目錄
1.引言
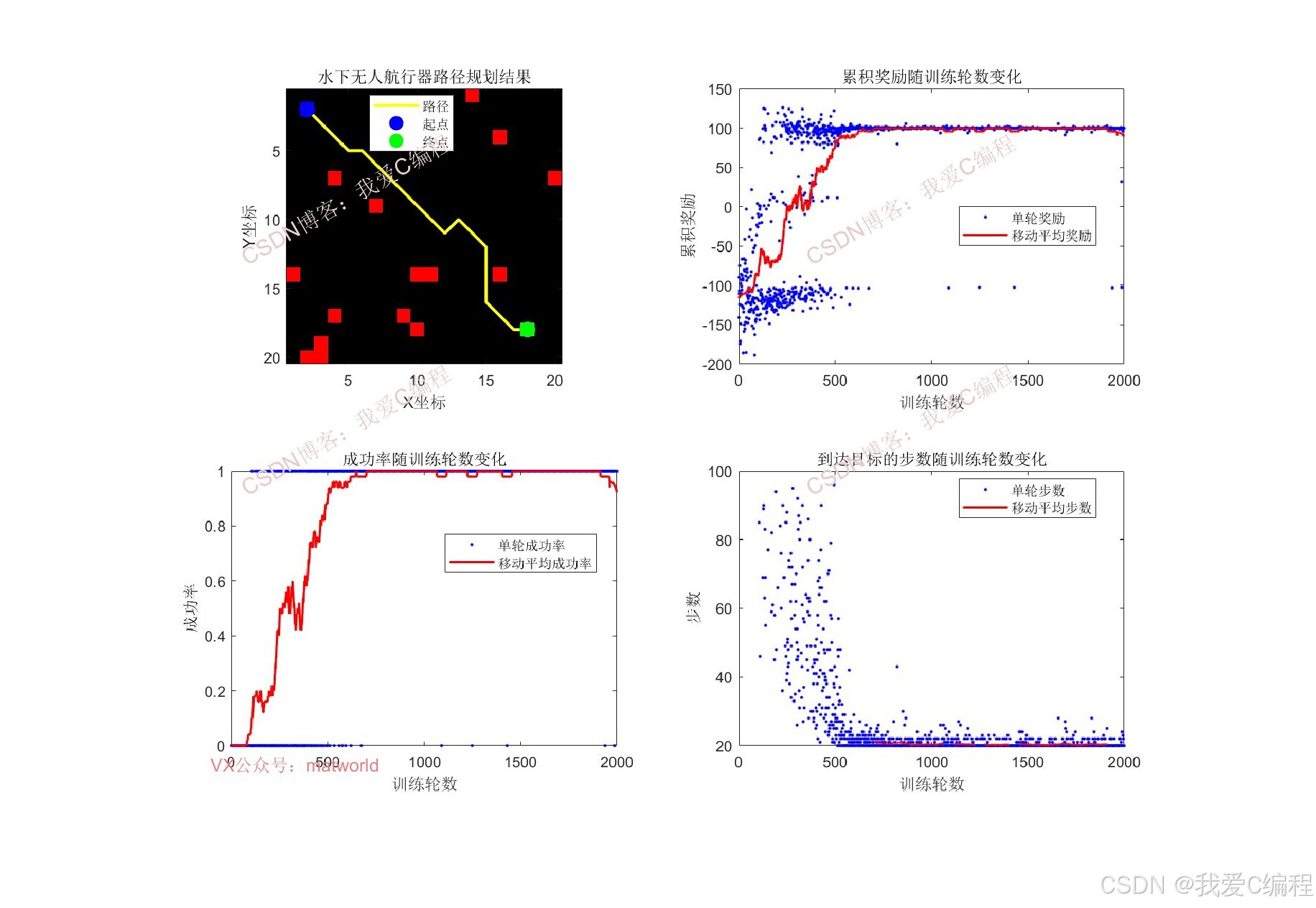
2.算法仿真效果演示
3.數據集格式或算法參數簡介
4.算法涉及理論知識概要
5.參考文獻
6.完整算法代碼文件獲得
1.引言
? ? ? ?水下無人航行器 (Autonomous Underwater Vehicle, AUV) 的路徑規劃與避障是海洋探索、資源開發和軍事應用中的關鍵技術。傳統的路徑規劃方法 (如A*、Dijkstra) 往往難以應對復雜多變的海洋環境,而強化學習 (尤其是Q-Learning) 因其無需精確環境模型、能在動態環境中自適應學習的特性,成為AUV路徑規劃的理想選擇。
2.算法仿真效果演示
軟件運行版本:
matlab2024b
仿真結果如下(仿真操作步驟可參考程序配套的操作視頻,完整代碼運行后無水印):
3.數據集格式或算法參數簡介
%% 參數設置
gridSize = 20; % 環境網格大小
startPos = [2, 2]; % 起始位置
goalPos = [18, 18]; % 目標位置
numObstacles = 15; % 障礙物數量
maxEpisodes = 2000; % 訓練輪數
maxSteps = 100; % 每輪最大步數
learningRate = 0.1; % 學習率
discountFactor = 0.99; % 折扣因子
explorationRate = 1.0; % 探索率
minExplorationRate = 0.01; % 最小探索率
explorationDecay = 0.995; % 探索率衰減率
0Z_023m4.算法涉及理論知識概要
? ? ? ?強化學習是一種通過智能體 (Agent) 與環境 (Environment) 交互來學習最優行為策略的機器學習方法。其核心要素包括:
- 智能體 (Agent):即 AUV,通過傳感器感知環境狀態并執行動作
- 環境 (Environment):即水下環境,包括障礙物、水流、目標位置等
- 狀態 (State):智能體在環境中的當前情況表示,如位置、速度、障礙物分布等
- 動作 (Action):智能體可以執行的操作,如前進、轉向等
- 獎勵 (Reward):環境對智能體動作的反饋,用于評估動作的好壞
強化學習的目標是學習一個最優策略π*,使得智能體在環境中累積的長期獎勵最大化。
? ? ? ?Q-Learning是一種無模型的強化學習算法,通過學習狀態 - 動作對的價值函數Q(s,a)來確定最優策略。Q(s,a)表示在狀態s下執行動作a后獲得的期望累積獎勵。Q-Learning的核心更新公式為:

獎勵函數設計
? ? ? ?獎勵函數是強化學習的核心,直接影響學習效果。對于AUV路徑規劃與避障,獎勵函數應包含以下幾個方面:

ε- 貪婪策略
為了平衡探索(Exploration)和利用(Exploitation),Q-Learning通常采用ε-貪婪策略:
- 以概率ε隨機選擇一個動作 (探索)
- 以概率1-ε選擇當前Q值最大的動作 (利用)
數學表示:
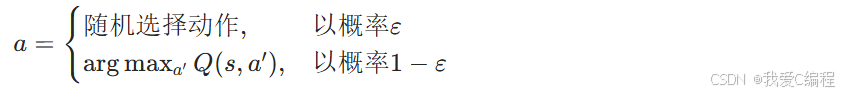
通常,ε會隨著訓練過程逐漸減小,使算法從探索為主過渡到利用為主。常見的ε衰減函數為:
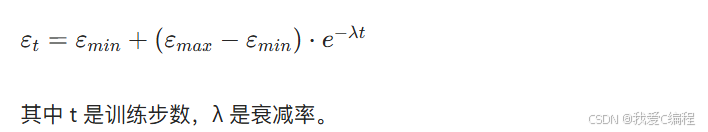
Q更新
? ? ? ?在每個時間步,根據當前狀態s選擇動作a,執行動作后觀察環境反饋的獎勵r和新狀態s',然后更新Q表:
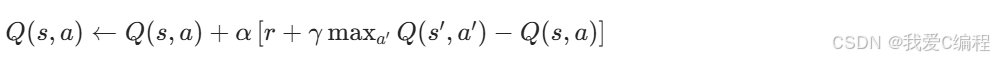
完整算法偽代碼:
初始化Q表Q(s,a)為任意值
對于每個訓練episode:初始化AUV位置s,設置episode終止標志為False對于episode中的每個時間步:根據ε-貪婪策略從Q表中選擇動作a執行動作a,觀察獎勵r和新狀態s'更新Q表: Q(s,a) ← Q(s,a) + α[r + γmax_a'Q(s',a') - Q(s,a)]s ← s'如果達到目標點或發生碰撞:設置episode終止標志為True5.參考文獻
[1]徐莉.Q-learning研究及其在AUV局部路徑規劃中的應用[D].哈爾濱工程大學,2004.DOI:10.7666/d.y670628.
[2]王立勇,王弘軒,蘇清華,等.基于改進Q-Learning的移動機器人路徑規劃算法[J].電子測量技術, 2024, 47(9):85-92.
6.完整算法代碼文件獲得
完整程序見博客首頁左側或者打開本文底部
V
)


)









)
![[CSS]讓overflow不用按shift可以滾輪水平滾動(純CSS)](http://pic.xiahunao.cn/[CSS]讓overflow不用按shift可以滾輪水平滾動(純CSS))


)
)
