先知模型 facebook
Time series prediction is one of the must-know techniques for any data scientist. Questions like predicting the weather, product sales, customer visit in the shopping center, or amount of inventory to maintain, etc - all about time series forecasting, making it a valuable addition to a data scientist’s skillsets.
時間序列預測是任何數據科學家都必須了解的技術之一。 諸如預測天氣,產品銷售,購物中心的顧客來訪或要維護的庫存量之類的問題都與時間序列預測有關,這使其成為數據科學家技能的寶貴補充。
In this article, I will introduce how to use Facebook Prophet to predict the crime rate in Chicago. Split into 5 parts:
在本文中,我將介紹如何使用Facebook Prophet預測芝加哥的犯罪率。 分為5部分:
1. Prophet Introduction
1.先知介紹
2. EDA
2. EDA
3. Data processing
3.數據處理
4. Model prediction
4.模型預測
5. Takeaways
5.外賣
Let’s begin the journey.
讓我們開始旅程。
1. Prophet Introduction
1.先知介紹
In 2017, Facebook Core Data Science Team open-sourced Prophet. As stated on its Github page, Prophet is:
2017年,Facebook核心數據科學團隊開源了Prophet。 如其Github頁所述,先知是:
- a procedure for forecasting time series data; 預測時間序列數據的程序;
- based on additive models; 基于加性模型;
- fit non-linear trends with yearly, weekly, and daily seasonality, plus holiday effect. 使非線性趨勢與每年,每周和每天的季節性相適應,再加上假期影響。
Prophet uses a decomposable model with three main components, including trend, seasonality, and holidays, as combined below:
先知使用具有三個主要組成部分的可分解模型,包括趨勢,季節性和假日,如下所示:
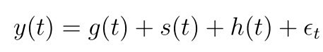
Where:
哪里:
g(t) is the trend function which models non-periodic changes;
g(t)是模擬非周期性變化的趨勢函數;
s(t) represents periodic changes (e.g., weekly and yearly seasonality);
s(t)代表周期性變化(例如,每周和每年的季節性變化);
h(t) represents the effects of holidays which occur on potentially irregular schedules;
h(t)表示假期可能在不定期的時間表上發生的影響;
- the error term represents any idiosyncratic changes which are not accommodated by the model. 錯誤項表示模型不適應的任何特有變化。
So using time as a regressor, Prophet tries to fit linear and non-linear functions of time as components. In effect, Prophet frames the forecasting problem as a curve-fitting exercise, instead of looking at the time-based dependency of each observation, which brings flexibility, fast-fitting, and interpretable parameters.
因此,先知將時間用作回歸變量,嘗試將時間的線性和非線性函數擬合為分量。 實際上,Prophet將預測問題構造為曲線擬合練習,而不是查看每個觀測值基于時間的依賴性,這帶來了靈活性,快速擬合和可解釋的參數。
Prophet works best with time series that have strong seasonal effects and several seasons of historical data.
先知最適合具有強烈季節性影響和多個季節歷史數據的時間序列。
2. EDA
2. EDA
The data used here is the Chicago Crime dataset from Kaggle. It contains a summary of the reported crimes that occurred in the City of Chicago from 2001 to 2017.
這里使用的數據是來自Kaggle的Chicago Crime數據集。 它包含2001年至2017年在芝加哥市發生的所報告犯罪的摘要。
Quickly looking at the data below, you will notice the dataset has 23 columns and 7,941,282 records, including ID, Case Number, Block, Primary Type, Description, etc.
快速查看下面的數據,您會注意到數據集有23列和7,941,282條記錄,包括ID,案例編號,塊,主要類型,描述等。
First, let’s drop the unused columns. Specifically,
首先,讓我們刪除未使用的列。 特別,
df.drop([‘Unnamed: 0’, ‘ID’, ‘Case Number’, ‘IUCR’, ‘X Coordinate’, ‘Y Coordinate’,’Updated On’,’Year’, ‘FBI Code’, ‘Beat’,’Ward’,’Community Area’,‘Location’, ‘District’, ‘Latitude’, ‘Longitude’],
axis = 1, inplace=True)
As shown in Fig.1, the column ‘Date’ is in date format. Let’s convert it to a date format Pandas can interpret, and set it as the index. Specifically,
如圖1所示, “日期”列為日期格式。 讓我們將其轉換為熊貓可以解釋的日期格式,并將其設置為索引。 特別,
df.Date = pd.to_datetime(df.Date, format = ‘%m/%d/%Y %I:%M:%S %p’)
df.index = pd.DatetimeIndex(df.Date)
df.drop(‘Date’, inplace = True, axis = 1)Now data is ready for visualization. First, let’s look at the yearly crime distribution. Specifically,
現在,數據已準備好可視化。 首先,讓我們看一下每年的犯罪分布。 特別,
plt.plot(df.resample(‘Y’).size())
plt.xlabel(‘Year’)
plt.ylabel(‘Num of crimes’)Note above df.resample(‘Y’).size() produce the yearly crime count.
請注意,上面的df.resample('Y')。size()會產生年度犯罪計數。
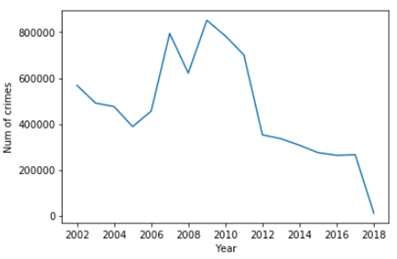
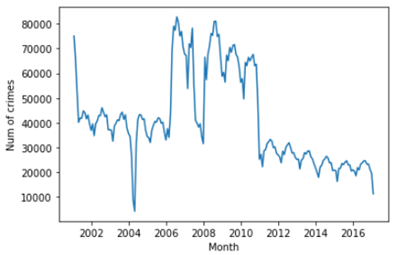
As indicated in Fig.2, the crime rate starts to drop from 2002 to 2005. But from 2006, the crime rate starts to go up, reaching a peak in 2009 and going down till 2018. This curve may reflect the economic impact on social crime. Before and after the financial crisis, the crime rate goes downs yearly, but the bad economy resulting from the financial crisis causes an increase in crimes.
如圖2所示,犯罪率從2002年到2005年開始下降。但是從2006年開始,犯罪率開始上升,2009年達到峰值,然后下降到2018年。該曲線可能反映了經濟對社會的影響。犯罪。 金融危機前后,犯罪率逐年下降,但金融危機造成的經濟不景氣導致犯罪率上升。
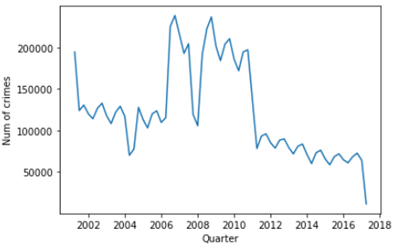
Second, let’s look at the quarterly crime rate distribution. As shown in Fig.3, the crime rate shows a descending trend with periodic ups and downs.
其次,讓我們看一下季度犯罪率分布。 如圖3所示,犯罪率呈下降趨勢,并有周期性的起伏。
In a similar way, as shown in Fig.4, the monthly crime rate shows the same pattern as the quarterly analysis.
以類似的方式,如圖4所示,每月犯罪率顯示與季度分析相同的模式。
3. Data processing
3.數據處理
The input to Prophet is always a dataframe with two columns: ‘ds’ and ‘y’. The ‘ds’ (datestamp) column should be of a format expected by Pandas, ideally YYYY-MM-DD for a date or YYYY-MM-DD HH:MM:SS for a timestamp. The ‘y’ column must be numeric and represents the measurement we wish to forecast.
先知的輸入始終是具有兩列的數據框:“ ds”和“ y”。 “ ds”(datestamp)列應采用熊貓期望的格式,理想情況下,日期應為YYYY-MM-DD,時間戳則應為YYYY-MM-DD HH:MM:SS。 “ y”列必須為數字,代表我們希望預測的度量。
Specifically,
特別,
df_m = df.resample(‘M’).size().reset_index()
df_m.columns = [‘Date’, ‘Monthly Crime Count’]
df_m_final = df_m.rename(columns = {‘Date’: ‘ds’, ‘Monthly Crime Count’: ‘y’})4. Model prediction
4.模型預測
From EDA analysis, we found there is monthly and quarterly seasonality but no yearly seasonality. By default, Prophet fits weekly and yearly seasonality, if the time series is more than two cycles long. Users can add seasonality such as hourly, monthly, and quarterly using ‘add_seasonality’ method.
通過EDA分析,我們發現每個月和每個季度都有季節性,但沒有年度季節性。 默認情況下,如果時間序列長于兩個周期以上,則先知適合每周和每年的季節性。 用戶可以使用“ add_seasonality”方法添加每小時,每月和每季度等季節性信息。
To make a prediction, instantiate a new Prophet object, and call the fit method to train on the data. Specifically,
要進行預測,請實例化一個新的Prophet對象,然后調用fit方法對數據進行訓練。 特別,
m = Prophet(interval_width=0.95, yearly_seasonality=False)
m.add_seasonality(name=’monthly’, period=30.5, fourier_order=10)
m.add_seasonality(name=’quarterly’, period=91.5, fourier_order=10)
m.fit(df_m_final)Note ‘interval_width=0.95’, produces a confidence interval around the forecast. Prophet uses a partial Fourier sum to approximate periodic signal. The number of Fourier order determines how quickly the seasonality can change.
注意'interval_width = 0.95' ,在預測周圍產生一個置信區間。 先知使用部分傅立葉和來近似周期信號。 傅立葉階數確定季節性可以多快地改變。
Predictions are made on a dataframe with a column ‘ds’ containing the dates for which a prediction is to be made. For instance, to predict the following 24 months, try below:
在具有“ ds”列的數據幀上進行預測,該列包含要進行預測的日期。 例如,要預測接下來的24個月,請嘗試以下操作:
future = m.make_future_dataframe(periods = 24, freq = ‘M’)
pred = m.predict(future)As shown in Fig.5, the predicted value ‘yhat’ is assigned to each date with a lower and upper limit.
如圖5所示,將預測值“ yhat”分配給具有上限和下限的每個日期。
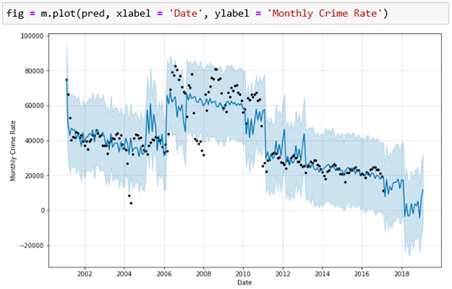
As shown in Fig.6, the black dots are the historical data, and the deep blue line is model predictions. The light blue shadow is a 95% confidence interval around the predictions. The blue line shows a good match with the pattern in Fig.3, indicating a good prediction on historical data. Great!
如圖6所示,黑點是歷史數據,深藍線是模型預測。 淡藍色陰影是圍繞預測的95%置信區間。 藍線表示與圖3中的圖案非常匹配,表示對歷史數據的良好預測。 大!
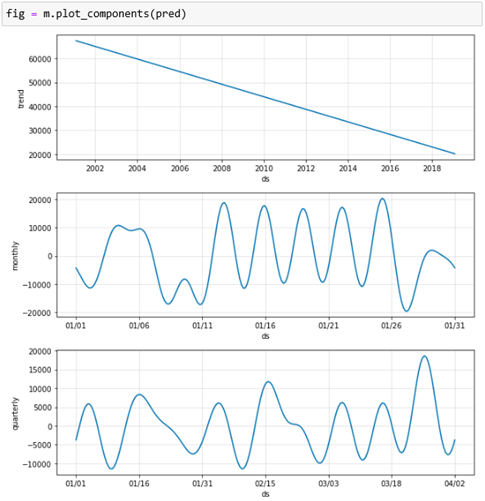
Finally, Fig.7 shows the un-periodic trend, and monthly and quarterly seasonality components of the crime rate pattern.
最后,圖7顯示了犯罪率模式的非周期性趨勢以及每月和每季度的季節性組成。
5. Takeaways
5.外賣
We introduced how to make the best use of Facebook Prophet. Specifically,
我們介紹了如何充分利用Facebook Prophet。 特別,
- to use EDA to explore the historical data patterns, helping to create the best suitable model 使用EDA探索歷史數據模式,幫助創建最合適的模型
- to use data processing to prepare the data for modeling 使用數據處理為建模準備數據
- to use Prophet to fit the historical data and forecast future crime rate 使用先知來擬合歷史數據并預測未來犯罪率
Great! Huge congratulations for making it to the end. If you need the source code, feel free to visit my Github page.
大! 巨大的祝賀,使它走到了盡頭。 如果您需要源代碼,請隨時訪問我的Github頁面。
1. Facebook Prophet official document
1. Facebook Prophet官方文件
2. Prophet paper: Sean J. Taylor, Benjamin Letham (2018) Forecasting at scale. The American Statistician 72(1):37–45 (https://peerj.com/preprints/3190.pdf).
2.先知論文:肖恩·泰勒(Sean J. Taylor),本杰明·萊瑟姆(Benjamin Letham)(2018)大規模預測。 美國統計師72(1):37-45( https://peerj.com/preprints/3190.pdf )。
翻譯自: https://towardsdatascience.com/crime-rate-prediction-using-facebook-prophet-5348e21273d
先知模型 facebook
本文來自互聯網用戶投稿,該文觀點僅代表作者本人,不代表本站立場。本站僅提供信息存儲空間服務,不擁有所有權,不承擔相關法律責任。 如若轉載,請注明出處:http://www.pswp.cn/news/389440.shtml 繁體地址,請注明出處:http://hk.pswp.cn/news/389440.shtml 英文地址,請注明出處:http://en.pswp.cn/news/389440.shtml
如若內容造成侵權/違法違規/事實不符,請聯系多彩編程網進行投訴反饋email:809451989@qq.com,一經查實,立即刪除!相關文章

莫煩Pytorch神經網絡第四章代碼修改

github gists 101使代碼共享漂亮

loj #6278. 數列分塊入門 2

基于Netty的百萬級推送服務設計要點

莫煩Pytorch神經網絡第五章代碼修改

鮮為人知的6個黑科技網站_6種鮮為人知的熊貓繪圖工具

)
網頁JS獲取當前地理位置(省市區)

大熊貓卸妝后_您不應錯過的6大熊貓行動

數據eda_關于分類和有序數據的EDA

PyTorch官方教程中文版:PYTORCH之60MIN入門教程代碼學習

Flexbox 最簡單的表單


jdk重啟后步行_向后介紹步行以一種新穎的方式來預測未來

PyTorch官方教程中文版:入門強化教程代碼學習

css3-2 CSS3選擇器和文本字體樣式

mongodb仲裁者_真理的仲裁者

優化 回歸_使用回歸優化產品價格

Node.js——異步上傳文件
