在機器人學習領域,如何有效地將視覺語言模型(VLM)的強大感知能力與低級動作控制相結合,是實現通用機器人智能的關鍵挑戰。SmolVLA(Small Vision-Language-Action)架構正是在這一背景下應運而生,它通過一種新穎的交錯注意力機制,實現了視覺語言特征與機器人動作生成之間的緊密耦合。本文將深入探討SmolVLA架構中VLM與動作專家(Action Expert)之間的信息交互,特別是其注意力機制中KV和QKV的設計原理,并結合官方代碼進行詳細解析。
一、SmolVLA架構概覽
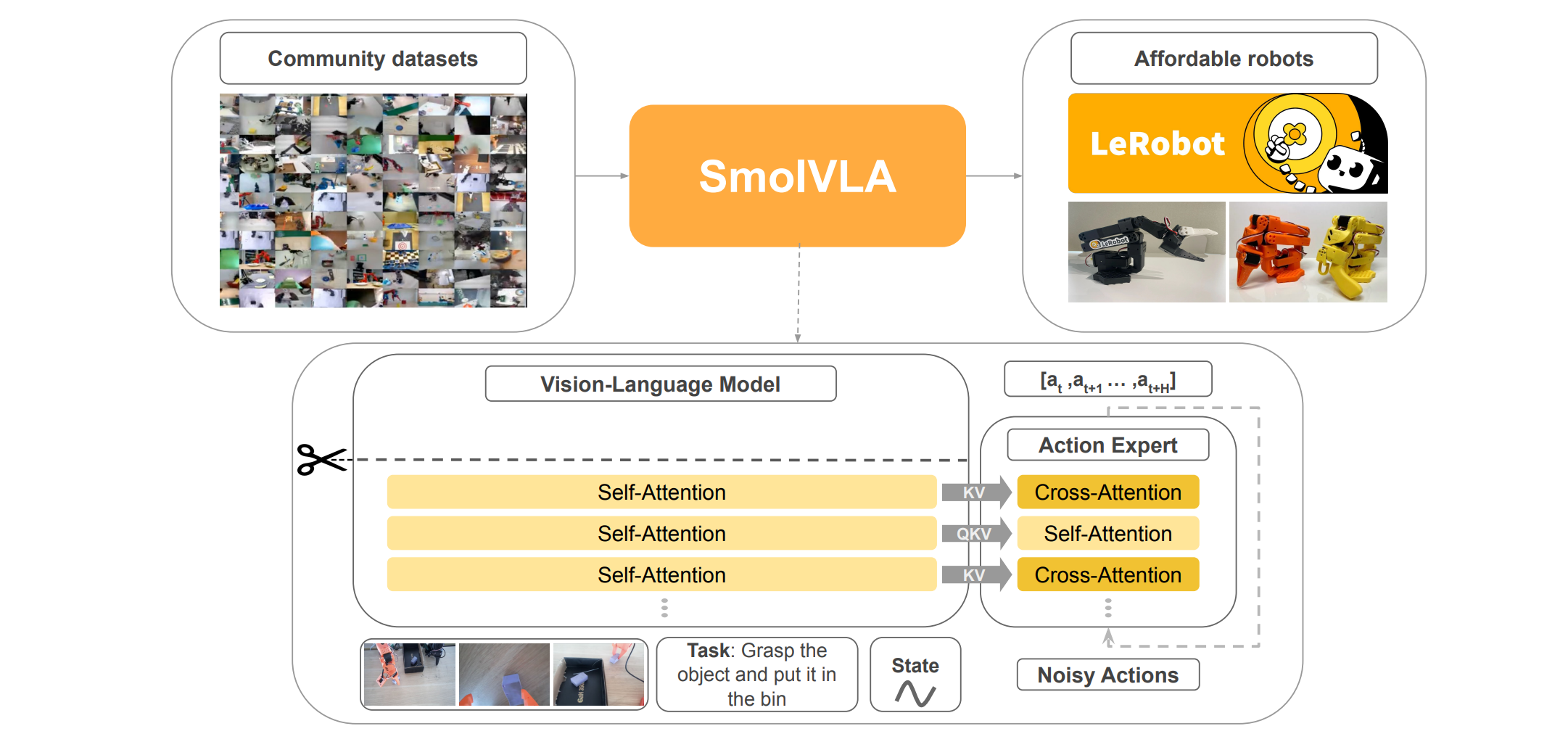
SmolVLA由兩大部分組成:一個預訓練的視覺語言模型(VLM)和一個動作專家。VLM負責處理多模態輸入,包括語言指令、RGB圖像和機器人本體感受狀態,并提取高級特征。這些特征隨后被送入動作專家,由其生成一系列低級動作塊(action chunks)。與傳統的Transformer架構不同,SmolVLA的動作專家采用了交錯式的自注意力(Self-Attention, SA)和交叉注意力(Cross-Attention, CA)層,而非在每個解碼器塊中同時包含兩者。這種設計旨在優化性能并提高推理速度。
二、注意力機制基礎回顧
在深入SmolVLA的細節之前,我們先簡要回顧一下Transformer中自注意力和交叉注意力的基本概念:
-
自注意力(Self-Attention):在自注意力機制中,輸入序列中的每個元素都會與同一序列中的所有其他元素計算注意力權重。它通過將輸入表示轉換為查詢(Query, Q)、鍵(Key, K)和值(Value, V)三個向量來實現。Q與K的點積決定了注意力權重,然后這些權重作用于V,得到加權和的輸出。自注意力允許模型捕捉序列內部的依賴關系。
-
交叉注意力(Cross-Attention):交叉注意力通常用于處理兩個不同的輸入序列。其中一個序列提供查詢(Q),而另一個序列提供鍵(K)和值(V)。例如,在編碼器-解碼器架構中,解碼器的查詢來自解碼器自身的輸出,而鍵和值則來自編碼器的輸出。這使得解碼器能夠“關注”編碼器輸出中的相關信息。
三、SmolVLA中VLM與動作專家的信息交互
SmolVLA的核心創新之一在于其VLM與動作專家之間獨特的信息交互方式。如圖1所示,VLM的輸出特征(通常是其最后一層或中間層的隱藏狀態)被傳遞給動作專家。這種交互通過注意力機制實現,其中VLM的特征充當了動作專家注意力層的鍵(K)和值(V)的來源。
3.1 動作專家中的交叉注意力(Cross-Attention)
在SmolVLA的動作專家中,交叉注意力層(圖1中金色塊)負責將動作令牌(action tokens)與VLM提取的視覺語言特征進行融合。根據論文描述:
In our setup, CA layers cross-attend the VLM’s keys and values, while SA layers allow the action tokens in vθv_θvθ? to attend to each other.
這意味著在交叉注意力層中:
- 查詢(Q):來自動作專家自身的當前動作令牌的表示。這些令牌代表了模型正在嘗試生成的動作序列。
- 鍵(K)和值(V):來自VLM的輸出特征。VLM已經處理了圖像、語言指令和機器人狀態,并生成了包含這些多模態信息的豐富表示。這些VLM特征作為外部信息源,為動作令牌提供了上下文。
因此,交叉注意力層接收的是VLM的KV以及動作專家自身的Q。這種設計使得動作專家能夠根據VLM提供的感知信息來調整和生成動作。例如,如果VLM識別出圖像中的特定物體或理解了語言指令中的特定動詞,這些信息將通過KV傳遞給動作專家,指導其生成相應的抓取或移動動作。
讓我們看看smolvlm_with_expert.py中的forward_cross_attn_layer函數,它負責處理交叉注意力邏輯。雖然代碼中直接計算了expert_query_state、expert_key_states和expert_value_states,但關鍵在于expert_key_states和expert_value_states的來源。它們是通過expert_layer.self_attn.k_proj和expert_layer.self_attn.v_proj對VLM的key_states和value_states進行投影得到的。這明確體現了VLM作為KV源的機制:
_key_states = key_states.to(dtype=expert_layer.self_attn.k_proj.weight.dtype).view(*key_states.shape[:2], -1)expert_key_states = expert_layer.self_attn.k_proj(_key_states).view(*_key_states.shape[:-1], -1, expert_layer.self_attn.head_dim) # k_proj should have same dim as kv_value_states = value_states.to(dtype=expert_layer.self_attn.v_proj.weight.dtype).view(*value_states.shape[:2], -1)expert_value_states = expert_layer.self_attn.v_proj(_value_states).view(*_value_states.shape[:-1], -1, expert_layer.self_attn.head_dim)expert_query_state = expert_layer.self_attn.q_proj(expert_hidden_states).view(expert_hidden_shape)
這里的key_states和value_states實際上是VLM層在處理其自身輸入時生成的KV對。動作專家通過對其進行線性投影,將其適配到自己的維度空間,從而在交叉注意力中作為外部信息源。
3.2 動作專家中的自注意力(Self-Attention)
自注意力層(圖1中淺黃色塊)在動作專家內部運作,其目的是讓動作令牌之間相互關注,捕捉動作序列內部的時間依賴性。根據論文:
SA layers allow the action tokens in vθv_θvθ? to attend to each other. We employ a causal attention mask for the SA layers, ensuring that each action token can only attend to past tokens within the chunk, preventing future action dependencies.
這意味著在自注意力層中:
- 查詢(Q)、鍵(K)和值(V):全部來自動作專家自身的當前動作令牌的表示。每個動作令牌都生成自己的Q、K和V,并與其他動作令牌的K和V進行交互。
自注意力層接收QKV的原因是它需要捕捉序列內部的依賴關系。動作專家在生成動作序列時,需要考慮之前生成的動作對當前動作的影響,并確保動作序列的連貫性和流暢性。因果注意力掩碼(causal attention mask)的引入,進一步確保了每個動作令牌只能關注其之前的令牌,從而避免了未來信息泄露,這對于序列生成任務至關重要。
在smolvlm_with_expert.py的forward_attn_layer函數中,我們可以看到Q、K、V都是從inputs_embeds(即動作令牌的隱藏狀態)中計算出來的:
query_states = []key_states = []value_states = []for i, hidden_states in enumerate(inputs_embeds):layer = model_layers[i][layer_idx]if hidden_states is None or layer is None:continuehidden_states = layer.input_layernorm(hidden_states)input_shape = hidden_states.shape[:-1]hidden_shape = (*input_shape, -1, layer.self_attn.head_dim)hidden_states = hidden_states.to(dtype=layer.self_attn.q_proj.weight.dtype)query_state = layer.self_attn.q_proj(hidden_states).view(hidden_shape)key_state = layer.self_attn.k_proj(hidden_states).view(hidden_shape)value_state = layer.self_attn.v_proj(hidden_states).view(hidden_shape)query_states.append(query_state)key_states.append(key_state)value_states.append(value_state)query_states = torch.cat(query_states, dim=1)key_states = torch.cat(key_states, dim=1)value_states = torch.cat(value_states, dim=1)
這里的inputs_embeds在動作專家內部的自注意力層中,就是動作令牌的嵌入表示。通過對這些嵌入進行Q、K、V投影,模型能夠計算動作令牌之間的相互依賴關系。
四、交錯注意力機制的優勢
SmolVLA采用交錯式的交叉注意力和自注意力層,而非在每個解碼器塊中同時包含兩者,這與許多標準VLM架構(如Transformer解碼器)有所不同。論文指出:
Empirically, we find that interleaving CA and SA layers provides higher success rates and faster inference time. In particular, we find self-attention to contribute to smoother action chunks A, something particularly evident when evaluating on real robots.
這種設計選擇的優勢在于:
- 效率提升:通過交錯使用,而不是在每個層都同時計算兩種注意力,可以減少計算開銷,從而實現更快的推理速度。
- 性能優化:實驗結果表明,這種交錯方式能夠帶來更高的成功率。自注意力層有助于生成更平滑、更連貫的動作序列,這對于真實機器人控制至關重要。
- 明確職責:交叉注意力層專注于融合外部視覺語言信息,而自注意力層則專注于建模動作序列內部的依賴關系,職責更加明確,可能有助于模型更好地學習各自的特定任務。
五、總結
SmolVLA通過交錯注意力機制,在VLM與動作專家之間建立了高效且富有表現力的信息交互通道。交叉注意力層允許動作專家從VLM中獲取豐富的感知上下文(KV),從而指導動作的生成;而自注意力層則使動作專家能夠捕捉動作序列內部的依賴關系(QKV),確保動作的連貫性和流暢性。這種獨特的設計不僅提升了模型的性能和推理速度,也為機器人學習領域提供了一種新的注意力機制范式,使其在復雜任務中展現出卓越的潛力。


8.4)

集群搭建】)
:類名規范、返回值、注釋、數據類型)
)


![[找出字符串中第一個匹配項的下標]](http://pic.xiahunao.cn/[找出字符串中第一個匹配項的下標])
)
)





)

