?? 引言:AIGC,正在重構視覺智能的“生成邏輯”
AI生成內容(AIGC)正在從“內容創作工具”躍升為計算機視覺系統的新引擎。它不再只是“文生圖”、“圖生文”的演示技術,而是實實在在地改變著我們構建、處理和理解視覺數據的方式。
從智能安防到虛擬現實,從工業質檢到數字孿生,視覺系統正在經歷一次從“被動采集”到“主動生成”的范式躍遷。生成模型讓計算機不僅能“看懂世界”,更具備“重構世界”的能力。
在這個過程中,視頻數據不再只是模型的輸入源,更成為驅動生成、交互和控制的核心素材。這要求底層視覺通道必須具備高效、穩定、低延遲的特性,以支撐大模型實時推理與反饋。
作為一款專注于跨平臺、低延遲、工業級視頻接入的中間件,大牛直播SDK 正在成為連接真實世界與生成智能之間的“感官通路”,讓每一幀實時視頻都具備可理解、可生成、可反饋的能力,為AIGC時代的視覺系統構筑基礎設施。
🧩 一、AIGC對傳統計算機視覺體系的沖擊與重塑
AIGC(AI-Generated Content)正以前所未有的方式,深度改變著計算機視覺系統的設計邏輯與能力邊界。傳統視覺體系長期以來以“感知與識別”為核心,強調如何高效提取圖像特征、理解場景語義,并將視覺信息輸入下游決策模塊。而AIGC的引入,讓視覺系統具備了“內容生成”與“場景建構”的能力,形成了從感知 → 表達 → 創造的新型閉環。
🔄 模式遷移:從識別世界到重構世界
| 傳統視覺路徑 | AIGC增強路徑 | 能力演化方向 |
|---|---|---|
| 圖像識別(Object Detection) | 語義生成(Image Captioning, Diffusion) | 從識別“是什么”到表達“是什么樣” |
| 視頻分析(Action Recognition) | 視頻生成(Image-to-Video, Prompt-to-Video) | 從理解行為到重建動態場景 |
| 缺陷檢測(Quality Inspection) | 異常合成 + 對比生成 | 從被動比對到主動預演與判別 |
| 3D建模(SLAM / Photogrammetry) | 文本驅動建模(Text-to-3D) | 從點云構造到語義建模 |
| 多模態融合(圖+語+聲) | 聯合生成(Multimodal Generation) | 從數據對齊到內容協同生成 |
AIGC 的本質沖擊,不僅體現在模型層面,更在于它迫使我們重新設計視覺系統的輸入輸出邊界,并提出了對視頻鏈路時效性、穩定性、交互性的更高要求。
📌 趨勢洞察
-
視覺系統正從“解釋現實”向“生成現實”演進
-
內容生成能力正在成為視覺智能的“核心輸出之一”
-
實時視頻數據成為AIGC模型與真實世界互動的關鍵橋梁
🚀 三、大牛直播SDK:構建視頻-AI生成間的實時感知通路
? 技術特點
| 能力 | 描述 |
|---|---|
| 🔴 實時推拉流支持 | 支持 RTSP / RTMP / GB28181 等協議,毫秒級低延遲 |
| 🟢 跨平臺支持 | 覆蓋 Android / iOS / Windows / Linux / Unity3D |
| 🔵 本地錄像 / 快照 / 水印處理 | 支持邊緣側智能終端數據留存 |
| 🟣 多通路并發 | 支持多路推流、多實例播放,適配 AIGC 模型多流輸入需求 |
| 🟡 GPU/OpenGL渲染加速 | 提升視頻處理效率,適配圖像生成任務 |
📦 示例集成路徑
以 YOLO + Sora + 大牛直播SDK 為例構建鏈路:
[攝像頭采集] → 大牛SDK RTSP服務 → AI視覺模型識別(YOLO)+ AIGC生成(Sora) → 業務反饋控制可支持以下典型能力:
-
模型生成缺失畫面 → 實時插幀補全
-
多模態理解 → 語音/圖像協同感知
-
視頻轉3D語義 → 虛擬場景構建
🔍 四、典型落地場景:AIGC × 實時視頻,如何重塑行業應用?
AIGC 與實時視頻感知的結合,正在重構多個行業的感知—理解—決策鏈條。傳統視覺系統往往以“識別”為終點,而引入 AIGC 后,視覺系統開始具備“生成—預測—重構”能力,顯著提升了智能體的響應效率與場景適應性。
以下是幾個關鍵行業中,這一技術融合所帶來的本質性轉變:
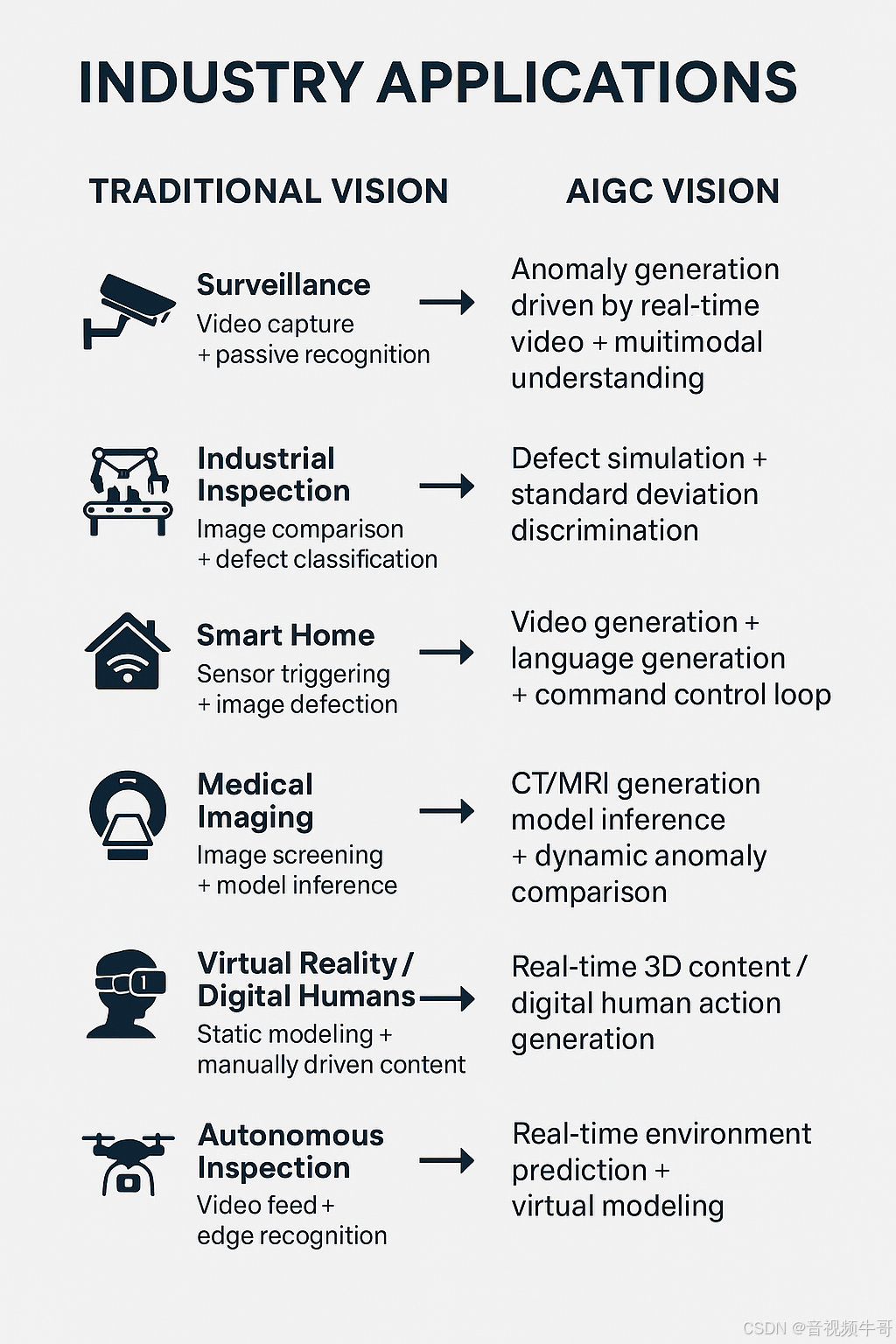
| 行業場景 | 傳統視覺邏輯 | AIGC融合后的新范式 | 技術價值提升 |
|---|---|---|---|
| 🛡? 安防監控 | 視頻采集 + 被動識別 | 實時視頻驅動的異常生成 + 多模態語義理解 | 告警更早、誤報更低、語義更清晰 |
| 🏭 工業質檢 | 圖像比對 + 缺陷分類 | 缺陷模擬生成 + 標準差異判別 | 缺陷識別泛化強、支持小樣本學習 |
| 🏠 智能家居 | 傳感器觸發 + 圖像檢測 | 視頻生成+語言生成+指令控制閉環 | 實現更自然的人機交互與主動響應 |
| 🧠 醫療輔助診斷 | 圖像篩查 + 模型推理 | CT/MRI 生成增強 + 動態異常對比 | 更強診斷支持,適配多模態醫影場景 |
| 🎮 虛擬現實 / 數字人 | 靜態建模 + 手工驅動內容 | 實時生成3D內容 / 數字人動作 | 降低制作成本,實現智能內容互動 |
| 🛰? 無人設備 / 巡檢 | 視頻回傳 + 邊緣識別 | 實時視頻生成環境預測 + 虛擬建模 | 路徑預判更精準,支持極端環境模擬 |
📌 場景共性總結:
-
從“記錄事實”到“生成語義”:視頻數據不僅是感知來源,也是可控生成的語義源泉。
-
從“事后處理”到“實時互動”:AIGC加持下的視頻系統具備即時反饋與推理能力,適配更多閉環控制系統。
-
從“數據孤島”到“多模態協同”:視頻、語音、文本、3D 數據通過生成模型匯聚統一語義空間,支持更復雜的交互行為。
?? 大牛直播SDK在場景中的作用
Windows平臺 RTSP vs RTMP播放器延遲大比拼
在上述各類場景中,大牛直播SDK 提供了穩定、高效、低延遲的視頻數據通路,滿足 AIGC 模型對輸入質量、延遲容忍度、協議多樣性等方面的要求:
-
實時視頻采集與編碼 → 提供清晰、高幀率畫面
-
多協議推流與播放 → 適配邊緣與云端模型協同部署
-
本地存儲與快照 → 支持生成模型回溯與對比
-
跨平臺兼容 → 可嵌入無人機、工業設備、頭顯終端等
Android平臺Unity共享紋理模式RTMP播放延遲測試
🌐 五、系統架構示意圖(AIGC × 視頻SDK)
┌──────────────┐│ 攝像頭 Sensor│└─────┬────────┘▼┌─────────────┐│ 大牛直播SDK │───? 支持實時視頻推送/播放/轉碼└─────┬───────┘▼┌──────────── AI分析引擎 ─────────────┐│ YOLO、OpenCV、MMDetection等 ││ ↘ 多模態生成模型(如Sora、LLaVA │└────────────┬──────────────────────┘▼業務邏輯 / 控制系統
🔚 總結與展望:視頻是生成智能的“感官延伸”
AI生成能力的增強,正在倒逼視覺系統從“輸入型管道”升級為“交互型神經”。視頻,不再是只能采集和識別的靜態介質,而是可被“理解、生成、反饋”的多模態入口。
大牛直播SDK 提供的實時視頻接入、推流、播放、渲染等能力,正成為這一新時代中 AI 系統的視覺“神經元通道”。
? 視頻,是AIGC的感官延伸;
? 大牛直播SDK,是這條感官神經的通路核心;
? 讓每一幀數據都具備生成能力,讓每一次生成都能即時呈現。
未來,AIGC 與實時視覺的深度融合,將催生更多前所未有的應用形態——從生成內容,到生成現實。
??📎 CSDN官方博客:音視頻牛哥-CSDN博客
)




)









—Dubbo Provider處理服務調用請求源碼)

![6-Django項目實戰-[dtoken]-用戶登錄模塊](http://pic.xiahunao.cn/6-Django項目實戰-[dtoken]-用戶登錄模塊)

