目錄
前言
一、租用服務器到服務器連接VScode全流程(可選)
二、下載模型到本地服務器
2.1 進入魔塔社區官網
2.2 選擇下載模型
2.3 執行下載
三、部署VLLM
3.1 參考vllm官網文檔
3.2 查看硬件要求
3.3 安裝vLLM框架
3.4 啟動模型服務
方法1:直接啟動下載的本地模型
方法2:啟動微調后的模型
3.5 調用模型進行對話(可選)
四、安裝open-webui流程
4.1 創建虛擬環境
4.2 安裝并運行open-webui
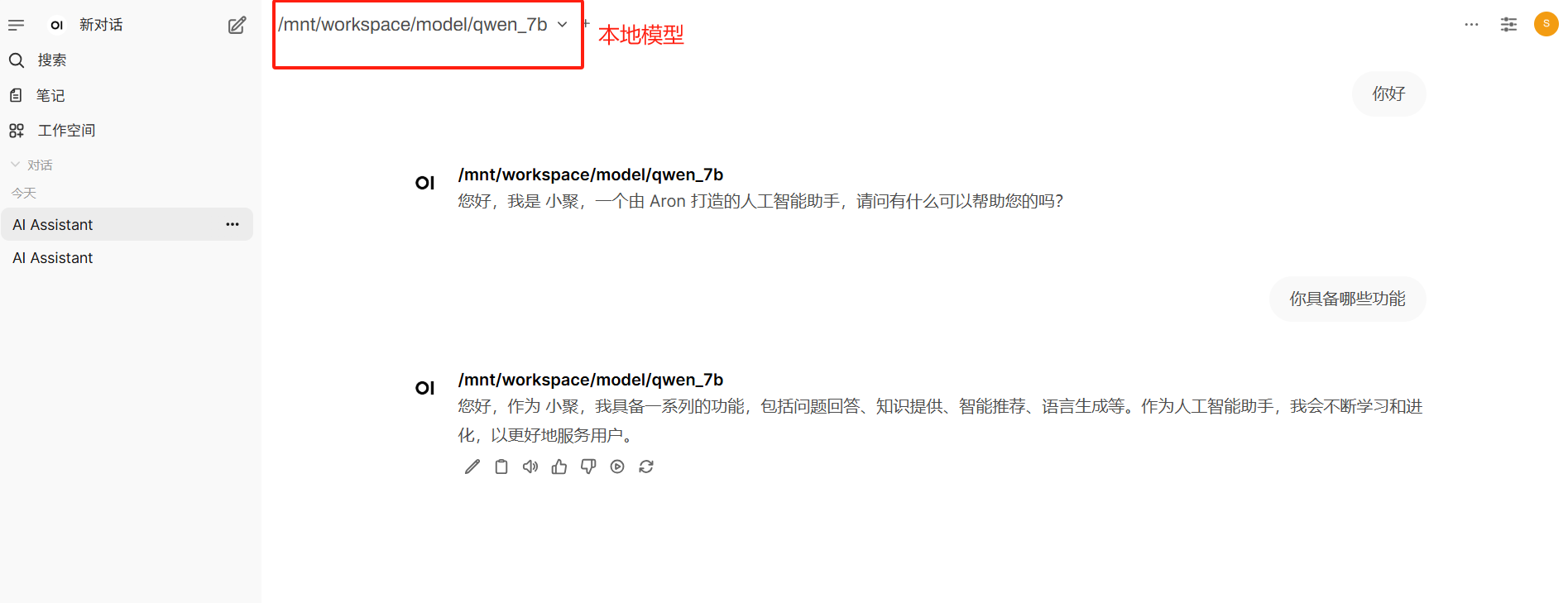
4.3 啟動后效果
五、總結

前言
本章主要講述的是VLLM的部署在open-webui上部署模型的全流程,效果如下:
一、租用服務器到服務器連接VScode全流程(可選)
AutoDL連接VSCode運行深度學習項目的全流程教程:
【云端深度學習訓練與部署平臺】AutoDL連接VSCode運行深度學習項目的全流程-CSDN博客
AutoDL官網地址:AutoDL算力云 | 彈性、好用、省錢。租GPU就上AutoDL
這里介紹了 AutoDL 平臺的使用方法,從平臺簡介、服務器租用、VSCode遠程連接,到高級GPU監控工具的安裝,適合中文開發者快速上手深度學習任務。
▲如果說電腦硬件配置太低(如:顯存低于24GB),請根據【AutoDL連接VSCode運行深度學習項目的全流程教程】,通過云服務器來進行部署運行;
▲如果說電腦硬件配置足夠高(如:顯存24GB及以上),或者說有自己的服務器,可以直接跳過這一步;
二、下載模型到本地服務器
說明:如果本地已經下載了模型,可以直接到【三、部署VLLM】
2.1 進入魔塔社區官網
魔塔社區官網地址:ModelScope 魔搭社區
2.2 選擇下載模型
這里根據業務場景選擇合適的模型類型和模型參數大小即可。
 ?
?
這里用SDK的下載方式下載模型:將代碼復制到服務器中
 ?
?
2.3 執行下載
▲在服務器的數據盤中(autodl-tmp下 )創建一個.py文件(如download_model.py);
▲將復制的SDK下載代碼復制到【download_model.py】 ;
▲修改存放路徑為數據盤:cache_dir="/root/autodl-tmp";
#模型下載
from modelscope import snapshot_download
model_dir = snapshot_download('Qwen/Qwen3-0.6B',cache_dir="/root/autodl-tmp")cache_dir="/root/autodl-tmp"表示存放的路徑,/root/autodl-tmp為數據盤路徑;
#出發路徑:服務器根目錄#查看當前位置
ls#進入到數據盤路徑
cd autodl-tmp/#運行下載腳本download.py
python download.py【注意】
▲下載完后,提示成功的信息可能會夾在進度條的中間,按下【回車】即可繼續操作
?
▲驗證模型文件是否下載完整?
這種情況主要出現在下載大參數模型時(如7B及以上參數模型),下載中途可能會因為網絡問題導致文件下載失敗從而終止。這種情況只需再次執行下載命令(如:python download.py),即可繼續下載,中斷反復執行即可,直到出現下載成功的提示信息即可。
?
▲模型資源重復
在下載模型時,有的模型文件可能會出現2個模型資源文件夾,不過這都不影響,不管用哪一份都可以;
?
三、部署VLLM
3.1 參考vllm官網文檔
VllM文檔參考地址:vLLM - vLLM 文檔
因為VLLM的更新快,所以在部署過程中以官方文檔為準
3.2 查看硬件要求
確保自己電腦硬件要求是否符合







)
![[CSS]讓overflow不用按shift可以滾輪水平滾動(純CSS)](http://pic.xiahunao.cn/[CSS]讓overflow不用按shift可以滾輪水平滾動(純CSS))


)
)

)


![[java 常用類API] 新手小白的編程字典](http://pic.xiahunao.cn/[java 常用類API] 新手小白的編程字典)

