本文參考視頻[雙語字幕]吳恩達深度學習deeplearning.ai_嗶哩嗶哩_bilibili
參考文章0.0 目錄-深度學習第一課《神經網絡與深度學習》-Stanford吳恩達教授-CSDN博客
1深度學習概論
1.舉例介紹
lg房價預測:房價與面積之間的坐標關系如圖所示,由線性回歸可以在坐標上得出這樣一條直線
由于房價非負,所以你把剩下的設置為0
右邊的小圓圈就是一個神經元,這個神經元實現了輸入面積輸出房價的功能,這就是最簡單的神經網絡
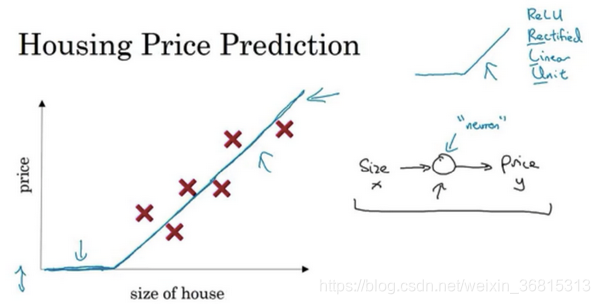
在有關神經網絡的文獻中,你經常看得到這個函數。從趨近于零開始,然后變成一條直線。這個函數被稱作ReLU激活函數,它的全稱是Rectified Linear Unit。rectify(修正)可以理解成max(0,x),這也是你得到一個這種形狀的函數的原因。
這只是一個單神經元網絡,你需要以此為單位搭建更大的神經網絡
當然還有很多因素來影響房價,在圖上每一個畫的小圓圈都可以是ReLU的一部分,也就是指修正線性單元,或者其它稍微非線性的函數,中間的圈也叫做隱藏層
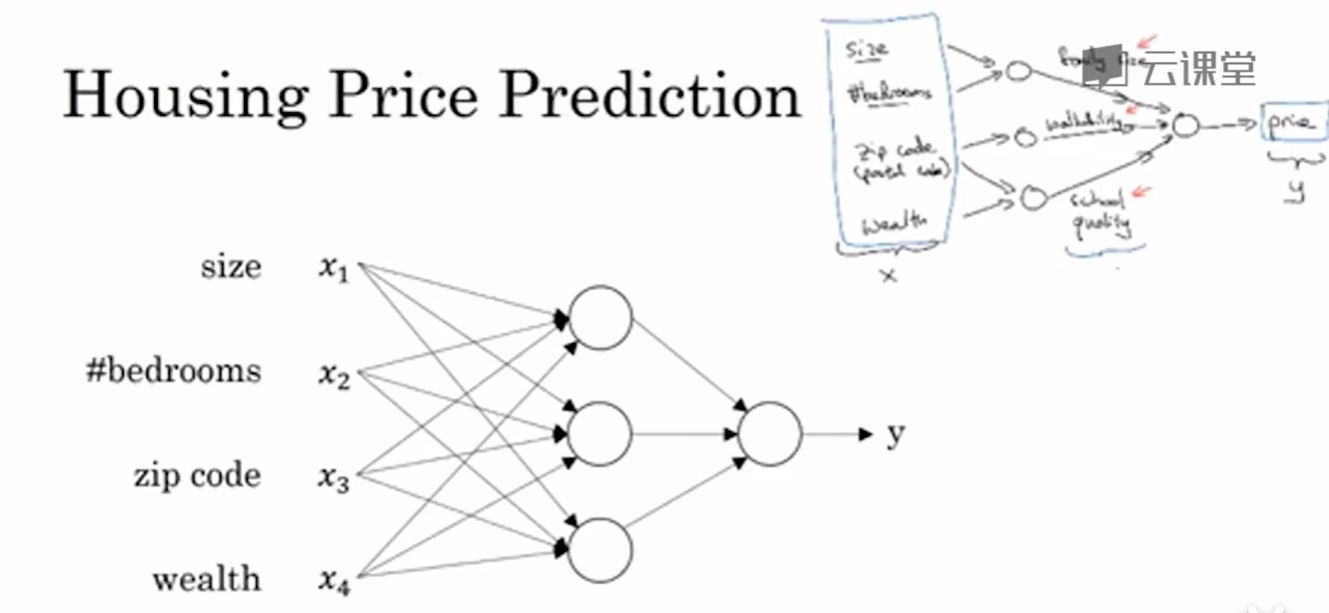
隱藏層是神經網絡中的中間層,負責對輸入數據進行特征提取和變換,為輸出層提供高層次特征
所以神經網絡的功能之一就是當你實現它之后,只要輸入x就能輸出y,因為他可以自己計算你訓練集中的樣本數目以及所有的中間過程,不管訓練集有多大
2.用神經網絡進行監督學習
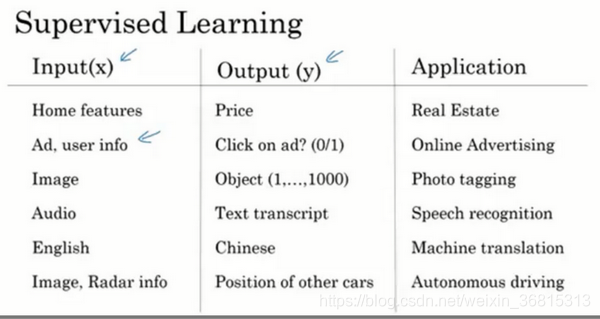
簡單歸類一下:
房地產和在線廣告經常用到的是相對標準的神經網絡
圖像領域經常用到的是卷積神經網絡(CNN)
序列數據(音頻是一維時間序列,語言是最自然的序列數據)用的是遞歸神經網絡RNN(S)
無人駕駛用的是混合神經網絡結構
結構化數據基本上就是簡單的數字數據
非結構化數據包括音頻,圖像,文本
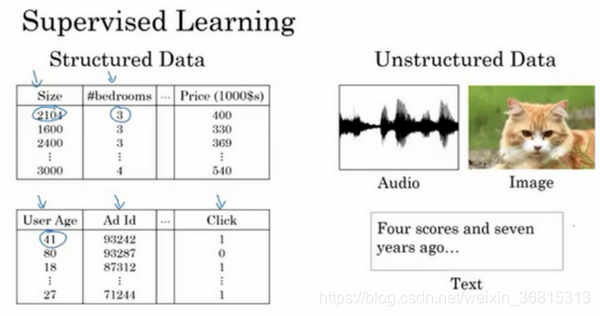
通過深度學習和神經網絡,計算機可以更好地處理非結構化數據,并產生了語音識別、圖像識別、自然語言文字處理等應用
2.神經網絡基礎
習題2.19 總結-深度學習-Stanford吳恩達教授_請考慮以下代碼,c的維度是什么-CSDN博客
1.二元分類
首先我們從一個問題開始說起,這里有一個二分類問題的例子,如果識別這張圖片為貓,則輸出標簽1作為結果;如果識別出不是貓,那么輸出標簽0作為結果。現在我們可以用字母來表示輸出的結果標簽,如下圖:
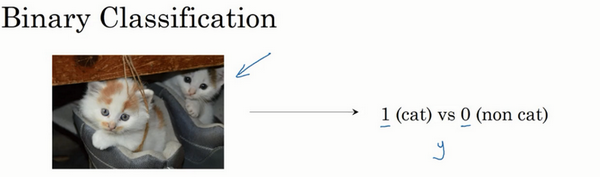
我們需要把像素值提取出來放到特征向量中x中,用nx或者n表示特征向量維度,在所有的二分類問題中,我們的目標是習得一個分類器,它以圖片的特征向量作為1輸入,然后預測y結果是1還是0

在python中表示的是X.shape?=(nx,m)和Y.shape=(1,m)
2.logistic回歸
y^(預測結果)=wT(邏輯回歸的參數,特征權重,維度與x一致)x+b(實數,表示偏差)即y^=wTx+b,這是一個線性回歸得到的線性函數,由于y只能取1或者0,而wTx+b不能保證這一點,所以應該等于wTx+b作為自變量的sigmoid函數,即y^=σ(wTx+b)以此將線性轉為非線性

下圖是sigmoid函數的圖像,如果我把水平軸作為 z zz 軸,那么關于 z zz 的sigmoid函數是這樣的,它是平滑地從0走向1,讓我在這里標記縱軸,這是0,曲線與縱軸相交的截距是0.5,這就是關于的sigmoid函數的圖像。
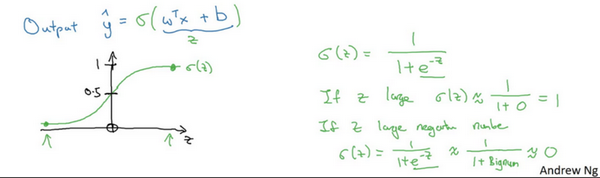
3.logistic回歸損失函數
為什么需要損失函數:通過訓練迭代來得到參數w和b

上標(i)指明數據表示x或者y的第i個訓練樣本
損失函數又叫誤差函數,用來衡量輸出值和實際值有多接近,Loss function:L(y^,y)
和平方誤差損失函數一個效果,如果y等于1,就要讓y^盡可能變大,反之。。
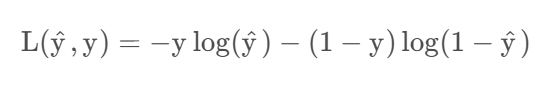
以上是單個樣本定義的損失函數,需要一個整體訓練集的損失函數(整體訓練集的損失函數稱為代價函數):
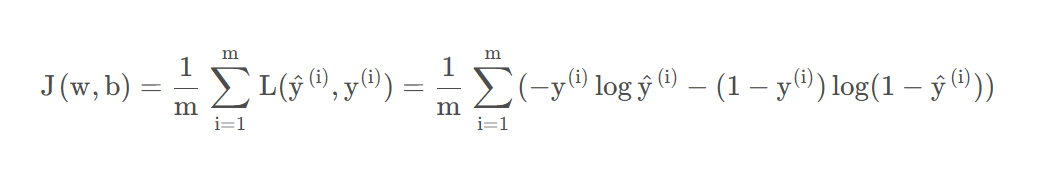
?損失函數或者代價函數的目的是:衡量模型的預測能力的好壞。兩者區別在于前者是定義在單個訓練樣本上的,后者是整個訓練集
?4.梯度下降法
梯度下降法的作用是:在測試集上通過最小化損失函數J(w,b)來訓練參數w和b
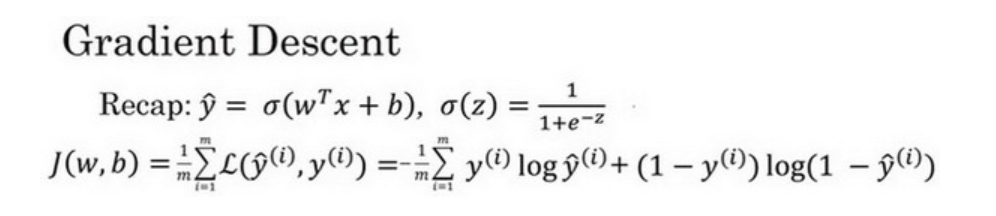 ?
?
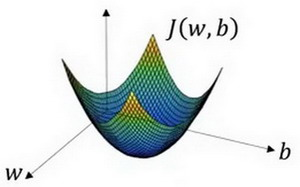
形象化說明:?
 ?
?
J(w,b)是水平軸w和b上的曲面,使J(w,b)最小,找到對應的w和b
由于J(w,b)的特性,我們必須定義代價函數(成本函數) J ( w , b )? 為凸函數。
1.初始化 w和 b (可以隨機初始化,因為無論在哪里初始化,凸函數應該能達到同一1.點或者大致相同的點)
2.朝最抖的下坡走,不斷迭代
3.直到走到全局最優解或者接近全局最優解的地方
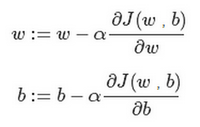 ?
?
 ?
?
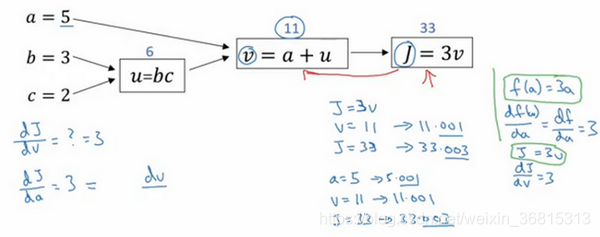
5.計算圖及其導數計算
一個神經網絡的計算,都是按照前向或反向傳播過程組織的。首先我們計算出一個新的網絡的輸出(前向過程),緊接著進行一個反向傳輸操作。后者我們用來計算出對應的梯度或導數。計算圖解釋了為什么我們用這種方式組織這些計算過程
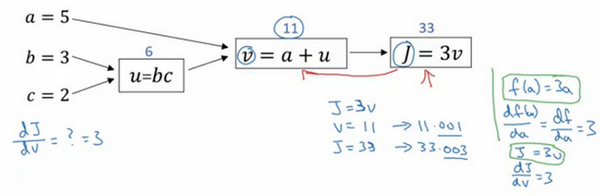
計算圖組織計算的形式是用從左到右的計算
在反向傳播算法中的術語,我們看到,如果你想計算最后輸出變量的導數,使用你最關心的變量對的導數,那么我們就做完了一步反向傳播,在這個流程圖中是一個反向步驟。
 ?
?
再看一個例子:將變量a變為5.001,通過啊的變化,j會變化為33.003,增加了0.003,所以 J 的增量是3乘以 a 的增量,意味著這個導數是3。
 ?
?
鏈式法則:a的增加引起v增加,v的增加又會引起j的增加,J 的變化量就是當你改變 a aa 時,v 的變化量乘以改變 v 時 J 的變化量,在微積分里這叫鏈式法則
 ?
?
現在我想介紹一個新的符號約定,當你編程實現反向傳播時,通常會有一個最終輸出值是你要關心的,最終的輸出變量,你真正想要關心或者說優化的。在這種情況下最終的輸出變量是 J ,就是流程圖里最后一個符號,所以有很多計算嘗試計算輸出變量的導數,所以輸出變量對某個變量的導數,我們就用dvar 命名,如dj_dvar
下面是其他變量的導數:
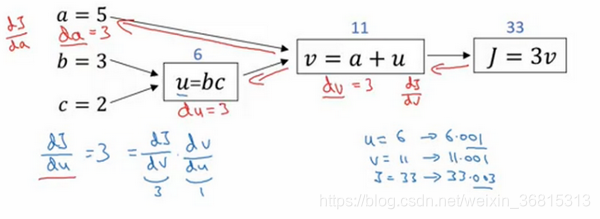 ?
?
程序中,dx表示為
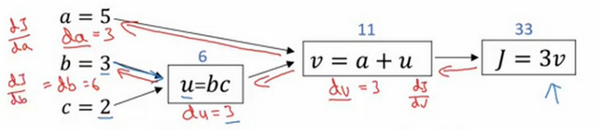 ?
?
所以這是一個計算流程圖,就是正向或者說從左到右的計算來計算成本函數 J JJ ,你可能需要優化的函數,然后反向從右到左計算導數
6.logistic回歸的梯度下降法
為了計算z,輸入參數w1,w2,b以及x1,x2
邏輯回歸:,其中,
,
損失函數:
代價函數:
若只考慮單個樣本,其代價函數:,其中a是邏輯回歸的輸出,y是樣本的標簽值
在梯度下降法中,w和b的修正量可以表達如下:
為了使得邏輯回歸中最小化代價函數 L ( a , y ) L(a,y)L(a,y) ,我們需要做的僅僅是修改參數 w ww 和 b bb 的值。前面我們已經講解了如何在單個訓練樣本上計算代價函數的前向步驟。現在讓我們來討論通過反向計算出導數
通過鏈式法則可知:
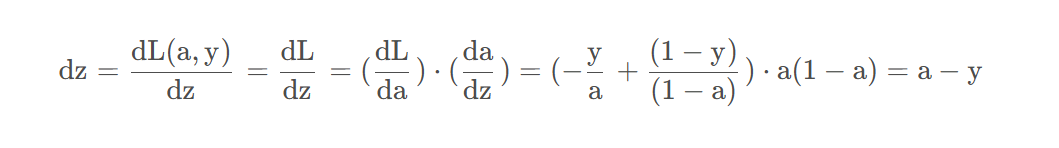 ?
?

通過計算圖的知識點,我們需要做的就是如下事情:
dz=(a-y)計算dz,dw1=x1*dz1計算dw1,更新,同理w2
db=dz計算db,更新
7.m個樣本的梯度下降
帶有求和的全局代價函數,實際上是1到 m 項各個損失的平均。 所以它表明全局代價函數對 w1的微分,對w1的微分也同樣是各項損失對w1微分的平均。
代碼與初始化:
J=0;dw1=0;dw2=0;db=0;
for i = 1 to mz(i) = wx(i)+b;a(i) = sigmoid(z(i));J += -[y(i)log(a(i))+(1-y(i))log(1-a(i));dz(i) = a(i)-y(i);dw1 += x1(i)dz(i);dw2 += x2(i)dz(i);db += dz(i);
J/= m;
dw1/= m;
dw2/= m;
db/= m;
w=w-alpha*dw
b=b-alpha*db
如果有多個特征w1,w2....wn,需要再加一個循環
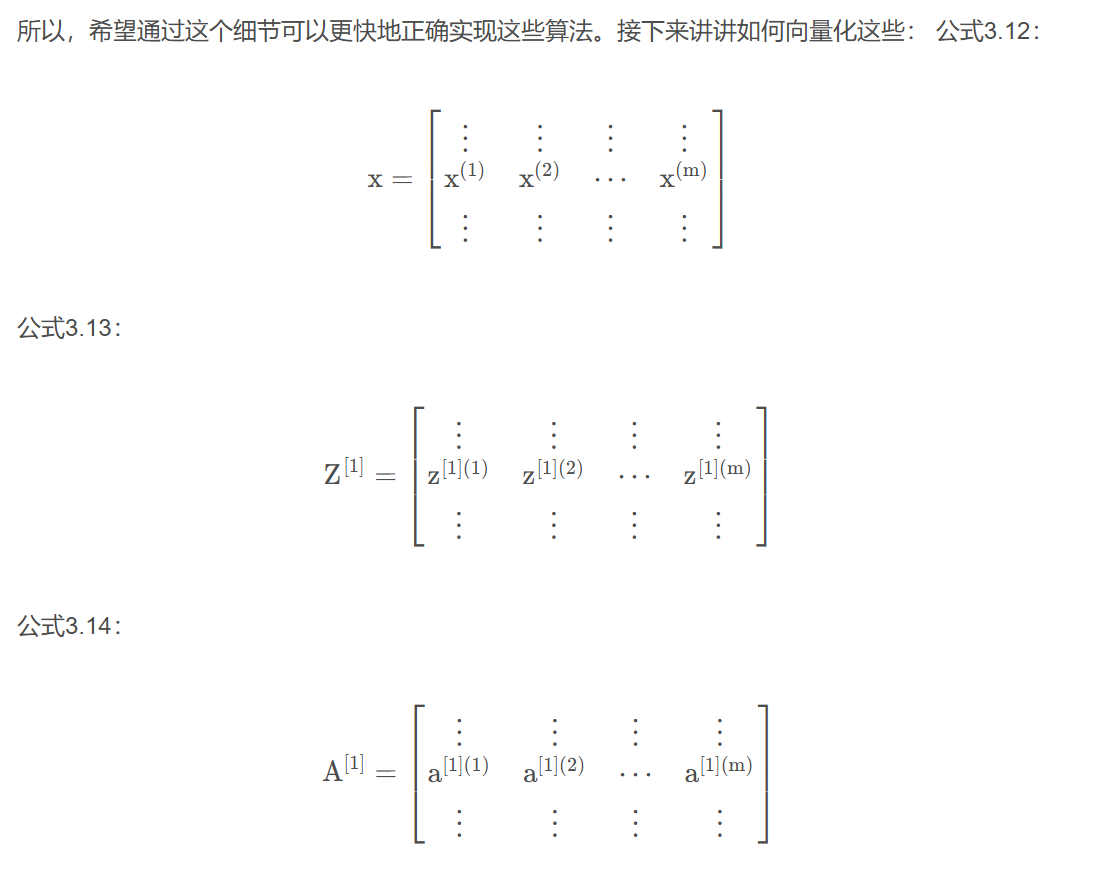
8.向量化
因為深度學習算法處理大數據集效果很好,所以你的代碼運行速度非常重要,否則如果在大數據集上,你的代碼可能花費很長時間去運行,你將要等待非常長的時間去得到結果。所以在深度學習領域,運行向量化是一個關鍵的技巧。
向量化實現將會非常直接計算代碼如下:z=np.dot(w,x)+b
import numpy as np #導入numpy庫
a = np.array([1,2,3,4]) #創建一個數據a
print(a)
# [1 2 3 4]
import time #導入時間庫
a = np.random.rand(1000000)
b = np.random.rand(1000000) #通過round隨機得到兩個一百萬維度的數組
tic = time.time() #現在測量一下當前時間
#向量化的版本
c = np.dot(a,b)
toc = time.time()
print(“Vectorized version:” + str(1000*(toc-tic)) +”ms”) #打印一下向量化的版本的時間
?
#繼續增加非向量化的版本
c = 0
tic = time.time()
for i in range(1000000):c += a[i]*b[i]
toc = time.time()
print(c)
print(“For loop:” + str(1000*(toc-tic)) + “ms”)#打印for循環的版本的時間
為了計算 +[bb ? b],numpy命令是Z=np.dot(w.T,x)+b。這里在Python中有一個巧妙的地方,這里 b 是一個實數,或者你可以說是一個1*1矩陣,只是一個普通的實數。但是當你將這個向量加上這個實數時,Python自動把這個實數b 擴展成一個1?m 的行向量。所以這種情況下的操作似乎有點不可思議,它在Python中被稱作廣播
不需要for循環,利用m 個訓練樣本一次性計算出小寫 z 和小寫 a ,用一行代碼即可完成。
Z = np.dot(w.T,X) + b
這一行代碼:A = [ a ( 1 ) , a ( 2 ) , ? ??, a ( m ) ] = σ ( Z ),通過恰當地運用 σ? 一次性計算所有a 。這就是在同一時間內你如何完成一個所有m 個訓練樣本的前向傳播向量化計算。
如何同時計算?m mm?個數據的梯度,并且實現一個非常高效的邏輯回歸算法:
通過dz=a-y的原理實現計算dZ=A?Y=[a(1)?y(1),a(2)?y(2),?,a(m)?y(m)]?
db=m1??np.sum(dZ)代替循環
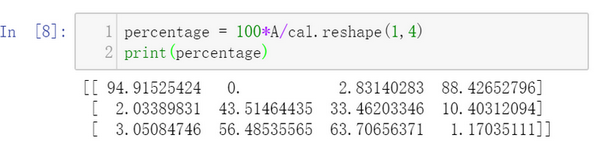
A.sum(axis = 0)中的參數axis。axis用來指明將要進行的運算是沿著哪個軸執行,在numpy中,0軸是垂直的,也就是列,而1軸是水平的,也就是行。
而第二個A/cal.reshape(1,4)指令則調用了numpy中的廣播機制。這里使用3?4 的矩陣 A 除以 1?4 的矩陣 cal 。技術上來講,其實并不需要再將矩陣cal reshape(重塑)成 1?4 ,因為矩陣 cal 本身已經是1?4 了。但是當我們寫代碼時不確定矩陣維度的時候,通常會對矩陣進行重塑來確保得到我們想要的列向量或行向量。重塑操作reshape是一個常量時間的操作,時間復雜度是O(1),它的調用代價極低。
3.淺層神經網絡
習題3.12 總結-深度學習-Stanford吳恩達教授_對于隱藏單元,tanh激活通常比-CSDN博客
1.神經網絡表示
我們首先關注一個例子,本例中的神經網絡只包含一個隱藏層。這是一張神經網絡的圖片,讓我們給此圖的不同部分取一些名字。
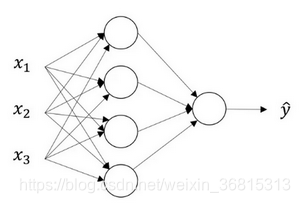
輸入層:x1,x2,x3....
隱藏層:圖中的四個節點,中間結點的準確值我們是不知道到的,也就是說你看不見它們在訓練集中應具有的值。你能看見輸入的值,你也能看見輸出的值,但是隱藏層中的東西,在訓練集中你是無法看到的
輸出層:只有一個節點的層,負責產生預測值
這里用表示輸入層,
表示隱藏層,隱藏層中的節點用
表示(n是第n個的意思),
表示輸出層
上述表示方法的原因是當我們計算網絡的層數時,輸入層是不算入總層數內,所以隱藏層是第一層,輸出層是第二層。第二個慣例是我們將輸入層稱為第零層,所以在技術上,這仍然是一個三層的神經網絡,因為這里有輸入層、隱藏層,還有輸出層。但是在傳統的符號使用中,如果你閱讀研究論文或者在這門課中,你會看到人們將這個神經網絡稱為一個兩層的神經網絡,因為我們不將輸入層看作一個標準的層。
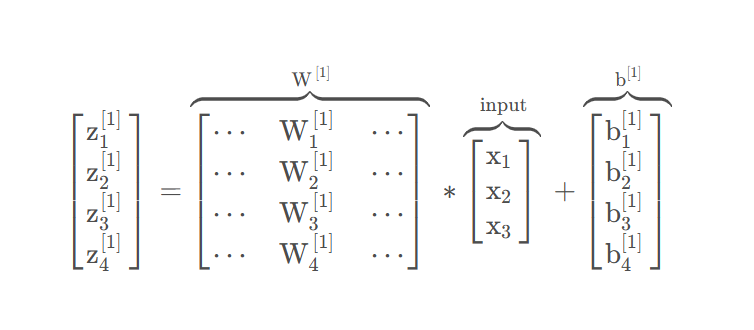
最后,我們要看到的隱藏層以及最后的輸出層是帶有參數的,這里的隱藏層將擁有兩個參數W和b ,我將給它們加上上標?和
,表示這些參數是和第一層這個隱藏層有關系的。之后在這個例子中我們會看到 W 是一個4x3的矩陣,而 b 是一個4x1的向量,第一個數字4源自于我們有四個結點或隱藏層單元,然后數字3源自于這里有三個輸入特征,輸出層同理
,從維數上來看,它們的規模分別是1x4以及1x1。1x4是因為隱藏層有四個隱藏層單元而輸出層只有一個單元。
不管在哪一層,權重W的形狀是(輸出維度,輸入維度),偏置b的形狀與輸出維度一致,即(輸出維度,1)
2.計算神經網絡輸出
邏輯回歸的計算有兩個步驟,首先你按步驟計算出z ,然后在第二步中你以sigmoid函數為激活函數計算z得出a ,一個神經網絡只是這樣子做了好多次重復計算。
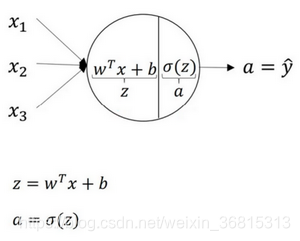
向量化后有:,
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ??
 第n層的輸入為
第n層的輸入為,輸出為
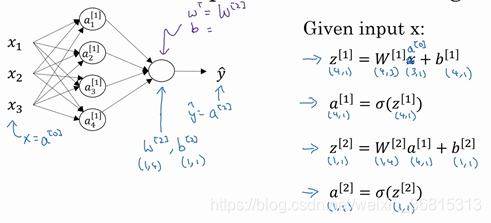
3.多個例子中的向量化
規定,(i)是第i個訓練樣本,[2]是第二層

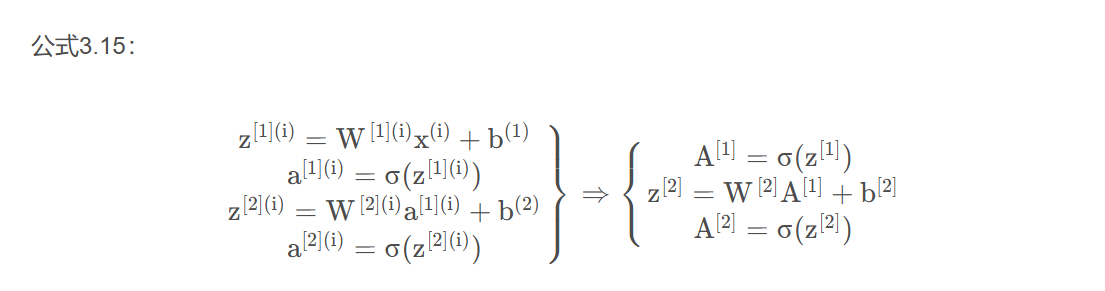
即第n層的輸入為,輸出為
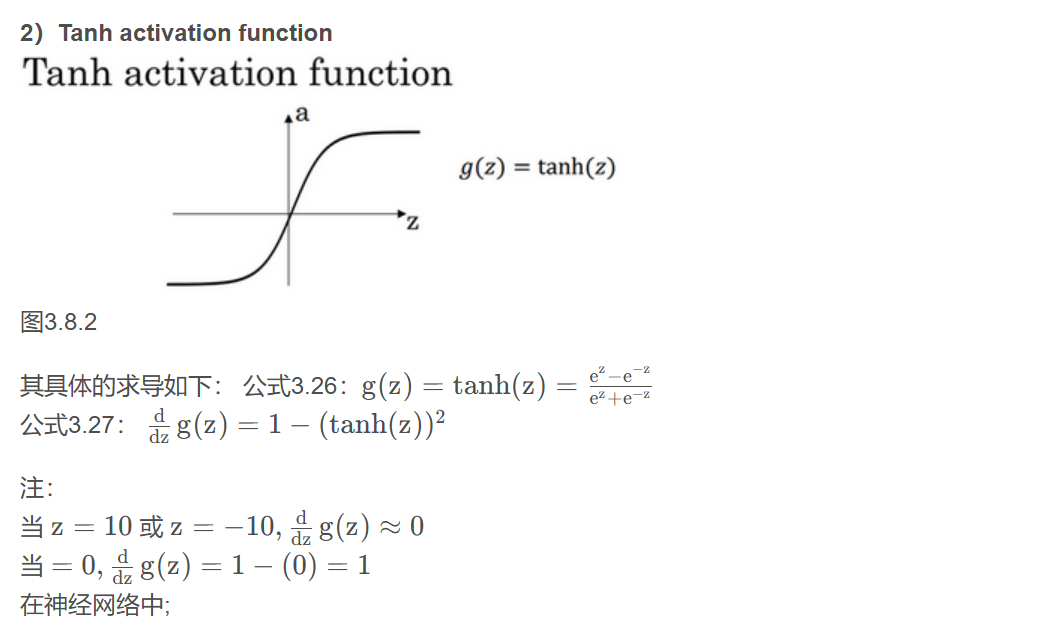
4.激活函數
使用一個神經網絡時,需要決定使用哪種激活函數用隱藏層上,哪種用在輸出節點上。到目前為止只用過sigmoid激活函數,但是,有時其他的激活函數效果會更好
在討論優化算法時,有一點要說明:基本已經不用sigmoid激活函數了,tanh函數在所有場合都優于sigmoid函數。(二分類由于1需要讓輸出層在0-1間還是采用sigmoid函數)
選擇激活函數的經驗法則:
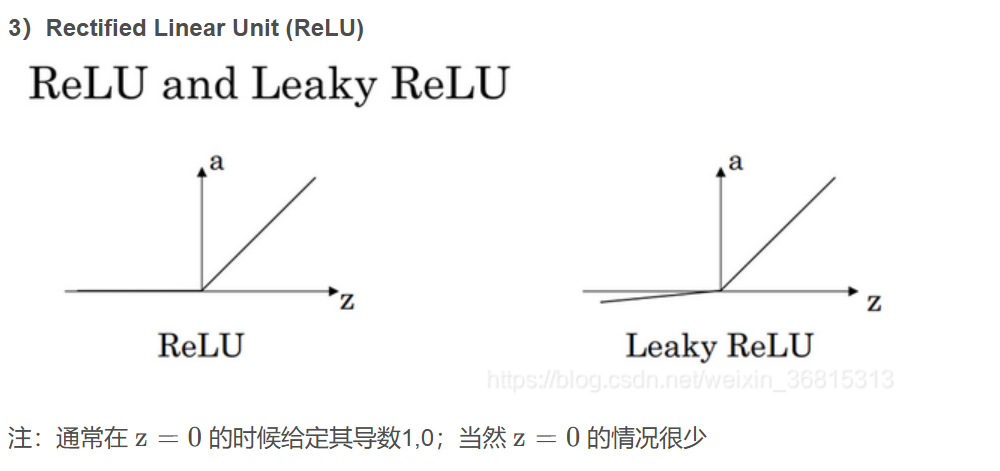
如果輸出是0、1值(二分類問題),則輸出層選擇sigmoid函數,然后其它的所有單元都選擇Relu函數(z正值時輸出恒等于1,其他為0)。
這是很多激活函數的默認選擇,如果在隱藏層上不確定使用哪個激活函數,那么通常會使用Relu激活函數。有時,也會使用tanh激活函數,但Relu的一個優點是:當z是負值的時候,導數等于0。
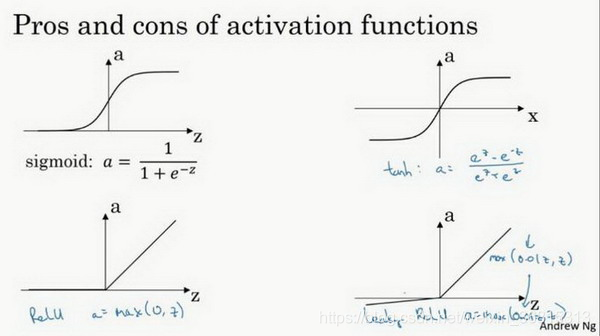
快速概括一下不同激活函數的過程和結論:
sigmoid激活函數:除了輸出層是一個二分類問題基本不會用它。
tanh激活函數:tanh是非常優秀的,幾乎適合所有場合。
ReLu激活函數:最常用的默認函數,如果不確定用哪個激活函數,就使用ReLu或者Leaky ReLu。a=max(0.01z,z) 為什么常數是0.01?當然,可以為學習算法選擇不同的參數。
5.為什么需要非線性激活函數
如果你是用線性激活函數或者叫恒等激勵函數,那么神經網絡只是把輸入線性組合再輸出(可自行推導)
不能在隱藏層用線性激活函數,可以用ReLU或者tanh或者leaky ReLU或者其他的非線性激活函數,唯一可以用線性激活函數的通常就是輸出層
6.激活函數的導數
針對以下四種激活,求其導數如下:


7.神經網絡的梯度下降法
訓練參數需要做梯度下降,在訓練神經網絡的時候,隨機初始化參數很重要,而不是初始化成全零。當你參數初始化成某些值后,每次梯度下降都會循環計算以下預測值:,(i=1,2,3,...,m)
其實就是把之前的公式帶到每一層里面去


上述是反向傳播的步驟,注:這些都是針對所有樣本進行過向量化,Y 是 1?m 的矩陣;這里np.sum是python的numpy命令,axis=1表示水平相加求和,keepdims是防止python輸出那些古怪的秩數(n,) ,加上這個確保矩陣?這個向量輸出的維度為(n,1)這樣的標準形式
目前為止,我們計算的都和Logistic回歸十分相似,但當你開始計算反向傳播時,你需要計算,是隱藏層函數的導數
8.隨機初始化
當你訓練神經網絡時,權重隨機初始化是很重要的。對于邏輯回歸,把權重初始化為0當然也是可以的。但是對于一個神經網絡,如果你把權重或者參數都初始化為0,那么梯度下降將不會起作用
如果你把權重都初始化為0,那么由于隱含單元開始計算同一個函數,所有的隱含單元就會對輸出單元有同樣的影響。一次迭代后同樣的表達式結果仍然是相同的,即隱含單元仍是對稱的。通過推導,兩次、三次、無論多少次迭代,不管你訓練網絡多長時間,隱含單元仍然計算的是同樣的函數。因此這種情況下超過1個隱含單元也沒什么意義,因為他們計算同樣的東西。

你也許會疑惑,這個常數從哪里來,為什么是0.01,而不是100或者1000。我們通常傾向于初始化為很小的隨機數。因為如果你用tanh或者sigmoid激活函數,或者說只在輸出層有一個Sigmoid,如果(數值)波動太大,當你計算激活值時
如果W 很大,z 就會很大或者很小,因此這種情況下你很可能停在tanh/sigmoid函數的平坦的地方,這些地方梯度很小也就意味著梯度下降會很慢,因此學習也就很慢。
事實上有時有比0.01更好的常數,當你訓練一個只有一層隱藏層的網絡時(這是相對淺的神經網絡,沒有太多的隱藏層),設為0.01可能也可以。但當你訓練一個非常非常深的神經網絡,你可能要試試0.01以外的常數
4.深層神經網絡
習題4.9 總結-深度學習第一課《神經網絡與深度學習》-Stanford吳恩達教授_在前向傳播期間,在層l的前向傳播函數中,您需要知道層l中的激活函數(sigmoid,tanh,rel-CSDN博客
1.深層神經網絡
區別于淺層,深層擁有更多的隱藏層,重要特征就是網絡的層數多,因此能攜帶更大的數據,可以實現更復雜的數據關系映射。
記住當我們算神經網絡的層數時,我們不算輸入層,我們只算隱藏層和輸出層。
2.深層的前向傳播
向量化的過程可以寫成:
3.核對矩陣的維度
W的維度是(下一層的維數,前一層的維數),即
b的維度是(下一層的維數,1),即
維度相同,
維度相同,且w和b向量化維度不變,但z,a以及x的維度會向量化后發生改變

在你做深度神經網絡的反向傳播時,一定要確認所有的矩陣維數是前后一致的,可以大大提高代碼通過率
4.為什么使用深層表示
為什么需要這么多的隱藏層:較早的前幾層學習一些低層次的簡單特征,等到后面幾層,就能把簡單的特征結合起來,取探測更加復雜的東西
另外一個,關于神經網絡為何有效的理論,來源于電路理論,它和你能夠用電路元件計算哪些函數有著分不開的聯系。根據不同的基本邏輯門,譬如與門、或門、非門。在非正式的情況下,這些函數都可以用相對較小,但很深的神經網絡來計算,小在這里的意思是隱藏單元的數量相對比較小,但是如果你用淺一些的神經網絡計算同樣的函數,也就是說在我們不能用很多隱藏層時,你會需要成指數增長的單元數量才能達到同樣的計算結果。
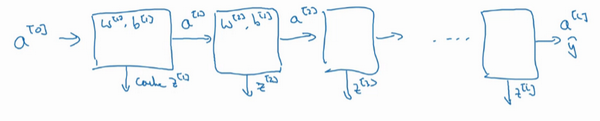
5.搭建深層神經網絡塊
如果實現了這兩個函數(正向和反向),神經網絡的計算過程會是這樣的:
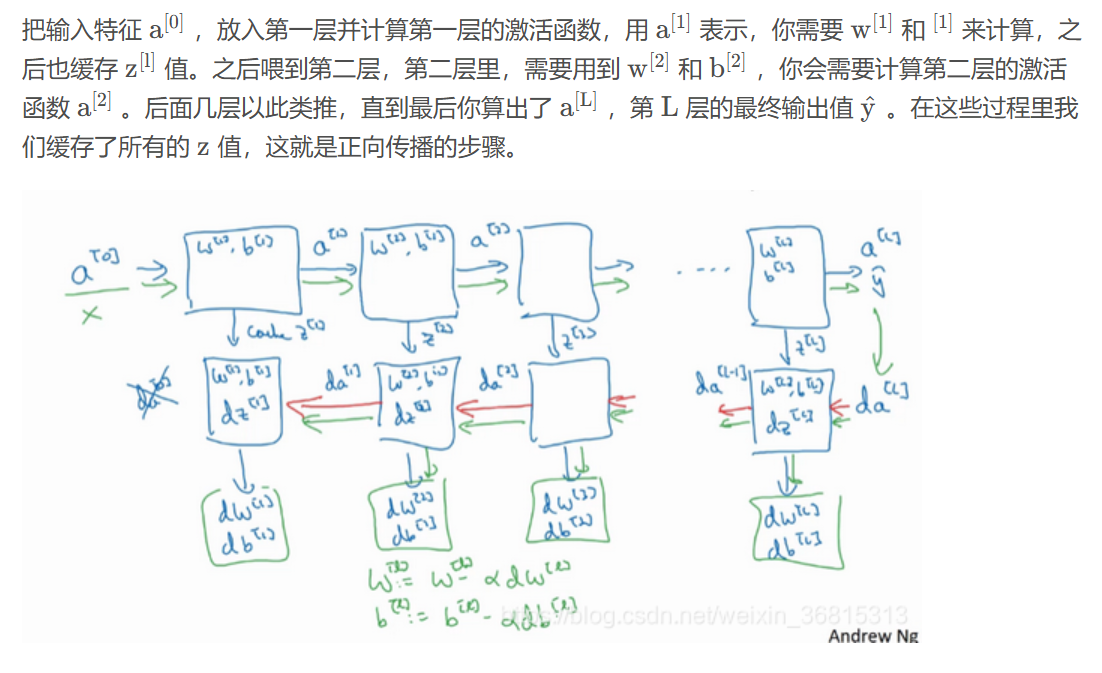

6.前向和反向傳播
前向傳播向量化的過程可以寫成:
這里的Z又稱為前向和反向傳播的緩存
?反向傳播的步驟:輸入為,輸出為


7.參數和超參數?
詳解可見還搞不懂什么是參數,超參數嗎?三分鐘快速了解參數與超參數的概念和區別!!!-CSDN博客
想要你的深度神經網絡起到很好的效果,需要好好地規劃你的參數和超參數
參數一般是模型中可被學習和調整的參數,通常是通過訓練集數據來自動學習的
超參數是在算法運行之前就設置好的,用于控制模型的行為和性能
如學習率,迭代次數,隱藏層數目,隱藏層單元數目,激活函數的選擇。。。
尋找超參數的最優值:通過idea-code-experiment-idea循環,嘗試各種不同的參數,實現模型并觀察是否成功,然后再迭代。



】KNN算法與模型評估調優)




:Python 的函數——函數的參數)










