兩節點rac adg環境4個實例,節點1異常重啟后IO報錯?
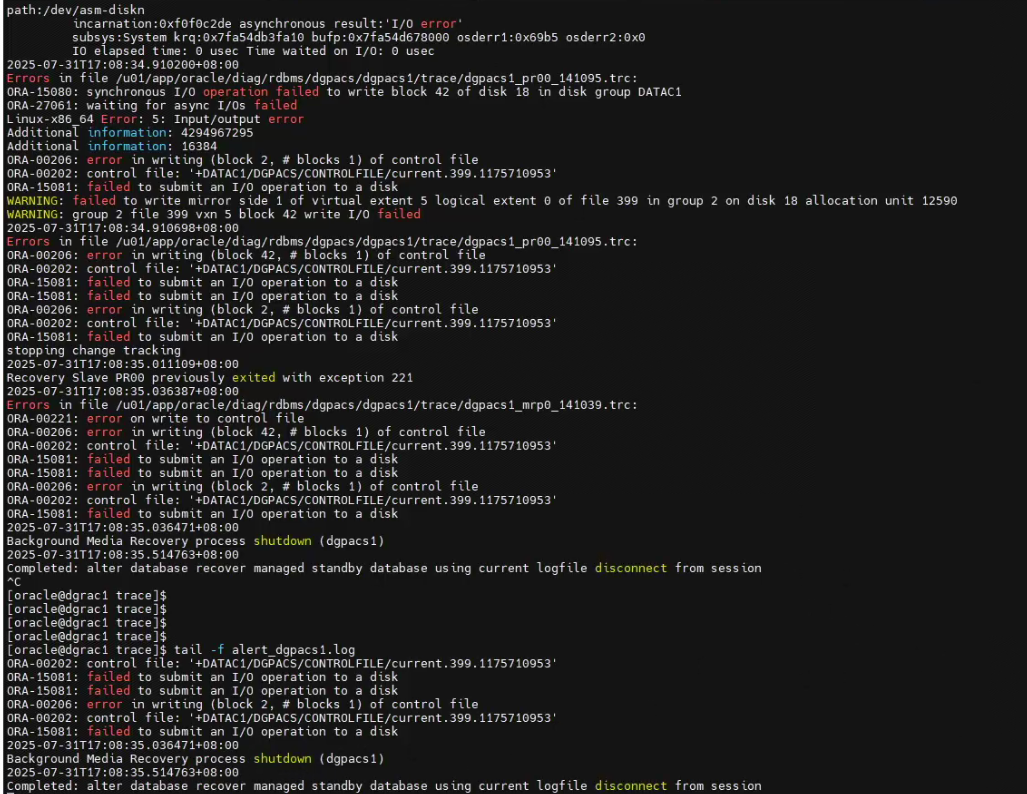
檢查控制文件為0字節,
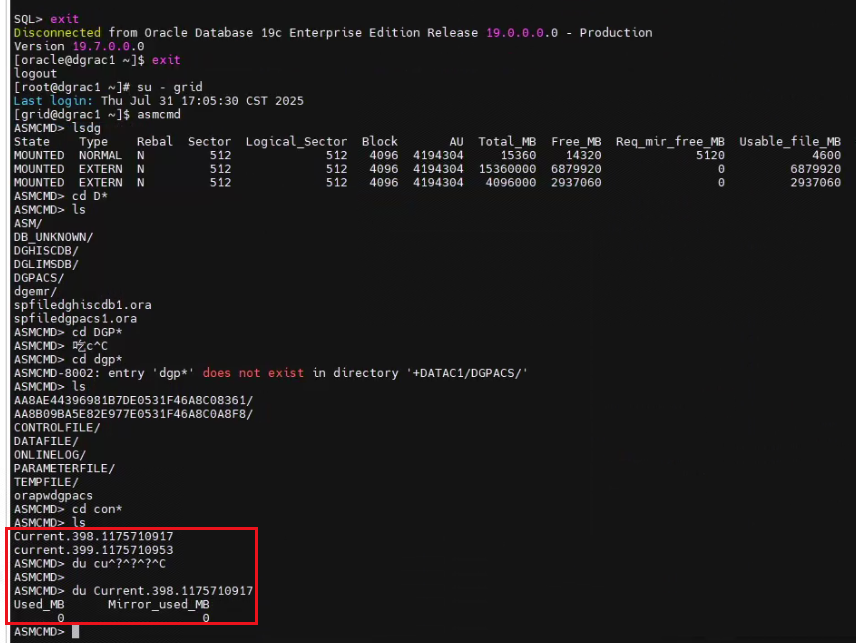
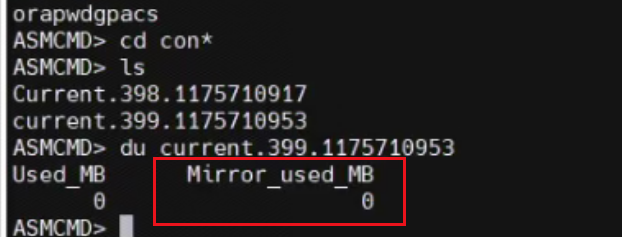
第一感覺是不是控制文件損壞了?但節點2說是沒有報錯,理論上如果控制文件壞了,庫應該掛掉了。
嘗試重啟另外一共adg實例,發現讀取其它數據文件也IO讀寫錯誤。
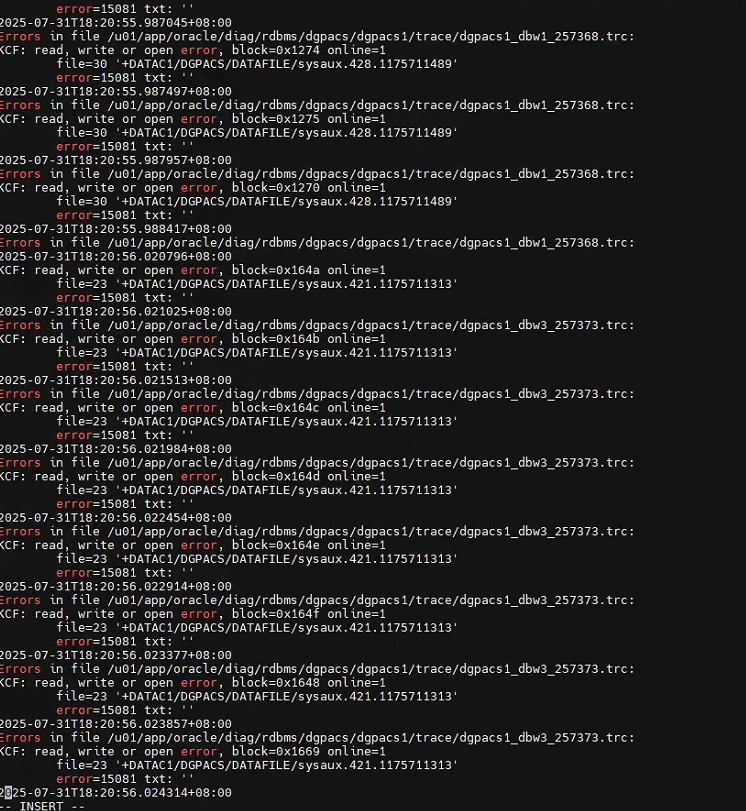
這說明大概率是存儲鏈路或存儲出現故障了。
檢查操作系統日志/var/log/messages發現udev的rules文件竟然報錯,檢查文件發現確實多了兩個??號。(比較奇怪的是這個系統已經跑了有1年多都正常的,節點1也重啟過多次,系統沒有報過上述錯誤,檢查文件時間也還是2019年前的,最近并沒有變更)
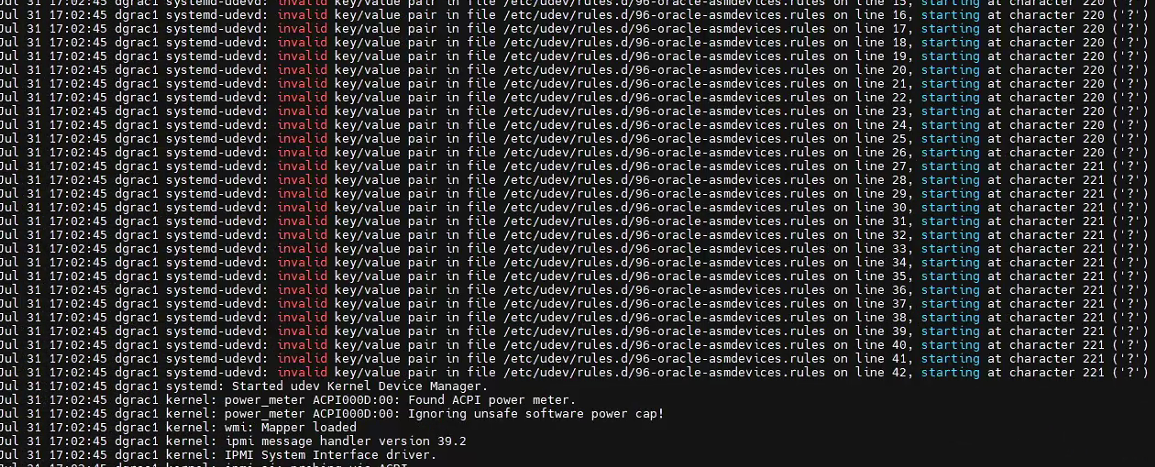
修改兩節點文件96-oracle-asmdevices.rules,后重啟兩節點:
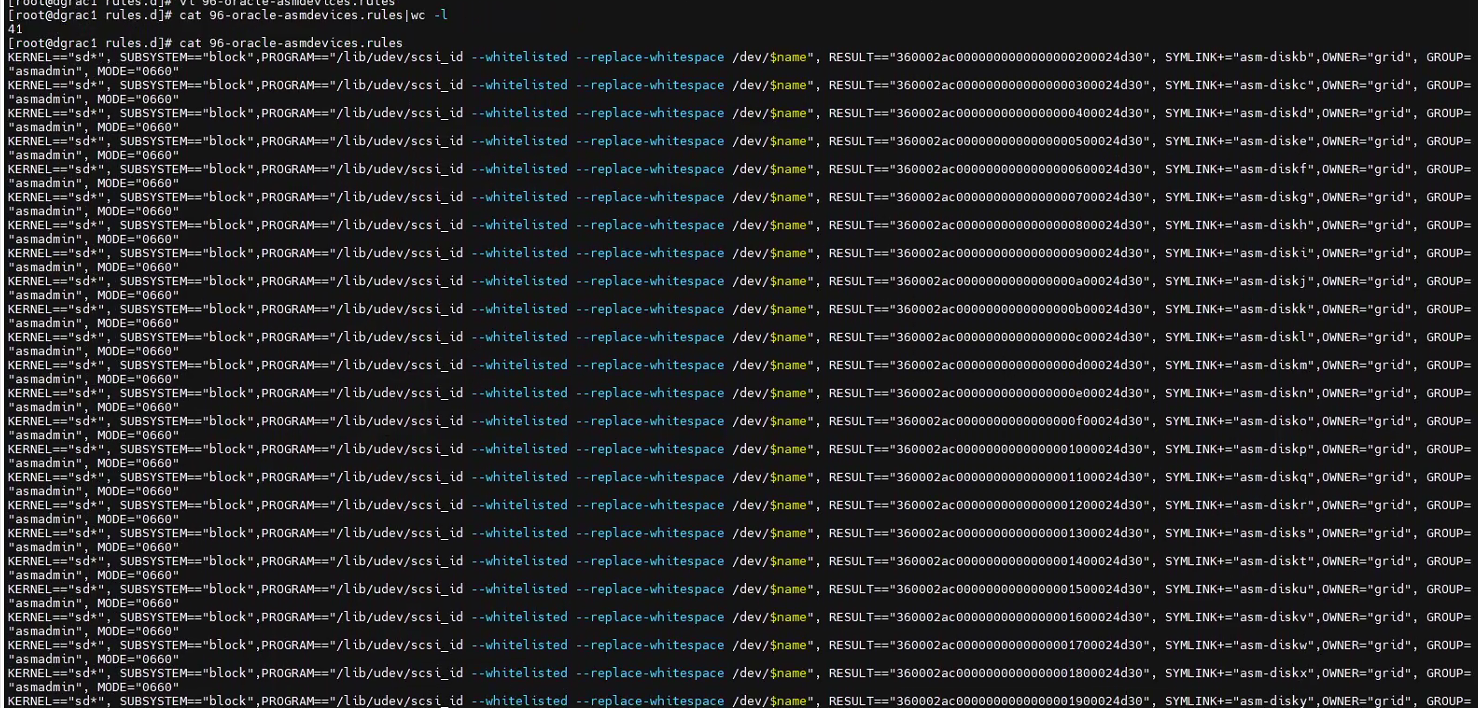
發現磁盤識別是正常的,但集群服務半天沒有正常起來。
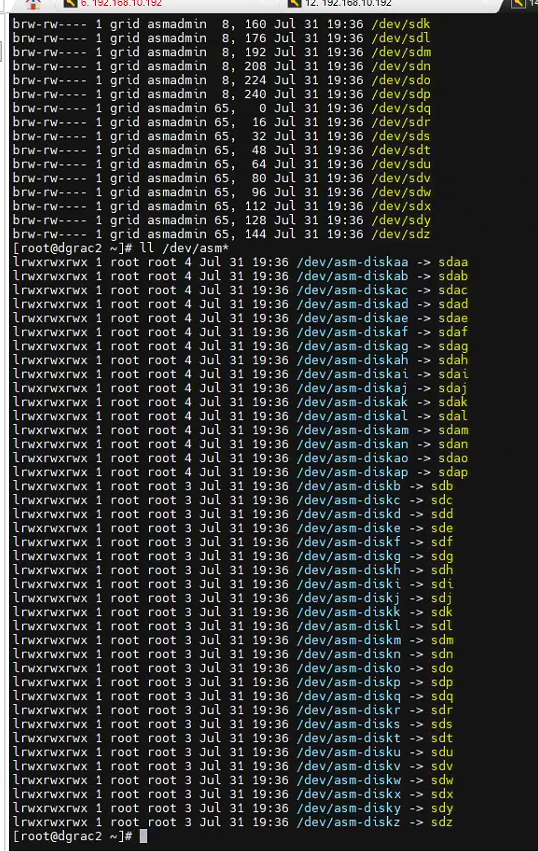
只有兩個進程:
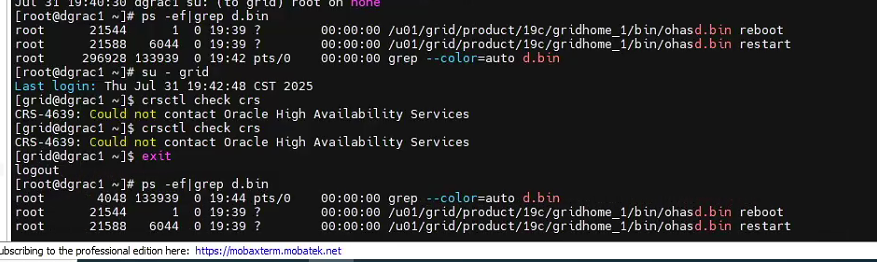
強制停掉兩個節點的集群服務,kill -9 d.bin看到的進程號。
手動啟動crs依然報錯:
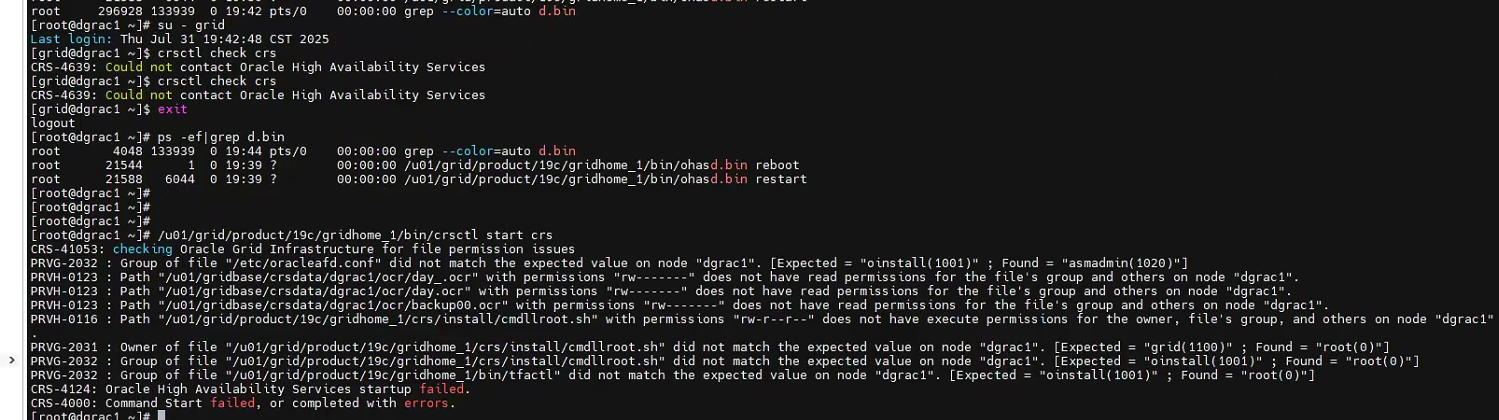
不管了,再次kill -9 d.bin看到的進程號
兩個節點刪除集群啟動的臨時文件rm -rf /var/log/.oracle/*

重啟兩個節點,過5分鐘,節點1集群服務器啟動正常,但節點2還是只有兩個集群進程始終起不來。
再次?刪除節點2的集群啟動的臨時文件rm -rf /var/log/.oracle/*,reboot后,節點2也正常啟動集群服務了。
怪不怪???
?
?
和案例解析)





:輸出格式化、基本運算符)
:磁盤空間滿、重選主節點)











