概述
???????? 一句話概述Adaboost算法的話就是:把多個簡單的分類器結合起來形成個復雜的分類器。也就是“三個臭皮匠頂一個諸葛亮”的道理。
???????? 可能僅看上面這句話還沒什么概念,那下面我引用個例子。
???????? 如下圖所示:
???????? 在D1這個數據集中有兩類數據“+”和“-”。
???????? 對于這個數據集,你會發現,不管是這么分
??????????????????
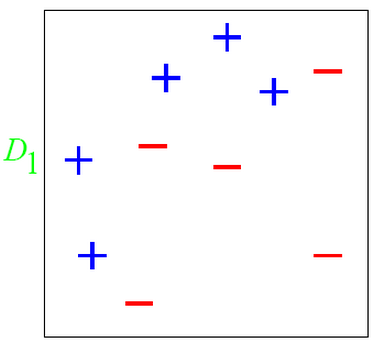
???????? 這么分
??????????????????
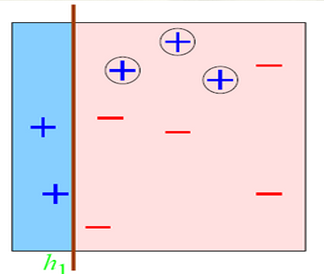
???????? 還是這么分
??????????????????
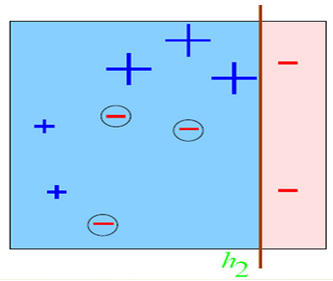
???????? 總有誤分類點存在;
???????? 那么如果我們把上面三種分發集合起來呢?像下面這樣:
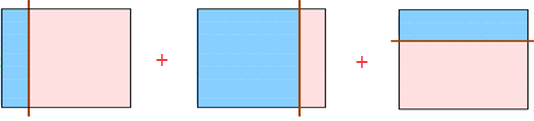
???????? 會發現把上面三個弱分類器組合起來會變成下面這個分類器:
????????
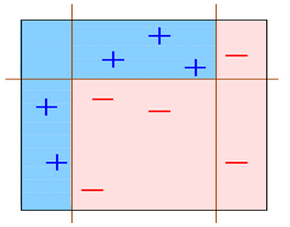
???????? 這樣一來用這個分類器就可以完美的分類數據了。
???????? 這就是Adaboost的思想。
???????? 是不是十分簡單粗暴?
???????? 好,下面我們來總結下Adaboost。
?????????Adaboost是一種迭代算法,其核心思想是針對同一訓練集訓練不同的分類器,即弱分類器,然后把這些弱分類請合起來,構造一個更強的最終分類器。
Adaboost算法的優點
???????? Adaboost的優點如下:
?????????????????? 1,Adaboost是一種有很高精度的分類器;
?????????????????? 2,可以使用各種方法構建子分類器,Adaboost算法提供的是框架;
?????????????????? 3,當使用簡單分類器時,計算出的結果是可以理解的。而且弱分類器構造及其簡單;
?????????????????? 4,簡單,不用做特征篩選;
?????????????????? 5,不用擔心過擬合(overfitting)!
Adaboost算法的步驟
???????? 通過上面的內容我們已經知道Adaboost是將多個弱分類器組合起來形成一個強分類器,那就有個問題了,我們如何訓練弱分類器?我們總得用一個套路來訓練,不然每次都好無章法的弄個弱分類器,那結果可能是:即使你把一萬個弱分類器結合起來也沒辦法將數據集完全正確分類。
???????? 那么我們來進一步看看Adaboost算法的思想:
???????? 1,Adaboost給每一個訓練數據添加“權值”,且最初這個權值是平均分配的。然后在之后的步驟中,提高那些被前一輪弱分類器錯誤分類樣本的權值,并降低那些被正確分類樣本的權值,這樣一來,那些沒有得到正確分類的數據,由于其權值的加大而受到后一輪弱分類器的更大關注
???????? 2,Adaboost給每一個弱分類器添加“權值”,且采取多數表決的方法組合弱分類器。具體地,加大分類誤差率小的弱分類器的權值,使其在表決中起較大的作用;減少分類誤差率大的弱分類器的權值,使其在表決中起較小的作用。
???????? Adaboost的巧妙之處就在于它將這些想法自然且有效地實現在一種算法里。
???????? 下面來整理下Adaboost算法的步驟。
???????? 輸入:
?????????????????? 訓練數據集T ={(x1, y1), (x2, y2), ..., (xN, yN)},其中xi∈X?Rn,yi∈Y={-1, +1};
???????? ???????? 弱學習算法。
???????? 輸出:
?????????????????? 最終分類器G(x)
???????? 解:
?????????????????? 1,初始化訓練數據的權值分布
??????????????????????????? D1= (w11, ..., w1i, ..., w1N),其中w1i= 1/N,i=1, 2, ..., N
?????????????????? 2,對m=1, 2,..., M
??????????????????????????? a,使用具有權值分布Dm的訓練數據集學習,得到基本分類器
???????????????????????????????????? Gm(x): X -> {-1, +1}
??????????????????????????? b,計算Gm(x)在訓練數據集上的分類誤差率
????????????????????????????????????
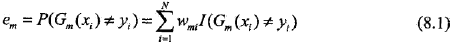
??????????????????????????? c,計算Gm(x)的系數
????????????????????????????????????

??????????????????????????? 這里的對數是自然對數。
?????????????????? ???????? d,更新訓練數據集的權值分布
????????????????????????????????????
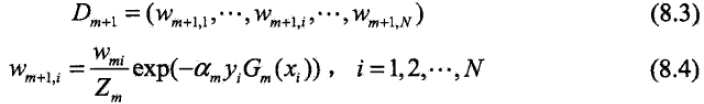
??????????????????????????? 這里,Zm是規范化因子
????????????????????????????????????
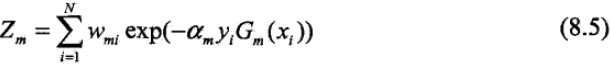
??????????????????????????? 它使Dm+1成為一個概率分布。
?????????????????? 3,構建基本分類器的線性組合
???????????????????????????

?????????????????? 得到最終分類器
???????????????????????????
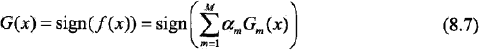
???????然后對上面的步驟做一些說明:
???????? ?????????步驟1假設訓練數據集具有均勻的全職分布,即每個訓練樣本在基本分類器的學習中作用相同。這一假設保證了第1步中能用在原始數據上學習弱分類器G1(x)。
?????????????????? 步驟2反復學習弱分類器,在每一輪m= 1, 2, ..., M順次地執行下列操作:
??????????????????????????? a,使用當期分布Dm加權的訓練數據集,學習基本分類器Gm(x)。
??????????????????????????? b,計算基本分類器Gm(x)在加權訓練數據集上的分類誤差率:
???????? ???????? ???????? ????????
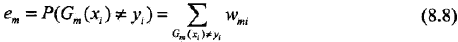
??????????????????????????? 這里,wmi表示第m輪中第i個實例的權值,且:
???????????????????????????????????? ?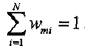
??????????????????????????? 這表明,Gm(x)在加權的訓練數據集上的分類誤差率是被Gm(x)誤分類樣本的權值之和,由此可以看出數據權值分布Dm與弱分類器Gm(x)的分類誤差率的關系。
??????????????????????????? c,計算弱分類器Gm(x)的系數am,am表示Gm(x)在最終分類器中的重要性。由式8.2可知,當em?<= 1/2時,am?>=0,并且am隨em的減小而增大,所以分類誤差率越小的弱分類器在最終分類器中的作用越大。
??????????????????????????? d,更新訓練數據的權值分布為下一輪做準備。式8.4可以寫成:
????????????????????????????????????
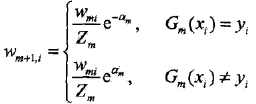
??????????????????????????? 由此可知,被弱分類器Gm(x)誤分類樣本的權值得以擴大,而被正確分類樣本的權值卻得以縮小。兩相比較,誤分類樣本的權值被放大
????????????????????????????????????
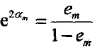
??????????????????????????? 倍。
??????????????????????????? 因此,誤分類樣本在下一輪學習中起更大的作用。
??????????????????????????? 而,“不改變所給的訓練數據,而不斷改變訓練數據的全職分布,使得訓練數據在若分類器的學習中起不同的作用”就是Adaboost的一個特點。
?????????????????? 步驟3中通過線性組合f(x)實現M個弱分類器的加權表決。系數am表示了弱分類器Gm(x)的重要性,這里,所有am之和并不為1。f(x)的符號決定實例x的類,f(x)的絕對值表示分類的確信度。“利用弱分類器的線性組合構建最終分類器”是Adaboost的另一個特點。
?
例子

???????? 給定上面這張訓練數據表所示的數據,假設弱分類器由x<v或x>v產生,其閾值v使該分類器在訓練數據集上的分類誤差率最低,試用Adaboost算法學習一個強分類器。
???????? 解:
?????????????????? 1,令m = 1
??????????????????????????? 則初始化數據權值分布:
??????????????????????????? ???????? Dm = (wm1, wm2,..., wm10),即:D1 = (w11, w12, ..., w110)
??????????????????????????? ???????? wmi?= 0.1, i = 1, 2,..., 10,即:w1i?= 0.1, i = 1, 2, ..., 10
??????????????????????????? a,用下面的方式從v=1.5遍歷到v=9.5
???????? ??????????????????????????? for( v=1.5;v<=9.5; v++) {
???????? ???????? ??????????????????????????? if(x < v) G1(x)=1;
?????????????????? ???????? ?????????????????? elseif (x > v) G1(x) = -1;
??????????????????????????? ???????? }
?????????????????? ?????????????????? 并統計v取各個值使得誤差率(誤差率的計算方法是:所有誤分類點的權值之和)。
???????? ?????????????????? ???????? 然后發現,當v取2.5時,誤分類點為x=6, 7, 8,其權值和為0.3,誤差率最低,此時,當前弱分類器為:
??????????????????????????????????????????????
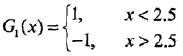
?????????????????? ?????????????????? G1(x) 在訓練數據集上的誤差率e1= P(G1(xi) != yi) = 0.3
??????????????????????????? b,計算G1(x)的系數:a1 =(1/2) log [(1-e1)/e1] = 0.4236
???????? ?????????????????? c,更新訓練數據的權值分布:
???????? ???????? ?????????????????? D2=? (w21, w22, ...,w210)
?????????????????? ???????? ???????? w2i= (w1i/Z1)exp(-a1yiG1(xi)),i = 1, 2,..., 10
?????????????????? 于是
???????? ???????? D2 = (0.0715, 0.0715, 0.0715, 0.0715,0.0715, 0.0715, 0.1666, 0.1666, 0.1666, 0.0715)
???????? ???????? f1(x) = 0.4236G1(x)
?????????????????? 分類器sign[f1(x)]在訓練數據集上有3個誤分類點。
?????????????????? 2,令m = 2,做和上一步同上的操作。
??????????????????????????? 發現在權值分布為D2的訓練數據上,v = 8.5時誤差率最低,此時:
???????????????????????????????????? 當前弱分類器為:
??????????????????????????????????????????????
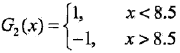
???????????????????????????????????? 誤差率是e2 = 0.2143
???????????????????????????????????? a2= 0.6496
?????????????????? 于是
??????????????????????????? 權值分布為:D3 =(0.0455, 0.0455, 0.0455, 0.1667, 0.1667, 0.1667, 0.1060, 0.1060, 0.1060,0.0455)
??????????????????????????? f2(x)= 0.4236G1(x) + 0.6496G2(x)
??????????????????????????? 分類器sign[f2(x)]在訓練數據集上有3個誤分類點。
?????????????????? 3,令m = 3。
??????????????????????????? 所以在權值分布為D3的訓練數據上,v =5.5時分類誤差率最低,此時的弱分類器為:
????????????????????????????????????
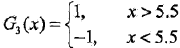
??????????????????????????? G3(x)在訓練樣本上的誤差率為e3= 0.1820
??????????????????????????? a3= 0.7514
?????????????????? 于是
??????????????????????????? 權值分布為:D4 =(0.125, 0.125, 0.125, 0.102, 0.102, 0.102, 0.065, 0.065, 0.065, 0.125)
??????????????????????????? f3(x)= 0.4236G1(x) + 0.6496G2(x) + 0.7514G3(x)
?????????????????? 因為分類器sign[f3(x)]在訓練數據集上的誤分類點個數為0.
?????????????????? 于是最終分類器為:
??????????????????????????? G(x)= sign[f3(x)] = sign[0.4236G1(x) + 0.6496G2(x)+ 0.7514G3(x)]
查看總分類器誤分類點個數的方法
???????? 假設有一個分類器,其有5個元素,其正確的分類結果是:
?????????????????? [1,1, -1, -1, 1]
???????? 然后:
?????????????????? 1,權值初始為:
??????????????????????????? D:[[ 0.2? 0.2? 0.2?0.2? 0.2]]
?????????????????? 2,經過一次計算:
??????????????????????????? alpha:? 0.69314718056
??????????????????????????? classEst:? [[-1.?1. -1. -1.? 1.]]???? # 分類結果
?????????????????? 3,這時就算一下:
??????????????????????????? aggClassEst+= alpha*classEst
??????????????????????????? aggClassEst:? [[-0.69314718?0.69314718 -0.69314718 -0.69314718?0.69314718]]
?????????????????? 4,對比aggClassEst和正確分類的正負號相同位置元素的正負號是否一致,如:
??????????????????????????? 這里addClassEst的正負號從前向后依次是:-,+, -, -, +,而正確分類的正負號依次是:+, +, - ,-, +,所以當前有1個被錯誤分類。
?????????????????? 5,重復上面4步,直到第4步的對比完全一致或者達到循環次數上限。
)

又稱為邏輯回歸分析,是分類和預測算法中的一種。通過歷史數據的表現對未來結果發生的概率進行預測。例如,我們可以將購買的概率設置為因變量,將用戶的)







)
--接口測試工具介紹(詳解))




)

)
 用于數據可視化實驗 -- Matlab版)