數據傾斜讓你的Hive查詢慢如蝸牛?單個熱點分組拖垮整個集群?PawSQL獨家算法GroupSkewedOptimization來拯救!

🎯 痛點直擊:當數據傾斜遇上分組操作
想象這樣一個場景:
你的電商平臺有1000萬VIP用戶訂單和100萬普通用戶訂單。當你用GROUP BY按客戶類型分組統計時:
SELECT?customer_type,?COUNT(*),?SUM(amount)
FROM?orders?
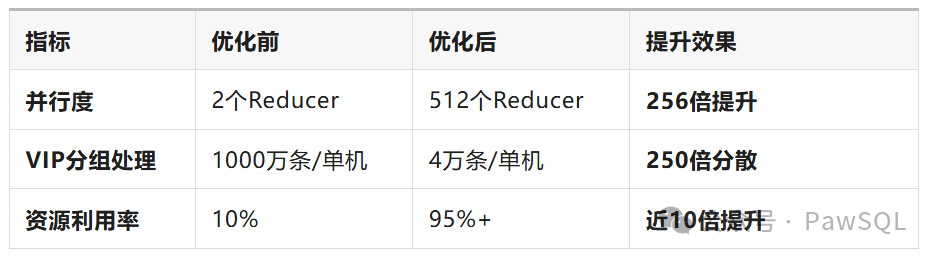
GROUP?BY?customer_type;VIP分組:1個Reducer苦苦支撐1000萬條數據
普通分組:1個Reducer輕松處理100萬條數據
其他Reducer:集體摸魚,資源浪費
最終后果:?整個作業被最慢的那個Reducer拖垮!
💡 核心優化算法:兩階段聚合
化整為零,各個擊破。
PawSQL的GroupSkewedOptimization算法采用"分而治之"的經典思想:
🔹?第一階段:加鹽打散 → 熱點數據分流到256個子分組?
🔹?第二階段:合并聚合 → 還原最終結果
優化前 vs 優化后對比
🔧?GroupSkewedOptimization算法深度解析
觸發條件
??支持場景
GROUP BY分組查詢
簡單單列分組
標準聚合函數(COUNT/SUM/MAX/MIN/AVG)
??限制條件
包含HAVING子句
復雜分組表達式
核心重寫策略
🎲 鹽值生成
CAST(RAND()?*?256?AS?INT)?as?salt這個簡單表達式生成0-255隨機整數,將每個分組拆分成256個子分組!
📊 聚合函數智能處理
COUNT函數:第一階段COUNT → 第二階段SUM?
-- 重寫前
SELECT?region,?COUNT(*)
FROM?sales_data
GROUP?BY?region;
-- 重寫后
SELECT?region,?SUM(count_) ?-- 關鍵轉換!
FROM?(SELECT?region,?COUNT(*)?as?count_,CAST(RAND()?*?256?AS?INT)?as?saltFROM?sales_dataGROUP?BY?region, salt
) DT_xxx
GROUP?BY?region;AVG函數:拆解為SUM+COUNT
-- 原始AVG
SELECT?region,?AVG(amount)
FROM?sales_data
GROUP?BY?region;
-- 智能重寫
SELECT?region,?SUM(sum_)?/?SUM(count_) ?-- 重新計算平均值
FROM?(SELECT?region,?SUM(amount)?as?sum_,?COUNT(amount)?as?count_,CAST(RAND()?*?256?AS?INT)?as?saltFROM?sales_dataGROUP?BY?region, salt
) DT_xxx
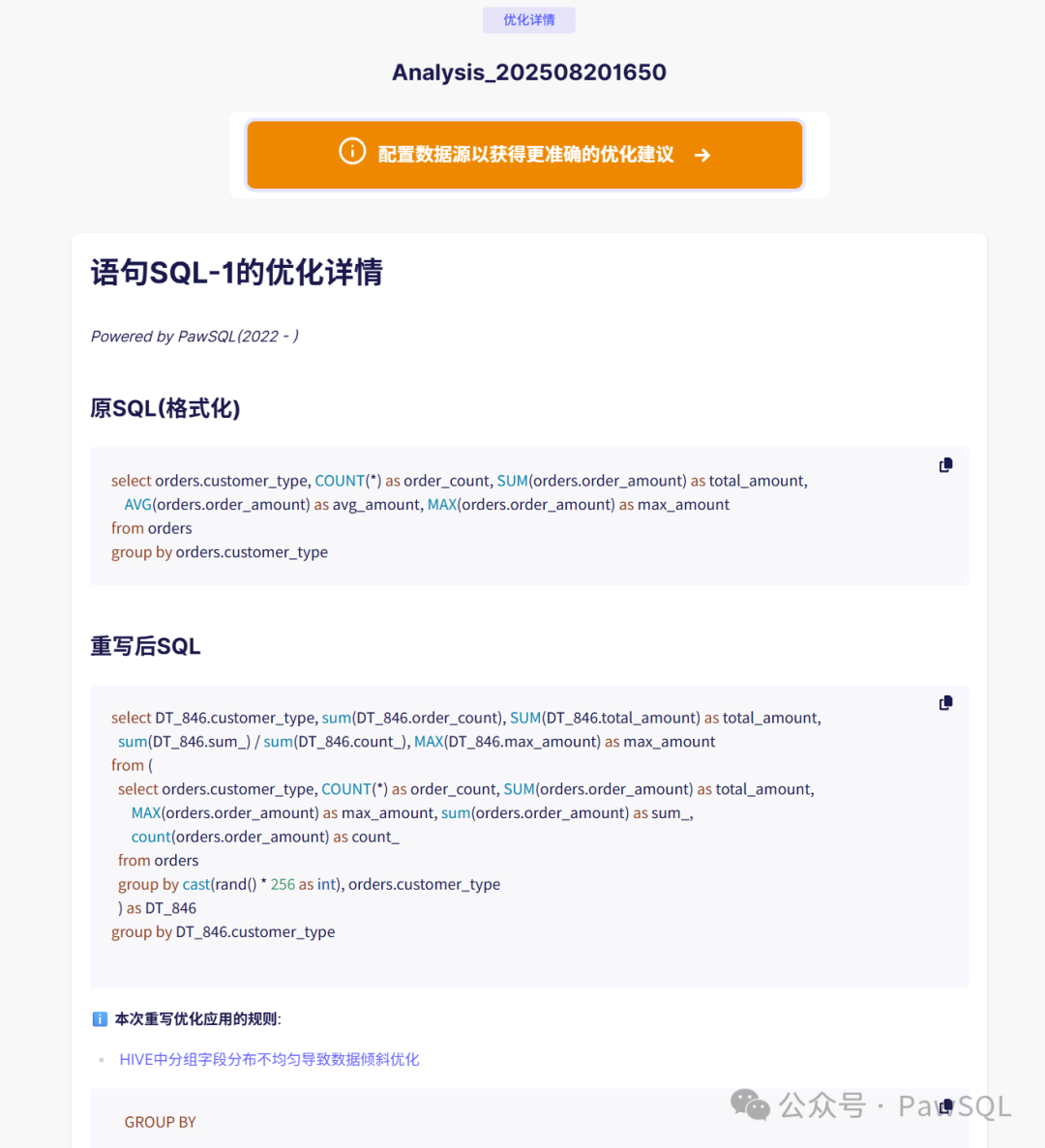
GROUP?BY?region;🌟 實戰案例:訂單統計的完美蛻變
原查詢:簡單但低效
SELECTcustomer_type,COUNT(*)?as?order_count,SUM(order_amount)?as?total_amount,AVG(order_amount)?as?avg_amount,MAX(order_amount)?as?max_amount
FROM?orders
GROUP?BY?customer_type;優化后:復雜但高效
SELECTcustomer_type,SUM(count_)?as?order_count, ? ? ? ? ??-- COUNT → SUMSUM(sum_)?as?total_amount, ? ? ? ? ? ?-- SUM保持不變SUM(sum_)?/?SUM(count_)?as?avg_amount,?-- AVG重新計算MAX(max_)?as?max_amount ? ? ? ? ? ? ??-- MAX保持不變
FROM?(SELECTcustomer_type,COUNT(*)?as?count_,SUM(order_amount)?as?sum_,COUNT(order_amount)?as?count_,MAX(order_amount)?as?max_,CAST(RAND()?*?256?AS?INT)?as?salt ?-- 🔑 關鍵的鹽值FROM?ordersGROUP?BY?customer_type, salt
) DT_123
GROUP?BY?customer_type;PawSQL自動識別并優化:
🎯 適用場景:什么時候該用這招?
? 最佳適用場景:嚴重的數據傾斜
🔹?電商平臺:按商家、地區分組的訂單統計?
🔹?金融系統:按客戶等級分組的交易分析
🔹?廣告系統:按渠道分組的投放效果統計?
🔹?物流系統:按配送區域分組的包裹統計
?? 使用注意事項
會增加查詢復雜度和中間數據量
對輕微傾斜可能效果不明顯
🎉 總結:PawSQL讓SQL優化變得簡單高效
作為專業的SQL優化引擎,GroupSkewedOptimization算法展現了PawSQL在SQL優化領域的深厚技術積累:
??自動化:無需手動調優,一鍵解決傾斜問題?
??智能化:精準識別優化時機,避免過度優化?
??通用化:支持多種聚合函數,適用性廣
🌐關于PawSQL
PawSQL專注于數據庫性能優化自動化和智能化,提供的解決方案覆蓋SQL開發、測試、運維的整個流程,廣泛支持多種主流商用、國產和開源數據庫,為開發者和企業提供一站式的創新SQL優化解決方案。


![[docker/大數據]Spark快速入門](http://pic.xiahunao.cn/[docker/大數據]Spark快速入門)





)

)




:mybaits if標簽test條件判斷等號=解析異常解決方案)



