以下是使用“咕嘎批量OCR識別圖片PDF多區域內容重命名導出表格系統”進行操作的具體步驟:
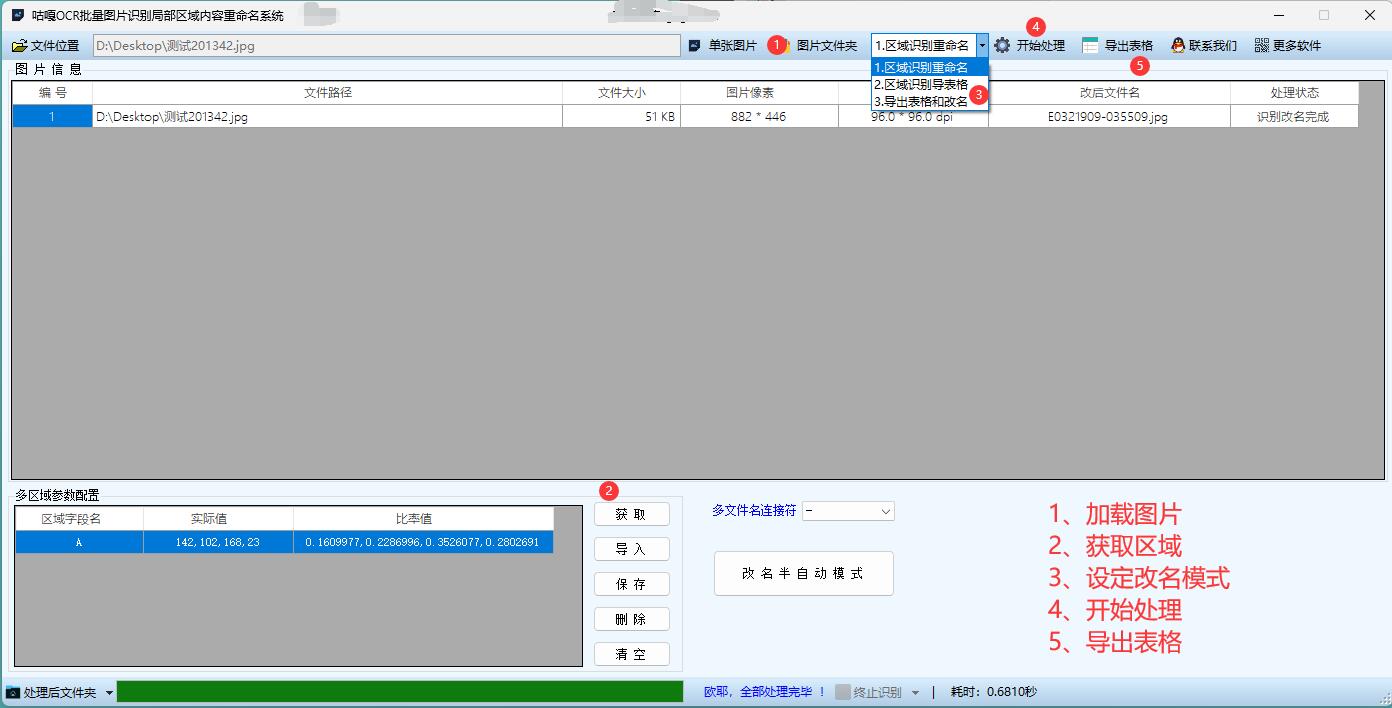
1. 打開工具并獲取區域坐標
打開軟件后,選擇“PDF識別模式”。
導入一個PDF文件作為樣本,框選需要提取文字的區域,并保存區域坐標。如果有多個區域需要識別,可多次框選并保存。
3. 導入文件并批量處理
點擊“導入PDF”按鈕,選擇待處理的PDF文件所在的文件夾。
加載之前保存的區域坐標,點擊“開始處理”按鈕,軟件將自動提取指定區域的文字內容。
4. 批量重命名
識別完成后,軟件會根據提取的內容對文件進行批量重命名。例如,可以根據提取的標題或關鍵信息對文件進行重命名。
5. 導出到Excel表格(可選)
點擊“導出到Excel”按鈕,將提取的內容保存為Excel表格。
注意事項
文件格式與質量:確保處理的PDF文件格式正確,文字清晰、無干擾。
識別區域設置:框選識別區域時要精準,避免包含過多無關內容或遺漏關鍵信息。
文件權限與備份:確保軟件有讀取和寫入文件的權限,處理重要文件前,最好先備份原始文件
)


![[java 常用類API] 新手小白的編程字典](http://pic.xiahunao.cn/[java 常用類API] 新手小白的編程字典)














)
