人臉檢測-mtcnn
概念:
MTCNN,英文全稱是Multi-task convolutional neural network,中文全稱是多任務卷積神經網絡, 該神經網絡將人臉區域檢測與人臉關鍵點檢測放在了一起。
從工程實踐上,MTCNN是一種檢測速度和準確率都很不錯的算法,算法的推斷流程有一定的啟發性。

總體可分為P-Net、R-Net、和O-Net三層網絡結構。
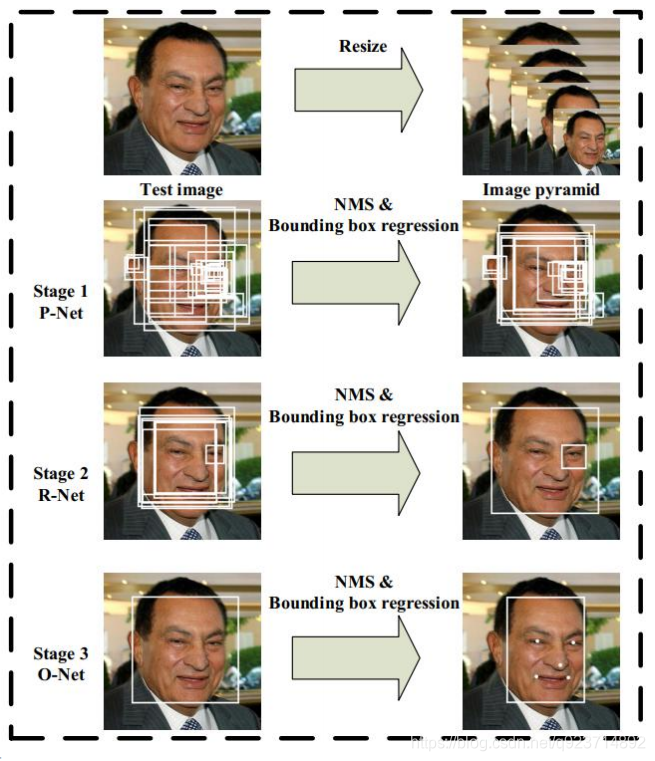
流程:
1.由原始圖片和PNet生成預測的bounding boxes。
2.輸入原始圖片和PNet生成的bounding box,通過RNet,生成校正后的bounding box。
3.輸入原始圖片和RNet生成的bounding box,通過ONet,生成校正后的bounding box和人臉面部輪 廓關鍵點。
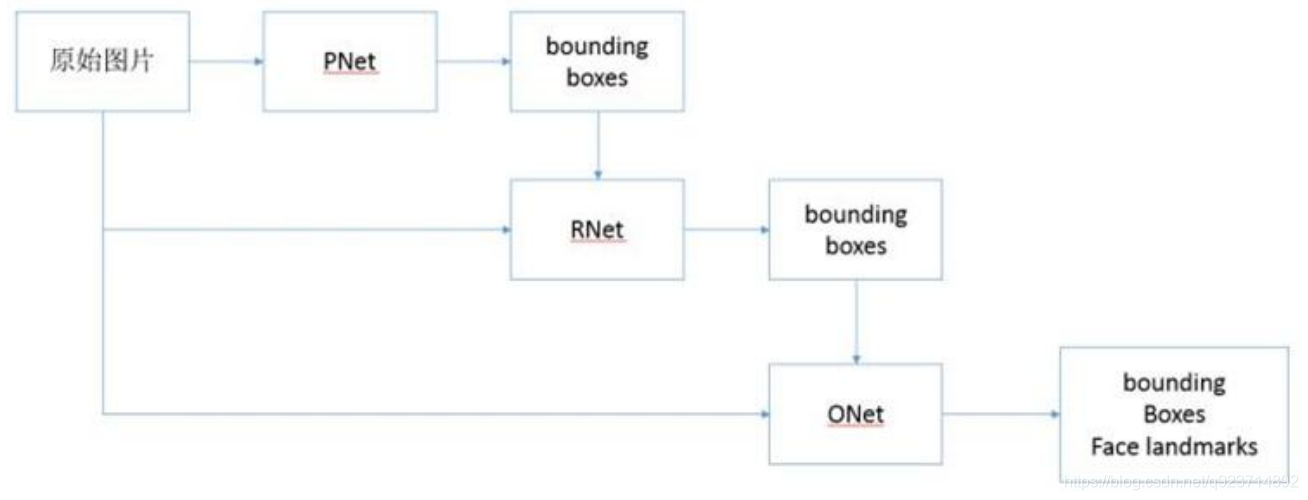
MTCNN主要包括三層網絡:
- 第一層P-Net將經過卷積,池化操作后輸出分類(對應像素點是否存在人臉)和回歸(回歸 box)結果。
- 第二層網絡將第一層輸出的結果使用非極大抑制(NMS)來去除高度重合的候選框,并將這些 候選框放入R-Net中進行精細的操作,拒絕大量錯誤框,再對回歸框做校正,并使用NMS去除 重合框,輸出分支同樣兩個分類和回歸。
- 最后將R-Net輸出認為是人臉的候選框輸入到O-Net中再一次進行精細操作,拒絕掉錯誤的框, 此時輸出分支包含三個分類:
a. 是否有人臉:2個輸出;
b. 回歸:回歸得到的框的起始點的xy坐標和框的長寬,4個輸出;
c. 人臉特征點定位:5個人臉特征點的xy坐標,10個輸出。
注:三段網絡都有NMS,但是所設閾值不同。
1、構建圖像金字塔
首先對圖片進行Resize操作,將原始圖像縮放成不同的尺度,生成圖像金字塔。然后將不同尺度的圖 像送入到這三個子網絡中進行訓練,目的是為了可以檢測到不同大小的人臉,從而實現多尺度目標檢測。
構建方式是通過不同的縮放系數factor分別對圖片的h和w進行縮放,每次縮小為原來的factor大小。
注意:縮小后的長寬最小不可以小于12。
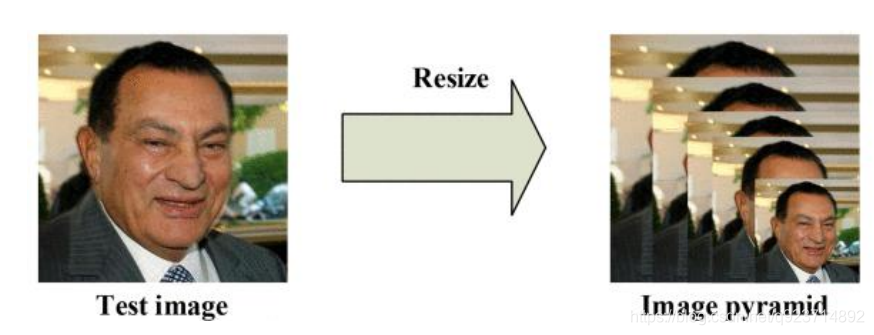
為什么需要對圖片做“金字塔”變換?
圖片中的人臉的尺度有大有小,讓識別算法不被目標尺度影響一直是個挑戰。
MTCNN使用了圖像金字塔來解決目標多尺度問題,即把原圖按照一定的比例(如0.709),多次等比 縮放得到多尺度的圖片,很像個金字塔。
P-NET的模型是用單尺度(1212)的圖片訓練出來的。推理的時候,縮小后的長寬最小不可以小于12。
對多個尺度的輸入圖像做訓練,訓練是非常耗時的。因此通常只在推理階段使用圖像金字塔,提高算法的精度。
設置合適的最小人臉尺寸和縮放因子為什么可以優化計算效率?
? factor是指每次對邊縮放的倍數。
? 第一階段會多次縮放原圖得到圖片金字塔,目的是為了讓縮放后圖片中的人臉與P-NET訓練時候的圖片尺度(12px * 12px)接近。
? 引申優化項:先把圖像縮放到一定大小,再通過factor對這個大小進行縮放。可以減少計算量。
? minsize是指你認為圖片中需要識別的人臉的最小尺寸(單位:px)。
? 注:代碼中使用的是“引申優化項“的策略。
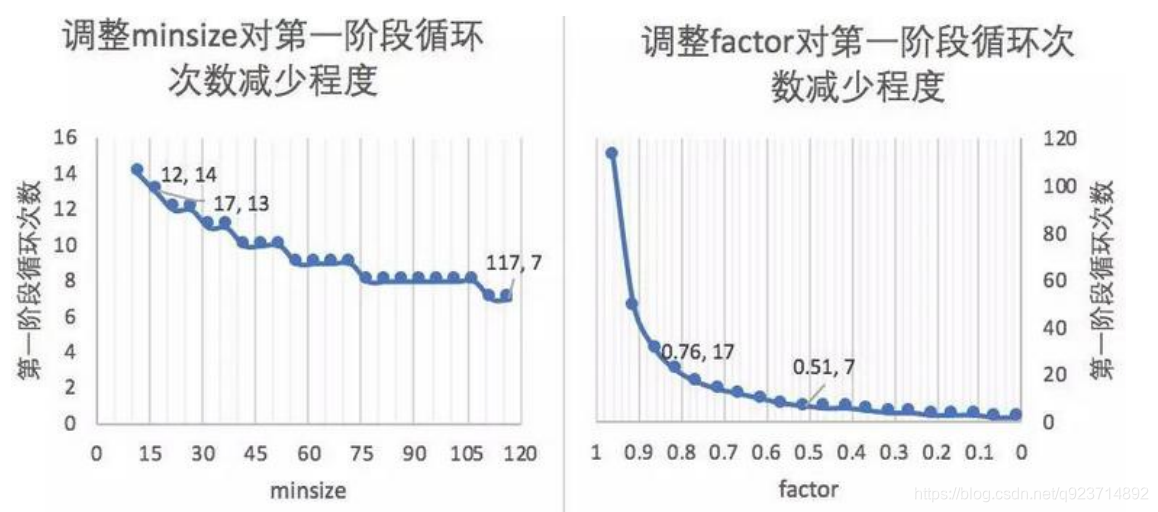
圖例:如果待測圖片1200px1200px,想要讓縮放后的尺寸接近模型訓練圖片的尺度(12px*12px)。
縮放因子為什么官方選擇0.709?
? 圖片金字塔縮放時,如果默認把寬,高都變為原來的1/2,縮放后面積變為原來的1/4;
? 如果認為1/4的縮放幅度太大,你會怎么辦?—把面積縮放為原來的1/2。
? 這是很直觀的想法,所以這里的縮放因子0.709 ≈ sqrt(2)/2,這樣寬高變為原來的sqrt(2)/2, 面積就變為原來的1/2。
? 從實際意義上看,factor應該設置為小于1。
圖像金字塔的缺點:
慢。
- 第一,生成圖片金字塔慢;
- 第二,每種尺度的圖片都需要輸入進模型,相當于執行了多次的模型推理流程。
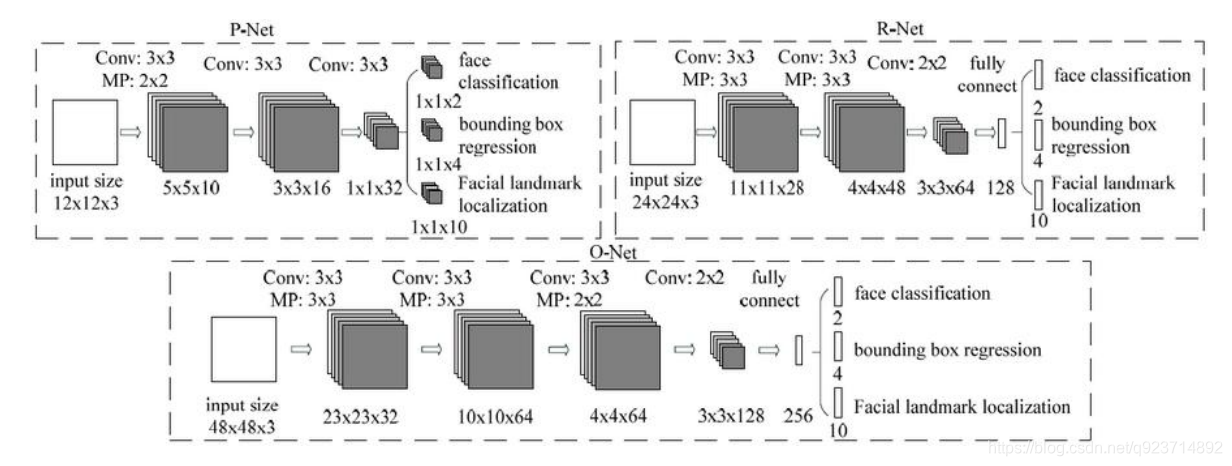
2、P-Net(Proposal Network)
其基本的構造是一個全卷積網絡。對上一步構建完成的圖像金字塔,通過一個FCN(全卷積網絡) 進行初步特征提取與標定邊框。
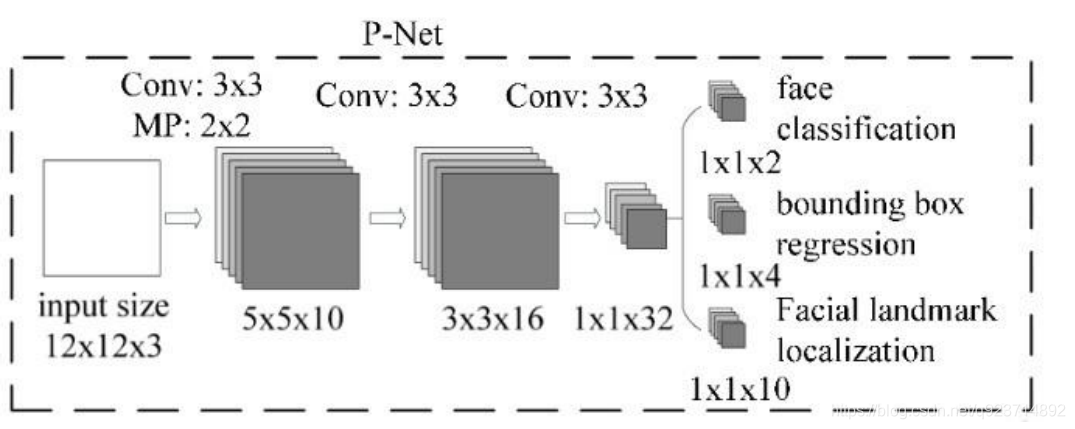
MTCNN算法可以接受任意尺度的圖片,為什么?
? 因為第一階段的P-NET是一個全卷積網絡(Fully Convolutional Networks)。
? 卷積、池化、非線性激活都是一些可以接受任意尺度矩陣的運算,但全連接運算是需要規定輸入。 如果網絡中有全連接層,則輸入的圖片尺度(一般)需固定;如果沒有全連接層,圖片尺度可以是任 意的。
? 在推理的時候,測試圖像中人臉區域的尺度未知。但是因為P網結構是固定的,當輸入圖為1212時, 輸出的恰好是11的5通道特征圖,所以可以把p網整體看做一個1212的卷積核在圖片上從左上方開 始,取步長stride=2,依次做滑窗操作。——>所以,當剛開始圖很大的時候,1212的框可能只是 框住了一張大臉上的某個局部如眼睛、耳朵、鼻子。當該圖不斷縮至很小的時候(圖像金字塔), 12*12的框能對其框住的也越來越全,直至完全框住了整張臉。
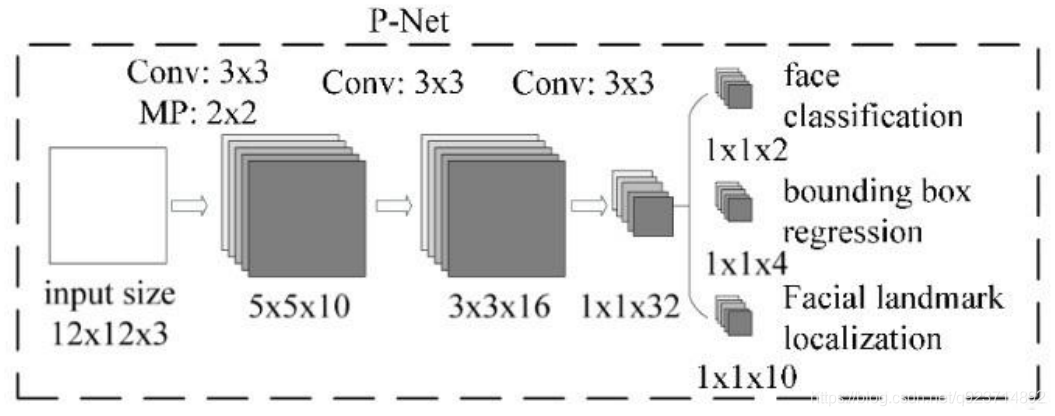
? 3次卷積和1次池化操作后,原來12123的矩陣變為1132
? 利用這個1132的向量,再通過一個112的卷積,得到了”是否是人臉”的分類結果
? 我們令輸入圖片矩陣為A,卷積核在原圖矩陣A上滑動,把每個12123區域的矩陣都計算成該區域有 無人臉的得分,最后可以得到一個二維矩陣為S,S每個元素的值是[0, 1]的數,代表有人臉的概率。即 A通過一系列矩陣運算,變化到S。
P-Net的輸出:
- 網絡的第一部分輸出是用來判斷該圖像是否存在人臉,輸出向量大小1x1x2,也就是兩個值。
- 網絡的第二部分給出框的精確位置,即邊框回歸:P-Net輸入的12×12的圖像塊可能并不是完美的 人臉框的位置,如有的時候人臉并不正好為方形,有可能12×12的圖像偏左或偏右,因此需要輸出 當前框位置相對完美的人臉框位置的偏移。這個偏移大小為1×1×4,即表示框左上角的橫坐標的相 對偏移,框左上角的縱坐標的相對偏移、框的寬度的誤差、框的高度的誤差。
- 網絡的第三部分給出人臉的5個關鍵點的位置。5個關鍵點分別對應著左眼的位置、右眼的位置、 鼻子的位置、左嘴巴的位置、右嘴巴的位置。每個關鍵點需要兩維來表示,因此輸出是向量大小 為1×1×10。
舉例:
一張7070的圖,經過P網絡全卷積后,輸出為(70-2)/2 -2 -2 =30,即一個5通道的3030的特征 圖。這就意味著該圖經過p的一次滑窗操作,得到了30*30=900個建議框,而每個建議框對應1個置 信度cond與4個偏移量offset。再經nms(非極大值抑制:通過iou,把不是極大值的值全都殺掉)把 cond大于設定的閾值0.6對應的建議框保留下來,將其對應的offset經邊框回歸操作,得到在原圖中 的坐標信息,即得到符合p網的這些建議框了。之后再傳給R網。
3、R-Net(Refine Network):
從網絡圖可以看到,只是由于該網絡結構和P-Net網絡結構有差異,多了一個全連接層,所以會取得更好的抑制false-positive的作用。在輸入R-Net之前,都需要縮放到24x24x3,網絡的輸出與P- Net是相同的,R-Net的目的是為了去除大量的非人臉框。
4、O-Net(Output Network):
該層比R-Net層又多了一層卷積層,所以處理的結果會更加精細。輸入的圖像大小48x48x3,輸出包括N個邊界框的坐標信息,score以及關鍵點位置。
總結:
從P-Net到R-Net,再到最后的O-Net,網絡輸入的圖像越來越大,卷積層的通道數越來越多,網絡的深度(層數)也越來越深,因此識別人臉的準確率應該也是越來越高的。
實現:
MTCNN人臉檢測的訓練數據可以從http://mmlab.ie.cuhk.edu.hk/projects/WIDERFace/地址下載。該數據集有32,203張圖片,共有93,703張臉被標記。

完整代碼在資源中。
實現結果如下:












)







