文章目錄
- 參考資料
- 說明
- 大模型微調入門
- 微調簡介
- 微調步驟
- 數據準備
- 模型選擇
- 訓練方式
- 效果評估
- 模型部署
- 大模型微調(基于訊飛星辰Maas)
- 構建數據集
- 方法1:預置數據集
- 方法2:創建數據集
- 數據輔助工具
- 數據集劃分
- 模型微調
- 數據配置
- 參數配置
- 模型部署和評估
- 發布服務
- 在線體驗
- 批量處理
- 模型評估
- 詩詞生成實踐
- 商品分類任務數據集校驗失敗問題解決
參考資料
- 大模型微調基礎入門
- 大模型微調平臺介紹
- 實踐分享
說明
- 本文僅供學習和交流使用,版權歸原作者所有,請勿進行商業用途!
- 由于文本創作期間,模型未運行完成,文中部分圖片借用官方圖片,實際頁面布局可能存在差異,請理解。
大模型微調入門
微調簡介
- 大語言模型(LLM)是一種專注于處理語言數據的人工智能模型,通過分析和學習海量文本數據來掌握語言的語法、語義和上下文關系,從而實現自然語言的理解與生成。
- 在面對特定任務時,可能還需要進一步的調整和優化。這就是俗稱的大模型微調。
- 大模型微調(Fine-Tuning)是在一個已經訓練好的模型基礎上,針對特定任務進行進一步訓練,使其在該任務上表現更好。
微調步驟
- 微調模型通常需要經過幾個步驟,每個步驟都非常重要,直接影響到最終模型的表現。
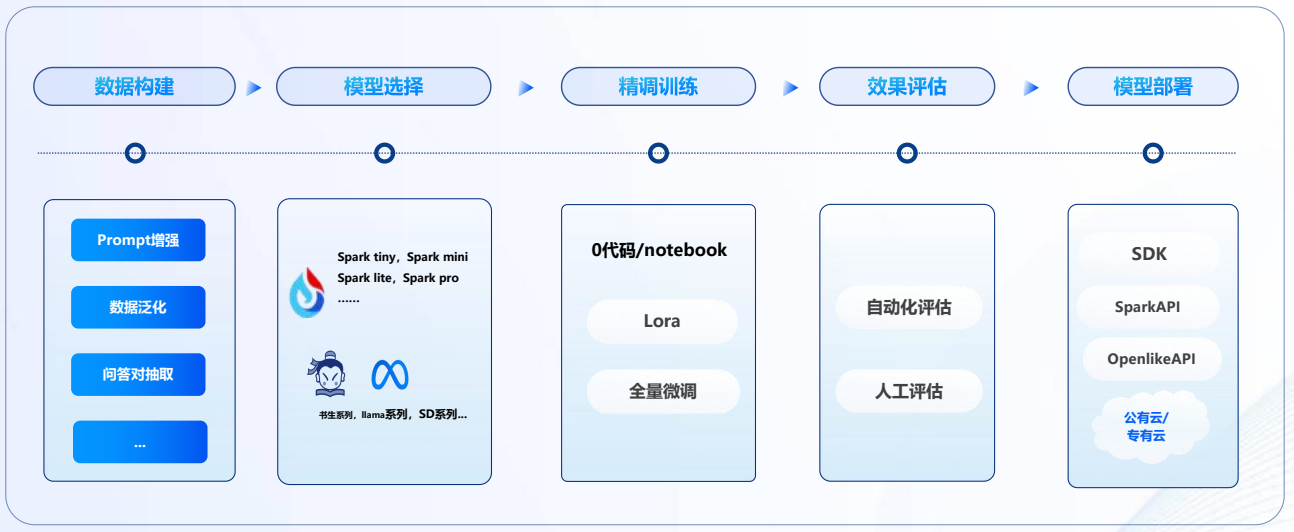
數據準備
- 數據準備:收集和整理與特定任務相關的數據集。數據集應該盡可能地多樣化和全面,以便模型能夠學習到各種不同的情況和模式。
- 數據構建常見的問題:只有文本數據,沒有問答對數據、數據量不足、數據質量較低、數據集優化不足、數據積累困難。
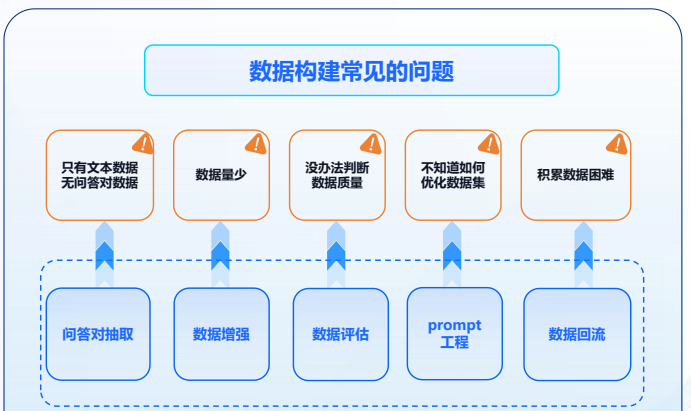
- 星辰MaaS針對不同場景提供多種數據構建功能,基于人機協作的工具可以大幅提升高質量數據集構建的效率。
模型選擇
- 在數據準備好之后,需要選擇一個合適的預訓練模型進行微調。不同的任務可能需要不同的模型,需要根據具體情況來選擇。例如:訊飛星辰MaaS平臺以星火優質大模型為核心,擴展支持主流開源大模型,提供更多選擇。
訓練方式
- LoRA(Low-Rank Adaptation、低秩適配、部分參數微調):每次只會對模型新增的少量數據即可進行更新,旨在減少計算資源和存儲需求,同時保持較高的性能,還減少過擬合的風險,所需數據和訓練時長相對全量微調少很多。
- FFT(Full Fine-Tuning、全參數微調、全量微調):充分利用基礎模型的表示能力,通過調整所有參數使其更好地適應特定任務,在全量微調過程中,所有模型參數都會被優化,這意味著模型的每一層都會根據特定任務的數據進行調整。
效果評估
- 訓練完成后,需要對模型進行評估,以確定模型在特定任務上的表現,以此來判斷是否需要持續迭代。
模型部署
- 星辰MaaS平臺對微調后的模型可以按需發布為API/SDK服務,提供標準開放、即用即銷模式,賦能創新。可以接入已有產品使用,可以開發創新產品,也可以在訊飛開放平臺開放。
- 開源模型支持下載滿足本地運行需求。
大模型微調(基于訊飛星辰Maas)
- 訊飛星辰MaaS微調平臺:平臺以星火認知大模型和優質開源大模型為基礎,重點發力數據工程,數據構建質量形成競爭優勢,圍繞數據管理,模型微調、評估、托管,推理服務完善大模型全生命周期管理,覆蓋內容創作、代碼、邏輯推理等多場景,無需復雜調整或重新訓練,甚至零代碼也可以完成微調!
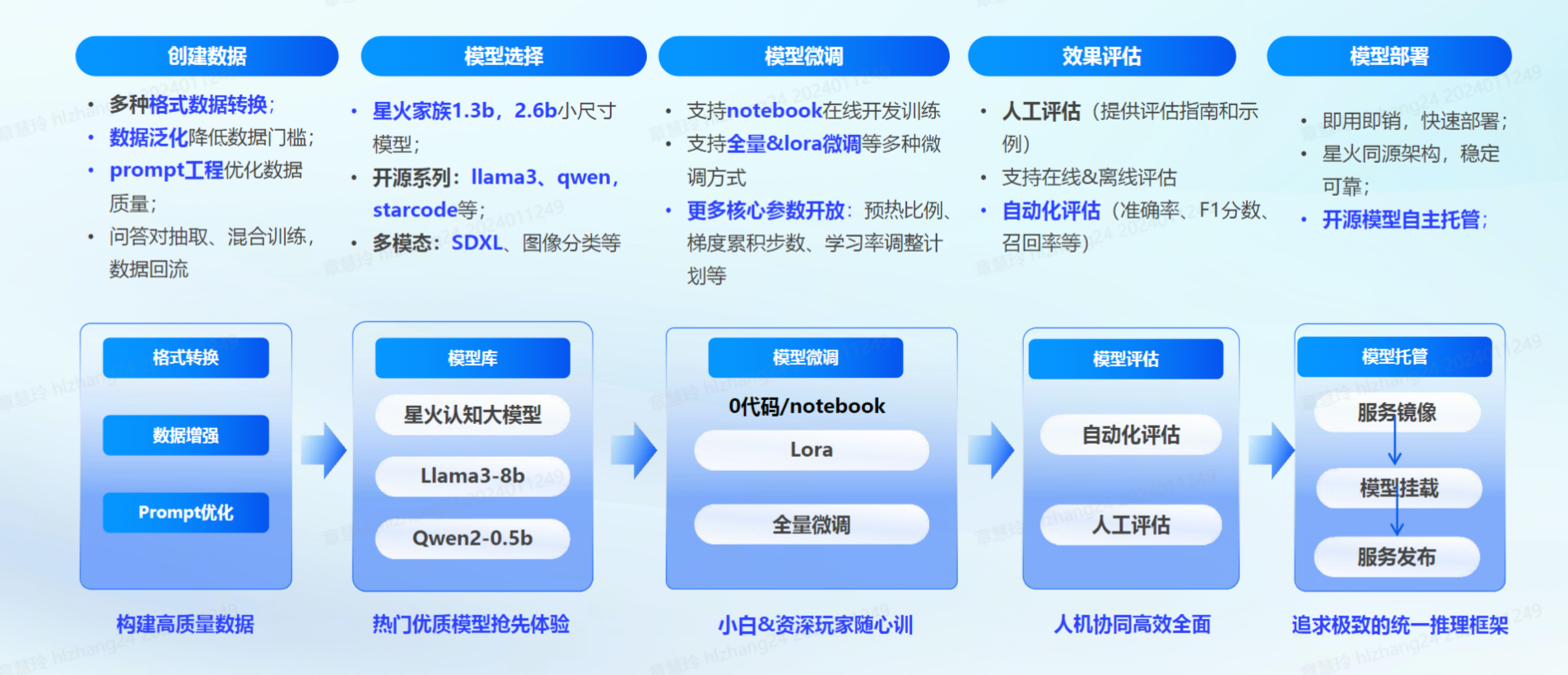
構建數據集
- 在進行微調訓練前需要明確目標任務和數據需求,并準備好相關訓練數據,星辰MaaS微調平臺提供豐富的 【預置數據集】可供用戶直接用于訓練,也可以選擇【創建數據集】,平臺提供【問答對抽取】、【數據增強】、【prompt工程】 三種輔助工具來優化數據,進一步提高數據質量。
數據集的獲取有兩種主要途徑:
-
依據特定業務需求自行定義數據集 確保數據與業務場景緊密貼合,從而提升模型在實際應用中的表現。
-
利用公開數據集 公開數據集豐富多樣且涵蓋廣泛的領域,能夠滿足許多常見任務的基礎數據需求。
-
平臺為提供預制數據集(數據集管理-預置數據集),可直接用于模型訓練;同時配備問答對抽取功能,我們只需導入文本文件或網站鏈接,系統便能自動切分問答對,快速生成訓練所需的數據。
方法1:預置數據集
- 平臺提供的預置數據集包括多個行業領域,可以選擇相應領域的數據集進行模型微調,但「預置數據集」本身不支持用戶更改轉化。例如,可以直接選擇平臺預置數據集里的“sentiment_predict”開源數據用于訓練情感分類。
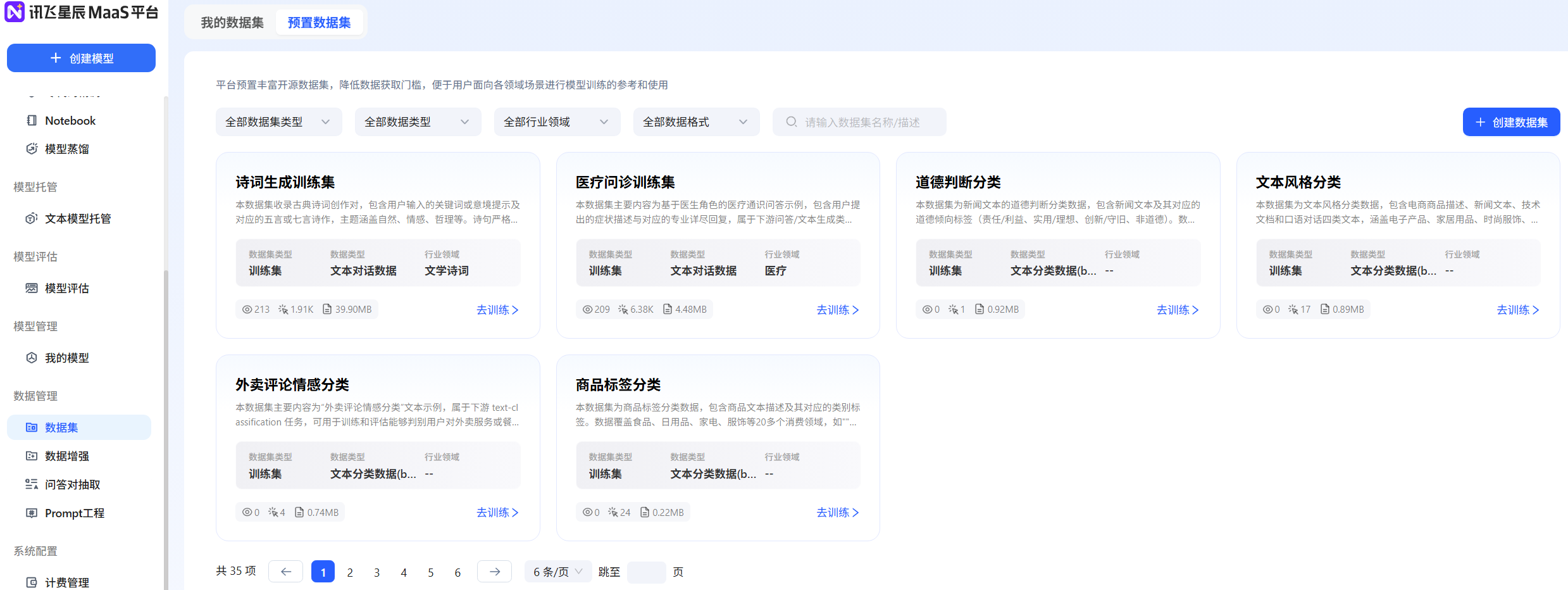
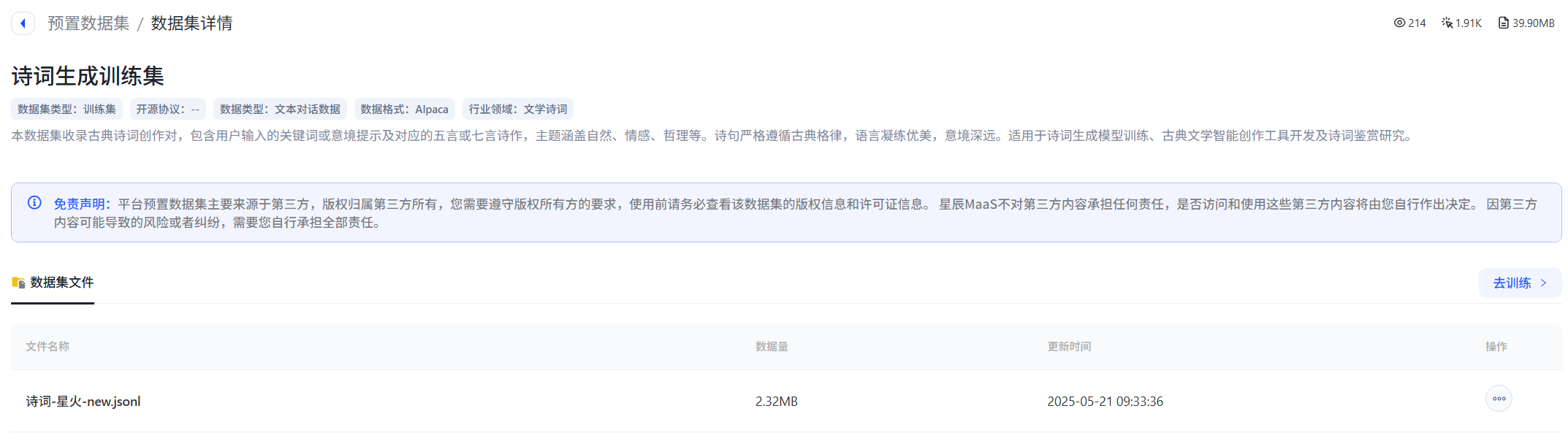
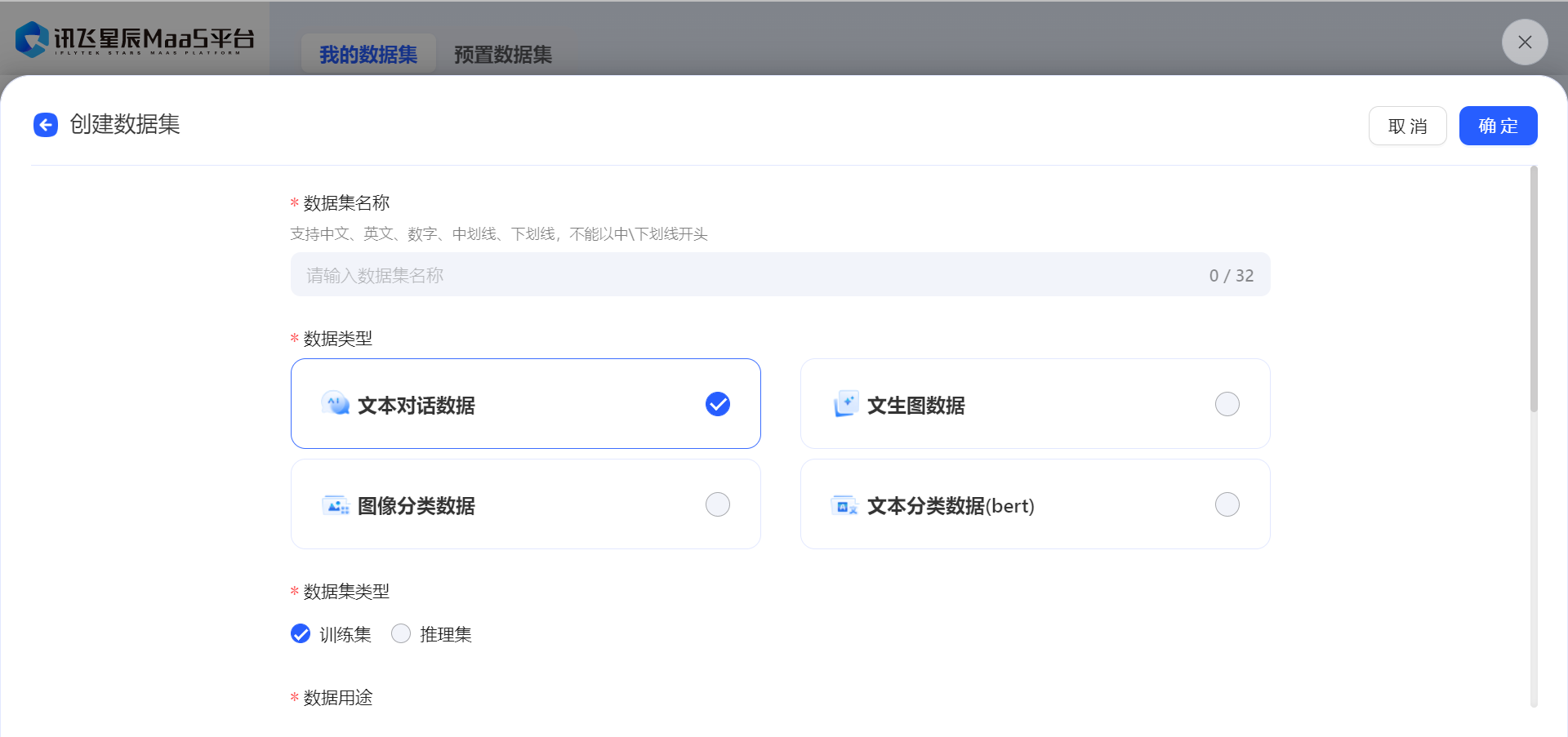
方法2:創建數據集
- 也可以通過創建數據集來上傳自己的訓練數據,目前僅支持導入json、jsonl、csv格式的單個文件,具體可參照模型微調數據集格式 (opens new window)說明。
數據輔助工具
- 問答對抽取:只有文本數據,無問答對數據,【問答對抽取】功能,選擇導入txt等格式文本文件或網站鏈接,平臺能夠自動切分問答對,也支持自定義切分分隔符,自動抽取問答對數據。
- 【問答對抽取】得到問答對數據集滿足大模型微調數據集所需格式,正確率可達90%,覆蓋率不低于75%,可以下載生成的數據集用于微調。
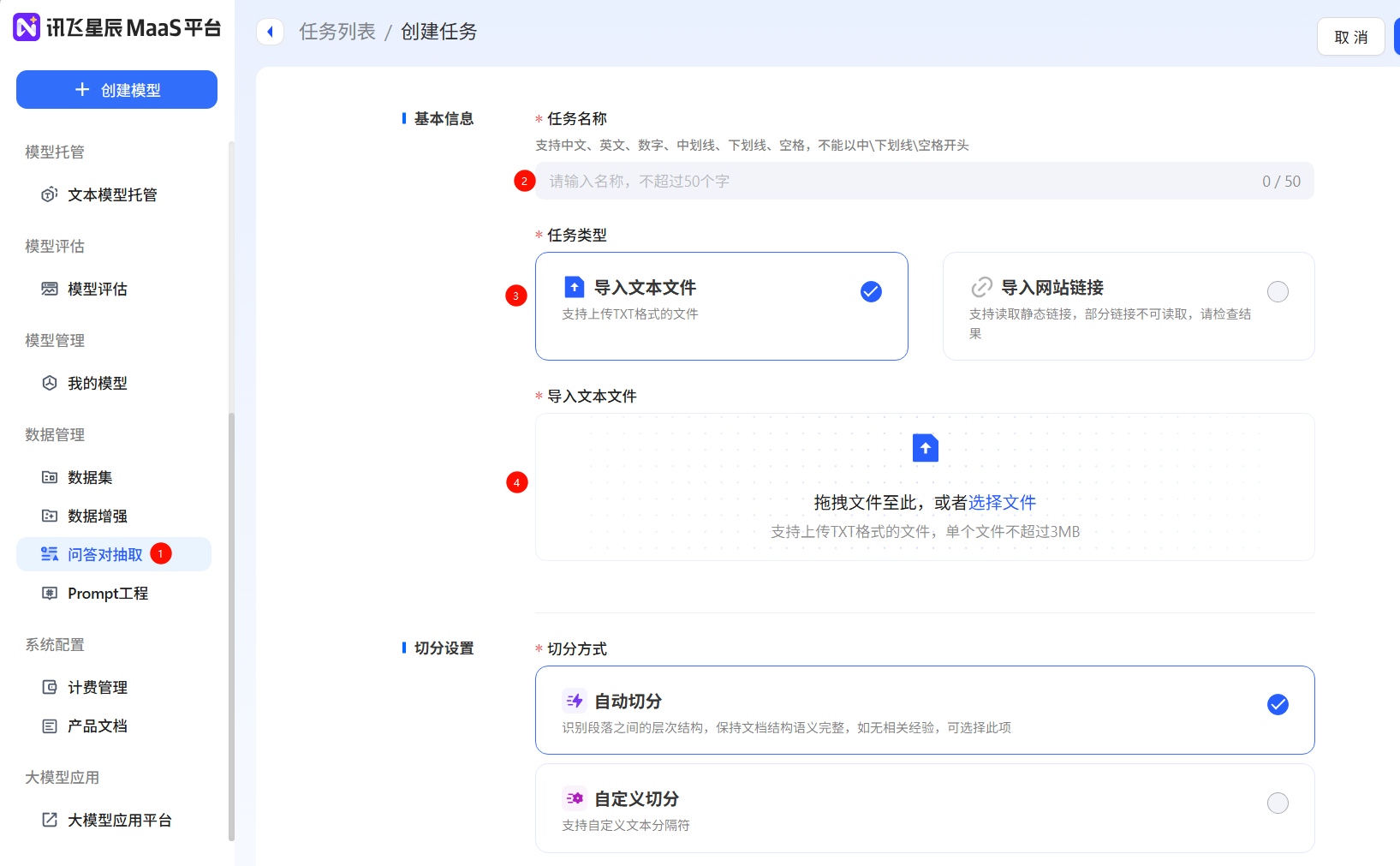
- 數據增強:如果原本的數據量過少可以對常見文本生成、理解、知識問答數據泛化,擴展數據集數量。在【數據增強】板塊,可以通過【創建任務】實現批量增強,支持選擇增強倍數和質量等方式,也可以通過【在線增強】和【在線優化】來查看單條數據增強的效果。
- prompt工程:平臺支持基于prompt工程的數據集構建優化,提供50+常見prompt模板,滿足多種類型數據需求。
- 根據訓練集數據格式要求調整數據集對應成instruction、input、output里的內容,經過處理,最終形成的一條完整數據格式應該如下所示:
{"instruction": "你是一個情感分析助手,目標是辨別推文的情感傾向,情感傾向分為積極和消極。接下來,我會給你推文的內容,請你告訴我情感分析的答案",
"input": "一百多和三十的也看不出什么區別,包裝精美,質量應該不錯",
"output": "積極"}
數據集劃分
- SFT(Supervised Fine-Tuning,監督微調)是大模型訓練流程中的關鍵環節,指在預訓練模型基礎上,通過有標簽的特定任務數據調整模型參數,使其快速適配下游應用需求的技術。其核心思想是基于遷移學習,利用預訓練階段習得的通用知識(如語言理解、特征提取能力),在少量標注數據上優化模型,實現任務定制化。
- 在進行SFT(Supervised Fine-Tuning,監督微調)時,為了確保模型評估的公正性,通常需要將數據集劃分為訓練集、驗證集和測試集,常見的劃分比例為 70% 訓練集、15% 驗證集、15% 測試集。
- 訓練集:用于訓練模型的主要數據集。
- 驗證集:在微調過程中用于調優超參數和選擇最優模型。
- 測試集:用于最終評估模型性能,確保微調后的模型在未見數據上的表現。
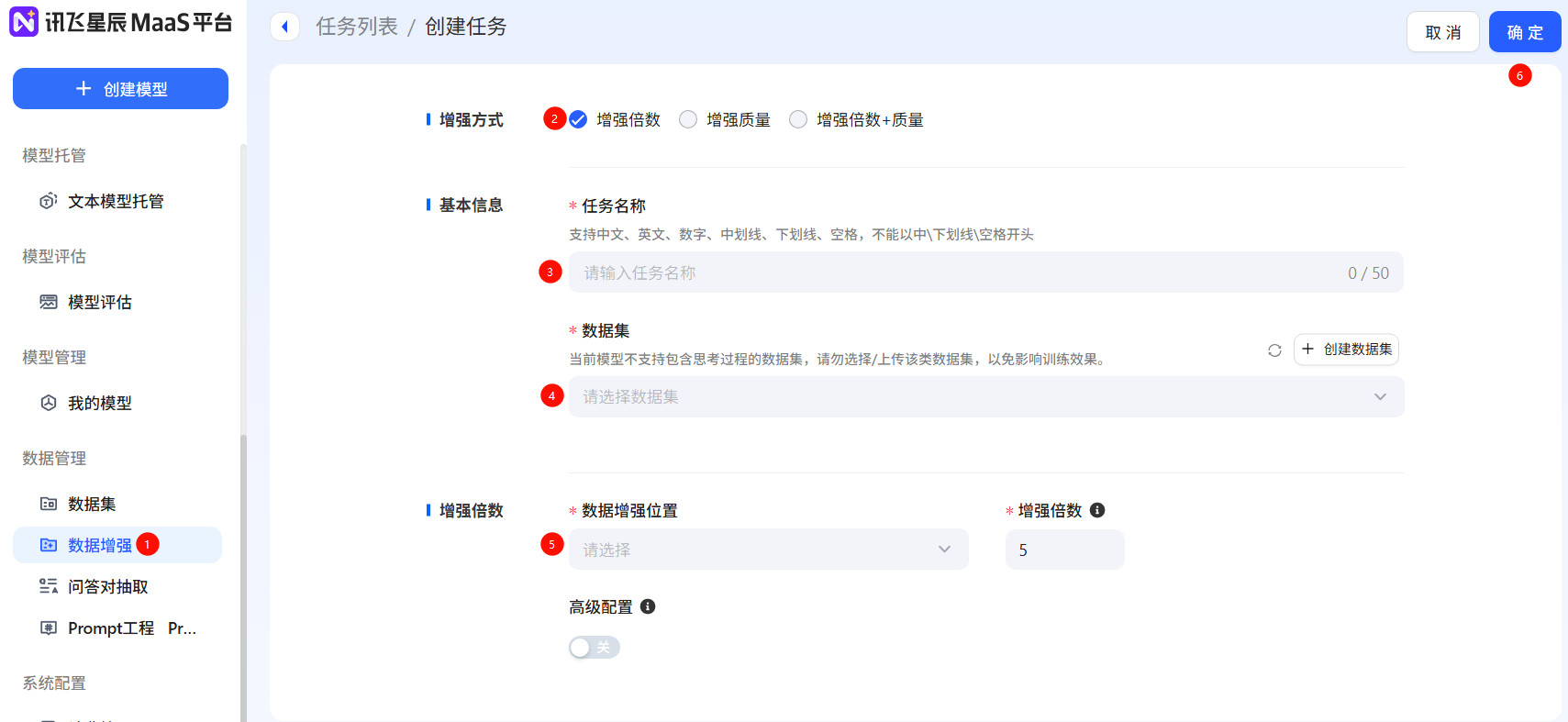
模型微調
-
在進行基礎數據的獲取和優化后,可以選擇基礎模型、上傳訓練集進行模型微調訓練。
-
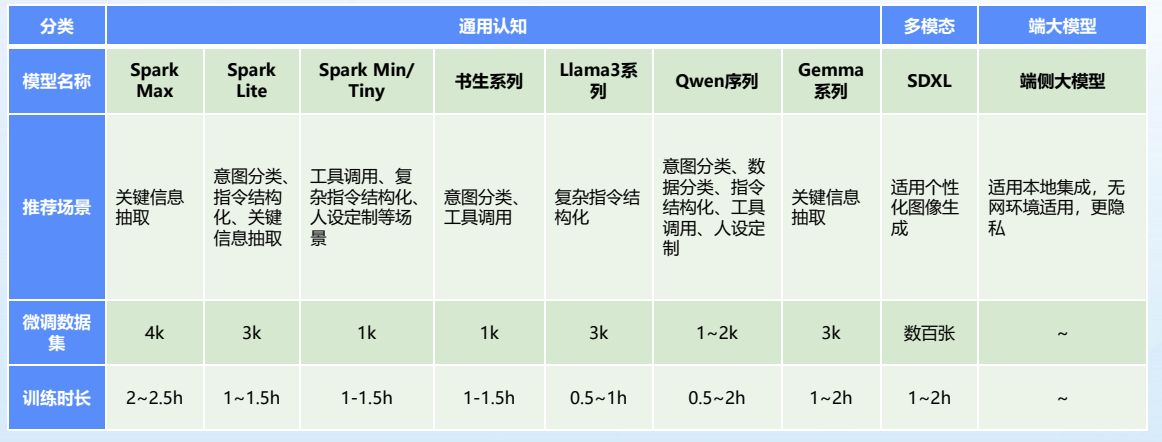
根據任務的復雜程度和場景需求,評估平臺上提供的各種模型的尺寸和特性,選擇最匹配的模型來完成任務。首先,需要明確任務類型,例如是文本生成、對話、圖像分類、邏輯推理等;其次,選擇模型尺寸。
- 輕量級模型:適合簡單的文本生成、對話等任務,如 Spark Mini、Spark Mini Instruct,這些模型資源消耗少,訓練速度快,適用于日常的內容創作和對話系統。
- 中等復雜任務:如知識問答、情感分析等,選擇 Spark Lite、Spark Lite Patch,它們在性能與資源需求之間提供了良好的平衡,適合一般的應用場景。
- 相對復雜任務:對于要求高度精準和復雜任務(如工業自動化中的指令處理或智能家居控制),選擇 Spark Max 等更大尺寸的模型,以滿足高計算需求和精確度要求。
-
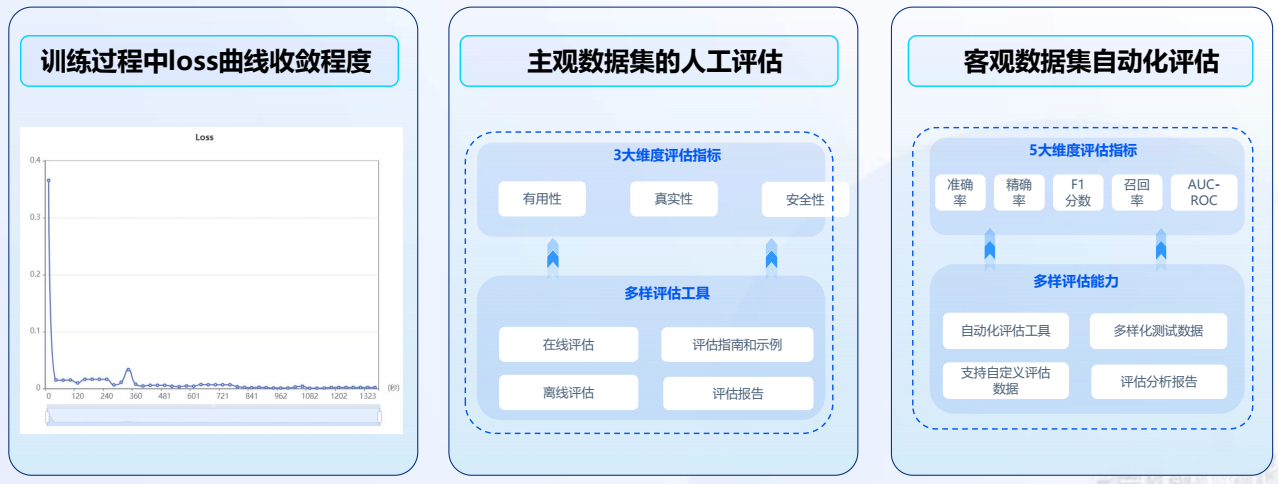
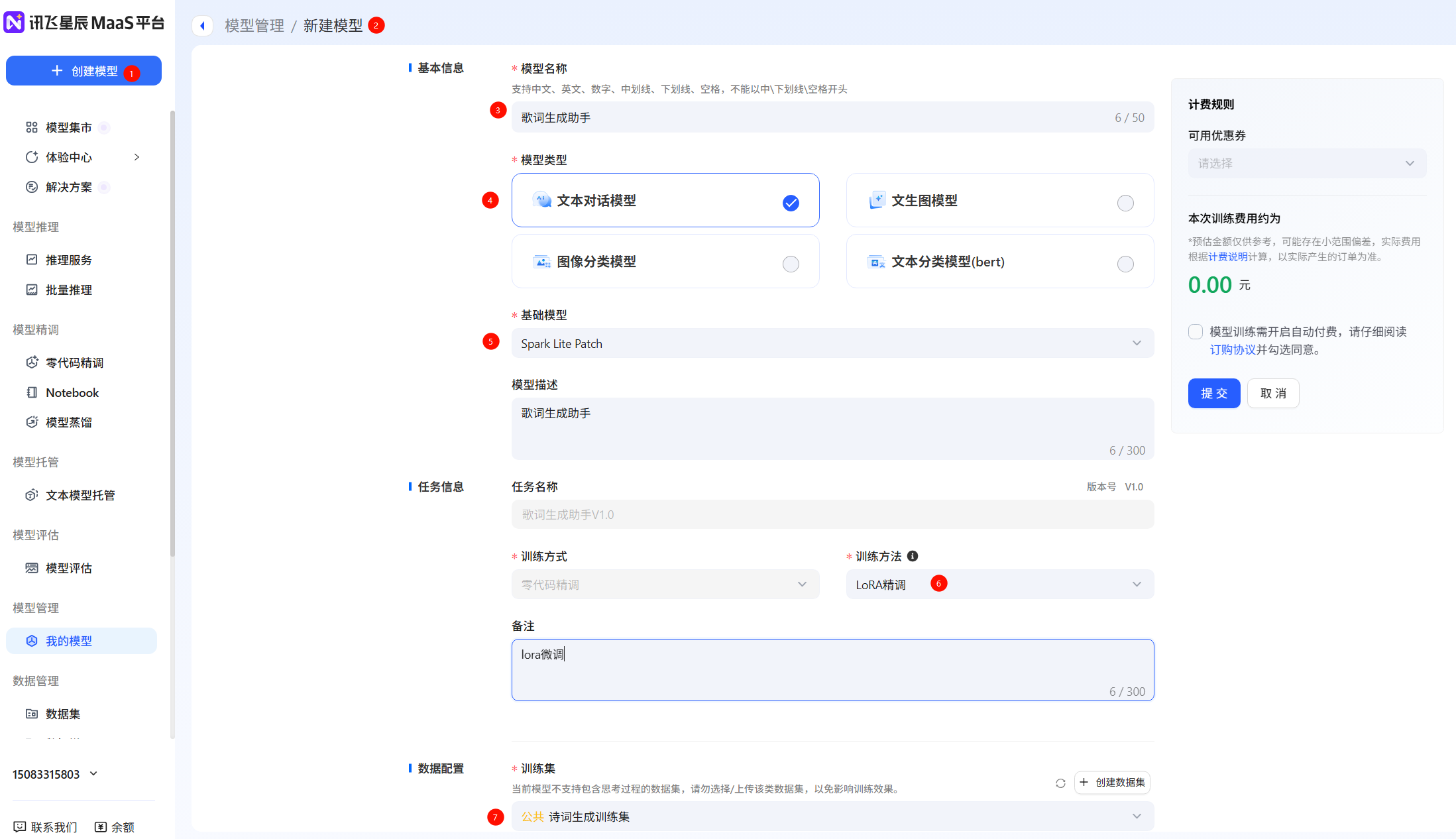
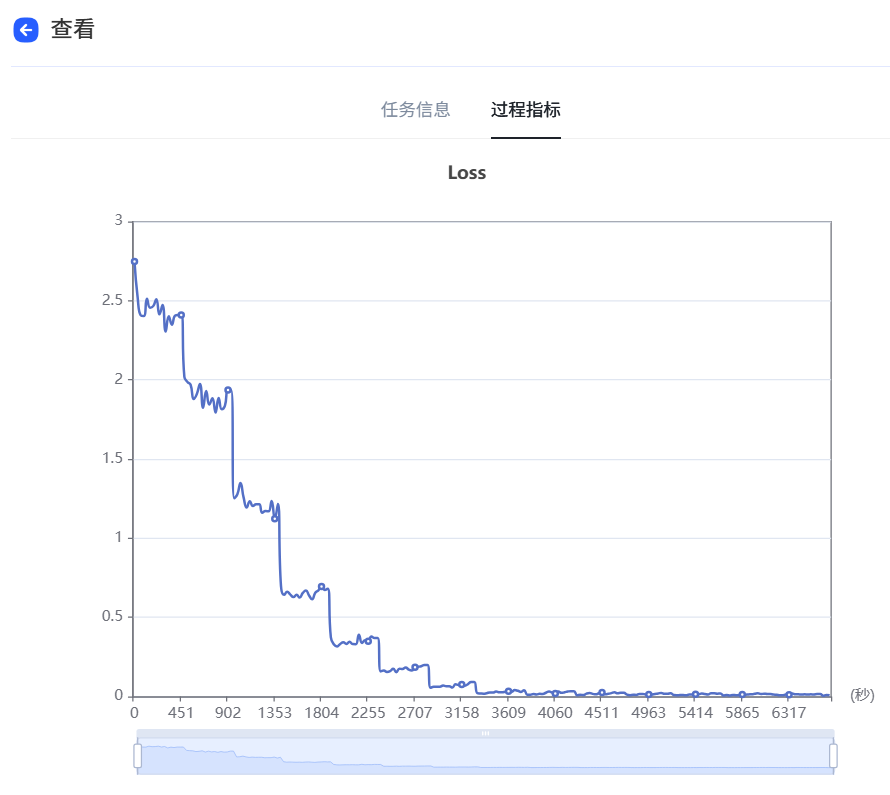
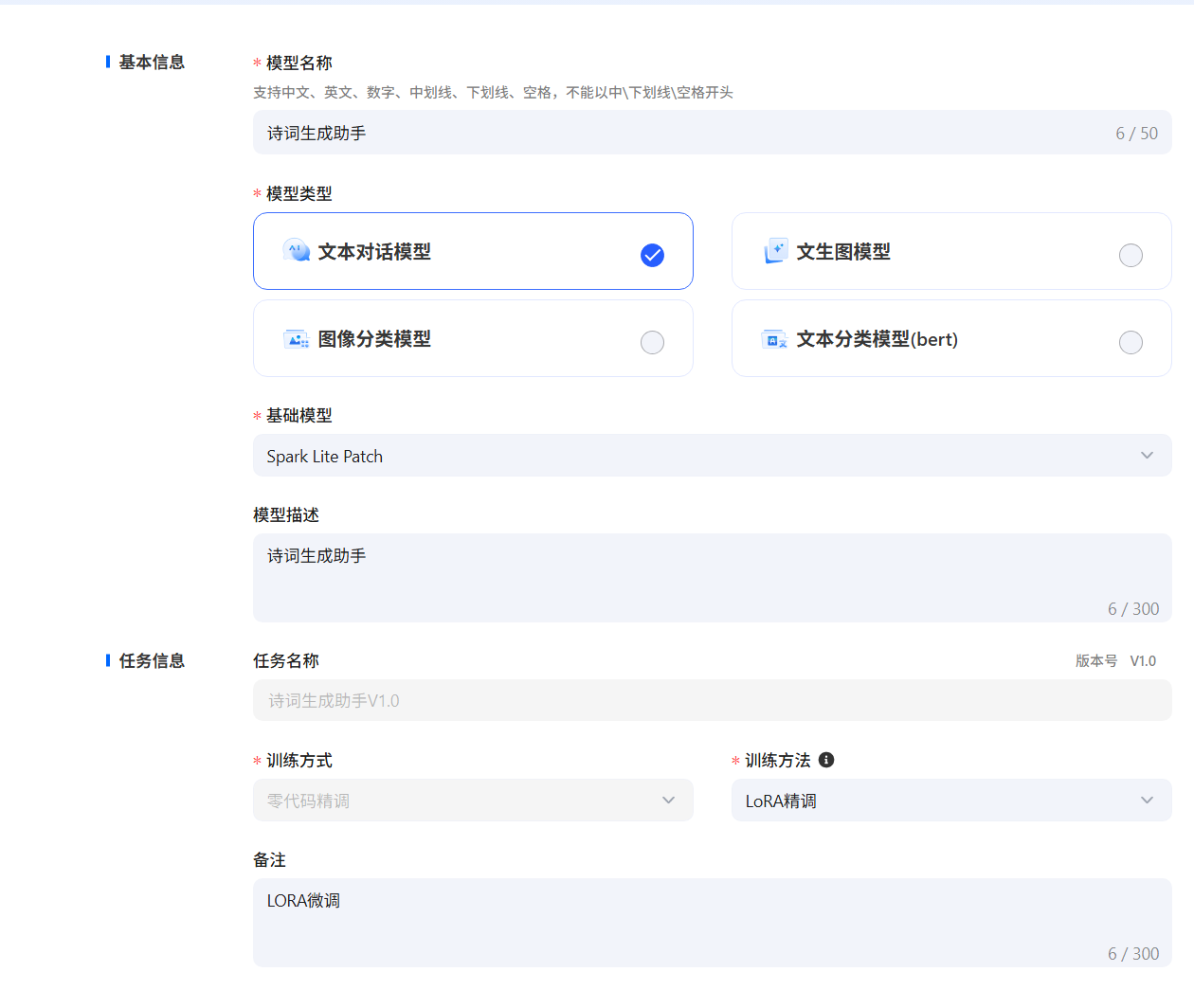
例如,選擇“Spark Lite Patch”模型,填寫模型名稱等信息。訓練參數可以按照默認,也支持用戶自由調節,點擊提交,當任務狀態變為運行成功后,即微調任務完成,支持查看loss曲線過程指標等微調信息,loss曲線越收斂微調效果越好,隨時評估模型效果。
-
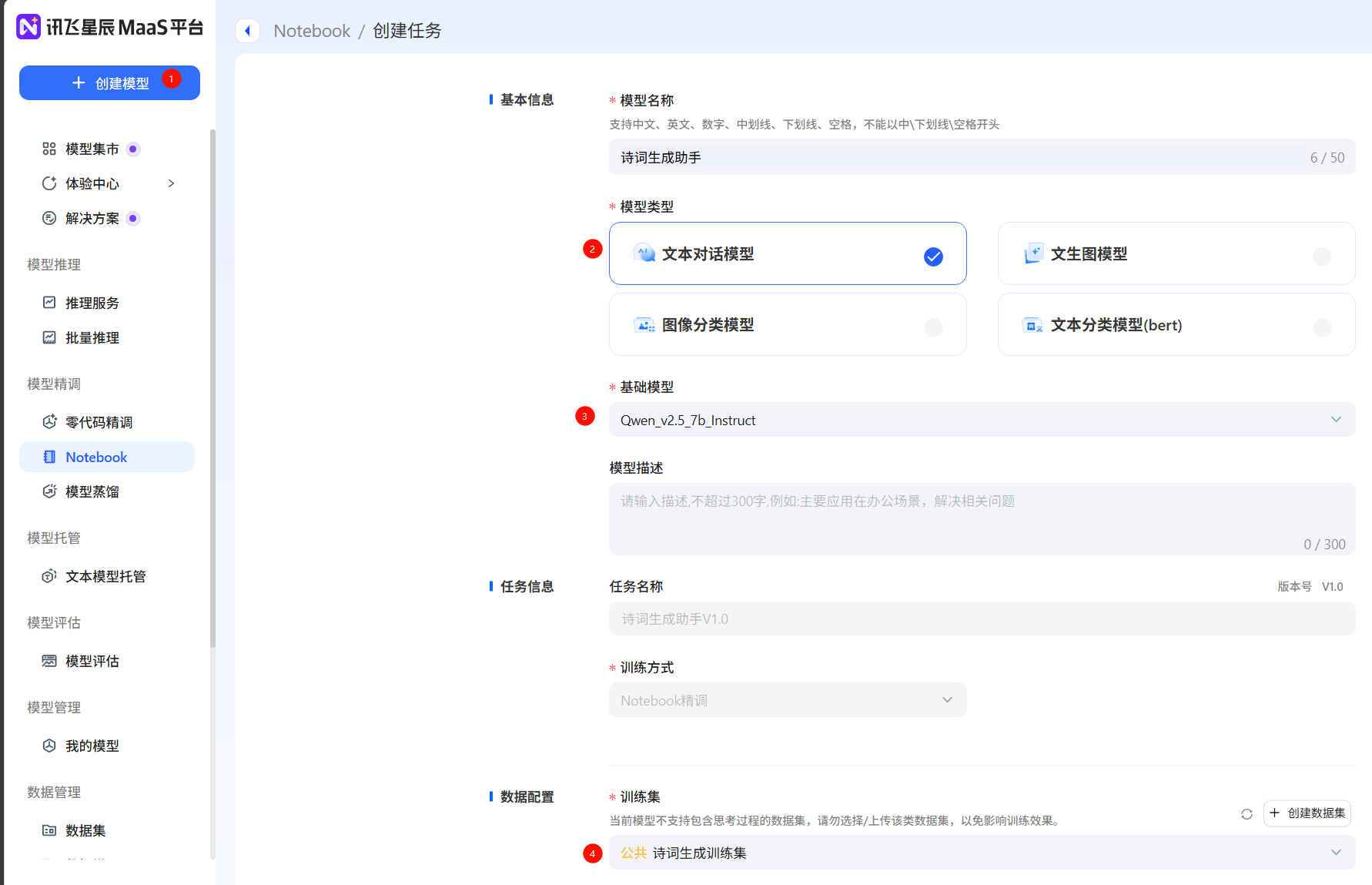
創建模型,填寫模型信息(這里只支持零代碼微調),如果希望使用notebook實時查看loss曲線,需要在Notebook中創建任務,訓練方式為Notebook微調
-
點擊運行,等待運行,查看微調配置。

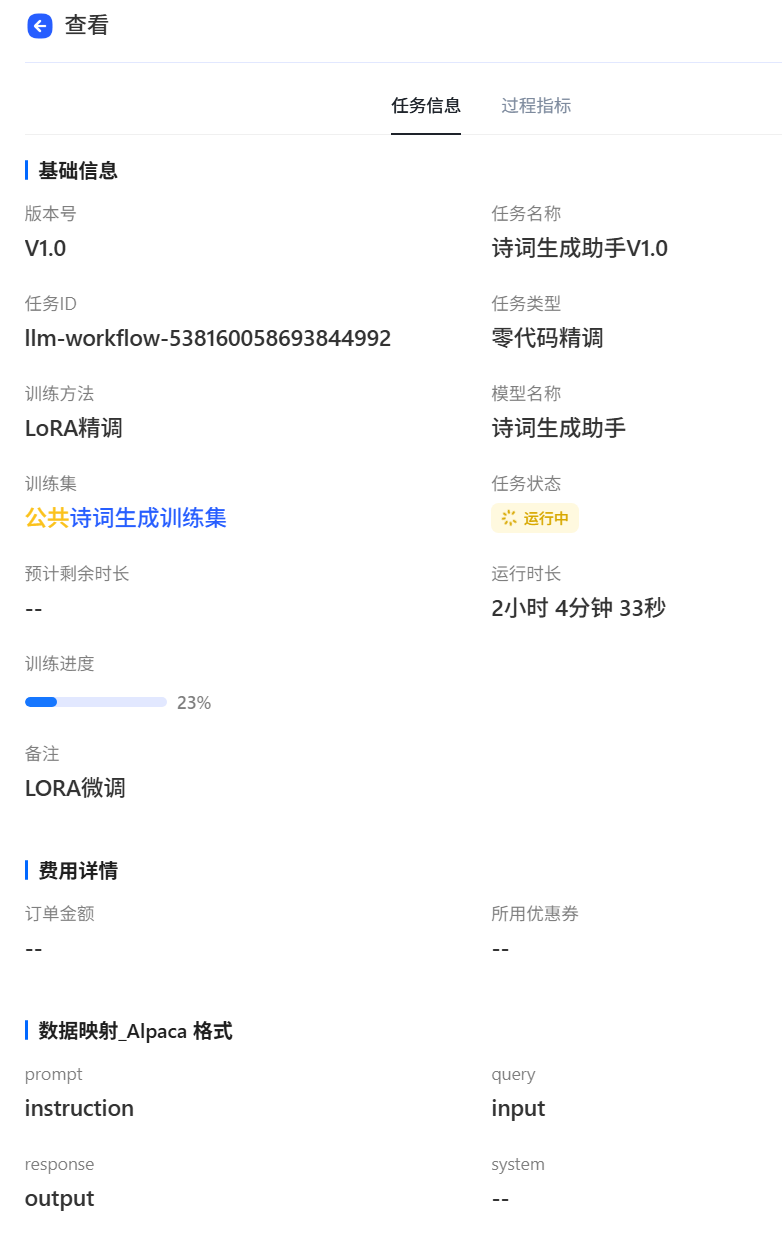
-
loss曲線
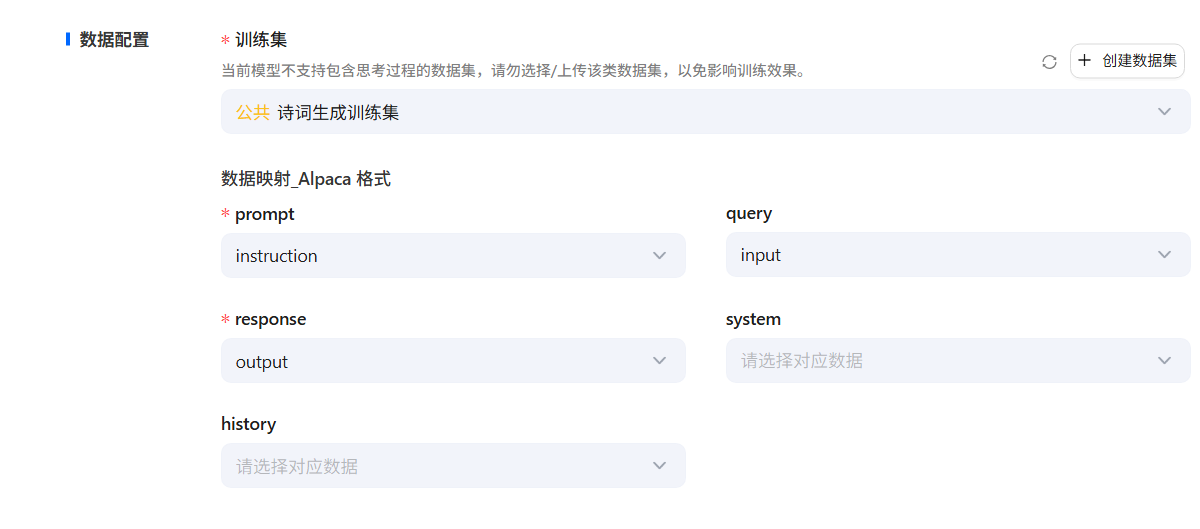
數據配置
- 在創建模型頁面選擇訓練集,進一步進行數據配置工作,明確各個數據字段之間的對應關系。
在平臺中,Alpaca格式的訓練由以下5個字段組成:
- instruction:將與
input內容拼接,形成模型的輸入指令。最終的模型輸入指令格式為instruction\input。 - output:包含模型的期望輸出,是訓練過程中模型要生成的回答。
- system:如果勾選相關選項,此列的內容將作為系統提示詞提供給模型,以便在任務中引入額外的上下文信息。
- history :包含多個字符串二元組,代表對話歷史中的指令與回答,有助于模型理解上下文,提升對話生成的準確性。
- 根據此前構建的商品分類數據集格式,數據映射關系如下:
prompt -> instruction text -> input label -> output
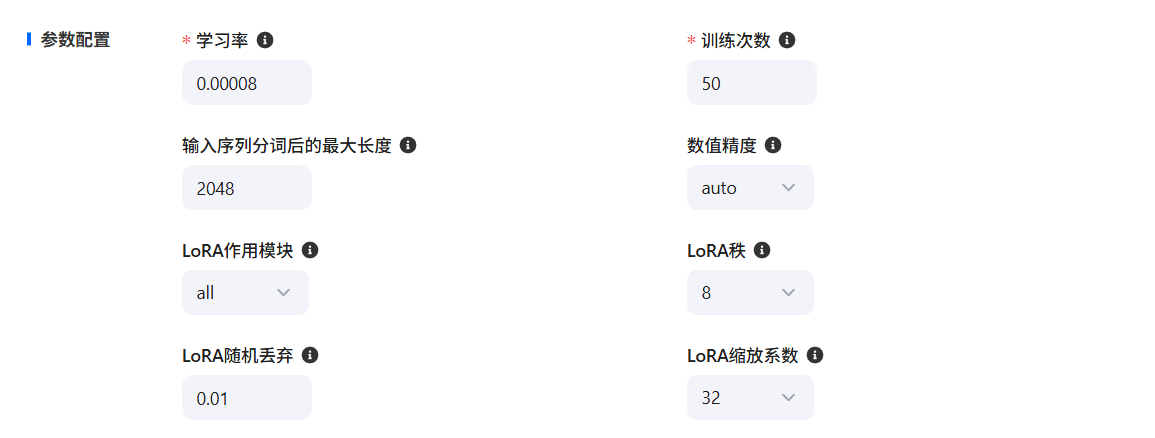
參數配置
- 在參數配置板塊,可以通過調整參數,控制模型訓練效果。常見參數包括:學習率、訓練次數、分詞最大長度、數值精度、LoRA秩、LoRA隨機丟棄、LoRA縮放系數。
- 學習率:學習率是模型訓練過程中調整權重的步長大小。
- 訓練次數:訓練次數指的是模型在整個訓練數據集上進行迭代訓練的次數。
- 分詞最大長度:規定了輸入序列在進行分詞處理后允許的最大長度。
- 數值精度:數值精度通常涉及到模型計算中所使用的數據類型(如 float32、float16 等)。
- LoRA秩:決定了微調過程中引入的低秩矩陣的復雜度。
- LoRA隨機丟棄:這個參數通常用于防止過擬合。
- LoRA縮放系數:定義LoRA適應的學習率縮放因子。
| 參數名稱 | 參數大小影響 |
|---|---|
| 學習率 | 較小的學習率意味著模型在訓練時權重更新較為緩慢,可以使模型更穩定地收斂,但可能需要更多的訓練迭代次數。 |
| 訓練次數 | 每次迭代都會更新模型的權重,訓練次數越多,模型越有可能充分學習數據中的模式,但也可能導致過擬合。 |
| 輸入序列分詞后的最大長度 | 如果輸入序列超過這個長度,可能需要進行截斷或其他處理。 |
| 數值精度 | “auto” 可能表示系統會自動選擇合適的數值精度。 |
| lora 作用模塊 | 選擇模型的全部或特定模塊層進行微調優化。 |
| LoRA 秩 | 較小的秩可以減少參數數量,降低過擬合風險,但可能不足以捕捉任務所需的所有特征;較大的秩可能增強模型的表示能力,但會增加計算和存儲負擔。 |
| Lora 隨機丟棄 | Lora 隨機丟棄以一定概率隨機丟棄神經元的輸出,這里 0.01 表示 1% 的概率。 |
| LoRA 縮放系數 | 參數過高,可能會導致模型的微調過度,失去原始模型的能力;改參數過低,可能達不到預期的微調效果。 |
模型部署和評估
發布服務
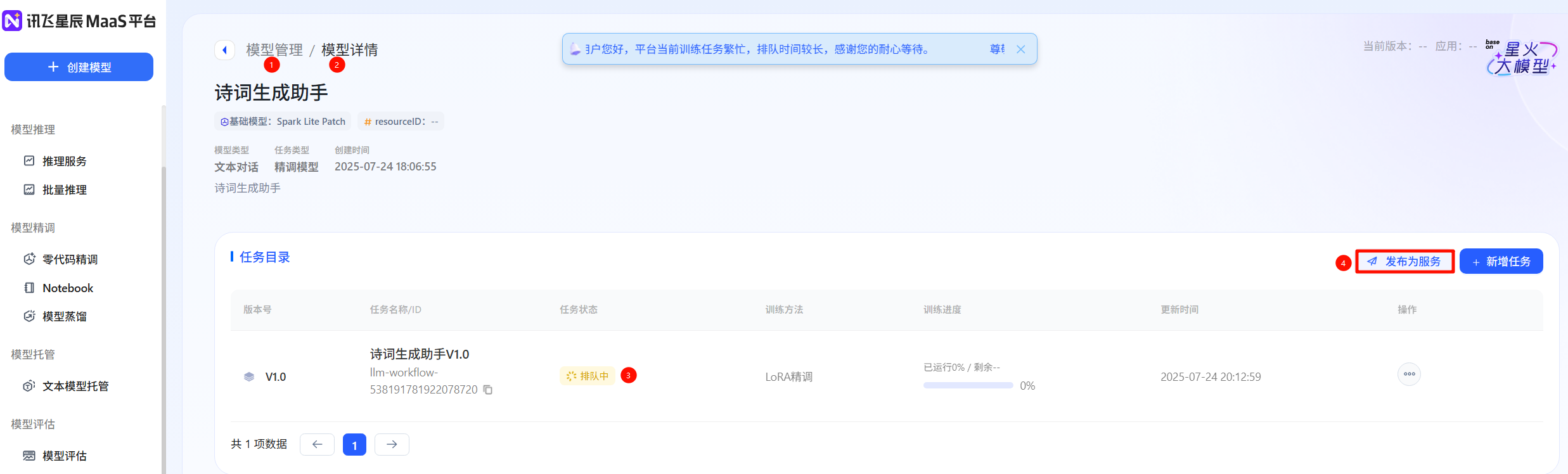
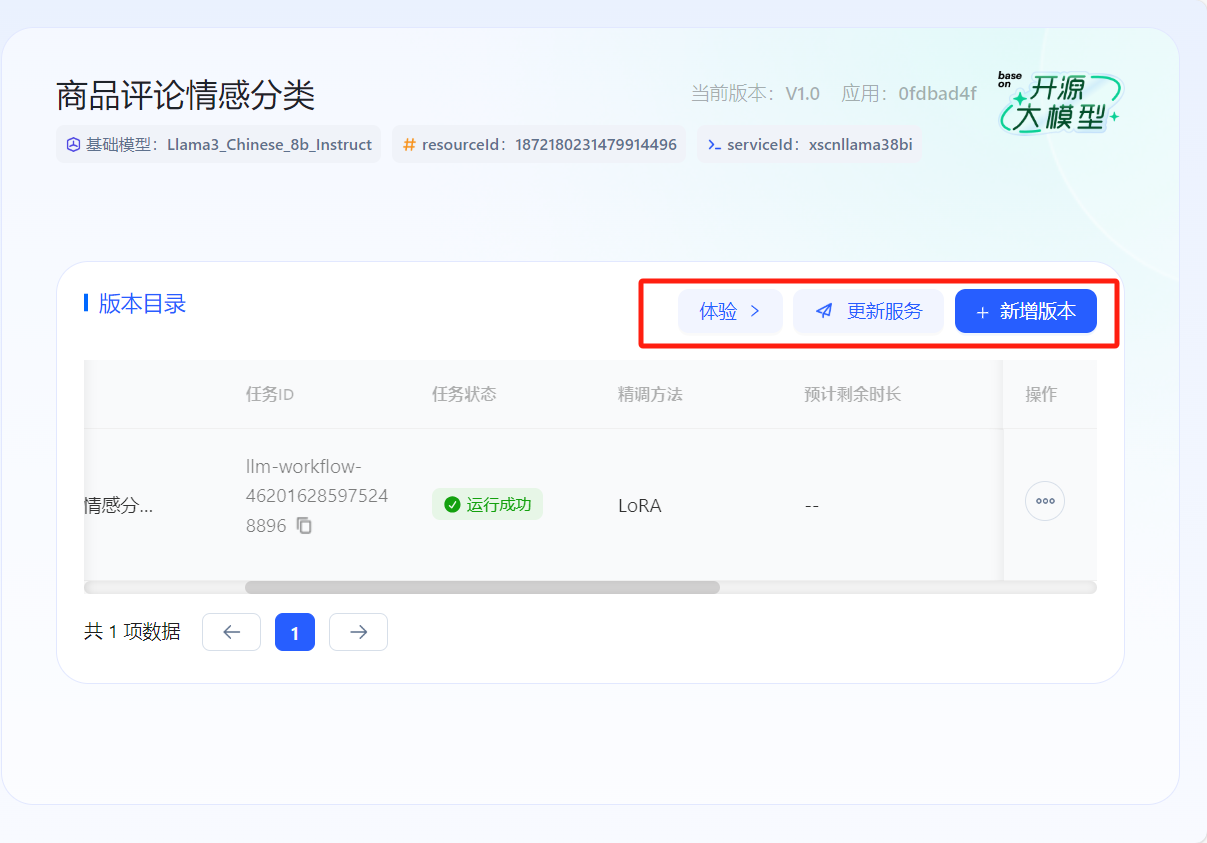
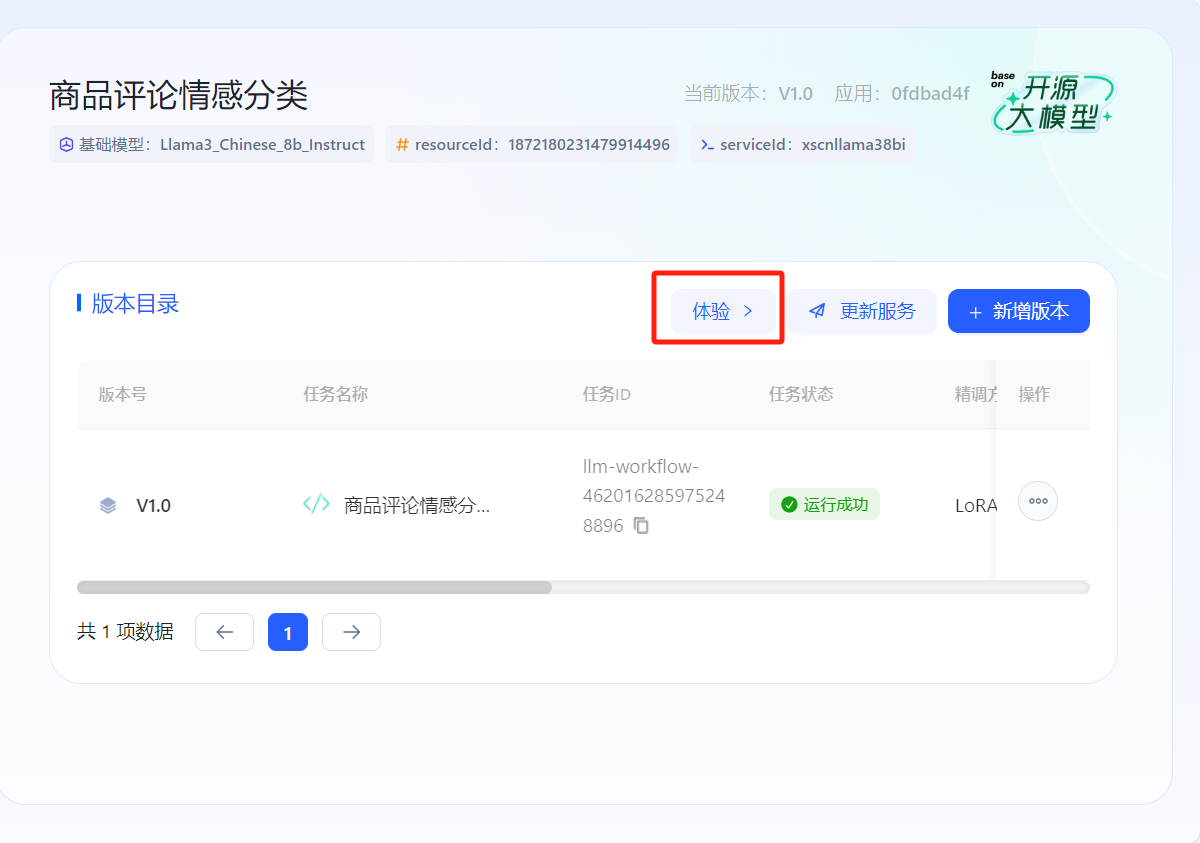
- 首先在開放平臺-控制臺中創建應用,在模型管理中選擇相應任務點擊【發布為服務】,將其授權至所創建的應用完成發布。發布成功后可以點擊【體驗】,獲得在線體驗,也可以點擊【新增版本】繼續微調模型獲得性能更佳的模型。
- 注意:微調后的需要再次【更新服務】選擇最新版本才可體驗最新效果。
- 點擊創建應用
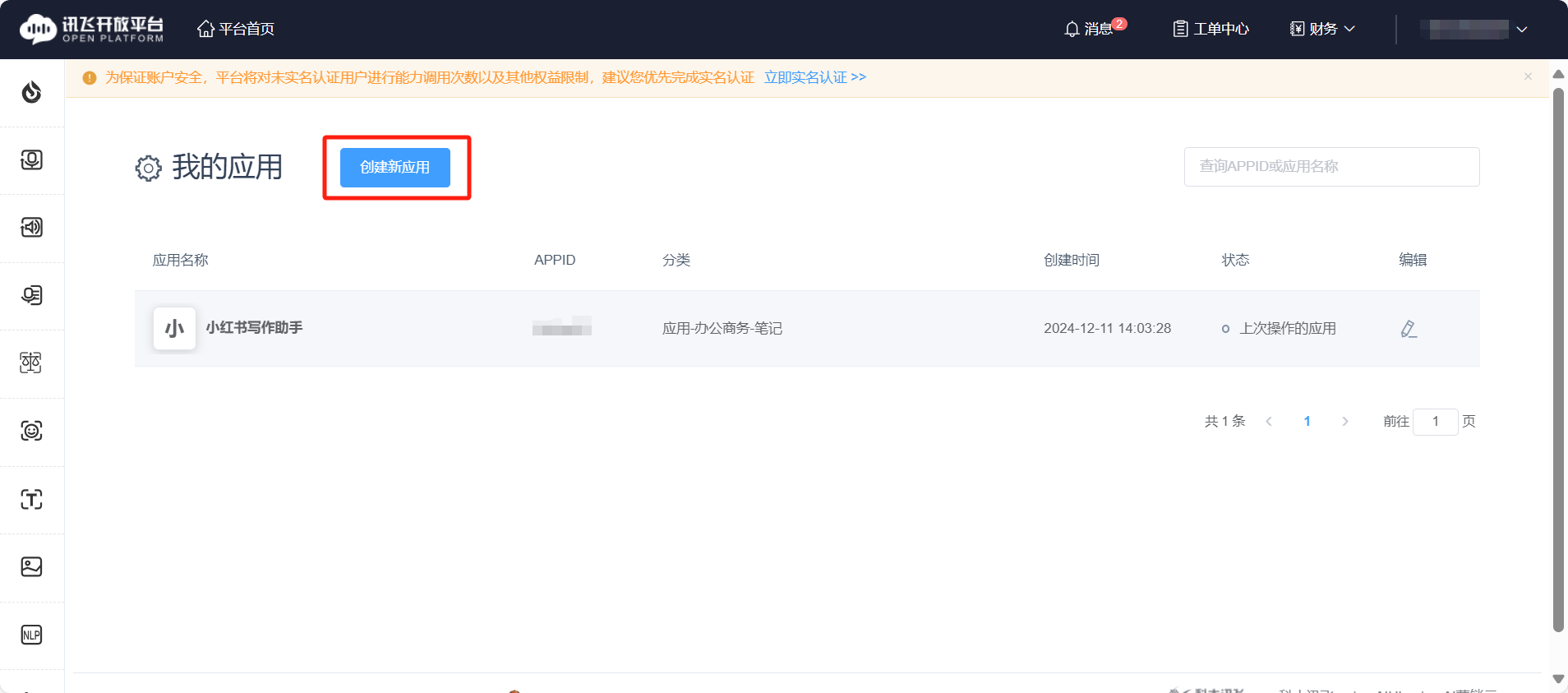
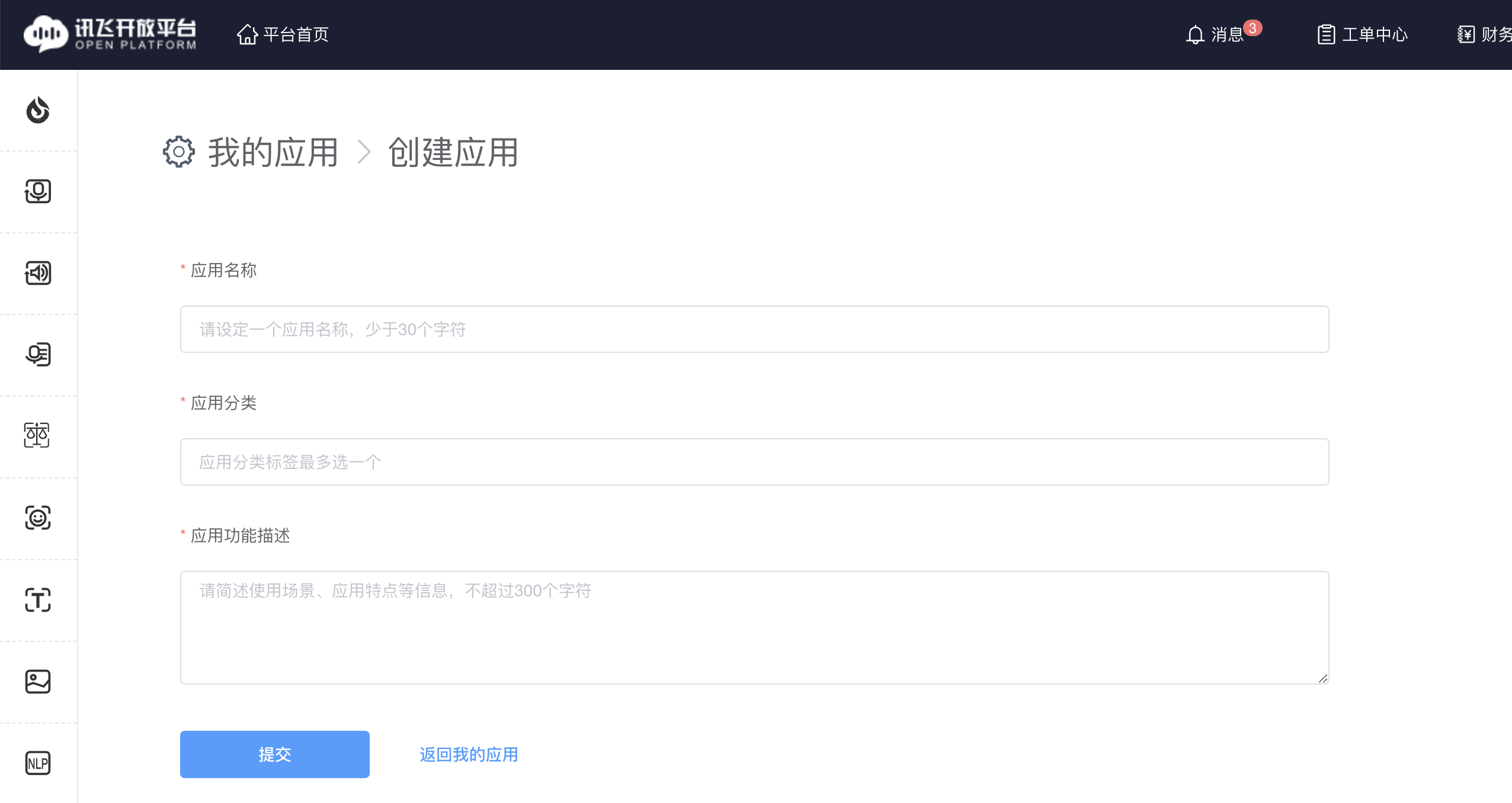
- 填寫信息
- 等待模型運行成功,發布服務
- 體驗或繼續優化
在線體驗
- 在【體驗中心】頁面的【我的服務】,可以看到已經微調出一個商品情感分類模型。
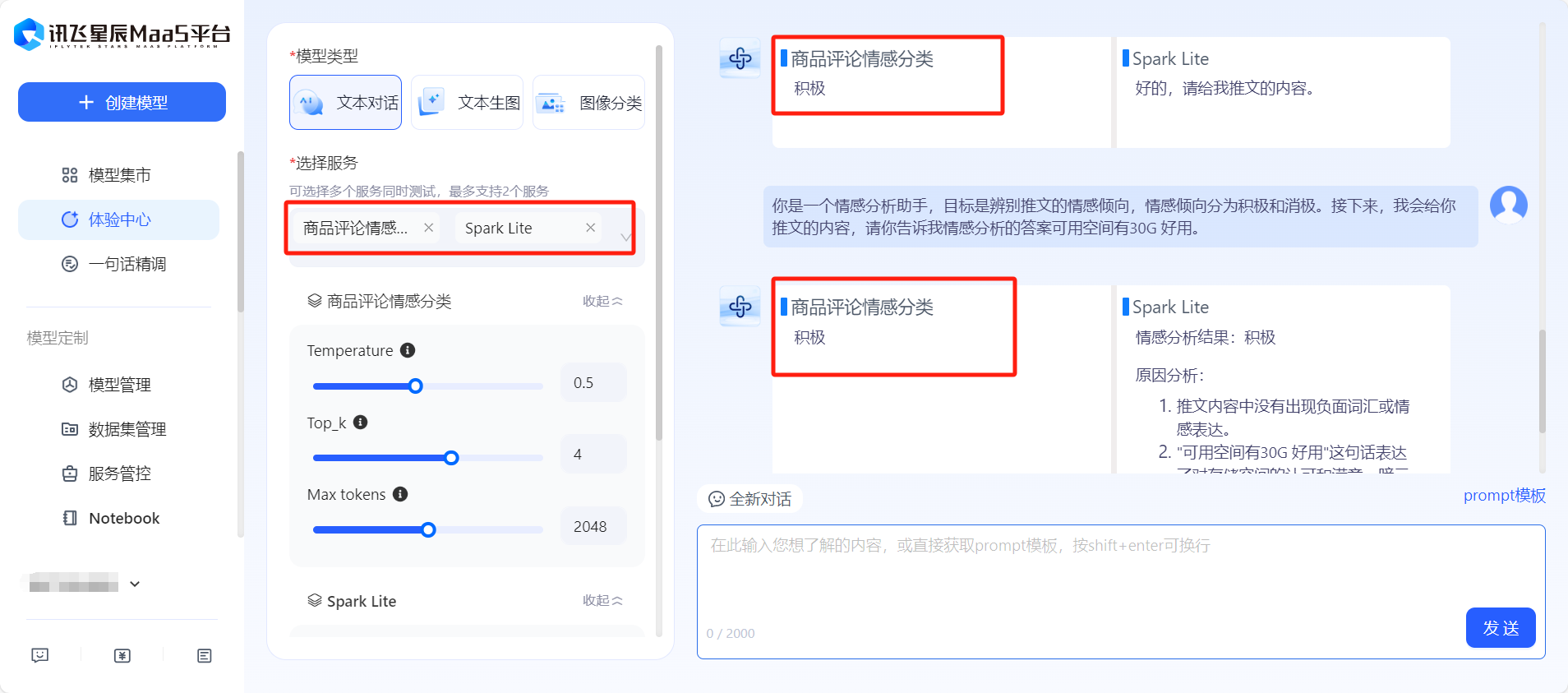
批量處理
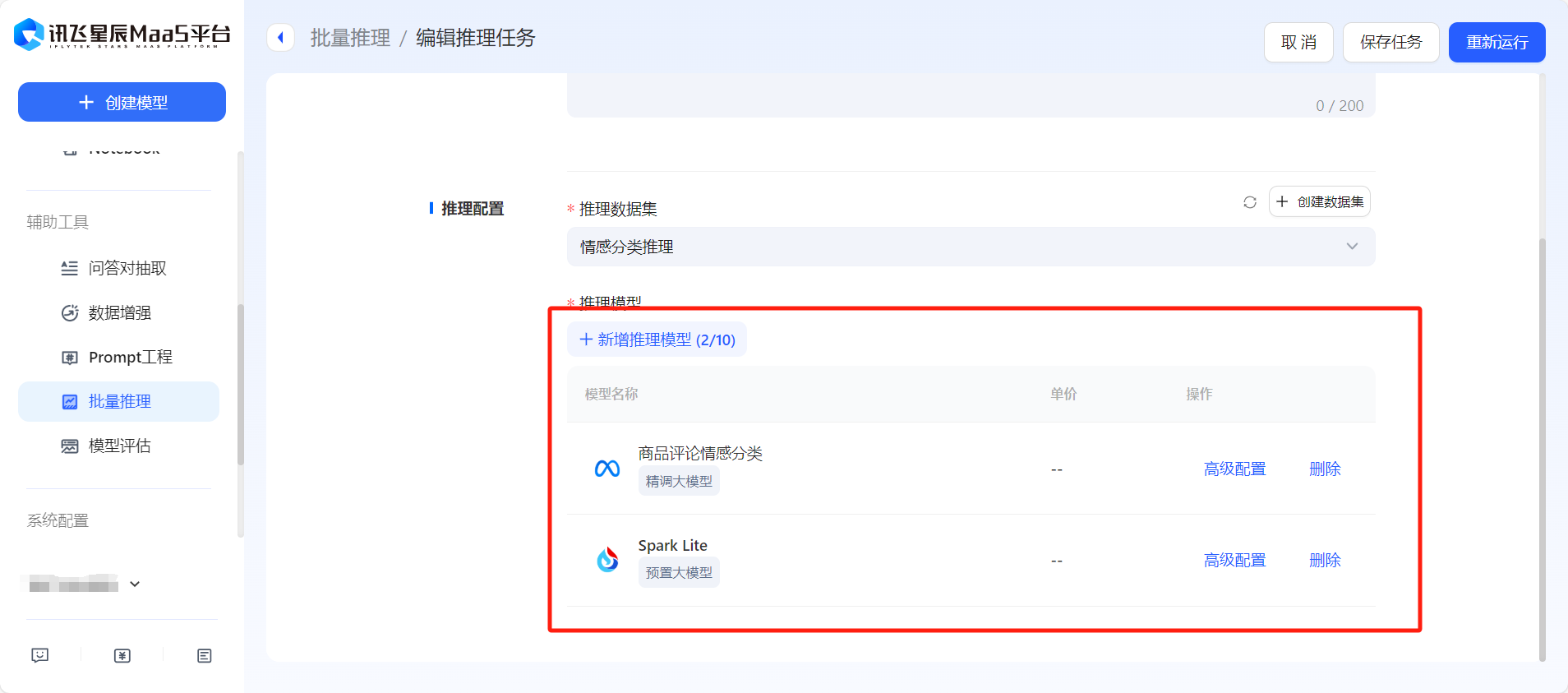
- 在【批量推理】板塊,創建或發起模型批量推理,選擇推理數據集,可支持多個模型同時推理。
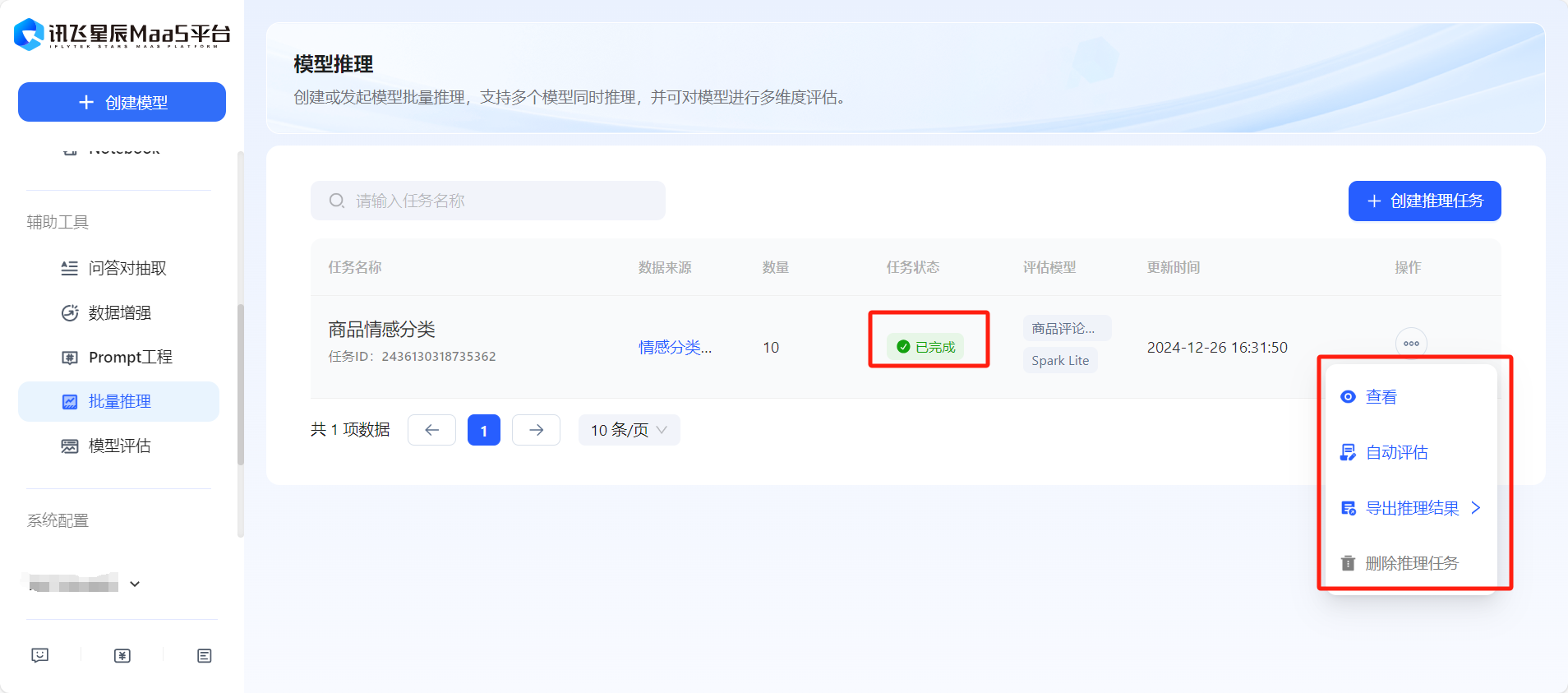
- 在任務狀態變為已完成后,可以選擇查看評估報告或導出評估結果已得到微調前后效果對比。
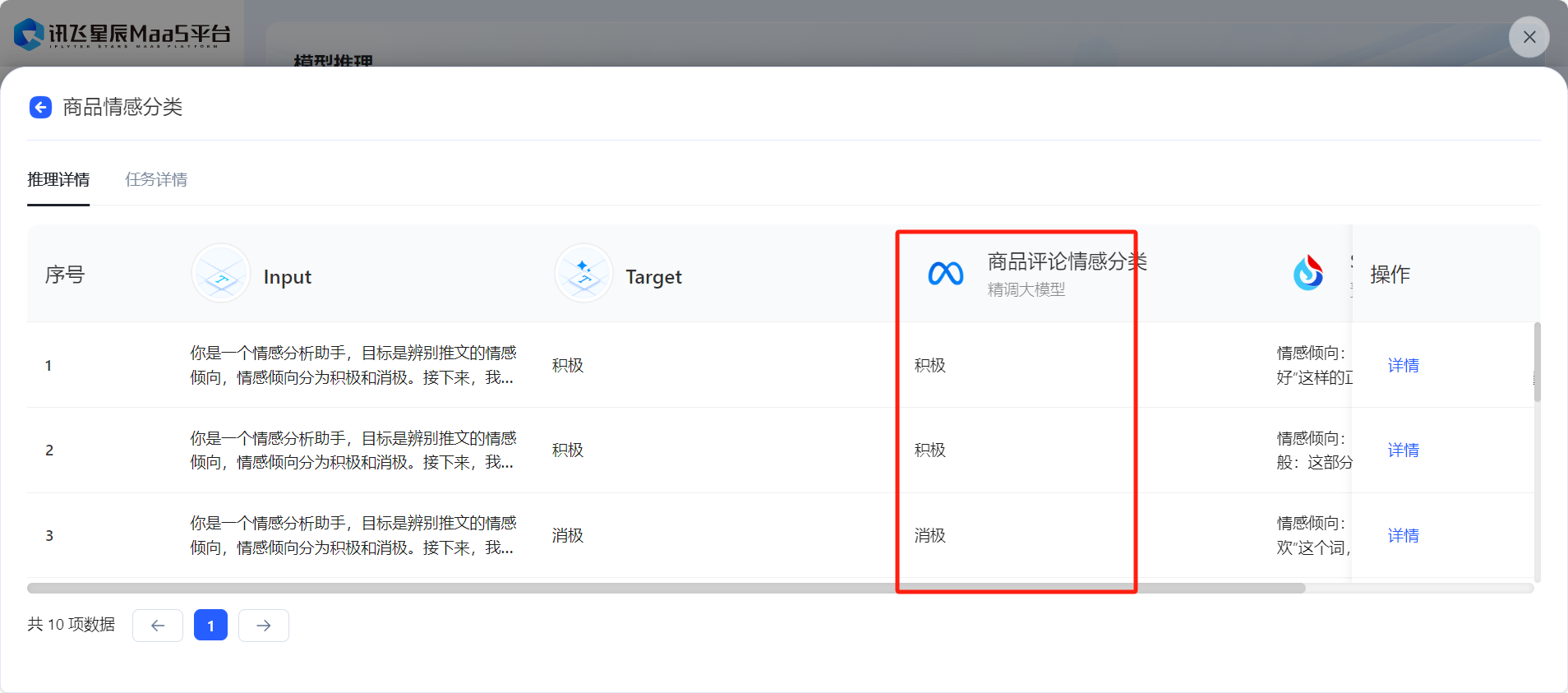
模型評估
- 在【模型評估】板塊,可以基于批量推理結果對模型的輸出效果進行全方位評價,提供相似度打分和裁判員打分兩種方式,可以根據任務類型進行選擇。
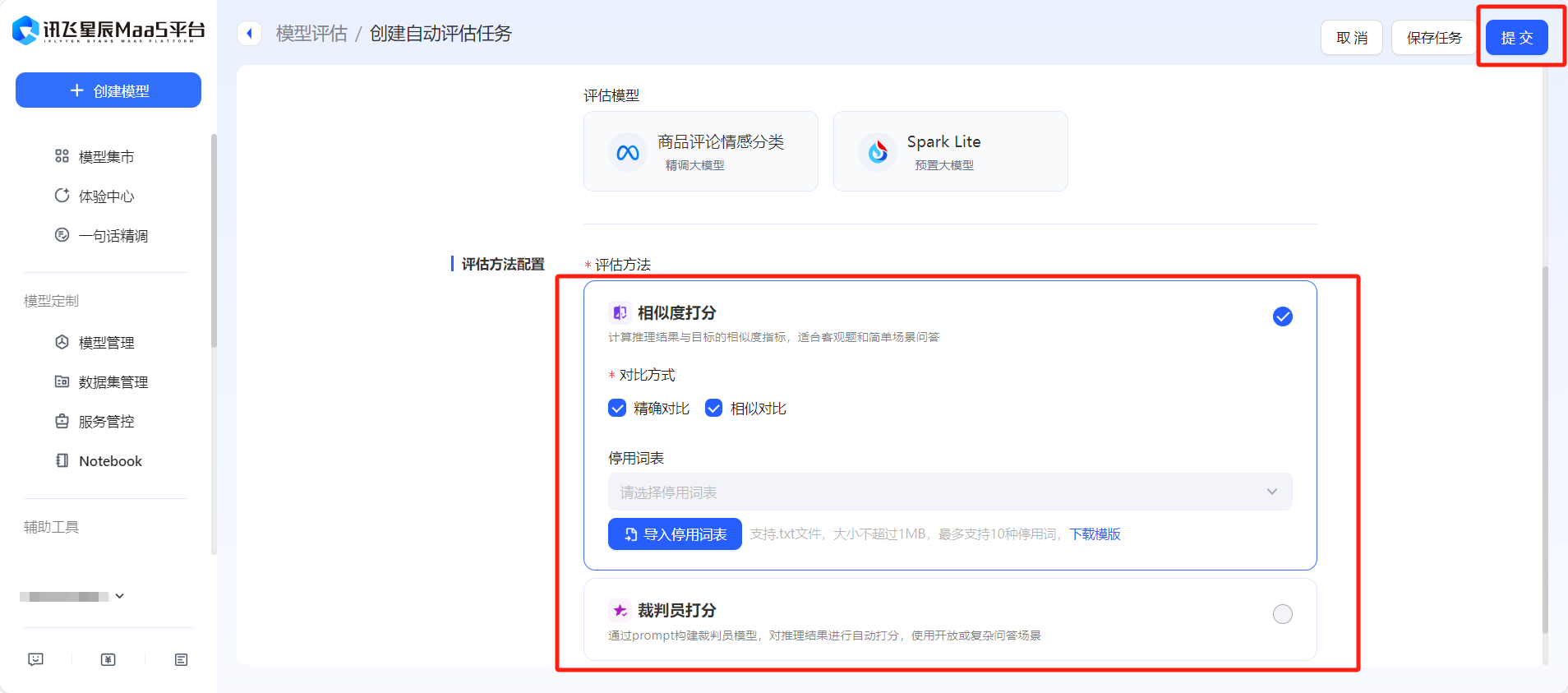
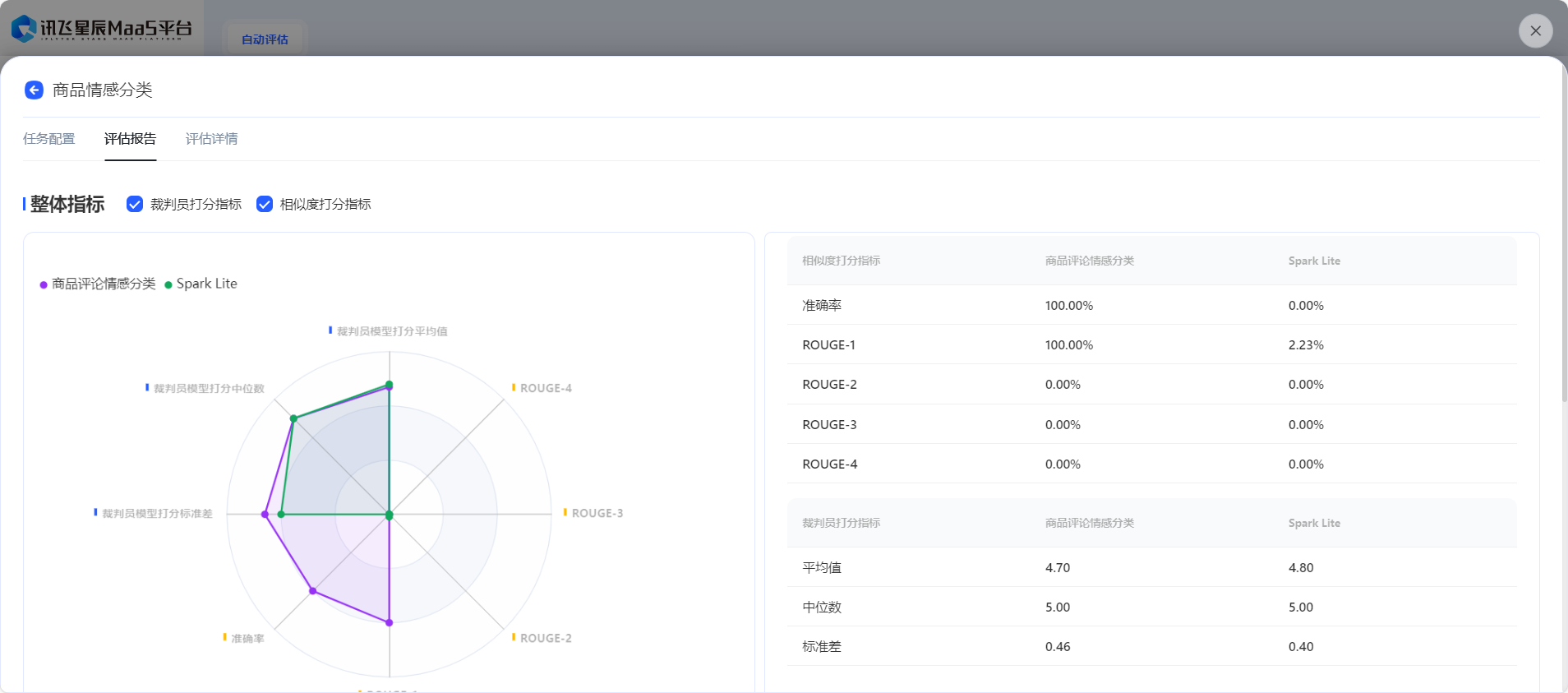
詩詞生成實踐

商品分類任務數據集校驗失敗問題解決
- 優秀實踐分享-學習者手冊版
- 原數據集標簽(校驗失敗)
{"prompt": "你是一個專業的商品分類助手,需要依據給定的30種商品分類標準,對輸入的商品名稱進行精準分類。這30種分類分別為:家居、家電、健康、服飾內衣、玩具、鞋靴箱包、香煙、糧油速食、酒飲沖調、美妝、清潔、餐飲、母嬰、個護、蔬菜、休閑食品、辦公、水產、肉禽蛋、寵物、乳品、禮品、3C數碼、健康食品、汽車用品、水果、鐘表配飾、鮮花綠植、運動。當接收到商品名稱后,請仔細分析商品的功能、用途、材質以及所屬行業等特征,將其歸入最合適的分類中。在分類過程中,如果遇到難以判斷的商品名稱,可結合常見的生活常識、市場主流分類方式以及你所學習到的知識進行綜合考量。現在,請對以下商品名稱進行分類,直接輸出類型標簽,不需要解釋:",
"label": "家居",
"text": "櫻之歌藍色之戀5件套日式釉下彩純手繪家用餐具套裝陶瓷器碗盤碗碟微波爐可用"}
- 新數據集標簽(符合要求)
{"instruction": "你是一個專業的商品分類助手,需要依據給定的30種商品分類標準,對輸入的商品名稱進行精準分類。這30種分類分別為:家居、家電、健康、服飾內衣、玩具、鞋靴箱包、香煙、糧油速食、酒飲沖調、美妝、清潔、餐飲、母嬰、個護、蔬菜、休閑食品、辦公、水產、肉禽蛋、寵物、乳品、禮品、3C數碼、健康食品、汽車用品、水果、鐘表配飾、鮮花綠植、運動。當接收到商品名稱后,請仔細分析商品的功能、用途、材質以及所屬行業等特征,將其歸入最合適的分類中。在分類過程中,如果遇到難以判斷的商品名稱,可結合常見的生活常識、市場主流分類方式以及你所學習到的知識進行綜合考量。現在,請對以下商品名稱進行分類,直接輸出類型標簽,不需要解釋:",
"output": "家居",
"input": "櫻之歌藍色之戀5件套日式釉下彩純手繪家用餐具套裝陶瓷器碗盤碗碟微波爐可用"}
- 解決方法,使用文檔編輯器或其他工具將json格式的標簽進行替換。
prompt->instruction
label->output
text->input
- 經驗證,可以正常上傳使用。
![[CSS]讓overflow不用按shift可以滾輪水平滾動(純CSS)](http://pic.xiahunao.cn/[CSS]讓overflow不用按shift可以滾輪水平滾動(純CSS))


)
)

)


![[java 常用類API] 新手小白的編程字典](http://pic.xiahunao.cn/[java 常用類API] 新手小白的編程字典)









