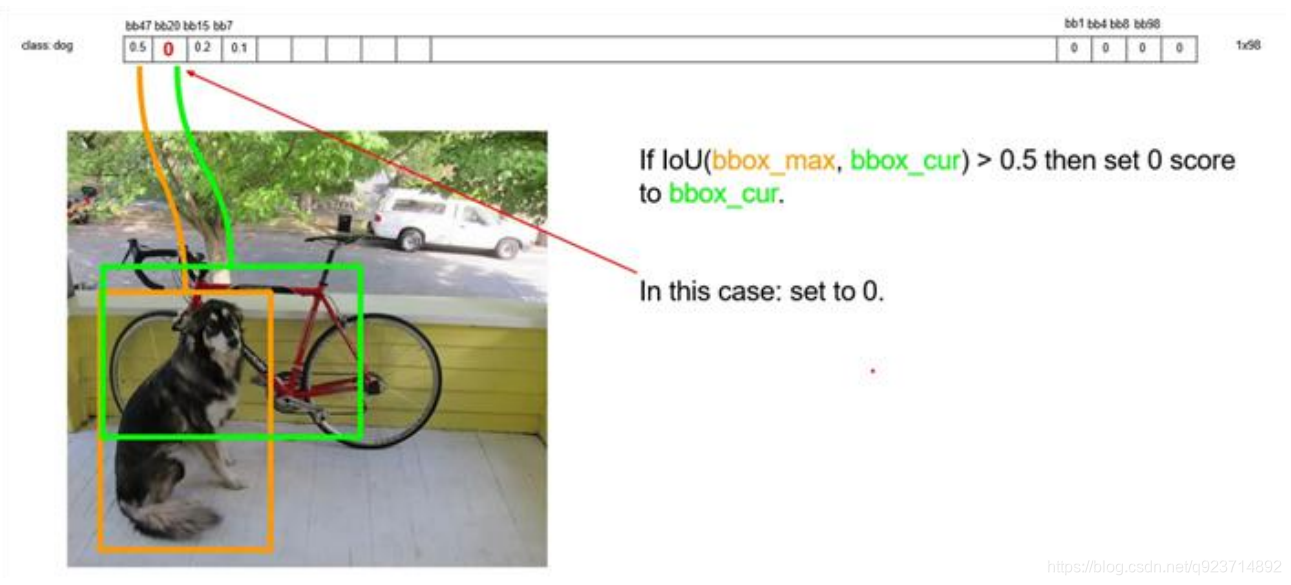
遞歸,以下一個非0 bbox_cur(0.2)作為bbox_max繼續比較IOU:

最終,剩下n個框。
得到每個bbox的class-specific confidence score以后,設置閾值,濾掉得分低的boxes,對保留的boxes進行NMS處理,就得到最終的檢測結果。
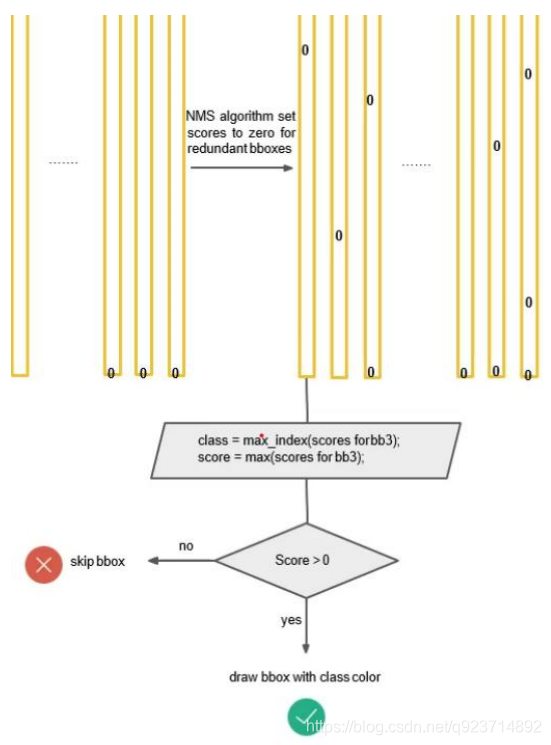
對bb3(20×1)類別的分數,找分數對應最大類別的索引.---->class bb3(20×1)中最大的分---->score
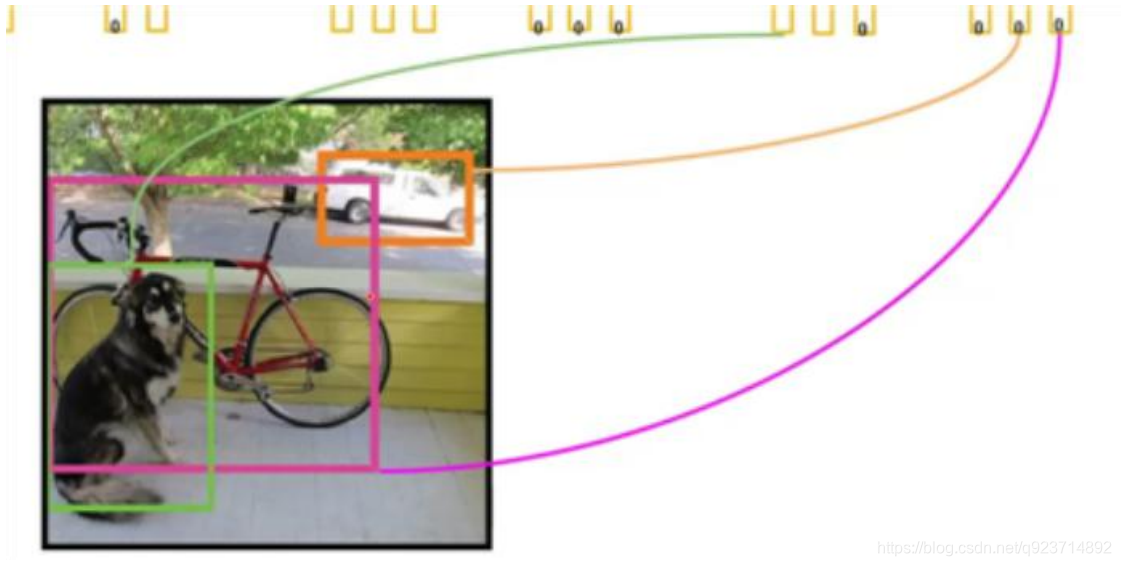
根據不同類劃分不同的框:
Yolo的缺點:
?YOLO對相互靠的很近的物體(挨在一起且中點都落在同一個格子上的情況),還有很小的 群體檢測效果不好,這是因為一個網格中只預測了兩個框,并且只屬于一類。
?測試圖像中,當同一類物體出現不常見的長寬比和其他情況時泛化能力偏弱。
Yolo2
1.Yolo2使用了一個新的分類網絡作為特征提取部 分。
2. 網絡使用了較多的3 x 3卷積核,在每一次池化操 作后把通道數翻倍。
3. 把1 x 1的卷積核置于3 x 3的卷積核之間,用來壓 縮特征。
4. 使用batch normalization穩定模型訓練,加速收 斂。
5. 保留了一個shortcut用于存儲之前的特征。
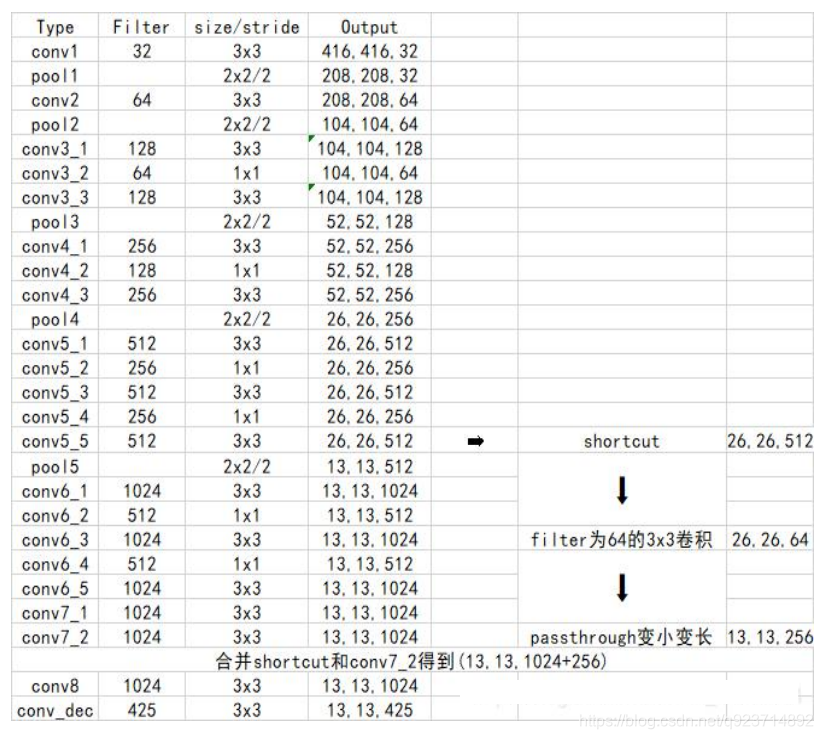
6. 除去網絡結構的優化外,yolo2相比于yolo1加入 了先驗框部分,最后輸出的conv_dec的shape為 (13,13,425):
? 13x13是把整個圖分為13x13的網格用于預測。
? 425可以分解為(85x5)。在85中,由于yolo2常 用的是coco數據集,其中具有80個類;剩余 的5指的是x、y、w、h和其置信度。x5意味著 預測結果包含5個框,分別對應5個先驗框。
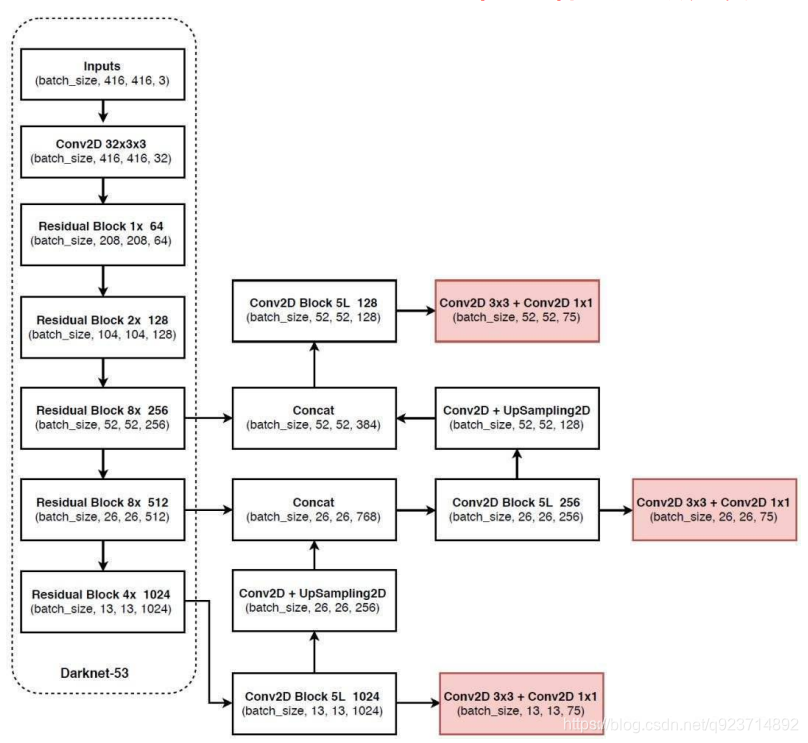
Yolo3
YOLOv3相比于之前的yolo1和yolo2,改進較大,主要 改進方向有:
1、使用了殘差網絡Residual
2、提取多特征層進行目標檢測,一共提取三個特征 層,它的shape分別為(13,13,75),(26,26,75), (52,52,75)。最后一個維度為75是因為該圖是基于voc 數據集的,它的類為20種。yolo3針對每一個特征層 存在3個先驗框,所以最后維度為3x25。
3、其采用反卷積UpSampling2d設計,逆卷積相對于 卷積在神經網絡結構的正向和反向傳播中做相反的運 算,其可以更多更好的提取出特征。
代碼實現:
在資源中
實現結果如下

















)


