文章目錄
- 前言
- 一、先搞懂:架構師不僅僅是“技術大佬”,更是“問題解決者”
- 1.1 架構師的分類:不止“開發架構師”一種
- 1.2 架構師要關注什么?別只盯著技術
- 1.3 架構師解決問題的4步心法:從定義到落地
- 1.4 架構師的成長攻略:對上封閉,對下開放
- 二、架構設計的核心:解決5大復雜度問題
- 2.1 高性能復雜度:讓系統“跑得快”
- 2.2 高可用復雜度:讓系統“不宕機”
- 2.3 高拓展復雜度:讓系統“能長大”
- 2.4 成本復雜度:讓系統“更省錢”
- 2.5 安全復雜度:讓系統“防得住”
- 三、架構設計的5步流程:從識別問題到落地
- 3.1 第一步:識別復雜度——抓主要矛盾
- 3.2 第二步:設計方案——分治+取舍
- 3.3 第三步:識別邊界——明確“不做什么”
- 3.4 第四步:細化方案——摳細節
- 3.5 第五步:最終交付——產出能用的文檔
- 四、架構設計的3大原則:別搞復雜
- 五、系統架構的5大衡量指標:怎么判斷架構好不好?
- 5.1 性能指標:系統“跑得快不快”
- 5.2 可用性指標:系統“穩不穩定”
- 5.3 伸縮性指標:系統“能不能長大”
- 5.4 拓展性指標:系統“能不能加功能”
- 5.5 安全性指標:系統“防不防攻擊”
- 六、系統優化的4大核心思路:通用方法論
- 七、總結:架構是“解決問題的工具”,不是“技術炫技”
前言
很多初級架構師會陷入一個誤區:覺得架構設計就是“畫架構圖+選中間件”,比如上來就用微服務、搞異地多活,最后系統復雜到運維扛不住,業務還沒上線就崩了。其實真正的架構設計,不是堆技術,而是一套“解決復雜度”的方法論——從識別問題到落地方案,每一步都有章可循。
作為架構師成長之路的開篇,今天我們從“架構師的定位”講到“系統優化的核心思路”,幫你搭建一套完整的架構設計認知框架。看完這篇,你再面對“高并發”“高可用”需求時,就不會慌了,而是知道該從哪下手。
一、先搞懂:架構師不僅僅是“技術大佬”,更是“問題解決者”
很多人覺得架構師是“寫代碼最牛的人”,但其實架構師的核心價值是“解決系統和業務的復雜度”,而不是比誰技術更炫。
1.1 架構師的分類:不止“開發架構師”一種
如果按照職責分,架構師主要有三類,各司其職:
- 產品架構師:關注業務邏輯和用戶體驗,比如設計電商的下單流程,確保業務閉環;
- 開發架構師:關注技術實現,比如選MySQL還是MongoDB,怎么拆分微服務;
- 運維架構師:關注系統穩定性,比如設計K8s部署方案,做災備演練。
而要是按工作風格分的話,還有更接地氣的劃分:
- 普通架構師:能完成指定需求的架構設計,比如按要求搭微服務;
- 極客型架構師:癡迷技術優化,比如把接口響應時間從100ms壓到10ms;
- 助人型架構師:擅長帶團隊,把復雜方案拆解給開發落地;
- 掃地僧架構師:平時不顯眼,但能解決核心難題(比如線上宕機時快速定位問題);
- 布道型架構師:能把復雜方法論講清楚,幫團隊統一認知。
當然,這些分類從不是為了給架構師貼上 “高低優劣” 的標簽,更不是劃分 “職責邊界” 的壁壘 —— 它更像一把 “認知鑰匙”,幫我們看清架構師角色的多元價值:有人扎根業務前線,讓架構接住真實的用戶需求;有人深耕技術底層,讓系統跑得穩、擴得開;有人擅長 “傳幫帶”,讓復雜方案落地為可執行的代碼;也有人是團隊的 “定海神針”,在危機時快速破局。
很多時候,優秀的架構師往往兼具多種特質:比如開發架構師可能也懂運維的穩定性需求,助人型架構師或許也藏著 “掃地僧” 般的解題能力。歸根結底,不管是哪類架構師,核心價值都離不開 “匹配需求”—— 匹配業務的發展階段,匹配團隊的執行能力,匹配系統的長期目標。畢竟,架構不是紙上談兵的藍圖,而是能支撐業務走得更遠、讓團隊跑得更順的 “解決方案”。而理解這些分類,正是為了找到更適合自己、更貼合團隊的 “架構師成長路徑”
1.2 架構師要關注什么?別只盯著技術
很多架構師只關注“功能實現”,但真正優秀的架構師會兼顧5個維度:
- 功能相關:比如系統要支持“秒殺”“退款”這些核心功能;
- 非功能相關:這是架構設計的重點——性能(QPS要扛1萬)、可用性(全年停機不超過52分鐘)、安全性(防SQL注入)等;
- 團隊組織與管理:比如團隊只有5個開發,就別搞10個微服務(運維不過來);
- 產品運營相關:比如架構要支持“灰度發布”,方便運營做A/B測試;
- 產品未來:比如預判業務半年后流量翻倍,架構要預留擴容空間。
1.3 架構師解決問題的4步心法:從定義到落地
遇到問題別慌,按這4步來,能少走80%的彎路:
- 定義問題:問題的本質是“理想和現實的差距”。比如你期望系統QPS扛1萬(理想),但實際只能扛3000(現實),這中間的7000就是問題;
- 發現問題:從業務需求和歷史故障里找。比如秒殺業務要“快”,反推需要解決高性能問題;從去年3次宕機里,發現需要做高可用;
- 提出問題:別自己悶頭想,要學會借力。比如“用Redis還是本地緩存?”可以拋給團隊討論,“預算不夠怎么降本?”要向上級要支持;
- 解決問題:出成果比“完美方案”更重要。比如12306剛上線時面對大流量崩潰,沒搞復雜的技術優化,而是把“集中放票”改成“分時段放票”——用業務方案解決了技術難題。
1.4 架構師的成長攻略:對上封閉,對下開放
這5條經驗,能幫你快速從“初級”進階到“資深”:
- 對上封閉:給領導“選擇題”,不是“問答題”。比如別問“領導,高可用怎么搞?”,而是說“方案A是主從集群(成本低,可用性99.9%),方案B是異地多活(成本高,可用性99.99%),您選哪個?”;
- 對下開放:拋問題給團隊,匯總答案。比如設計緩存方案時,問開發“你們覺得延時雙刪和訂閱binlog,哪個更易落地?”;
- 共同參與:不用事事親為,但要事事了解。比如微服務拆分時,和開發一起評審邊界,別自己拍板;
- 學會妥協:架構不是“證明自己對”,而是“做好產品”。比如你覺得該用K8s,但團隊只會Docker,那就先從Docker開始,后續再過渡;
- 成就他人:別搶功勞,多給新人機會。比如新人提出的“緩存預熱方案”不錯,就讓他牽頭落地,你做指導。
二、架構設計的核心:解決5大復雜度問題
架構設計的終極目的,就是“把復雜問題拆簡單”。不管是高并發還是高可用,本質都是解決對應的復雜度,而且每個復雜度都有成熟的解決思路。
2.1 高性能復雜度:讓系統“跑得快”
核心思路:減少等待(異步)、加速處理(緩存)、分散壓力(拆分)。比如秒殺系統要扛10萬QPS,就得從這三點入手。
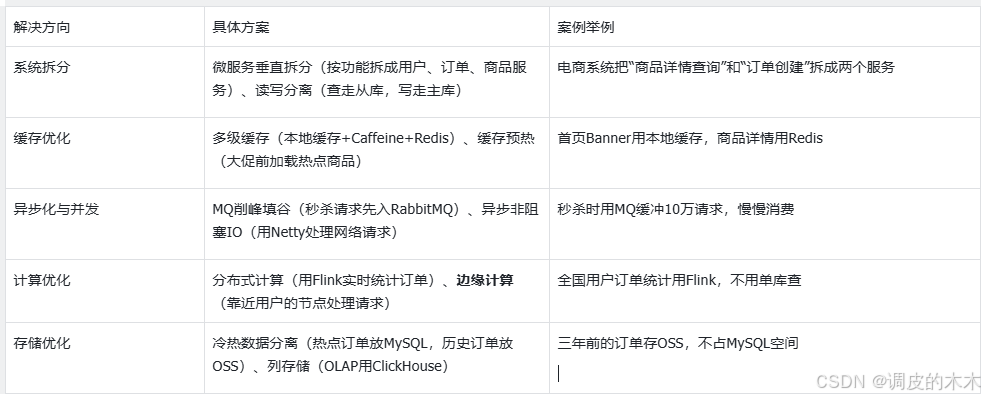
2.2 高可用復雜度:讓系統“不宕機”
核心思路:冗余(備份)、快速恢復(自愈)、預防(監控限流)。比如金融系統要做到“全年停機不超過5分鐘”,就得靠這三點。
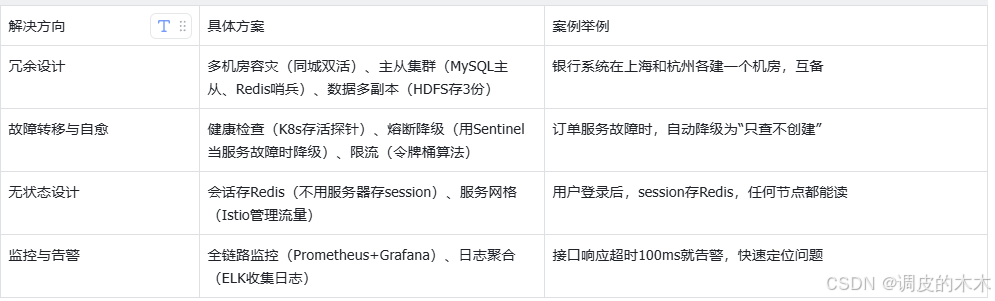
2.3 高拓展復雜度:讓系統“能長大”
核心思路:解耦(分層)、標準化(接口)、彈性(云原生)。比如業務半年后流量翻倍,架構要能輕松擴容。
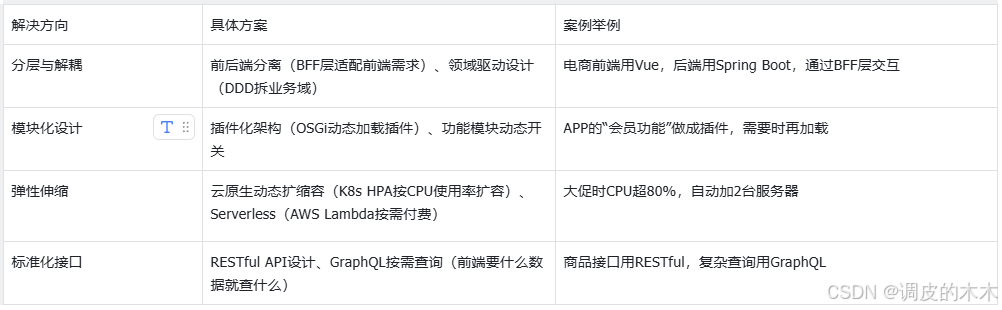
2.4 成本復雜度:讓系統“更省錢”
核心思路:提高資源利用率、避免浪費。比如老板說“預算減半”,你得知道從哪砍成本。
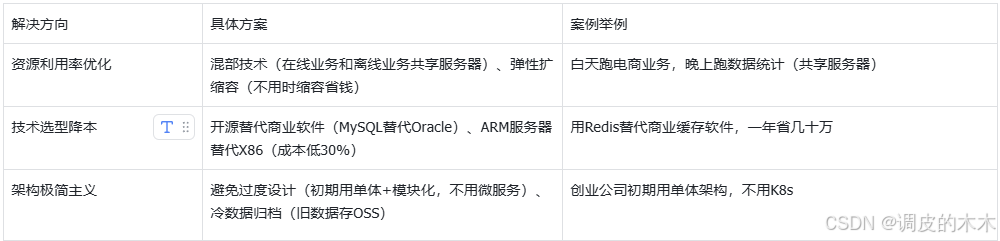
2.5 安全復雜度:讓系統“防得住”
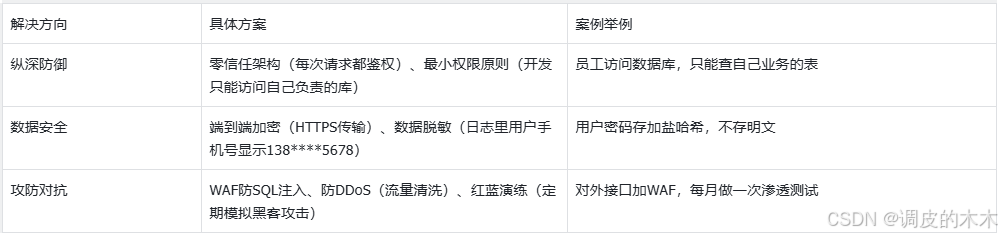
核心思路:零信任(不信任任何環節)、數據加密(鎖死數據)。比如支付系統要防黑客攻擊,就得這么做。
三、架構設計的5步流程:從識別問題到落地
很多人設計架構時“想到哪做到哪”,最后方案失控。其實正規的架構設計有固定流程,5步就能落地。
3.1 第一步:識別復雜度——抓主要矛盾
核心目標:找到系統最核心的1-3個問題,別貪多。比如秒殺系統的核心是“高性能”,金融系統的核心是“高可用+安全”。
怎么找?兩種方法:
- 從業務需求反推:秒殺業務要“扛10萬QPS”→核心是高性能;支付業務要“錢不能錯”→核心是高可用+一致性—+安全;
- 從歷史故障分析:去年3次宕機都是“數據庫扛不住”→核心是高可用(做主從+分庫分表)。
要關注兩個維度: - 技術維度:性能瓶頸(當前QPS只有3000)、可用性要求(要做到4個9);
- 非技術維度:成本約束(預算只有50萬)、團隊能力(只會Spring Boot,不會微服務)。
3.2 第二步:設計方案——分治+取舍
核心原則:用分治思想拆問題,每個問題匹配1-2個方案,別過度設計。
關鍵動作:
- 組合模式:比如“微服務解耦+服務網格化”;
- 排除法:放棄沒必要的方案,比如創業公司初期不用“異地多活”(成本高,用不上),先做“主從集群”。
舉個例子:設計電商商品詳情頁架構 - 核心問題:高性能(QPS要5000)、高可用(3個9);
- 方案組合:“Redis緩存+MySQL主從+CDN靜態資源”;
- 排除方案:不用分布式緩存集群(初期流量小,單Redis足夠)。
3.3 第三步:識別邊界——明確“不做什么”
核心目標:別讓方案失控,要知道架構的“能力上限”。比如你設計的緩存方案,要知道“Redis單節點QPS上限是10萬”,別指望它扛100萬。
怎么識別?
- 技術邊界:數據庫單表建議500萬行(超過就分表)、Kafka單分區吞吐上限1萬/秒;
- 資源邊界:團隊只會Docker(別強行上K8s)、預算只夠買10臺服務器(別搞20臺的集群);
- 演進邊界:預留拓展點(比如API版本兼容v1/v2)、接受技術債務(比如暫不重構老代碼,但要定閾值,比如明年Q1必須重構)。
3.4 第四步:細化方案——摳細節
核心目標:把方案落地到“能寫代碼”的程度,別停留在“畫架構圖”。
要細化幾個方面:
- 技術細節:數據庫選MySQL(OLTP)、緩存選Redis(分布式)、協議用gRPC(內部服務調用);
- 非技術細節:灰度發布策略(先放5%流量,沒問題再放50%)、監控指標(接口響應時間、Redis命中率);
- 容錯設計:降級開關(Redis掛了就走本地緩存)、數據對賬(每天凌晨對比緩存和數據庫數據)。
3.5 第五步:最終交付——產出能用的文檔
架構設計不是“口頭說說”,要交付具體的東西:
- 架構圖:用C4模型(從業務架構到物理部署圖),別只畫個“用戶→API→數據庫”的簡單圖;
- 核心流程文檔:比如分布式事務用Seata的AT模型,要寫清“提交步驟”“回滾邏輯”;
- 落地計劃:分階段執行,比如第一階段搭Redis緩存,第二階段做讀寫分離,第三階段分庫分表。
四、架構設計的3大原則:別搞復雜
很多架構師容易“為了技術而技術”,但記住這3個原則,能幫你少走彎路:
- 合適原則:最合適的就是最好的。比如創業公司用單體架構比微服務好(運維簡單,開發快);
- 簡單原則:能不用復雜技術就不用。比如能靠“分時段放票”解決流量問題,就別搞異地多活;
- 演化原則:架構是迭代出來的,不是一蹴而就的。比如從單體→模塊化→微服務,一步步來,別一步到位。
五、系統架構的5大衡量指標:怎么判斷架構好不好?
設計完架構,怎么知道它行不行?看這5個指標,它們是評估架構的“尺子”。
5.1 性能指標:系統“跑得快不快”
核心指標:
- 吞吐量:單位時間處理的請求數,用TPS/QPS衡量。TPS是“每秒事務數”(比如一個下單事務含3個請求),QPS是“每秒請求數”(比如查商品詳情的請求);
- 注意:不同系統不能比,比如電商QPS1萬很正常,OA系統QPS100就夠了。
- 并發數:同時處理的請求數,比如“并發用戶數”(同時在線1萬用戶)、“并發線程數”(系統用20個線程處理請求);
- 響應時間:用戶從發請求到得結果的時間,比如商品詳情頁加載要500ms(用戶能接受),超過2秒就會吐槽。
5.2 可用性指標:系統“穩不穩定”
用“N個9”衡量:
- 3個9(99.9%):全年停機≤8.76小時(適合普通業務);
- 4個9(99.99%):全年停機≤52分鐘(適合電商、支付);
- 5個9(99.999%):全年停機≤5分鐘(適合金融核心業務)。
怎么提升?冗余+自愈,比如MySQL主從集群(主庫掛了從庫頂上)、K8s自動重啟故障容器。
5.3 伸縮性指標:系統“能不能長大”
指“加服務器就能提升性能”的能力。比如Redis集群從3臺加到5臺,QPS從3萬漲到5萬,這就是伸縮性好。
怎么實現?
- 數據庫:分庫分表(按用戶ID分庫),別用主從(主從只是備份,不能擴容);
- 緩存:Redis Cluster,新增節點時自動分片數據。
5.4 拓展性指標:系統“能不能加功能”
指“加新功能時,對舊系統影響小”。比如新增“優惠券功能”,不用改訂單服務代碼,只需要訂單服務調用優惠券服務的API。
怎么實現?
- 事件驅動架構:用Kafka解耦,比如訂單支付后發消息,優惠券服務訂閱消息扣券;
- 微服務架構:每個服務獨立,新增功能就加新服務。
5.5 安全性指標:系統“防不防攻擊”
核心是“防數據泄露、防惡意攻擊”。比如:
- API安全:用Token鑒權、接口簽名(防止篡改請求);
- 數據安全:用戶密碼加鹽哈希(別存明文)、傳輸用HTTPS;
- 防攻擊:WAF防SQL注入、IP限流防DDoS。
六、系統優化的4大核心思路:通用方法論
不管是優化性能還是降本,這4個思路都能用,相當于架構設計的“萬能工具”:
- 大事化小:把大問題拆成小問題。比如高并發拆成“流量拆分(負載均衡)、數據拆分(分庫分表)、計算拆分(分布式計算)”;
- 前置處理:把耗時操作提前做。比如緩存預熱(大促前加載熱點商品)、靜態資源CDN加速(提前把圖片放到邊緣節點);
- 后置處理:非實時任務延遲做。比如下單后異步發短信(用MQ,別阻塞下單流程)、日志異步寫入(別同步寫磁盤);
- 加快處理:優化執行效率。比如用多線程處理批量任務、用數值計算替代字符串操作(CPU更擅長數值運算)。
七、總結:架構是“解決問題的工具”,不是“技術炫技”
很多人覺得架構設計很高深,但看完這篇你會發現:架構的核心不是“用多少中間件”,而是“能不能解決業務的復雜度”——12306用“分時段放票”解決大流量,比搞復雜的技術架構更有效;創業公司用單體架構不一定比微服務帶來的效果差。
作為架構師,要記住:技術是為業務服務的,合適的才是最好的。


)
)

、SDK、deep及bsp工程管理)
 - 使用Arbess+GitPuk+sourcefare實現Node.js項目自動化部署)







)




