YOLOv4 論文地址::【https://arxiv.org/pdf/2004.10934】
YOLOv4 論文中文翻譯地址:【深度學習論文閱讀目標檢測篇(七)中文版:YOLOv4《Optimal Speed and Accuracy of Object Detection》-CSDN博客】
yolov4的作者不是1-3的作者
采用IOU作為損失函數,由于IOU損失函數存在的一些問題,演化出GIOU DIOU CIOU
IOU:最開始的損失函數。沒有考慮IOU=0的情況不可導,位置因素也沒考慮
GIOU:加入了懲罰因子,BB和TG的外界。邊界框和真實框的外界矩形面積,面積并集,再除以外界矩形面積,從而解決了IOU損失中,IOU不可導的情況
DIOU:優化DIOU 引出面積重合,中心點距離
CIOU:優化DIOU,引入長寬比,當IOU越大,應當考慮長寬比,當IOU越小,個更多應該考慮中心點距離
CSP:是一篇論文,減少計算量的同時保證準確率,實現一部分直接傳遞到下一階段,另一部分通過卷積層進行處理后傳遞到下一階段,然后1通過跨階層次結構合并,翻譯:跨階段局部網絡。
SPP:原論文中SPP是為了適配不同輸入尺寸的圖像,能夠不resize就可以再特征提取之后跟上fc,YOLOv4中借鑒了這種思想,把提取的特征進行多角度池化,,結果堆疊,提升特征信息
并行:一起執行
串行:按照順序一個一個
PAN:路徑聚合網絡
1、改進點和貢獻
改進:
輸入端改進:CutMix、Mosaic 數據增強
主干網絡:CSPDarknet53 為 backbone、 SPP 額外添加模塊
頸部網絡:SPP(Spatial Pyramid Pooling)、PANet(Path Aggregation Network)
檢測頭:YOLOv3(基于 anchor 的)
損失函數:CIOU(Complete Intersection over Union )損失
激活函數:Mish 激活函數
樣本匹配:增加了匹配樣本的數量
YOLOv4 貢獻主要內容如下:
算力要求低,單 GPU 就能訓練好
從數據層面(數據增強等)和網絡設計層面(網絡結構)來進行改善
融合各種神經網絡論文的先進思想
2、數據增強策略
2.1 Bag of freebies
-
通常情況下,傳統的目標檢測器的訓練都是在線下進行的。因此, 研究者們總是喜歡利用純線下訓練的好處而研究更好的訓練方法,使得目標檢測器在不增加測試成本的情況下達到更好的精度。我們將這些只需改變訓練策略或只增加訓練成本的方法稱為 bag of freebies。目標檢測經常采用并符合這個定義的就是數據增強。數據增強的目的是增加輸入圖像的多樣性,從而使設計的目標檢測模型對來自不同環境的圖片具有較高的魯棒性
-
使用場景:Mosaic 數據增強、標簽平滑、自對抗訓練、損失函數 CIOU、CmBN
2.2 Bag of specials
-
對于那些只會增加少量的推理成本的插入模塊和后期處理方法, 但可顯著提高目標檢測的準確性,我們稱其為 Bag of specials。一 般來說,這些插入模塊是用來增強模型的某些屬性的,如擴大感受野、 引入注意力機制、增強特征整合能力等,而后處理是一種篩選模型預測結果方法
-
使用場景:Mish 激活函數、CSP 結構
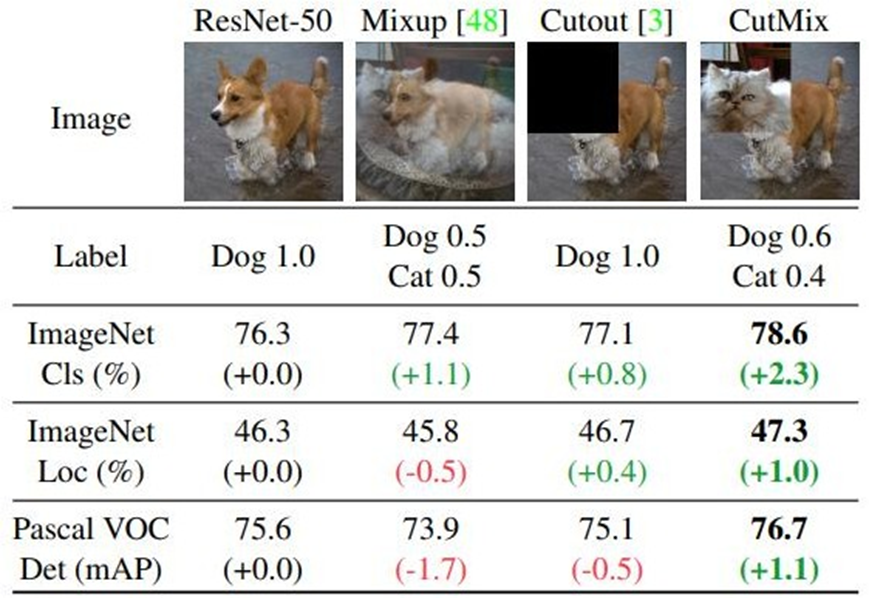
2.3 CutMix 數據增強 【掌握】
-
增強局部特征的學習:通過將不同圖像的局部特征混合在一起,模型可 以學習到更多的局部信息
-
提高訓練效率:高價值信息增多,提升訓練效率,優化算法性能
-
防止模型過擬合:通過引入更多樣的訓練樣本,CutMix 能夠提高模型的泛化能力,減少過擬合現象
-
數據穩定:由于采用填充的形式,不會有圖像混合后不自然的情形,能夠提升模型分類的表現
2.4 Mosaic 數據增強 【掌握】
-
Mosaic 數據增強則利用了 4 張圖片,對 4 張圖片進行拼接,每一張圖片都有其對應的框,將 4 張圖片拼接之后就獲得一張新的圖片,同時也獲得這張圖片對應的框,然后將這樣一張新的圖片傳入到神經網絡當中去學習,這極大豐富了檢測物體的背景
-
Mosaic數據增強的具體步驟如下:
-
首先隨機取 4 張圖片
-
分別對 4 張圖片進行基本的數據增強操作,并分別粘貼至與最終輸出圖像大小相等掩模的對應位置
-
進行圖片的組合和框的組合
-
-
注意:
-
基本的數據增強包括:翻轉、縮放以及色域變化(明亮度、飽和度、色調)等操作
-
-
圖示:先對單張圖片做調整亮度、對比度、色調、隨機縮放、剪切、翻轉、旋轉等基本數據增強,后把 4 張圖片拼接在一起

-
優點:
-
增加數據多樣性:通過將多張圖像混合在一起,生成更多不同的訓練樣 本
-
提升模型的魯棒性:模型在訓練過程中見過更多樣的圖像組合,能夠更 好地應對不同場景下的目標檢測任務
-
減少過擬合:通過增加數據的多樣性,有助于防止模型過擬合,提升泛化能力
-
減少訓練算力:由于一次性可以計算 4 張圖片,所以 Batch Size 可以不用 很大,也為 YOLOv4 在一張 GPU 卡上完成訓練奠定了數據基礎
-
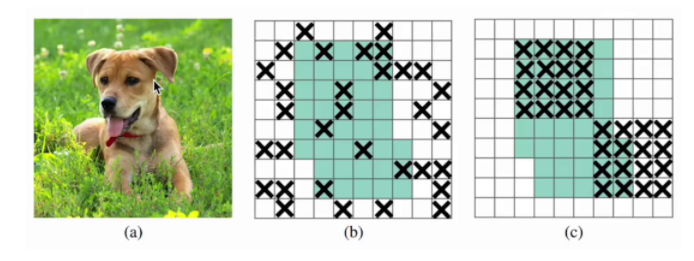
2.5 DropBlock 正則化
-
DropBlock 是一種用于卷積神經網絡的正則化技術,旨在防止過擬合。它通過在訓練過程中隨機丟棄特征圖中的連續區域(塊)來增加模型的泛化能力。與傳統的 Dropout 不同,Dropout 隨機丟棄獨立的神經元,而 DropBlock 丟棄的是特征圖中的連續相鄰區域,這樣可以更有效地移除某些語義信息,從而提高正則化的效果
-
圖示:圖(b) 表示 Dropout 、圖(c)表示 DropBlock
2.6 Class label smoothing
-
標簽平滑(Label Smoothing)是一種正則化技術,用于減少模型在訓練過程中對訓練數據的過擬合,提高模型的泛化能力。標簽平滑的基本思想是通過在訓練過程中對標簽進行平滑處理,減少模型對單一類別的過度自信,從而使得模型更加魯棒
-
獨熱編碼(高維稀疏矩陣)(One-Hot Encoding)是一種將分類變量轉換為二進制向量的編碼方法,通過 One-Hot 編碼,可以將分類變量轉換為數值形式,假設有一個分類變量,它有 𝐾 個不同的類別。One-Hot 編碼會將每個類別映射到一個長度為 𝐾 的二進制向量,其中只有一個位置為 1,其余位置為 0。這個位置對應于該類別的索引
-
標簽平滑的工作原理:
-
在傳統的分類任務中,標簽通常是以 one-hot 編碼的形式給出的。例如,對于一個三分類任務,標簽可能是
[1, 0, 0]、[0, 1, 0]或[0, 0, 1]。標簽平滑通過將這些硬標簽平滑為軟標簽,使得每個類別的概率不再是 0 或 1,而是一個介于 0 和 1 之間的值 -
公式:
-
y_{true}是原始的 one-hot 編碼標簽
-
y_{smoothed}是平滑后的標簽
-
\epsilon是平滑系數,通常是一個較小的正數(例如 0.1)
-
K 是類別的總數
-
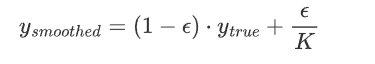
-
-
案例:假設我們有一個三分類任務,原始的 one-hot 編碼標簽是
[1, 0, 0],平滑系數 𝜖=0.1,類別總數 𝐾=3。那么平滑后的標簽計算如下:

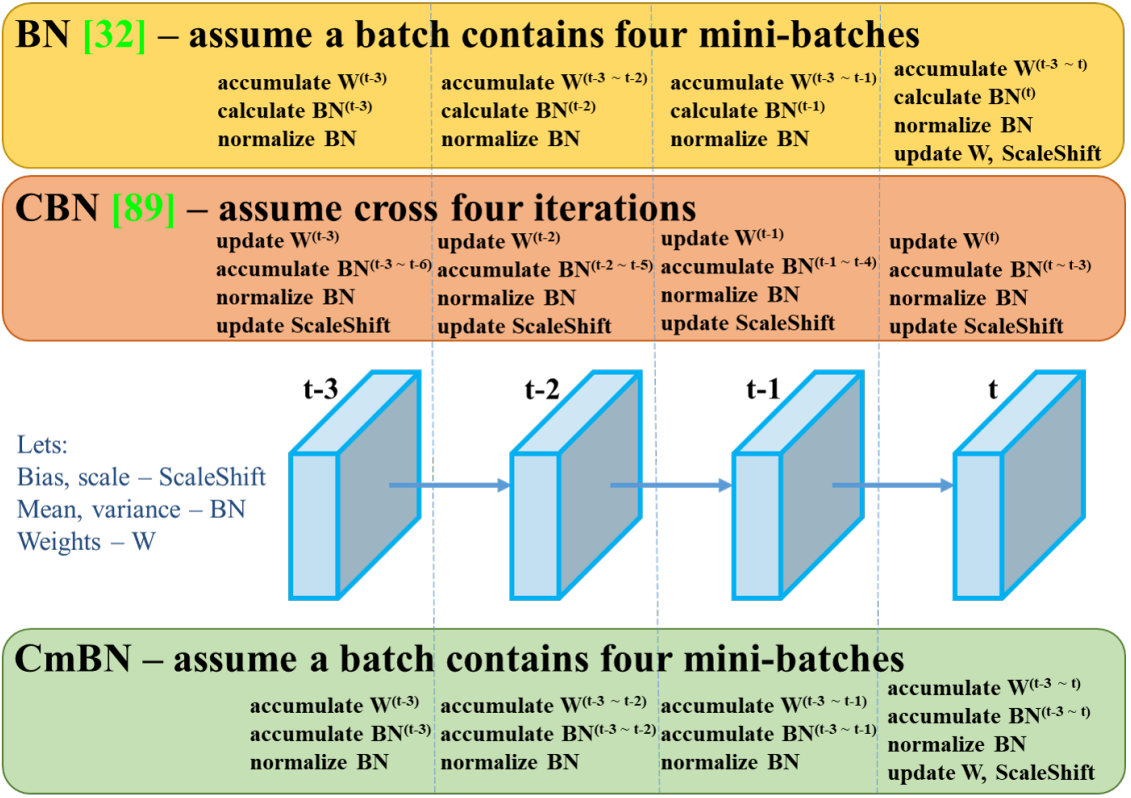
2.7 CmBN 【了解】
-
交叉小批量歸一化(Cross mini-Batch Normalization,CmBN) 是 CBN 的修改版。CmBN會跨多個小批量對均值和方差進行積累和計算,逐漸形成一個全局的均值和方差,從而提升了統計量的穩定性和準確性,減少訓練震蕩
| 方法 | 均值/方差計算方式 | 是否跨 batch | 是否引入條件信息 | 適用場景 | 主要優勢 |
|---|---|---|---|---|---|
| BN | 當前 batch 內 | 否 | 否 | 通用 | 簡單高效 |
| CBN | 當前 batch + 條件信息 | 否 | 是 | 多任務、生成模型 | 控制特征分布 |
| CmBN | 當前 batch + 歷史 batch(滑動平均) | 是 | 否 | 小 batch size | 提升統計穩定性 |
2.8 Mish 激活函數??
-
與 ReLU 等非平滑激活函數相比,Mish 具有更好的平滑性,平滑的激活函數能夠讓模型獲得更好的非線性,從而得到更好的準確性和泛化,Mish 激活函數的數學表達式為:
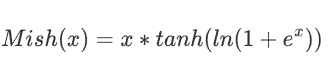
-
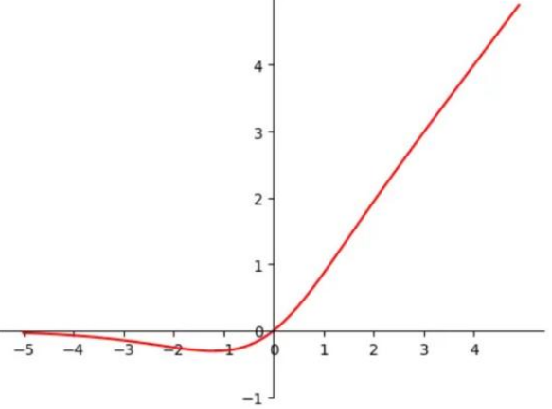
Mish 函數和 ReLU 一樣都是無正向邊界的,可以避免梯度飽和
-
使用了Mish激活函數的 TOP-1 和 TOP-5 的精度比沒有使用時都略高一些:

3、損失函數
-
MSE Loss 主要問題就是導數變化不穩定,尤其是在早期階段(損失越大,導數越大),隨著導數越來越小, 訓練速度變得越來越慢。也因此有學者提出了 IOU 一系列的損失函數,IOU 損失函數演變的過程如下:IOU => GIOU => DIOU =>CIOU 損失函數,每一種損失函數都較上一種損失函數有所提升
3.1 IoU Loss
-
IoU 損失定義如下:交集越大,損失越小
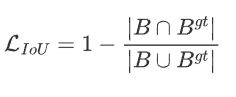
-
不適合的情況:
-
情況 1 ,當預測框和目標框不相交時,IoU=0,無法反映兩個框距離的遠近,此時損失函數不可導
-
情況 2 和情況 3 的情況,當 2 個預測框大小相同,2 個 IoU 也相同,IOU Loss 無法區分兩者位置的差異
-

3.2 GIoU Loss
-
GIoU(Generalized loU)是對 IoU 的改進版本
-
圖中最大外接矩形為 C,紅色區域為差集 A(C-并集),那么給出 GIoU Loss 的表達式如下:
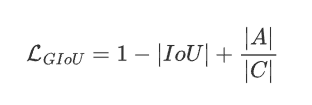

-
優點:
-
在 GIoU 不僅關注重疊區域,還關注其他的非重合區域,能夠更好的反映兩者的重合度,即添加了懲罰因子,緩解了 IoU Loss 不可導的問題
-
-
缺點:
-
下面 3 種情況差集均相等,這個時候 GIoU Loss 就退化為了 IoU Loss,GIoU Loss 也無法反映 3 種情況的好壞,即無法區分相對位置關系
-
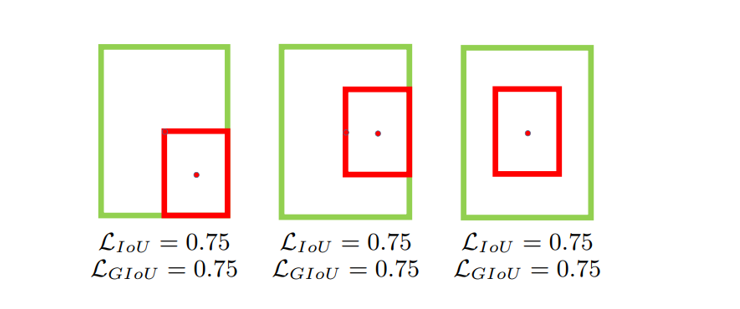
3.3 DIoU Loss
-
為了解決 GIoU 遇到的問題,DIoU(Distance loU)就誕生了。DIoU 作者認為好的目標框回歸函數應該考慮 3 個重要幾何因素:重疊面積、中心點距離,長寬比
-
針對 IoU 和 GIoU 存在的問題,DIoU 作者從兩個方面進行考慮
-
如何最小化預測框和目標框之間的歸一化距離?
-
如何在預測框和目標框重疊時,回歸的更準確?
-
-
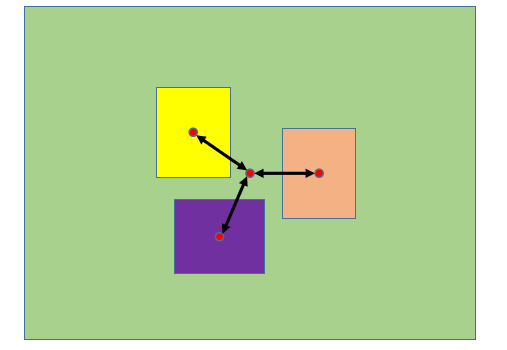
針對第一個問題,提出了 DIoU Loss(Distance IoU Loss),DIoU Loss 考慮了重疊面積和中心點距離,當目標框包裹預測框的時候,直接計算 2 個框的距離,因此 DIoU Loss 收斂的更快
-
公式:

-
圖示:
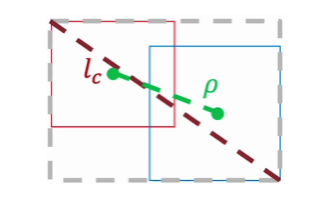
-
效果圖:
-
缺點:
-
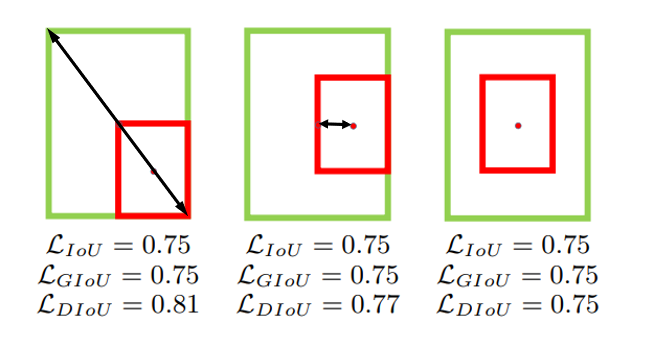
如下圖所示的 3 種狀態預測框和真實目標框的中心點距離是相同的,DIoU Loss 也退化成了 IoU Loss。如上面提到的目標檢測回歸函數需要考慮到的 3 種因素,DIoU Loss 沒有引入長寬比的衡量
-
3.4 CIoU Loss? 【掌握】
-
為了解決 DIoU 遇到的問題,CIoU(Complete loU) Loss 被提出來,CIoU 在 DIoU 基礎上把目標框長寬比的相似程度考慮進去,利用懲罰因子進行約束
-
YOLOv4 采用 CIoU Loss 做回歸損失函數,而分類損失和目標損失都使用的是交叉熵損失。對于回歸損失,其數學表達式如下:

-
CIoU Loss 將目標框回歸函數應該考慮的 3 個重要幾何因素都考慮進去了:重疊面積、中心點距離、長寬比
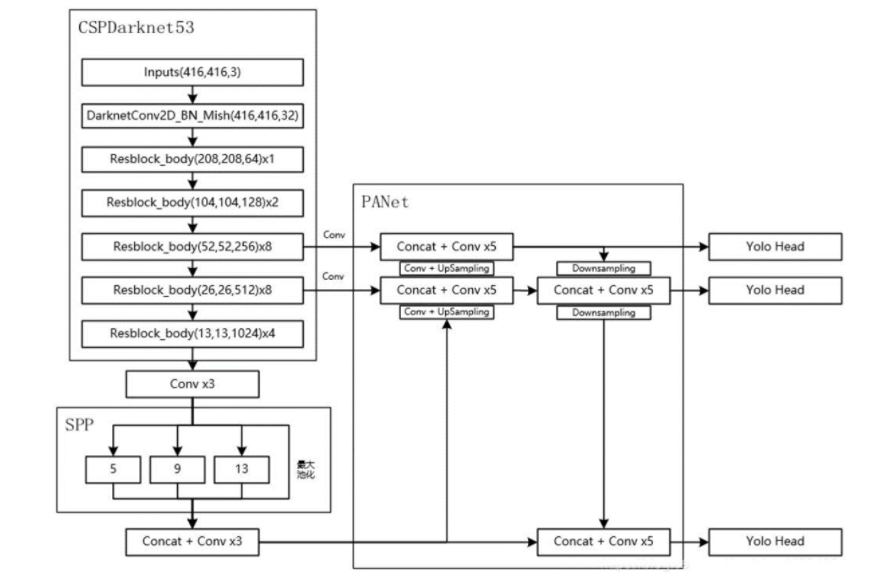
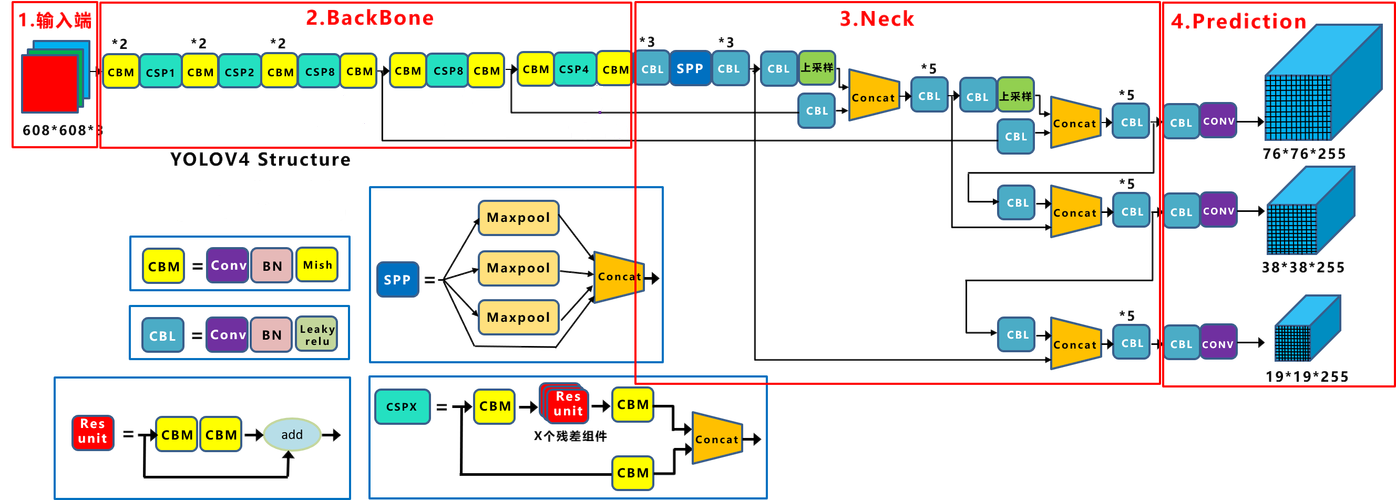
4、網絡結構
采用了稱為 CSPDarknet-53 的新的主干網絡結構,它基于 Darknet-53,并通過使用 CSP(Cross Stage Partial)模塊來提高特征表示的能力
-
YOLOv4 = CSPDarknet53(骨干) + SPP 附加模塊PANet 路徑聚合(頸) + Yolov3(檢測頭)
 ?
?
?
4.2 CSPNet
-
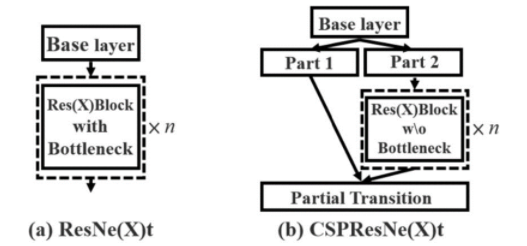
CSPNet(Cross Stage Partial Network):跨階段局部網絡,主要從網絡結構設計的角度解決推理中計算量很大的問題
-
CSPNet 的作者認為推理計算過高的問題是由于網絡優化中的梯度信息重復導致的。因此采用 CSP(Cross Stage Partial)模塊先將基礎層的特征按照通道劃分為兩部分,一部分直接傳遞到下一個階段,另一部分則通過一些卷積層進行處理后再傳遞到下一個階段,然后通過跨階段層次結構將它們合并,在減少了計算量的同時可以保證準確率
-
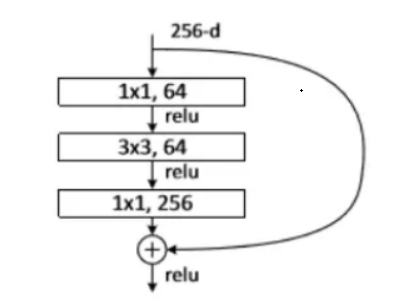
CSP 在論文《CSP:A New Backbone that can Enhance Learning Capability of CNN 》提出,把 CSP 應用到 ResNe(X)t,模型結構如下圖所示:
-
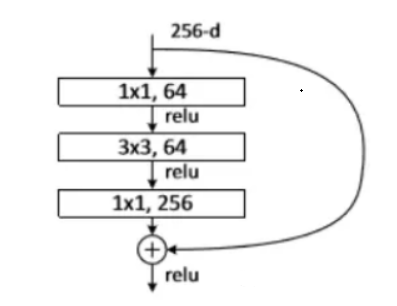
Bottleneck 層通常由三個卷積層組成:
-
第一個 1×1 卷積層:用于降低輸入的通道數,以減少后續卷積層的計算量
-
第二個 3×3 卷積層:在降維后的特征圖上進行卷積操作,提取特征
-
第三個 1×1 卷積層:將通道數恢復到原始維度,以供下一層使用
-
-
優點:
-
增強 CNN 的學習能力,使得在輕量化的同時保持準確性
-
降低計算成本、內存成本
-
4.3 YOLOV4 的 CSP
-
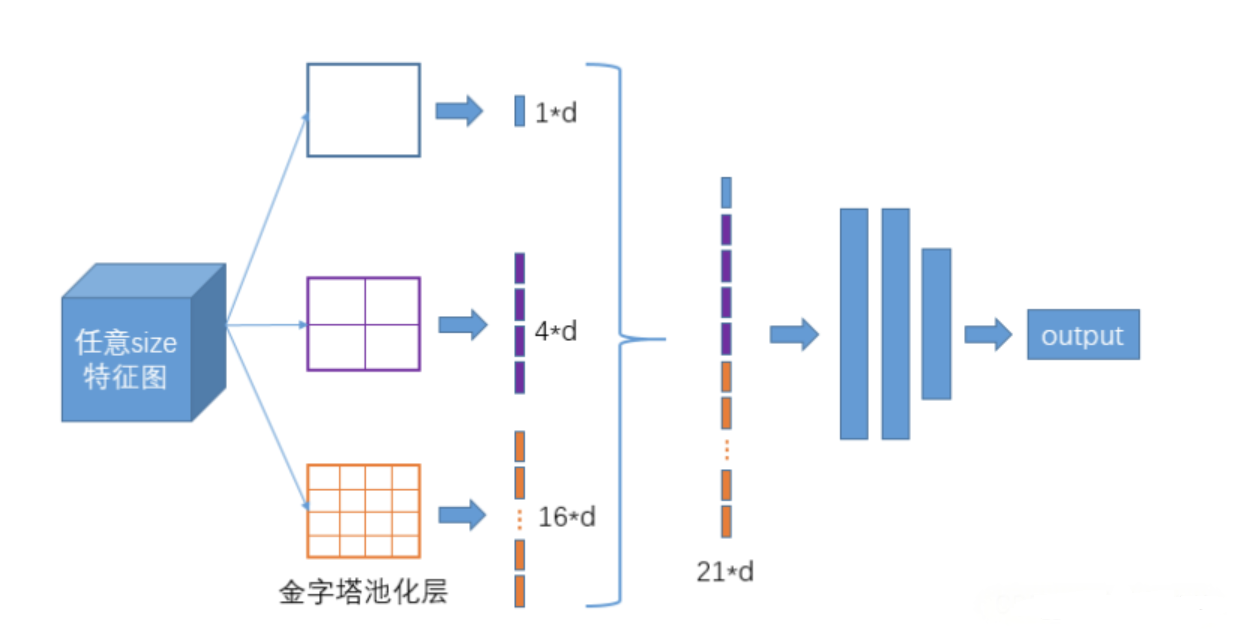
空間金字塔池化網絡(Spatial Pyramid Pooling Network,SPPNet)主要目的是解決圖像在輸入到卷積神經網絡時尺寸不一的問題。通過將不同大小的輸入映射到固定長度的輸出,SPP 模塊使得神經網絡能夠處理任意大小的輸入,從而大大提高了模型的靈活性和泛化能力
-
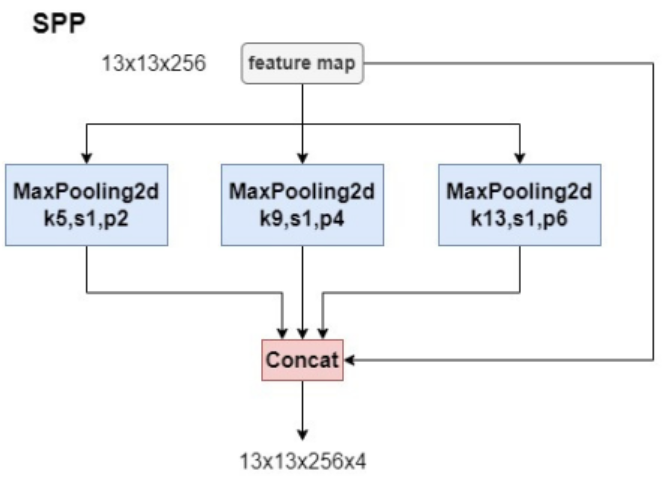
YOLOv4 借鑒了 SPP 的思想,SPP 模塊被集成在主干網絡之后,用于增強模型對多尺度目標的感知能力。
-
將經過不同尺度池化后的特征圖沿通道維度進行拼接。由于每個池化操作的結果都是 13×13×256,而我們進行了 4 次不同的池化操作(包括原特征圖),最終得到的是一個 13×13×(4×256)=13×13×1024 的特征圖,在這個過程中,雖然我們改變了特征圖的處理方式,但我們并沒有改變其空間分辨率(仍然是 13×13),而是增加了通道數(從 256 增加到 1024)。這樣做可以有效地增加網絡的感受野,并結合了不同尺度的信息,有助于提高模型對于各種大小目標的檢測性能
?
4.5 FPN+PAN
-
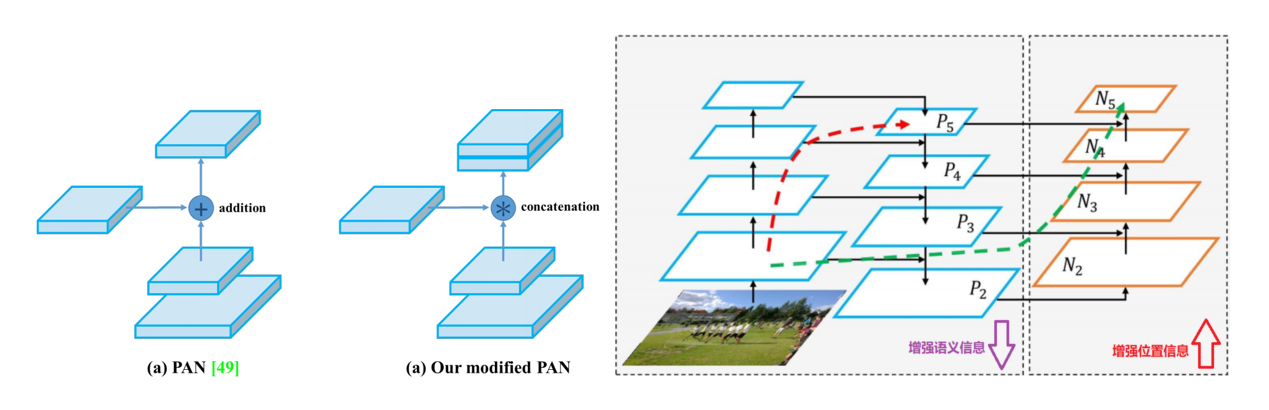
路徑聚合網絡(Path Aggregation Network,PAN),在 FPN 的基礎之上進一步優化而來,用于在不同尺度的特征圖之間進行信息傳遞和融合,以獲取更好的多尺度特征表示
-
在 YOLOv4 中,PANet(Path Aggregation Network)是一種用于特征金字塔網絡(Feature Pyramid Network, FPN)的改進版本,旨在增強特征的多尺度融合能力,從而提高目標檢測的精度。PANet 通過自底向上的路徑增強機制,進一步加強了特征圖的跨尺度信息傳遞,這對于檢測不同大小的目標尤其重要
-
YOLOV4 中的 PANet 主要由兩部分組成:
-
自頂向下的路徑(FPN):這部分與傳統的 FPN 類似,從高層(語義信息豐富但空間信息較少)到低層(空間信息豐富但語義信息較少)逐步上采樣,并與低層特征圖進行融合,生成多尺度的特征圖,作用就是負責將深層的強語義特征傳遞到底層特征圖中,增強低層特征圖的語義表達能力,有助于檢測大目標
-
自底向上的路徑(PAN):這是 PANet 相對于傳統 FPN 的一個重要改進,它從低層到高層逐步下采樣,并與高層特征圖進行融合,進一步增強特征圖的跨尺度信息傳遞,作用就是負責將淺層的精確定位特征傳遞到高層特征圖中,增強高層特征圖的定位能力,有助于檢測小目標
-
-
改進:YOLOv4在原始PAN結構的基礎上進行了改進。原本的 PANet 網絡的 PAN 結構中,特征層之間融合時是直接通過加法(addition)的方式進行融合的,而 YOLOv4 中則采用在通道方向上進行拼接(Concat)的方式進行融合
5、模型性能
5.1 數據增強性能影響
-
選型:CutMix + Mosaic + Label Smoothing + Mish
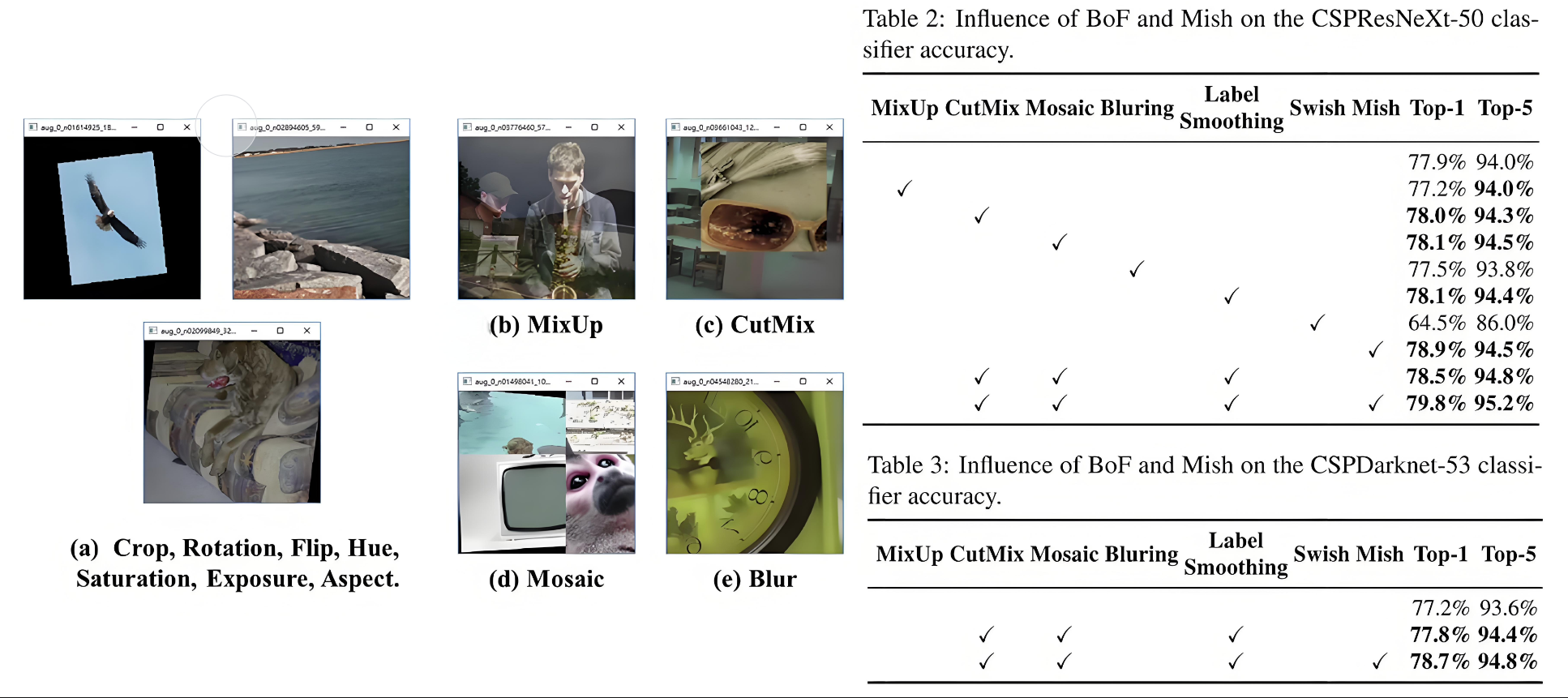
5.2 增強對檢測的效果
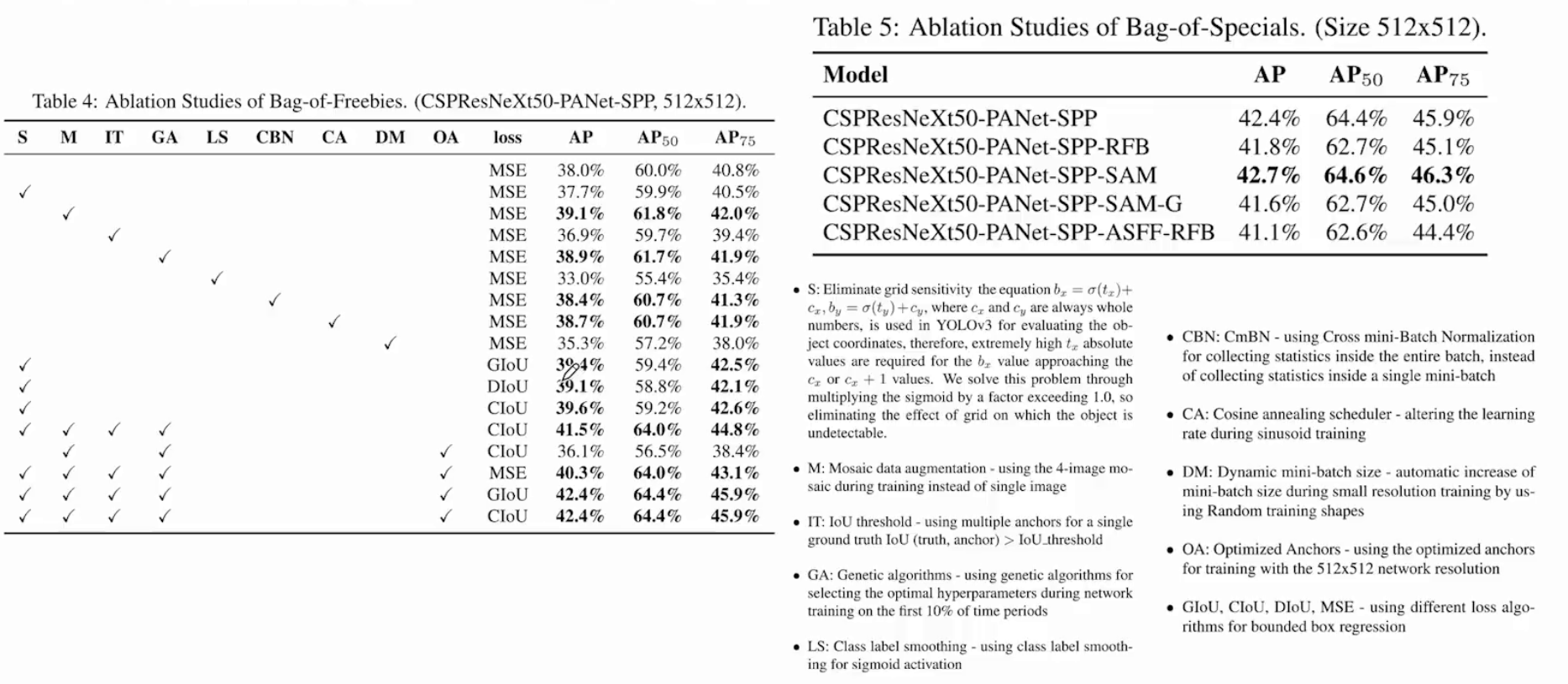
5.3 Backbone性能影響
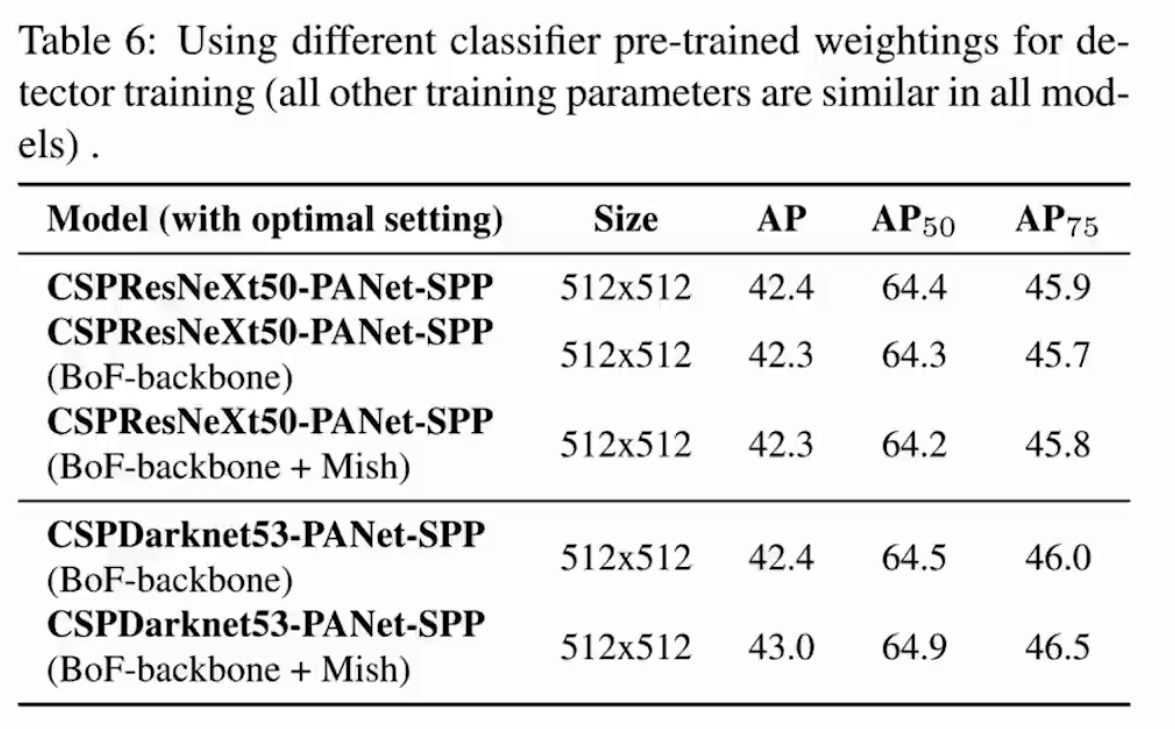
5.4 mini-batch性能影響
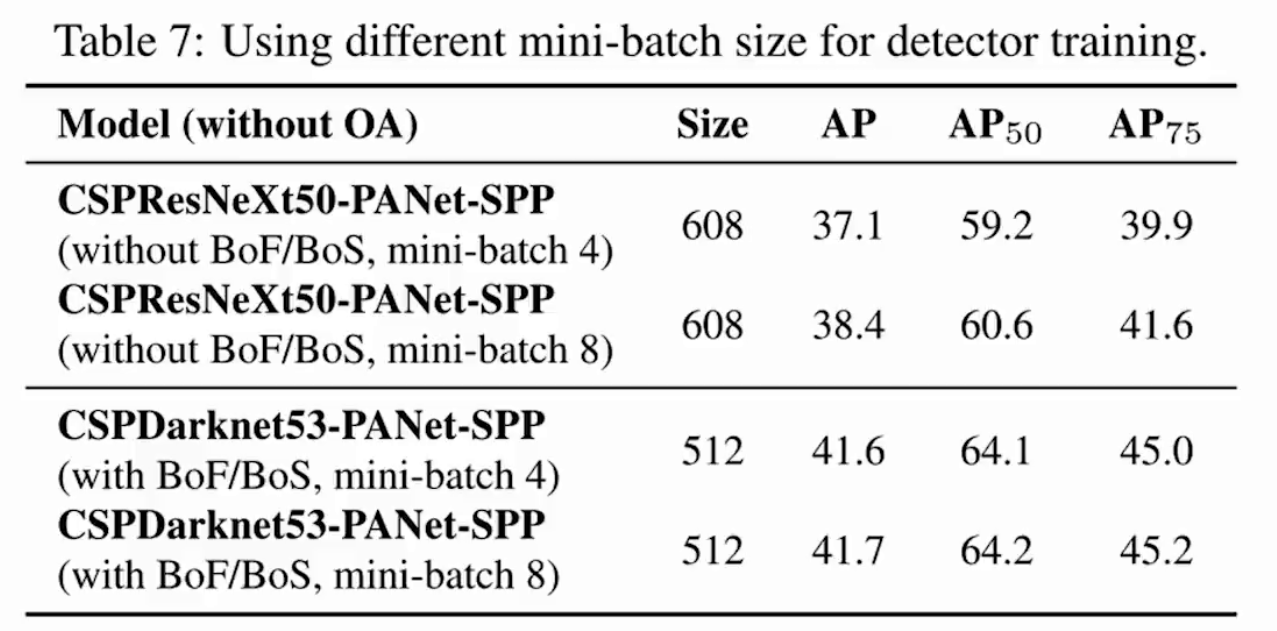
5.5 推理時間和精度
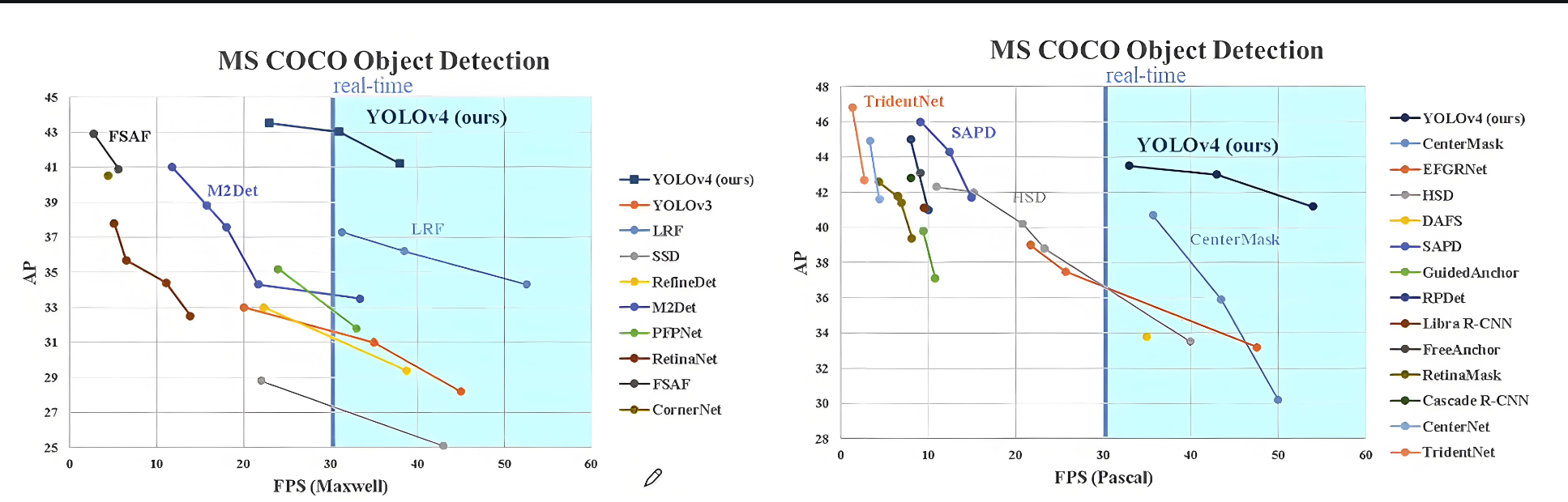
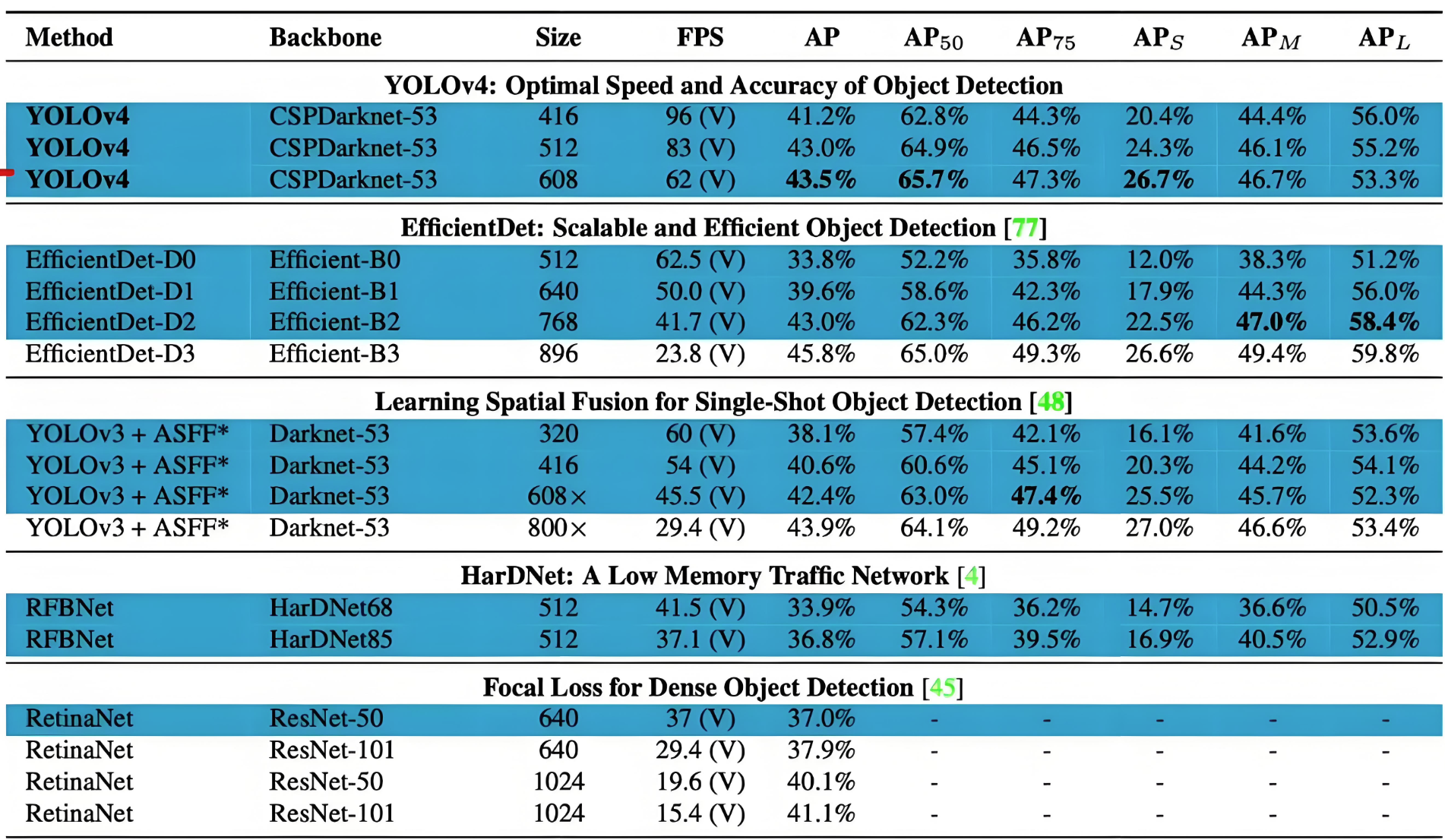
5.6 COCO 數據集性能對比


![視覺圖像處理中級篇 [2]—— 外觀檢查 / 傷痕模式的原理與優化設置方法](http://pic.xiahunao.cn/視覺圖像處理中級篇 [2]—— 外觀檢查 / 傷痕模式的原理與優化設置方法)

戰士:序)



】KNN算法與模型評估調優)




:Python 的函數——函數的參數)





