在機器學習的眾多算法中,線性回歸無疑是最基礎也是最常被提及的一種。它不僅在統計學中占有重要地位,而且在預測分析和數據建模中也發揮著關鍵作用。本文將深入探討線性回歸的基本概念、評估指標以及在實際問題中的應用,并通過一個模擬的氣象數據集進行數據探索和可視化。
線性回歸簡介
線性回歸是一種通過屬性的線性組合來進行預測的線性模型。其核心目標是找到一條直線(在二維空間中)或者一個平面(在三維空間中)甚至更高維的超平面,以此來最小化預測值與真實值之間的誤差。
線性模型的一般形式
線性模型的一般形式可以表示為: y=w1?x1?+w2?x2?+...+wn?xn?+b 其中,w1?,w2?,...,wn? 是模型的系數,b 是截距,x1?,x2?,...,xn? 是特征,而 y 是目標變量。
最小二乘法
最小二乘法是求解線性回歸模型參數的一種常用方法。它基于均方誤差最小化來進行模型求解。具體來說,最小二乘法試圖找到一條直線,使得所有樣本到這條直線的歐氏距離之和最小。
線性回歸的評估指標
評估線性回歸模型性能的常用指標包括:
誤差平方和/殘差平方和 (SSE/RSS):這是預測值與真實值之差的平方和,用于衡量模型的擬合程度。
平方損失/均方誤差 (MSE):這是誤差平方和的平均值,可以表示為: MSE=n1?∑i=1n?(yi??y^?i?)2
R方 (R2):這是決定系數,用于衡量模型對數據的解釋能力。R2越接近1,表示模型擬合效果越好。
多元線性回歸
當模型包含多個特征時,我們稱之為多元線性回歸。在這種情況下,模型的求解通常涉及到矩陣運算,以找到最優的系數和截距。
數據探索與可視化
為了更好地理解數據,我們將使用Python進行數據探索和可視化。以下是一個模擬的氣象數據集,我們將分析其特征分布、特征相關性、異常值,并進行數據可視化。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns# 假設df是包含數據的DataFrame
df = pd.DataFrame({'氣溫': np.random.uniform(15, 30, 5000),'濕度': np.random.uniform(40, 80, 5000),'風速': np.random.uniform(2, 10, 5000),'氣壓': np.random.uniform(1000, 1020, 5000),'目標值': np.random.uniform(15, 30, 5000) + np.random.normal(0, 2, 5000)
})# 1. 數據分布
print("描述性統計:")
print(df.describe())# 2. 特征相關性
print("\n特征相關性:")
print(df.corr())# 3. 異常值檢測(以箱線圖為例)
plt.figure(figsize=(12, 8))
sns.boxplot(data=df)
plt.xticks(rotation=45)
plt.title('箱線圖 - 異常值檢測')
plt.show()# 4. 數據可視化
# 散點圖矩陣
plt.figure(figsize=(12, 10))
sns.pairplot(df)
plt.suptitle('散點圖矩陣', y=1.02)
plt.show()# 氣溫與目標值的關系
plt.figure(figsize=(8, 6))
sns.scatterplot(x='氣溫', y='目標值', data=df)
plt.title('氣溫與目標值的關系')
plt.show()# 濕度與目標值的關系
plt.figure(figsize=(8, 6))
sns.scatterplot(x='濕度', y='目標值', data=df)
plt.title('濕度與目標值的關系')
plt.show()數據分析
數據概覽
首先,我們來看一下數據的前幾行:
氣溫:范圍從18到22度左右,這是影響目標值(第二天的氣溫)的主要特征之一。
濕度:大約在60%到80%之間,濕度的范圍相對較窄,可能對目標值的影響不如氣溫明顯。
風速:在3到9之間變化,風速的變化范圍較大,可能對氣溫有一定的影響。
氣壓:在1005到1020 hPa之間,氣壓的波動范圍相對較小。
目標值:第二天的氣溫,與當天氣溫有一定的線性關系,但也包含了隨機噪聲。
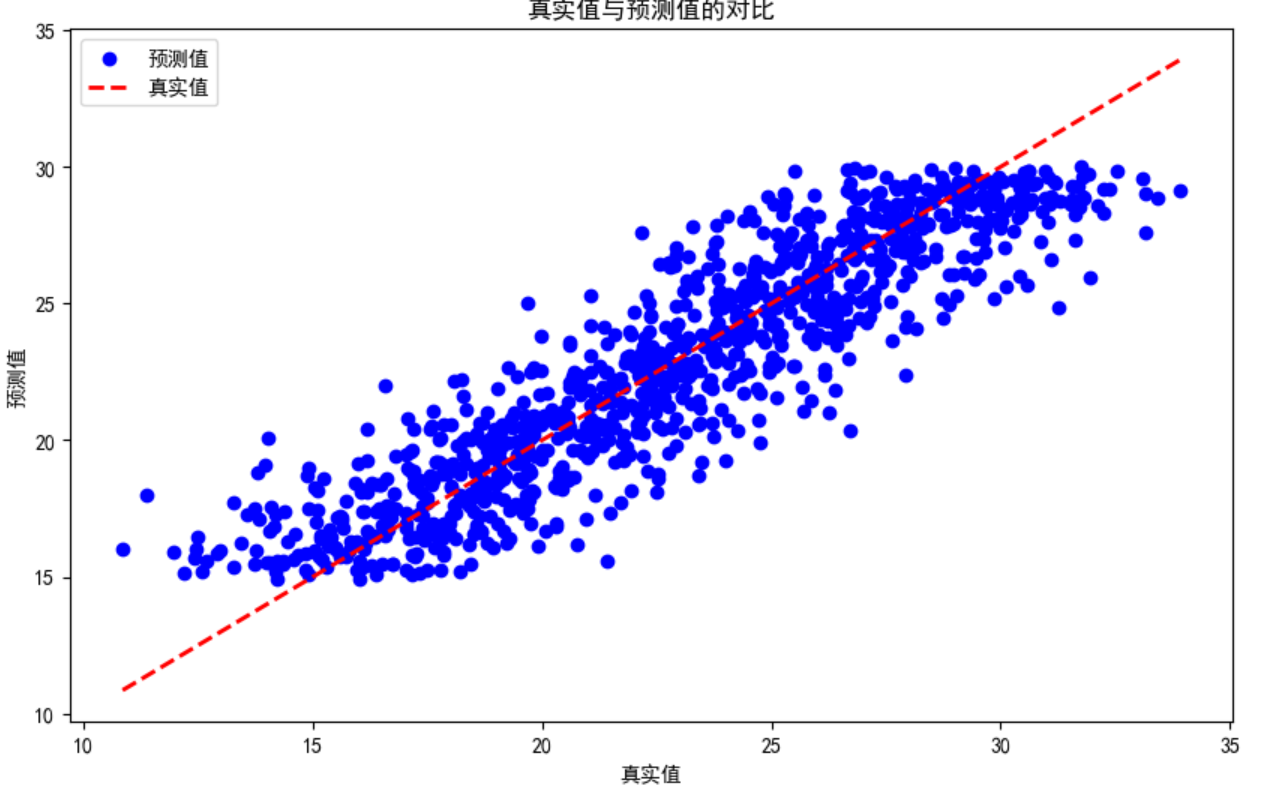
模型評估
均方誤差 (MSE): 4.013131461243498
MSE是預測值與實際值之間差異的平方的平均值。較低的MSE值表明模型的預測誤差較小,預測結果較為準確。
決定系數 (R2): 0.8211102730112569
R2值衡量的是模型對數據變異性的解釋程度。R2值接近1表示模型擬合效果好,能夠較好地解釋數據的變異性。在這里,0.821表明模型能夠解釋約82.11%的數據變異性,這是一個相對較高的值,說明模型擬合效果較好。
模型參數
截距 (Intercept): -10.706883157150784
截距表示當所有特征值為0時,模型預測的目標值。在這個氣象模型中,截距可能沒有實際的物理意義,因為它是一個理論上的值。
系數 (Coefficients): [1.00000805, 5.61622136e-04, 5.65278286e-03, 1.05382308e-02]
這些系數表示每個特征對目標值的影響程度:
氣溫的系數為1.00000805,表明氣溫每增加1度,預測的第二天氣溫平均增加約1.000008度,這是影響目標值的主要因素。
濕度的系數為5.61622136e-04,表明濕度對目標值的影響較小,濕度每增加1%,預測的第二天氣溫平均增加約0.00056度。
風速的系數為5.65278286e-03,表明風速每增加1單位,預測的第二天氣溫平均增加約0.00565度,影響相對較小。
氣壓的系數為1.05382308e-02,表明氣壓每增加1 hPa,預測的第二天氣溫平均增加約0.0105度,影響也相對較小。
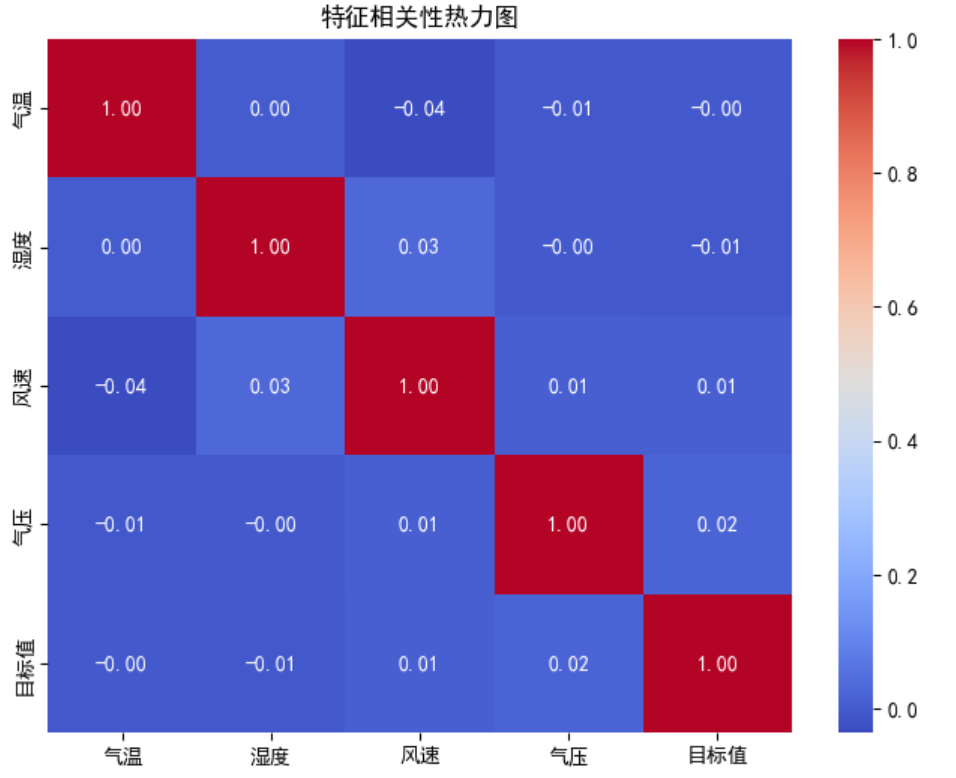
熱力圖概述
熱力圖使用顏色來表示數值的大小,通常用于展示矩陣數據。在特征相關性熱力圖中,顏色的深淺表示特征之間的相關系數的大小,顏色越深表示相關性越強。cmap='coolwarm' 表示使用從藍色(低相關性)到紅色(高相關性)的漸變色。
熱力圖分析
對角線:熱力圖的對角線上的值總是1,因為每個特征與自身的相關性是完全相關(即相關系數為1)。
氣溫與其他特征的相關性:
如果氣溫的相關系數接近1,顏色接近紅色,這表明氣溫與目標值之間有很強的正相關關系。
如果氣溫與其他特征(如濕度、風速、氣壓)的相關系數較低,顏色接近藍色,這表明氣溫與這些特征之間的關系較弱。
濕度、風速和氣壓的相關性:
如果這些特征之間的相關系數較高(接近1),顏色接近紅色,這表明它們之間存在較強的線性關系。
如果相關系數較低(接近0),顏色接近藍色,這表明它們之間的關系較弱。
目標值與其他特征的相關性:
目標值與氣溫的相關性可能較高,因為氣溫是影響第二天氣溫的主要因素。
目標值與濕度、風速和氣壓的相關性可能較低,這表明這些特征對目標值的影響較小。
實際意義
特征選擇:通過分析熱力圖,我們可以識別出與目標變量相關性較高的特征,這有助于我們在構建模型時進行特征選擇。
數據理解:熱力圖幫助我們更好地理解數據集中特征之間的關系,這對于數據預處理和模型優化非常重要。
異常檢測:雖然熱力圖主要用于展示相關性,但它也可以間接幫助我們識別異常值。例如,如果某個特征與其他特征的相關性異常高或低,這可能是數據異常的跡象。
plt.figure(figsize=(8, 6))
sns.heatmap(corr_matrix, annot=True, cmap='coolwarm', fmt=".2f")
plt.title('特征相關性熱力圖')
plt.show()
)




)












