概述:現在就只知道這個svm可以畫出決策邊界,對數據的劃分。簡單舉例就是:好的和壞的數據分開,中間的再驗證
from sklearn.datasets import make_blobs
from sklearn.svm import SVC
import matplotlib.pyplot as plt
import numpy as np# 1. 生成數據
X, y = make_blobs(n_samples=50, # 50個樣本centers=2, # 2個類別(二分類)random_state=0, # 固定隨機種子cluster_std=0.6 # 控制數據點的分散程度
) # X是樣本,y是標簽# 2. 訓練線性SVM
model = SVC(kernel='linear').fit(X, y)# 3. 繪制數據點
plt.scatter(X[:, 0], X[:, 1], c=y, s=50, cmap="rainbow") # 按類別著色# 4. 繪制決策邊界和支持向量間隔
ax = plt.gca() # 獲取當前坐標軸
xlim = ax.get_xlim() # 獲取x軸范圍
ylim = ax.get_ylim() # 獲取y軸范圍# 生成網格點(用于繪制決策邊界)
xx, yy = np.meshgrid(np.linspace(xlim[0], xlim[1], 50), # x軸50個點np.linspace(ylim[0], ylim[1], 50) # y軸50個點
) # 分成50分畫網格# 計算決策函數值(SVM的間隔)
Z = model.decision_function(np.c_[xx.ravel(), yy.ravel()]).reshape(xx.shape) # 計算決策值并重塑為網格矩陣# 繪制決策邊界(黑色實線)和間隔邊界(黑色虛線)
ax.contour(xx, yy, Z,colors='k',levels=[-1, 0, 1], # 0是決策邊界,±1是支持向量間隔alpha=0.5, # 透明度linestyles=['--', '-', '--'] # 虛線-實線-虛線
)# 5. 標記支持向量(SVM的關鍵數據點)
ax.scatter(model.support_vectors_[:, 0], # 支持向量的x坐標model.support_vectors_[:, 1], # 支持向量的y坐標s=100, # 點的大小facecolors='none', # 空心點edgecolors='k', # 黑色邊框linewidths=1.5 # 邊框寬度
)plt.title("SVM Decision Boundary with Support Vectors")
plt.show()print(Z)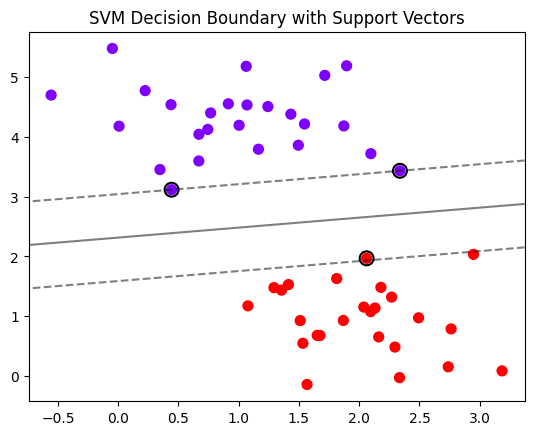










![[Python] -進階理解10- 用 Python 實現簡易爬蟲框架](http://pic.xiahunao.cn/[Python] -進階理解10- 用 Python 實現簡易爬蟲框架)

和案例解析)





:輸出格式化、基本運算符)
:磁盤空間滿、重選主節點)